Dask应用:计算站点风险概率预报产品
本文介绍如何使用 Dask 从集合预报数据中提取数据,为站点计算风险概率预报产品。
需求
集合预报模式的产品后处理任务比确定性模式涉及更多的数据。
本文关注如何从集合预报系统输出的逐时效 GRIB 2 数据中计算某站点的概率预报产品。 即从各个成员的 GRIB 2 文件中提取相应要素的站点数据,得到一个与成员个数相同的预报值数组,根据给定阈值计算超过阈值的概率。
具体需求可以浏览《智慧冬奥2022天气预报示范计划 (SMART2022-FDP) —— 技术方案》中 4.1.6 模式集成产品 章节,其中表 4-12 给出影响赛事的气象风险阈值。 这里仅摘录部分产品要求:
- 温度:超过阈值的概率,例如 < 0°C,> 5°C 等
- 能见度:超过阈值的概率,例如 < 500m,< 200m 等
- 降水:超过阈值的概率,例如 > 1mm,> 2mm 等
- 平均风速:超过阈值的概率,例如 > 4m/s,> 10m/s 等
现有方案
NWPC 正在建设的产品后处理系统中采用串行方式生成风险概率预报产品。
利用 wgrib2 提取需要的数据,再由 NWPC 内部开发的 smartFDP_meps.exe 程序计算概率值,最后通过 sed 等 Linux 命令行工具生成 XML 文件。
具体过程如下图所示:
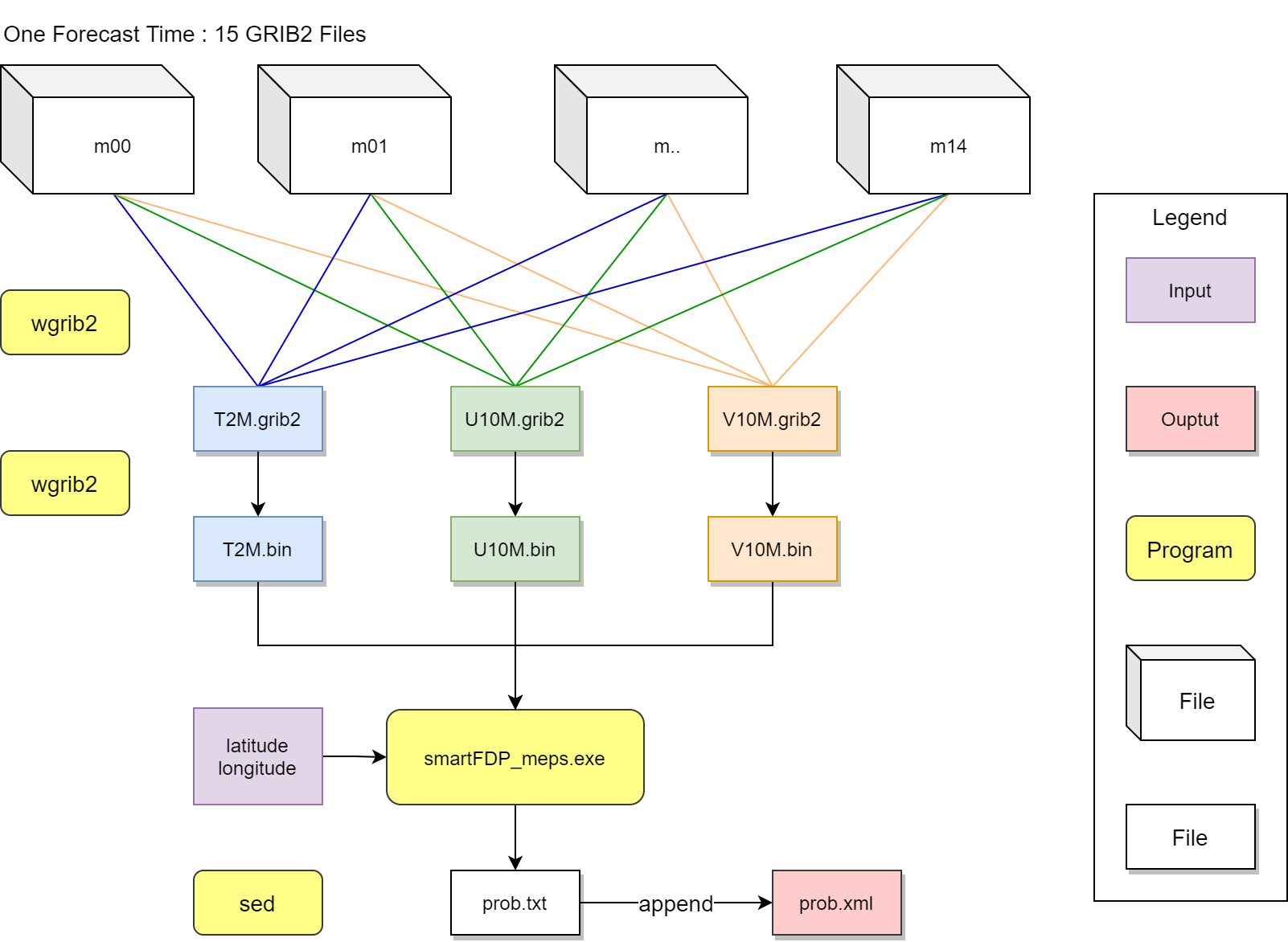
单个时效的计算流程可以分为三个部分:
数据处理:生成计算概率值需要的数据
1.1 使用
wgrib2从所有集合成员 (m00 - m14) 的 GRIB 2 数据中将需要的变量提取并合并到单个文件中,例如将 2 米温度数据提取到 T2M.grib2 文件中,将 10 米风数据提取到 U10M.grib2 和 V10M.grib2 文件中;1.2 使用
wgrib2将提取合并后的 GRIB 2 文件转成二进制格式 (例如 T2M.bin)。概率计算:给定经纬度 (
latitude和longitude) 执行smartFDP_meps.exe程序,该程序会读取运行目录下的二进制文件,将计算得到的概率值写入prob.txt文件中;产品生成:使用
sed从程序输出的prob.txt文件中读取概率值,通过echo和重定向以 XML 格式追加 (append) 到最终的产品文件prob.xml中。
循环计算所有时效,得到最终的风险概率预报产品文件 (XML 格式)。
对于单个站点,上述算法计算 GRAPES REPS (0-72 时效) + GRAPES GEPS (78-240 时效) 融合产品共耗时 23 分钟。
分析上述过程可以发现该算法涉及大量磁盘 IO,如果直接从原始文件中获取站点数据并保存在内存中,可以减少 IO 操作 (nwpc-oper/nwpc-oper)。 另外从集合成员输出中提取站点数据的任务之间没有关联,非常适合改成并发算法 (Dask)。 当获取到所有要素所有成员的站点数据记录后,根据阈值计算概率操作的运行速度很快,可以采用串行方式逐个完成计算 (Pandas)。
Dask 方案
下面介绍目前基于 Dask 实现的并发计算方案,如下图所示,将整个计算分为两个部分:
- 并行部分:从多个 GRIB 2 文件中批量获取数据记录,得到多时效、多成员、多要素的站点预报值,形成记录列表
- 串行部分:将数据记录列表合并为二维表格 (Pandas DataFrame),根据阈值依次计算各项概率值
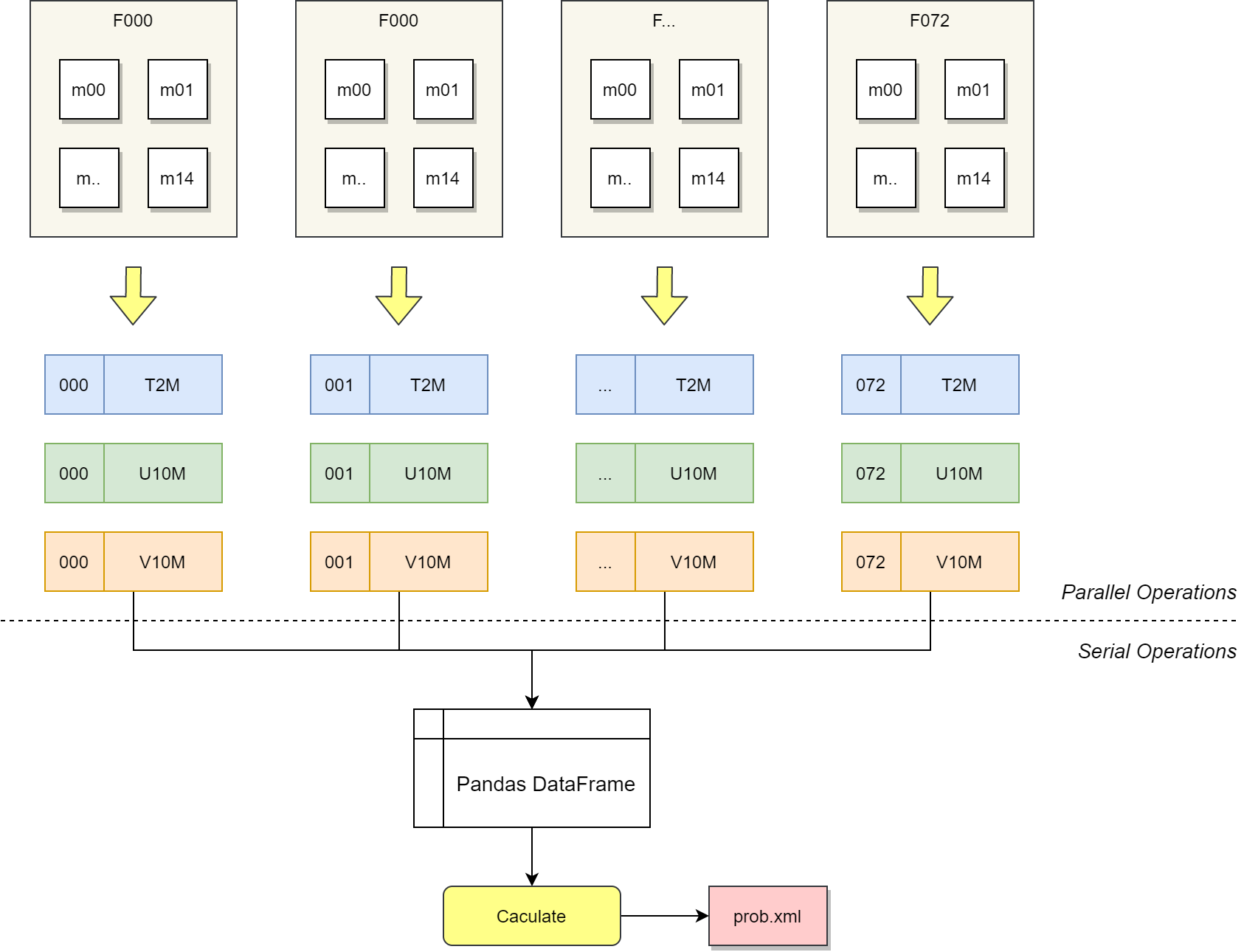
站点风险概率预报产品的并发计算方案,基于 Dask 和 Pandas 实现
每个数据提取任务都可以独立运行。下图展示在 Dask 集群中计算数据表格的过程。 根据时效 (Forecast Hour),成员 (Member) 和变量 (Field) 构建数据抽取计算任务 (FN)。 每个任务都返回一个数据记录 (Value Record),将所有数据记录组合生成数据表格 (Value Table)。 后续串行程序根据该表格计算概率值。
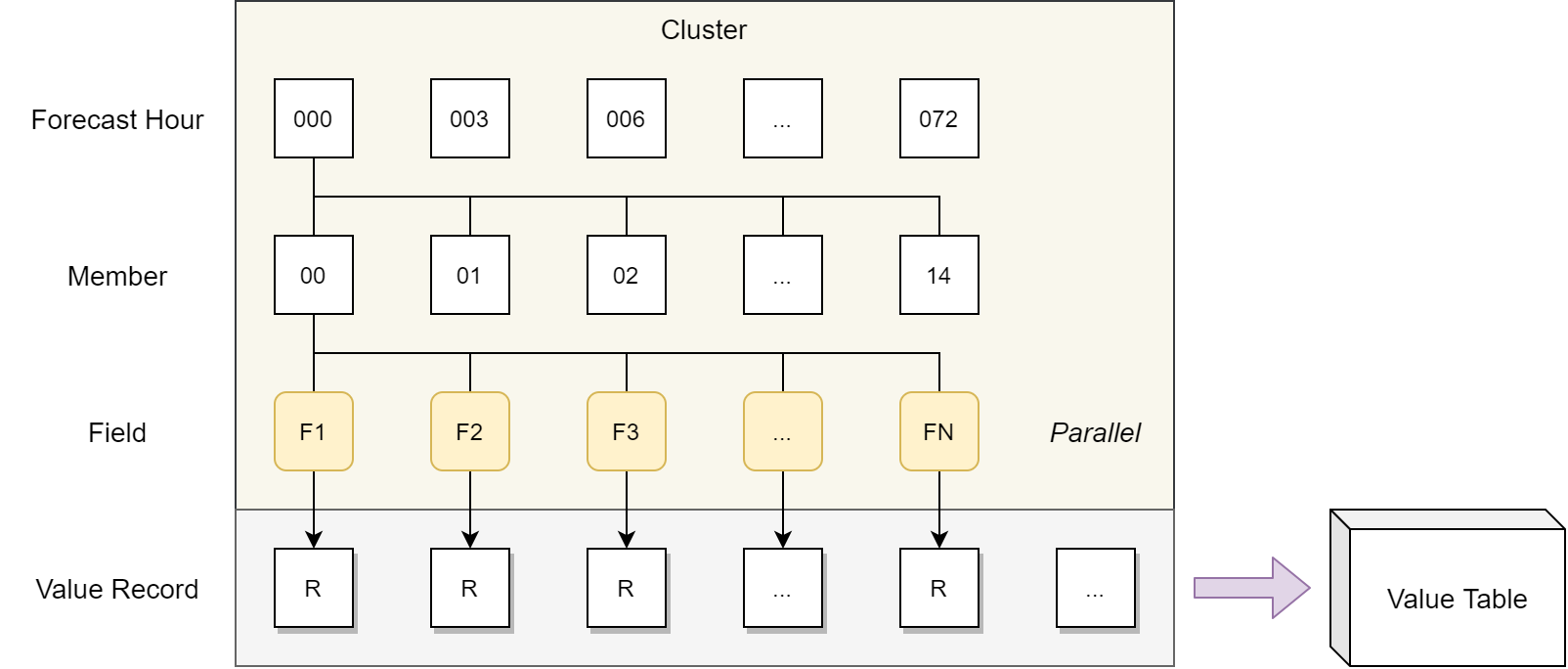
在 Dask 集群中计算概率值表格示意图
应用
目前该算法尚未在业务中实际应用,仅进行个例试验。
Dask progress 运行时间 1 分 26 秒,脚本运行时间 1 分 48 秒,共生成 8586 行表格:
forecast_time number name value
0 3 0 u10 -0.83457421875
1 3 0 v10 1.1639208984375
2 3 0 gust10 3.1947773809432984
3 3 0 t2 292.6203125
4 3 0 rh2 81.00631134033203
... ... ... ... ...
8591 240 30 gust10 1.5580632820129394
8592 240 30 t2 285.04966796875
8593 240 30 rh2 71.68885528564454
8594 240 30 vis 24135.47596359253
8595 240 30 tp 0.0
实现
分成并行和串行两个部分介绍目前试验性质的实现。
变量筛选条件
PARAMETER_LIST = [
("u10", {"parameter": "10u"}),
("v10", {"parameter": "10v"}),
("gust10", {"parameter": "GUST"}),
("t2", {"parameter": "2t"}),
("rh2", {"parameter": "2r"}),
("vis", {"parameter": "VIS"}),
]
RAIN_PARAMETER = (
"tp", {"parameter": "APCP"}
)
并行部分:提取站点数据
并行部分从 GRIB 2 数据文件中提取站点数据,结果保存到 record_list 列表中。
以 GRAPES REPS 为例,计算 3 - 72 时效,共 15 个成员
forecast_time_list = pd.to_timedelta(np.arange(3, 73, 3), unit="h")
member_list = np.arange(0, 15)
逐时效、逐要素循环,使用 get_point() 函数获取站点数据记录,保存到 record_list 列表中。
from nwpc_data.data_finder import find_local_file
for forecast_time in forecast_time_list:
previous_forecast_time = forecast_time - pd.Timedelta(hours=3)
for number in member_list:
file_path = find_local_file(
"grapes_reps/grib2/orig",
start_time=start_time,
forecast_time=forecast_time,
number=number,
data_level=("runtime", "archive")
)
previous_file_path = find_local_file(
"grapes_reps/grib2/orig",
start_time=start_time,
forecast_time=previous_forecast_time,
number=number,
data_level=("runtime", "archive")
)
for name, p in PARAMETER_LIST:
record_future = dask.delayed(get_point)(file_path, name, p, forecast_time, number)
record_list.append(record_future)
record = dask.delayed(get_rain_point)(
file_path, previous_file_path, RAIN_PARAMETER[0], RAIN_PARAMETER[1], forecast_time, number
)
record_list.append(record)
get_point() 函数从文件中提取站点要素记录,采用最近邻插值:
from nwpc_data.format.grib import load_field_from_file
from nwpc_data.operator import extract_point
def get_point(file_path, name, field_filter, forecast_time, number):
f = load_field_from_file(
file_path,
**field_filter,
)
p = extract_point(
f,
latitude=LOCATION["latitude"],
longitude=LOCATION["longitude"],
scheme="nearest"
)
return {
"forecast_time": int(forecast_time/pd.Timedelta(hours=1)),
"number": number,
"name": name,
"value": p.values,
}
完成 Dask 任务图计算,获取 record_list
def get_object(a):
return a
rl = dask.delayed(get_object)(record_list)
r = rl.persist()
progress(r)
record_list = r.compute()
生成二维表格并保存为 CSV 文件
df = pd.DataFrame(record_list)
df.to_csv(Path(output_directory, output_file_name), index=False)
串行部分:计算概率
串行部分用于从 CSV 文件保存的数据值计算概率值,阈值列表如下:
THRESHOLDS = [
("ws", 5),
("ws", 11),
("ws", 14),
("gs", 17),
("gs", 20),
("t", 5),
("r", 65),
("tp", 1),
("wis", 200),
]
读取 CSV 文件
file_path = Path(output_directory, output_file_name)
df = pd.read_csv(file_path)
获取时效列表
forecast_list = df["forecast_time"].unique()
为每个时效的每个阈值计算概率值,将每条记录保存到 forecast_data 列表中。
代码使用 query() 函数查找记录。
forecast_data = []
for index, forecast_hour in enumerate(forecast_list):
record = {
"index": index,
"forecast_hour": forecast_hour
}
for name, threshold in THRESHOLDS:
if name == "ws":
u = df.query(f'forecast_time == {forecast_hour} & name == "u10"')["value"]
v = df.query(f'forecast_time == {forecast_hour} & name == "v10"')["value"]
ws = np.sqrt(u**2 + v**2)
f = sum(ws > threshold)/len(ws) * 100
record[f"{name.upper()}{threshold}"] = f"{f:.2f}"
elif name == "gs":
gs = df.query(f'forecast_time == {forecast_hour} & name == "gust10"')["value"]
f = sum(gs > threshold) / len(gs) * 100
record[f"{name.upper()}{threshold}"] = f"{f:.2f}"
elif name == "t":
t = df.query(f'forecast_time == {forecast_hour} & name == "t2"')["value"] - 273.15
f = sum(t > threshold) / len(t) * 100
record[f"{name.upper()}{threshold}"] = f"{f:.2f}"
elif name == "r":
r = df.query(f'forecast_time == {forecast_hour} & name == "rh2"')["value"]
f = sum(r > threshold) / len(r) * 100
record[f"{name.upper()}{threshold}"] = f"{f:.2f}"
elif name == "tp":
tp = df.query(f'forecast_time == {forecast_hour} & name == "tp"')["value"]
f = sum(tp > threshold) / len(tp) * 100
record[f"{name.upper()}{threshold}"] = f"{f:.2f}"
elif name == "wis":
wis = df.query(f'forecast_time == {forecast_hour} & name == "vis"')["value"] / 1000
f = sum(wis > threshold) / len(wis) * 100
record[f"{name.upper()}{threshold}"] = f"{f:.2f}"
else:
raise ValueError(f"name is not supported: {name}")
forecast_data.append(record)
生成概率表格 prod_df
prod_df = pd.DataFrame(forecast_data)
print(prod_df)
index forecast_hour WS5 WS11 WS14 ... GS20 T5 R65 TP1 WIS200
0 0 3 0.00 0.00 0.00 ... 0.00 100.00 100.00 80.00 0.00
1 1 6 0.00 0.00 0.00 ... 0.00 100.00 100.00 20.00 0.00
2 2 9 0.00 0.00 0.00 ... 0.00 100.00 100.00 0.00 0.00
... ... ... ... ... ... ... ... ... ... ...
49 49 228 0.00 0.00 0.00 ... 0.00 100.00 100.00 0.00 0.00
50 50 234 0.00 0.00 0.00 ... 0.00 100.00 100.00 0.00 0.00
51 51 240 0.00 0.00 0.00 ... 0.00 100.00 93.55 0.00 0.00
[52 rows x 11 columns]
后续可以根据该表格生成最终的 XML 格式产品。
参考
Dask 相关文章:
Dask 应用系列文章: