预测雷暴旋转的基础机器学习:分类 - 决策树
本文翻译自 AMS 机器学习 Python 教程,并有部分修改。
Lagerquist, R., and D.J. Gagne II, 2019: “Basic machine learning for predicting thunderstorm rotation: Python tutorial”. https://github.com/djgagne/ams-ml-python-course/blob/master/module_2/ML_Short_Course_Module_2_Basic.ipynb.
数据
使用《预测雷暴旋转的基础机器学习:分类 - 训练》文章中处理过的数据。
介绍
决策树是具有分支节点(椭圆)和叶节点(矩形)的流程图。 在下图中,f 是恶劣天气的预测概率。
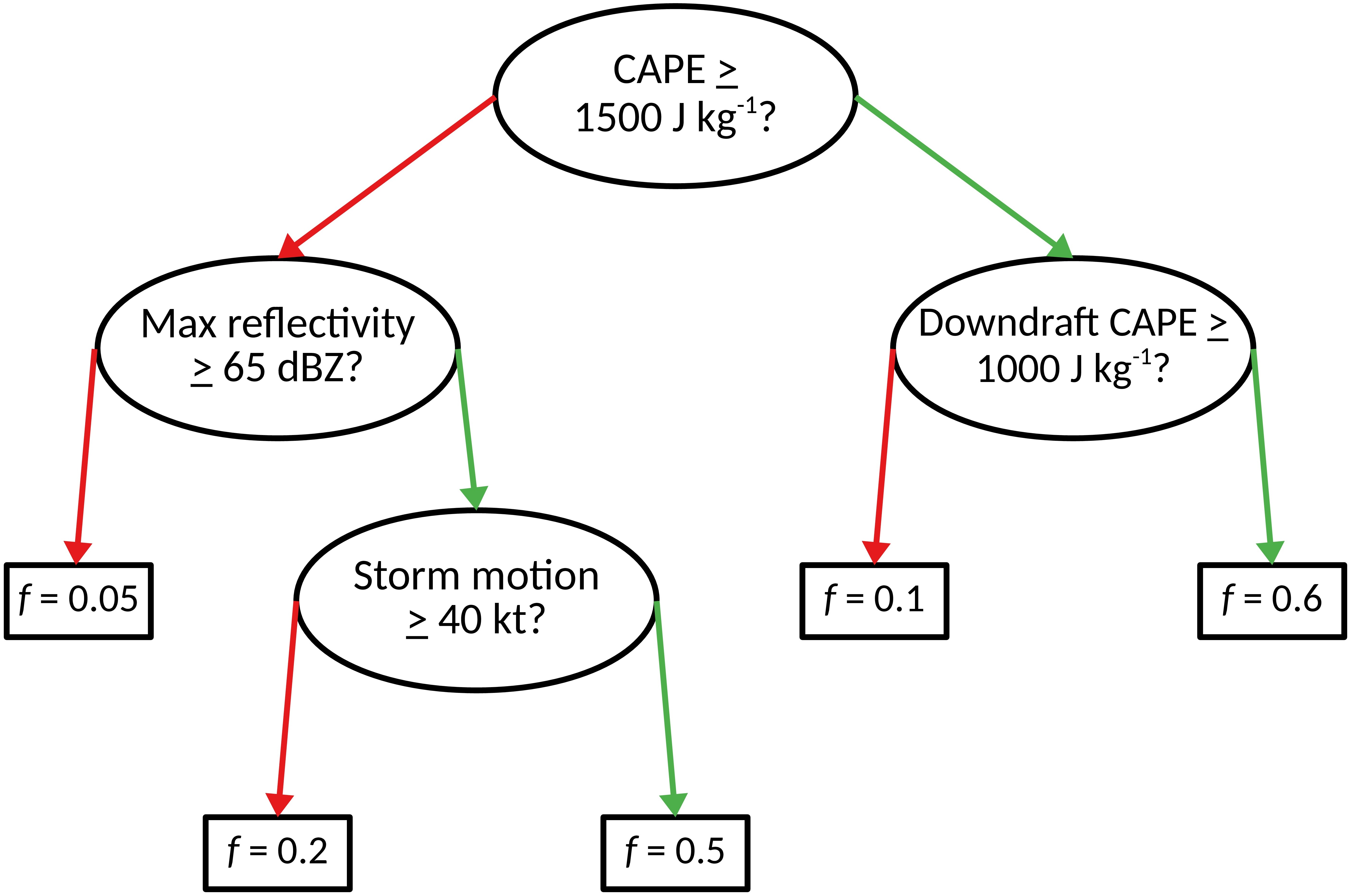
分支节点是分叉的,叶节点是终端的。 换句话说,每个分支节点有2个子节点,每个叶节点有0个子节点。
在叶节点进行预测,并在分支节点提出问题。 由于分支节点是分支的,因此在分支节点处提出的问题必须能用是或否回答。
自 1960 年代以来 (Chisholm 1968),决策树已用于气象学。 它们是由人类专家主观构建的,直到 1980 年代,当时开发了一种目标算法 (Quinlan 1986) 来“训练”它们(确定每个分支节点的最佳问题)。
叶节点 L 的预测值是到达该节点 L 的所有训练样本的平均值。
- 对于回归,这是一个真实值(达到 L 的示例的平均未来最大涡度)。
- 对于分类,这是一个概率(达到 L 的样本中最大未来涡 >= 3.850×10^{-3} s^{-1} 的比例)。
在每个分支节点选择的问题是使信息增益 (information gain) 最大化的问题。
这是通过最小化 “remainder” 来完成的,“remainder” 基于子节点的熵。
一个节点的信息熵 (information entropy) 定义如下。
\begin{equation*} \textrm{Ent}(D) = -\sum_{k=1}^{|y|}p_k\textrm{log}_2p_k \end{equation*}
其中:
- 样本有 |y| 个类别
- p_k 是第 k 类样本占的比例
对于二分类问题,假设正样本的比例为 f,则上式可以写成:
\begin{equation*} E = -\left[f\textrm{log}_2{f} + (1-f)\textrm{log}_2(1-f)\right] \end{equation*}
“remainder” 定义如下:
\begin{equation*} R = \frac{n_{\textrm{left}} E_{\textrm{left}} + n_{\textrm{right}} E_{\textrm{right}}}{n_{\textrm{left}} + n_{\textrm{right}}} \end{equation*}
其中:
- n_{left} 是发送给左孩子的示例数(问题的答案为“否”)
- n_{right} 是发送给右孩子的示例数(问题的答案为“是”)
- E_{left} 是左孩子的熵
- E_{right} 是右孩子的熵
示例
下一个单元训练具有默认超参数的决策树,以预测暴风雨将产生未来涡度 >= 3.850×10^{−3} s^{-1} 的可能性。
创建模型
setup_classification_tree 创建决策树模型
RANDOM_SEED = 6695
def setup_classification_tree(
min_examples_at_split: int=30,
min_examples_at_leaf: int=30,
) -> sklearn.tree.DecisionTreeClassifier:
return sklearn.tree.DecisionTreeClassifier(
criterion='entropy',
min_samples_split=min_examples_at_split,
min_samples_leaf=min_examples_at_leaf,
random_state=RANDOM_SEED
)使用默认超参数创建决策树模型
default_tree_model = setup_classification_tree(
min_examples_at_split=30,
min_examples_at_leaf=30,
)
default_tree_modelDecisionTreeClassifier(criterion='entropy', min_samples_leaf=30,
min_samples_split=30, random_state=6695)
训练
train_classification_tree 用于训练决策树模型
BINARIZED_TARGET_NAME = 'strong_future_rotation_flag'
def train_classification_tree(
model,
training_predictor_table: pd.DataFrame,
training_target_table: pd.DataFrame,
):
model.fit(
X=training_predictor_table.values,
y=training_target_table[BINARIZED_TARGET_NAME].values
)
return model训练模型
_ = train_classification_tree(
model=default_tree_model,
training_predictor_table=training_predictor_table,
training_target_table=training_target_table
)预测
training_probabilities = default_tree_model.predict_proba(
training_predictor_table.values
)[:, 1]
training_probabilities[:10]array([0. , 0. , 0.14285714, 0.14285714, 0. ,
0. , 0. , 0. , 0. , 0. ])
计算平均观测概率
training_event_frequency = np.mean(
training_target_table[BINARIZED_TARGET_NAME].values
)
training_event_frequency0.10034434450161697
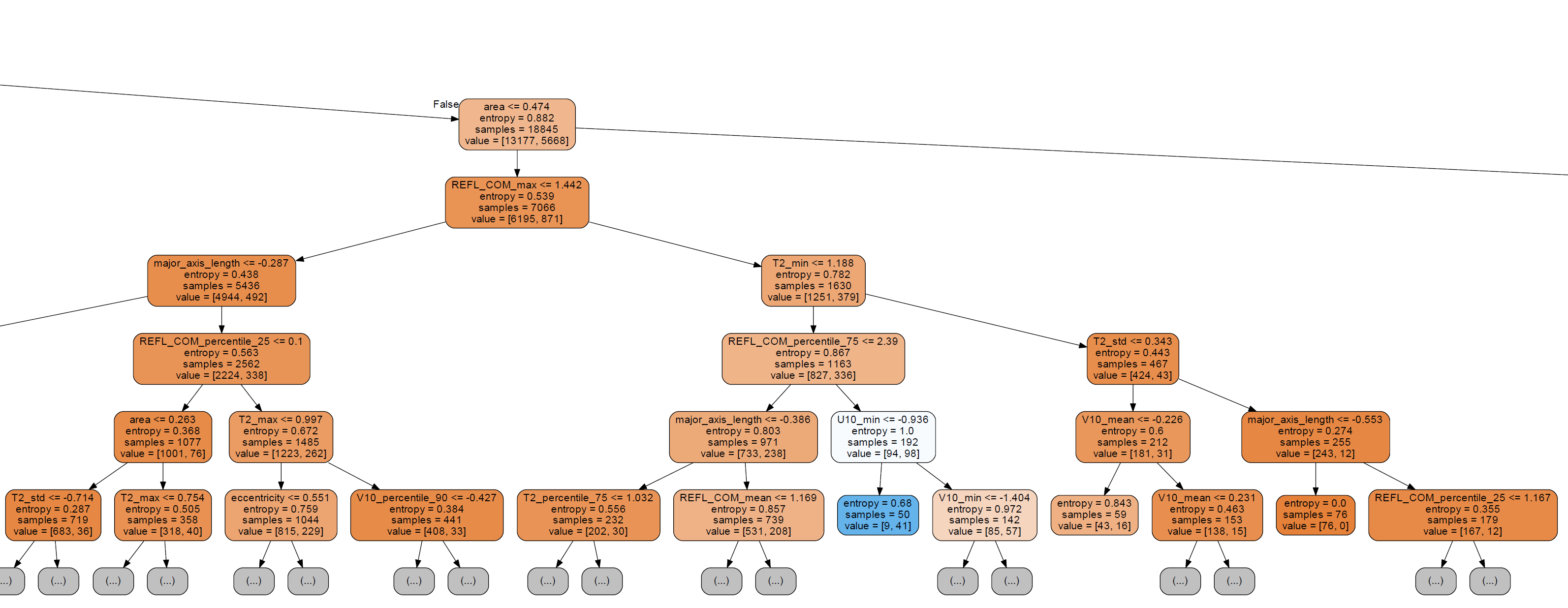
绘制决策树
import graphviz
dot_data = sklearn.tree.export_graphviz(
default_tree_model,
out_file=None,
filled=True,
rounded=True,
max_depth=10,
feature_names=list(training_predictor_table)
)
graph = graphviz.Source(dot_data)
graph.render("default_tree_model")
graph原图太大,仅裁剪一小部分
评估
eval_binary_classifn 函数用于评估决策树模型的性能,已在逻辑回归章节中介绍。
评估训练集
eval_binary_classifn(
observed_labels=training_target_table[BINARIZED_TARGET_NAME].values,
forecast_probabilities=training_probabilities,
training_event_frequency=training_event_frequency,
dataset_name='training'
)Training Max Peirce score (POD - POFD) = 0.781
Training AUC (area under ROC curve) = 0.955
Training Max CSI (critical success index) = 0.471
Training Brier score = 0.049
Training Brier skill score (improvement over climatology) = 0.459
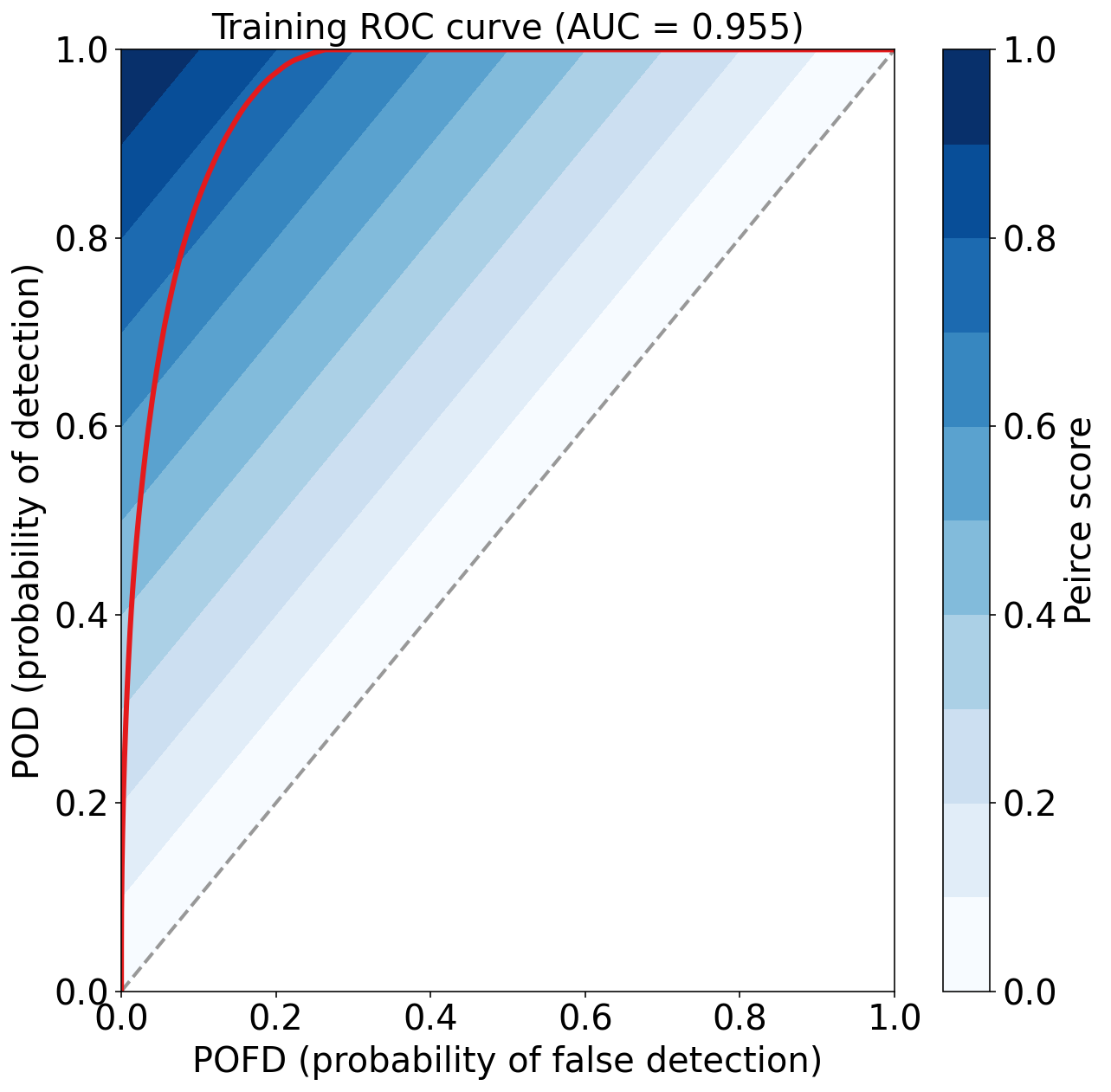
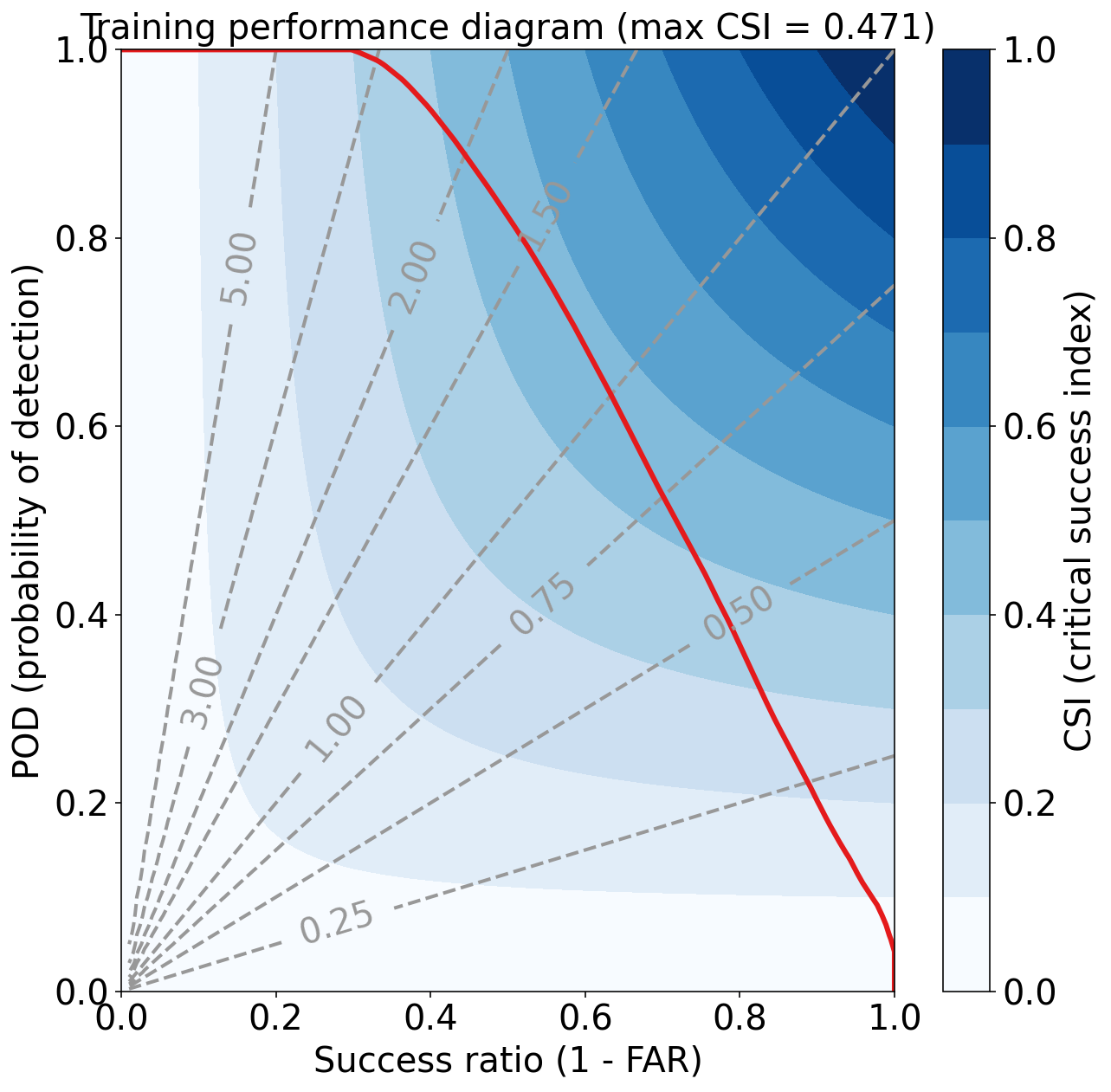
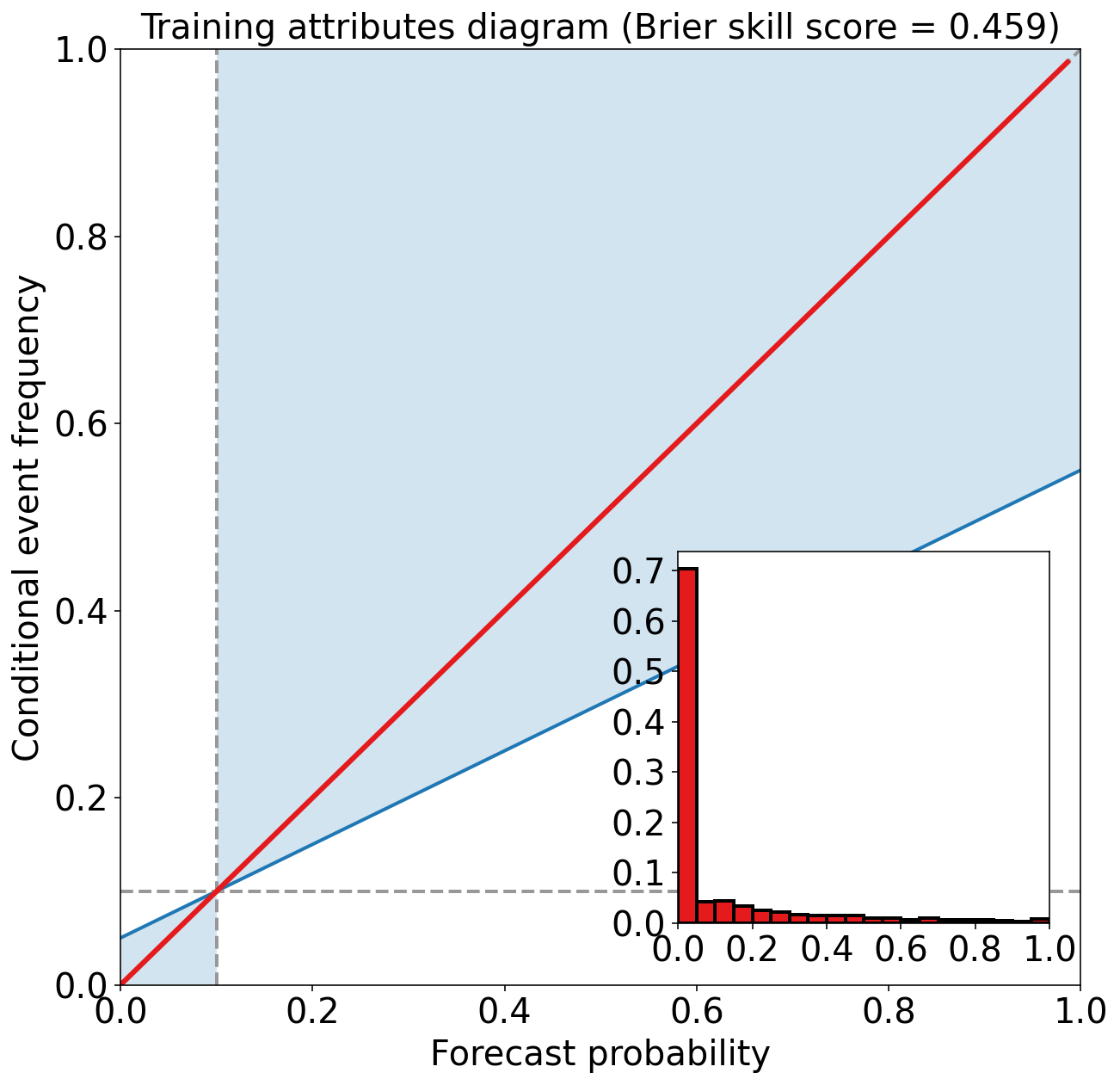
评估验证集
预测验证集
validation_probabilities = default_tree_model.predict_proba(
validation_predictor_table.values
)[:, 1]评估验证集
eval_binary_classifn(
observed_labels=validation_target_table[BINARIZED_TARGET_NAME].values,
forecast_probabilities=validation_probabilities,
training_event_frequency=training_event_frequency,
dataset_name="validation"
)Validation Max Peirce score (POD - POFD) = 0.598
Validation AUC (area under ROC curve) = 0.854
Validation Max CSI (critical success index) = 0.342
Validation Brier score = 0.069
Validation Brier skill score (improvement over climatology) = 0.233
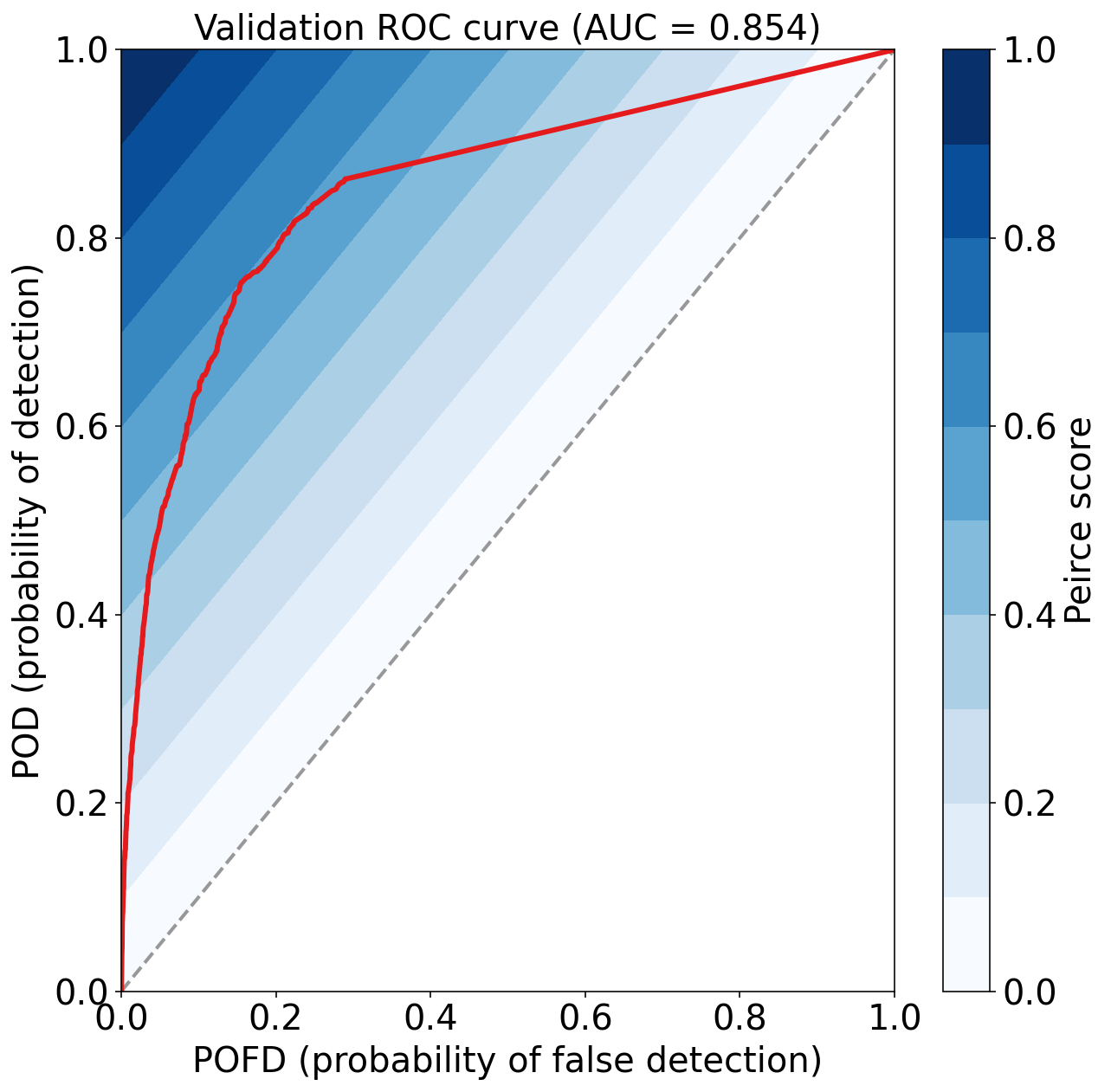
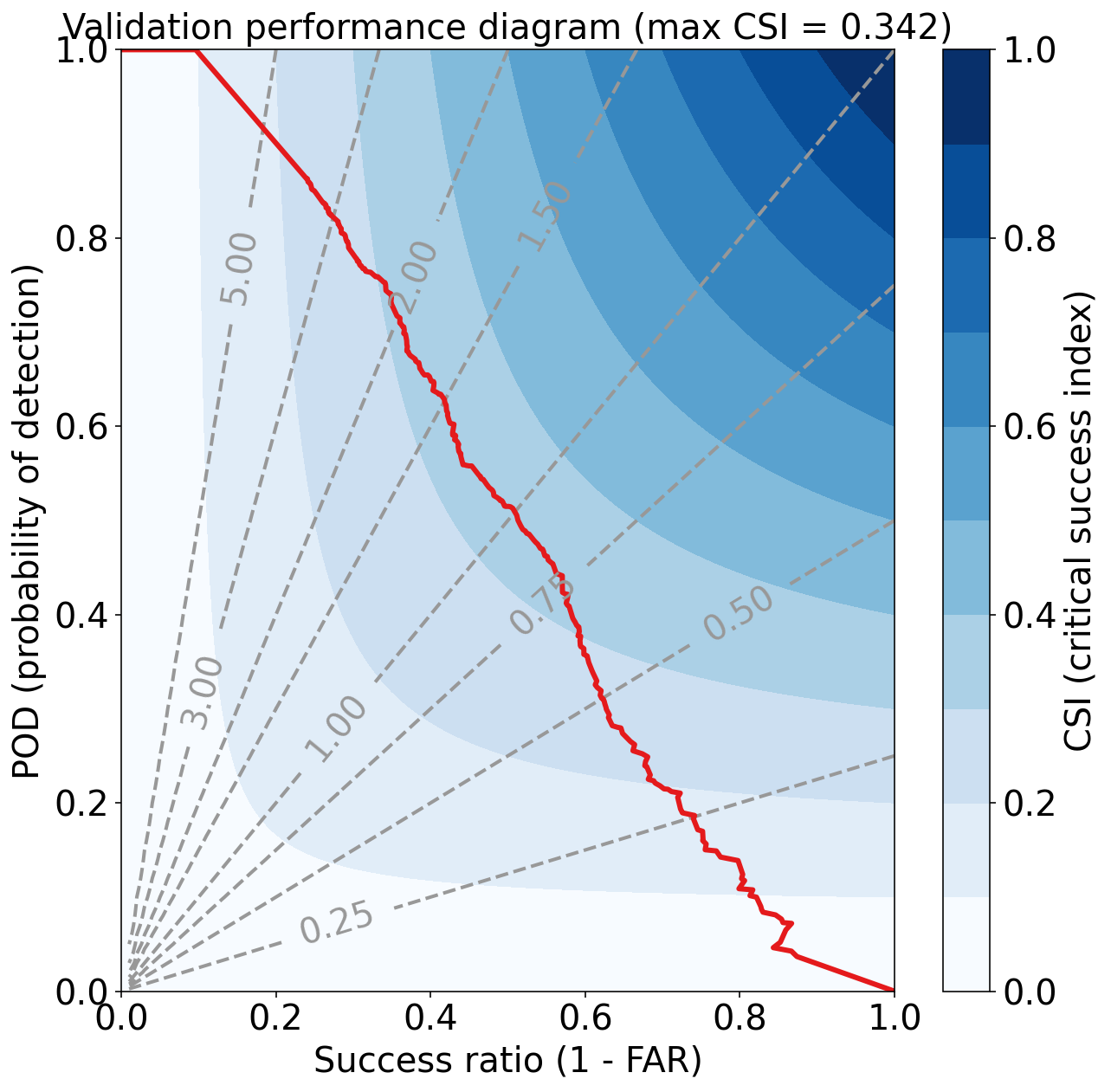
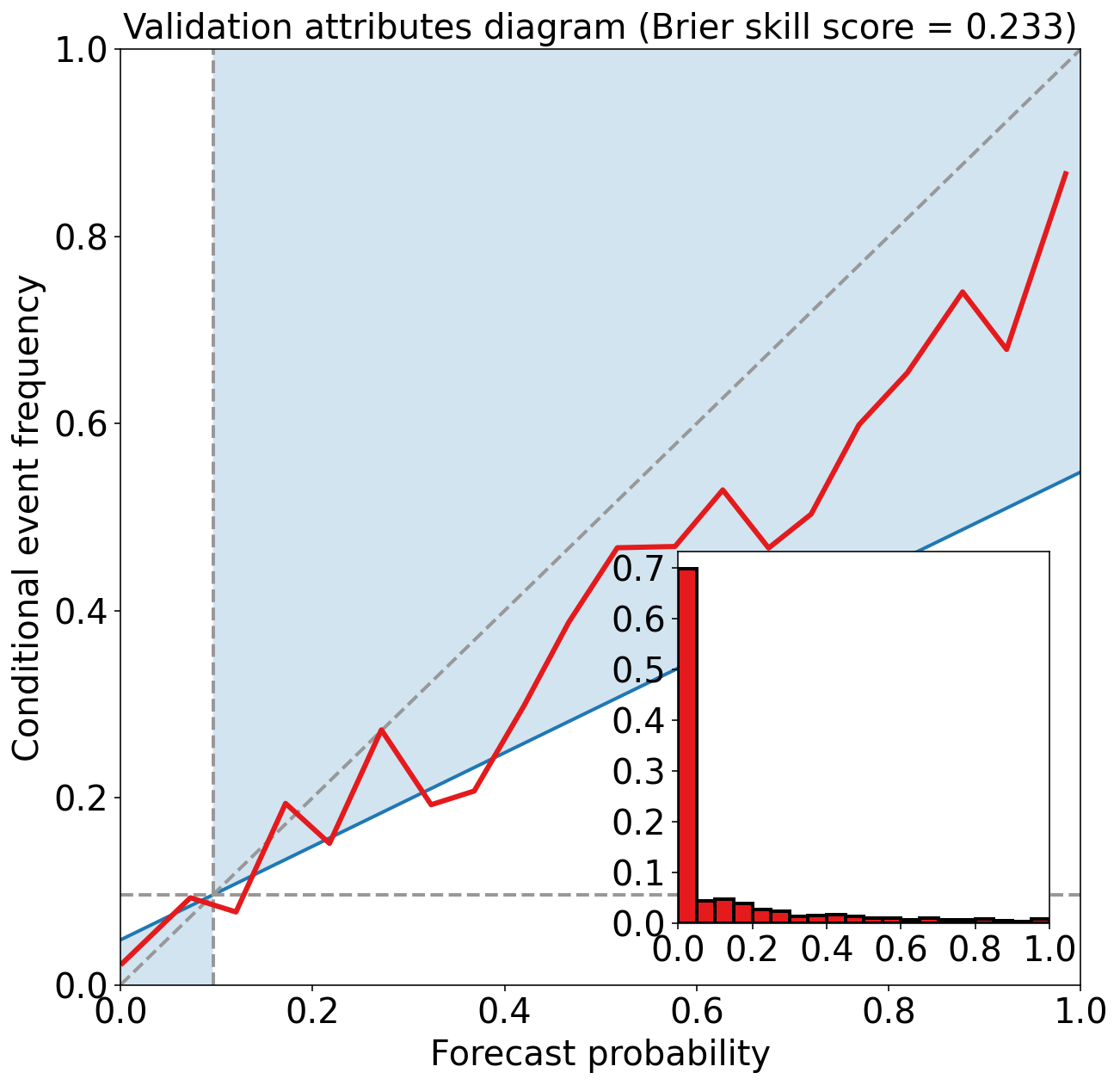
注:
对比训练集和验证集的指标,可以发现验证集性能下降较为明显,说明有训练的模型对训练集过拟合。
这也是决策树最常见的问题。
后续章节将会介绍使用随机森林等方法降低决策树的过拟合。
参考
https://github.com/djgagne/ams-ml-python-course
AMS 机器学习课程
数据预处理:
《数据分析与预处理》
实际数据处理:
线性回归:
逻辑回归: