Dask应用:从多个文件中抽取GRIB2要素场
本文介绍如何使用 Dask 从多个文件中并发抽取 GRIB2 要素场,按顺序合并成一个文件。
需求
GRAPES MESO 1KM 模式系统是面向 2022 北京冬奥会的业务系统,覆盖京津冀地区,每天运行 8 次,每次预报 24 小时。 与其他 GRAPES 系列模式一样,1KM 模式也逐时效生成原始 GRIB 2 数据产品 (grib2-orig),每个文件包含单个时效的所有要素场。
1KM 模式系统为冬奥会 FDP 项目生成 GRIB 2 格式的次公里网格产品 (grib2-bth),按要素分为多个文件,每个文件包含全部 25 个预报时效。 从 grib2-orig 制作 grib2-bth 产品需要从多个文件中抽取某个特定要素场,并将这些要素场按时效顺序保存为一个文件,如下图所示。
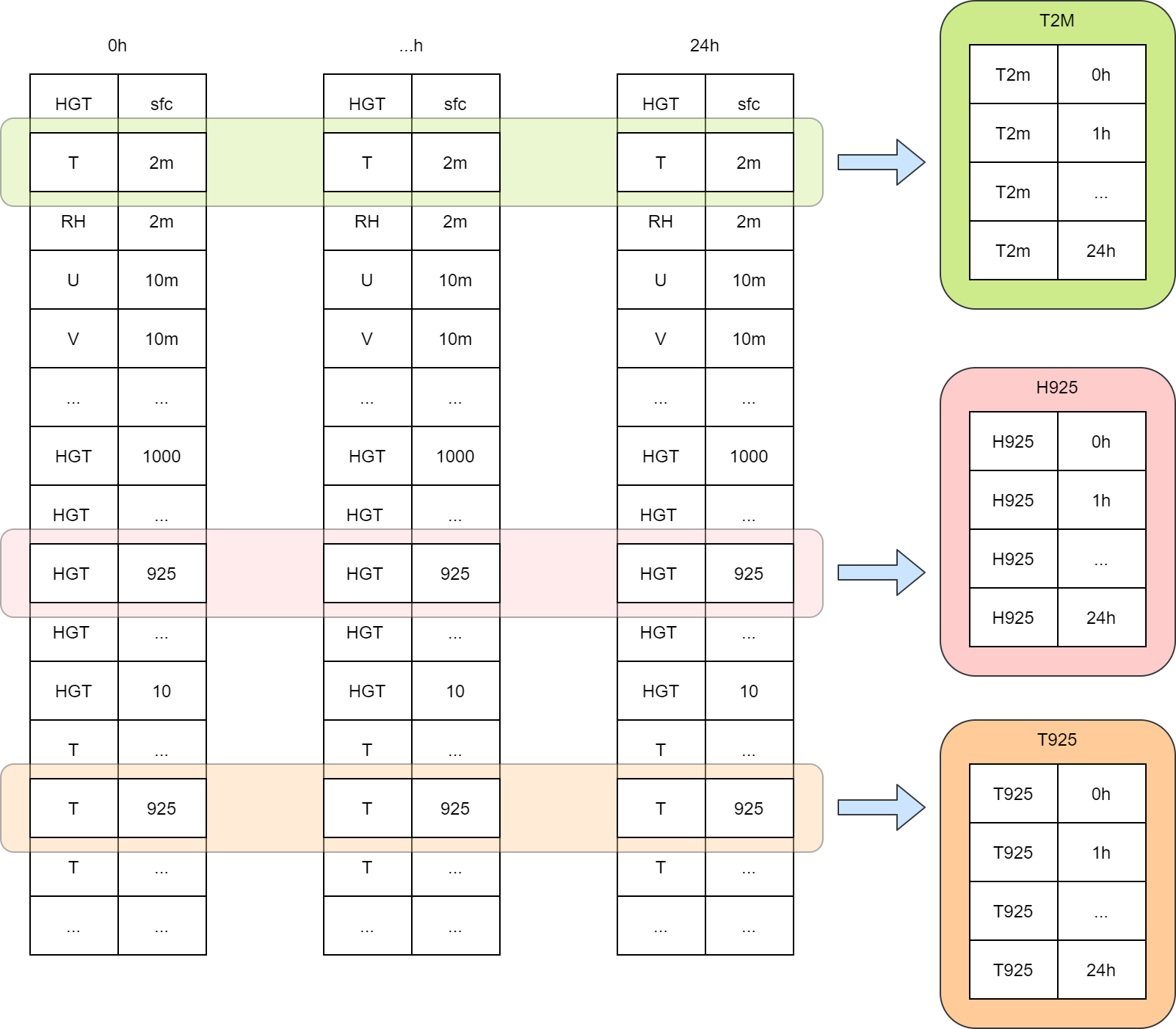
从原始 GRIB 2 数据生成 GRIB2-BTH 产品示意图,从每个单时效文件中抽取一个要素场合并成一个时间序列文件
方案
本文使用 Dask 同时从多时效文件中并发抽取所有要素,并按照时效顺序分别将各要素写入到单独的文件中。 算法如下所示。
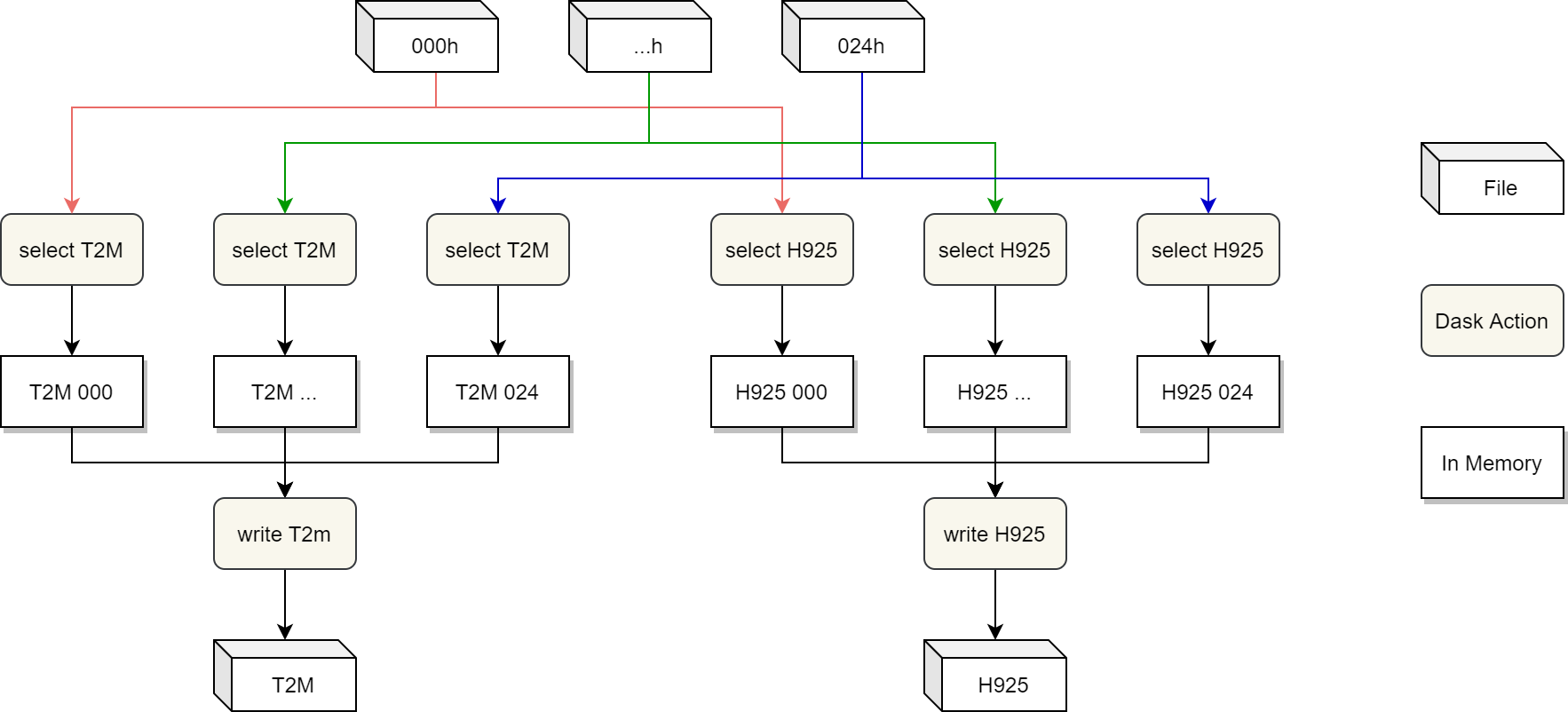
从多文件并发抽取 GRIB 2 并写入到新文件中,每个没有依赖关系的 Dask 任务都可以并发执行
实现
下面以目前在 GRAPES MESO 1KM 业务系统中实际使用的脚本为例说明上述算法如何实现。
要素筛选条件
使用 nwpc-oper/nwpc-data 库从 GRIB 2 文件中抽取要素场。
PRODUCTION_LIST 包含要素的筛选条件。
列表中每一项代表一个变量,其中:
field:要素场筛选条件,由nwpc_data.format.grib.eccodes.load_bytes_from_file函数的关键字参数构成output:用于新生成的文件名
PRODUCTION_LIST = [
{
"field": {"parameter": "HGT"},
"output": {"name": "HGT"}
},
{
"field": {"parameter": "2t"},
"output": {"name": "2T"}
},
{
"field": {"parameter": "GUST", "level": 10},
"output": {"name": "10FG1"}
},
},
{
"field": {"parameter": "t", "level_type": "surface"},
"output": {"name": "SKT"}
},
{
"field": {"parameter": {
"discipline": 0, "parameterCategory": 16, "parameterNumber": 224
}, "level_type": "surface"},
"output": {"name": "CRR"}
},
*[
{
"field": {"parameter": "r", "level_type": "pl", "level": level},
"output": {"name": f"{level}R"}
} for level in [925, 850, 800, 700, 500]
],
# ... 省略部分项目 ...
]
上面列表展示了 nwpc-data 库 GRIB 读取系列 API 支持的多种筛选方式:
变量名
- 支持 ecCodes 的
shortName(例如2t) 和 wgrib2 的大写字母变量名 (例如HGT) - 支持
discipline,parameterCategory,parameterNumber数字编码
层次
- 支持 ecCodes 的层次类型 (例如
surface) - 支持自定义层次名 (例如
pl,单位hPa)
创建 Dask 集群
在 CMA-PI HPC 的并行节点中创建 Dask 集群,详细信息请浏览《在Slurm中使用Dask》。
import dask
from dask.distributed import Client, progress
from dask_mpi import initialize
initialize(
interface="ib0",
nthreads=1,
dashboard=False
)
client = Client()
并发算法
对于每个要素 product,按时效列表 forecast_time_list 从相应文件 file_name 中读取要素场字节流 field_bytes,保存到字节流列表 field_bytes_list。
调用 write_to_file,将 field_bytes_list 中的字节数组依次写入到文件中,将生成文件路径保存到 output_files 中。
output_files = []
for product in PRODUCTION_LIST:
field = product["field"]
forecast_time_list = pd.to_timedelta(np.arange(0, 25, 1), unit="h")
field_bytes_list = []
for forecast_time in forecast_time_list:
file_name = get_grib2_file_name(start_time, forecast_time)
field_bytes = dask.delayed(load_bytes_from_file)(
Path(grib_orig_path, file_name),
**field
)
field_bytes_list.append(field_bytes)
output_file_path = dask.delayed(write_to_file)(
product, field_bytes_list, output_path
)
output_files.append(output_file_path)
构成计算图后,使用 persist() 开始计算,并使用 compute() 得到计算结果。
其中 progress 可以实时打印计算进度。
def get_output_files(output_files):
return output_files
t = dask.delayed(get_output_files)(output_files)
result = t.persist()
progress(result)
output_f = result.compute()
读取 GRIB 2 消息字节流
nwpc_data.format.grib.eccodes.load_bytes_from_file 函数根据筛选条件从 GRIB 2 文件中查找要素场并返回 GRIB 2 消息字节流。
该函数调用 eccodes.codes_get_message 函数从 GRIB 2 消息对象中获取原始字节数组 (即编码后的字节数组)。
def load_bytes_from_file(
file_path: Union[str, Path],
parameter: Union[str, Dict],
level_type: str = None,
level: int = None,
) -> Optional[bytes]:
offset = 0
fixed_level_type = fix_level_type(level_type)
with open(file_path, "rb") as f:
while True:
message_id = eccodes.codes_grib_new_from_file(f)
length = eccodes.codes_get(message_id, "totalLength")
if message_id is None:
return None
if not _check_message(message_id, parameter, fixed_level_type, level):
eccodes.codes_release(message_id)
offset += length
continue
return eccodes.codes_get_message(message_id)
写入文件
以二进制写入模式 (wb) 打开文件,将 bytes 数组 field_bytes_list 依次写入到该文件中。
def write_to_file(product, field_bytes_list, output_path):
output_name = product["output"]["name"]
output_file = Path(output_path, f"{output_name}.grb2")
with open(output_file, "wb") as f:
for field_bytes in field_bytes_list:
f.write(field_bytes)
return output_file
应用
该方法已在 GRAPES_MESO_1KM 后处理系统中应用,替换原有串行方法。
下面是 8 个时次的运行时长,使用 1 个并行节点运行。
其中 progress 时长是 Dask 任务执行耗时,脚本时长是实际作业脚本的运行时长。
脚本时长明显大于 progress 时长,增加的耗时可能来自
- 加载用户自定义 Python 环境
- 启动 Dask 集群
- 关闭 Dask 集群
我后续也会继续研究为什么各个时次运行时长不够稳定。
| 时次 | progress 时长 | 脚本时长 |
|---|---|---|
| 2021092503 | 42s | 2m11s |
| 2021092506 | 47s | 2m57s |
| 2021092509 | 40s | 2m24s |
| 2021092512 | 1m19s | 3m35s |
| 2021092515 | 39s | 2m15s |
| 2021092518 | 47s | 3m09s |
| 2021092521 | 59s | 3m47s |
| 2021092600 | 1m21s | 7m27s |
原有方案
最后简要介绍下原有方案。
原有方案使用 cat 和 wgrib2 两个命令生成 grib2-bth 产品。
该方案使用 cat 命令将多个单时效 grib2 文件合并为一个文件,再使用 wgrib2 命令从汇总文件中抽取要素场。
合并
首先对多个单时效文件进行合并,尝试两种合并方式:
第一种将单时效文件逐步合并为单一文件,如下图所示:
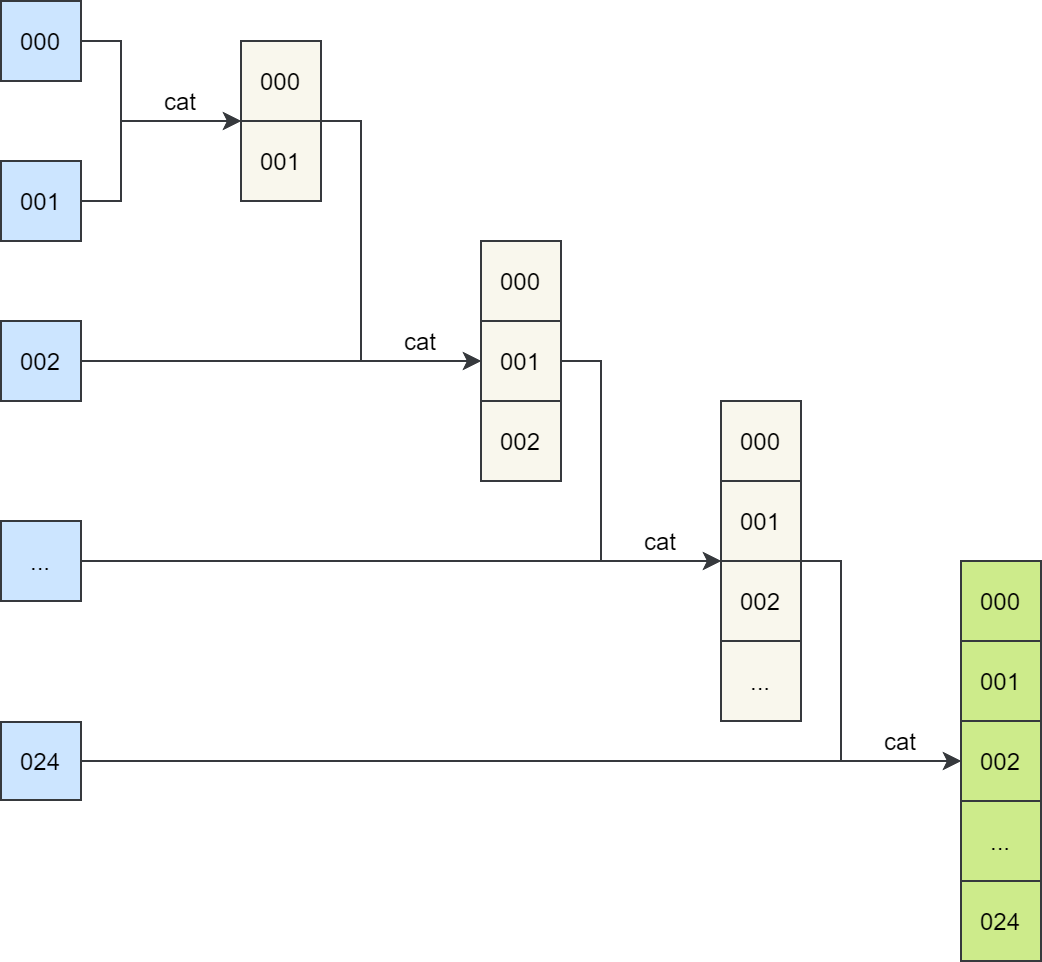
逐步 cat 方案示意图,将单时效文件逐步合并为单一文件
合并 25 个文件的任务可能运行 4 分钟,极端情况下可能需要 10 分钟。
第二种使用 cat 命令同时合并多个文件,可以将合并文件时间缩短到 10 秒以内。如下图所示:
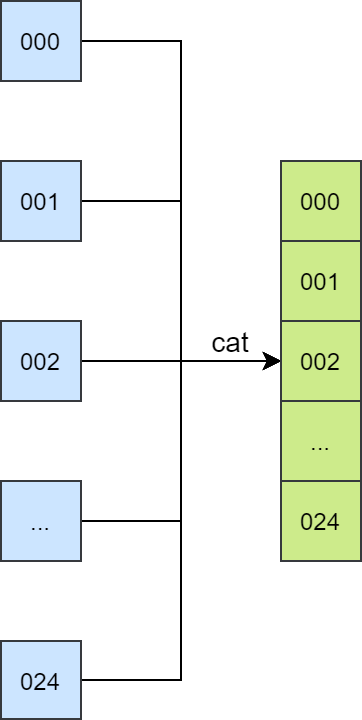
同时 cat 方案示意图,减少磁盘 IO
可以看到应该尽量避免频繁使用磁盘 IO,因为目前使用的 HPC 的 IO 速度不够稳定(仅个人感觉,未经测试)。
抽取
有了合并后的文件,就可以使用 wgrib2 从文件中提取需要的变量,grib2-bth 产品包含 53 个变量。
抽取命令如下所示:
wgrib2 ${in_file} -match ":(HGT:surface)" -grib zs_${fcst_file}
mv zs_${fcst_file} Z_NAFP_C_NWPC_${NDATE}_P_GRAPES_1KM_BTH_HGT_${init_time}00_02400060.grb2
串行抽取耗时大约 8 分钟。
参考
Dask 相关文章:
Dask 应用系列文章:
