Dask教程:分布式,高级
本文翻译自 dask-tutorial 项目
分布式 futures
from dask.distributed import Client
c = Client(n_workers=4)
c.cluster
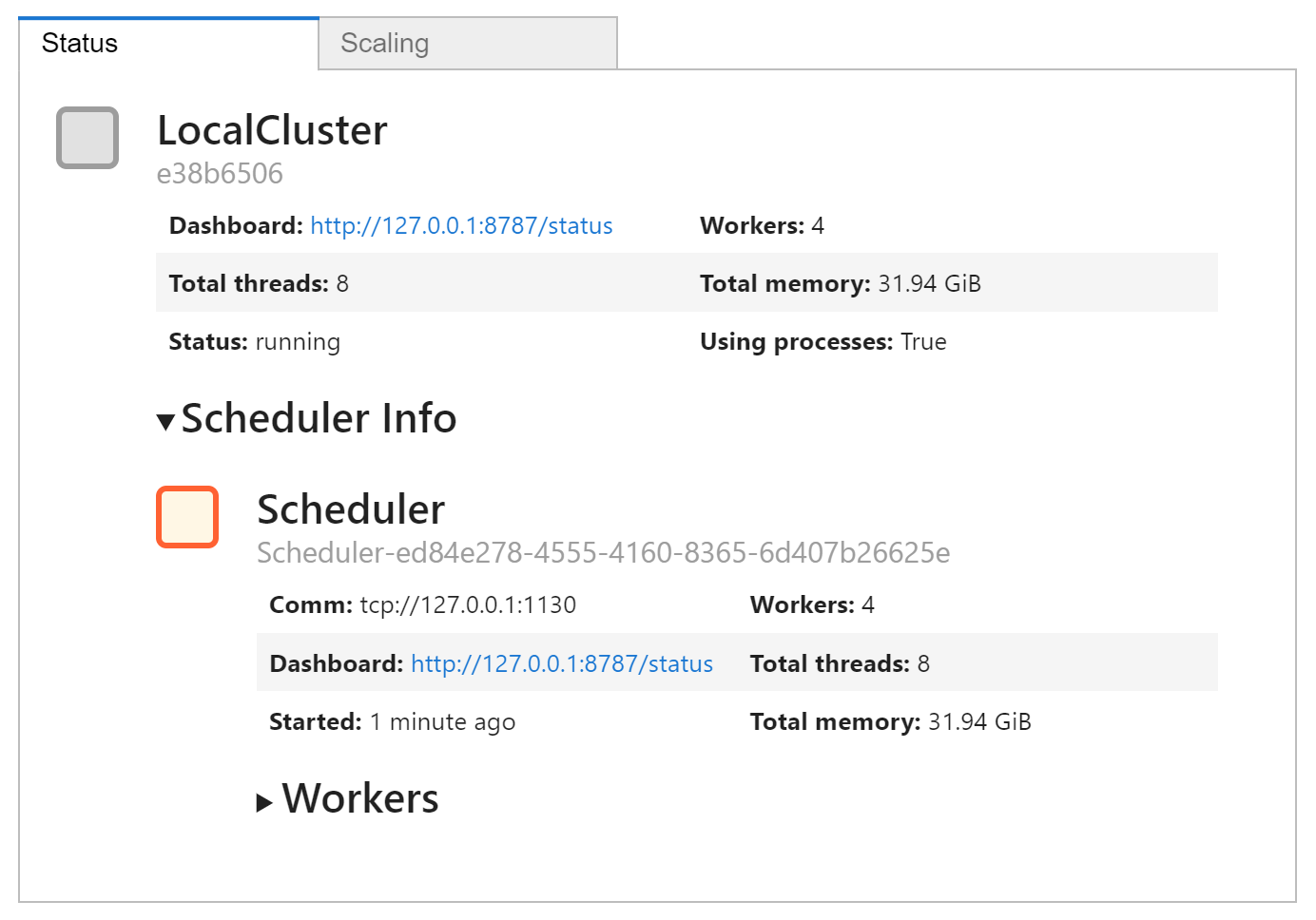
在前一章中,我们展示了使用分布式执行器执行计算 (使用 delayed 创建) 与任何其他执行器相同。
但是,我们现在可以访问其他功能,并控制内存中保存的数据。
首先,futures 接口 (源自内置的 concurrent.futures) 允许类似 map-reduce 的功能。
我们可以使用一组输入提交单个函数进行评估,或者使用 submit() 和 map() 对一系列输入进行评估。
请注意,调用立即返回,给出一个或多个 futures,其状态从 “pending” 开始,然后变为 “finished”。
没有阻塞本地 Python 会话。
这是 submit 操作的最简单示例:
def inc(x):
return x + 1
fut = c.submit(inc, 1)
fut
Future: inc status: pending, type: None, key: inc-c5c7b9feb85235b658578a98acc14b70
我们可以根据需要随时重新执行以下单元格,作为轮询 future 状态的一种方式。 这当然可以在循环中完成,在每次迭代时暂停一小段时间。 我们可以继续我们的工作,或者查看仍在进行的工作进度条,或者强制等待,直到未来准备就绪。
与此同时,状态仪表板 (上面的集群小部件旁边的链接) 在任务流中获得了一个新元素,表明 inc() 已完成,问题处的进度部分显示一个任务已完成并保存在内存中。
fut
Future: inc status: finished, type: builtins.int, key: inc-c5c7b9feb85235b658578a98acc14b70
您可以查看进度的可能替代方案:
from dask.distributed import wait, progress
progress(fut)
将在此笔记本中显示进度条,而不必转到仪表板。 这个进度条也是异步的,同时不会阻塞其他代码的执行。
wait(fut)
会阻塞并强制笔记本等待直到 fut 指向的计算完成。
但是,请注意 inc() 的结果位于集群中,现在执行计算不需要时间,因为 Dask 注意到我们正在请求它已经知道的计算结果。
稍后会详细介绍。
# 取回信息 - 如果 fut 没有准备好,这会阻塞
c.gather(fut)
# 只考虑一个 future 时的等效动作
# fut.result()
2
在这里,我们看到了在集群上执行工作的另一种方式:
当您将输入作为 future 提交或映射时,计算将移动到数据 而不是相反的方式,并且客户端在本地 Python 会话中永远不需要看到中间值。
这类似于使用 delayed 构建图,实际上,delayed 可以与 futures 结合使用。
这里我们使用之前的延迟对象 total。
# 一些需要时间的琐碎工作
# 来自分布式章节
from dask import delayed
import time
def inc(x):
time.sleep(5)
return x + 1
def dec(x):
time.sleep(3)
return x - 1
def add(x, y):
time.sleep(7)
return x + y
x = delayed(inc)(1)
y = delayed(dec)(2)
total = delayed(add)(x, y)
注意与 total.compute() 的不同。
注意下面代码立即完成
fut = c.compute(total)
fut
Future: add status: pending, type: None, key: add-f86e2138-9bb3-4eaf-8015-840e0afd2c04
c.gather(fut) # 等待直到结果生成
3
Client.submit()
submit 接受一个函数和参数,将它们推送到集群,返回一个 Future 表示要计算的结果。
该函数被传递给一个工作进程进行评估。
请注意,此单元格立即返回,而计算可能仍在集群上进行。
fut = c.submit(inc, 1)
fut
Future: inc status: pending, type: None, key: inc-993322fa7180f3b3b7cb4feb3c5ab69e
这看起来很像上面的 compute(),除了现在我们将函数和参数直接传递给集群。
对于习惯了 concurrent.futures 的人来说,这看起来很熟悉。
这个新的 fut 的行为方式与上面的相同。
请注意,我们现在已经覆盖了之前的 fut 定义,它将被垃圾收集,因此,之前的结果被集群释放
练习:改用 Client.submit 重建上述延迟计算
传递给 submit 的参数可以是来自其他提交操作或延迟对象的 future。
特别是前者,展示了 将计算转移到数据 的概念,这是使用 Dask 进行编程的最强大元素之一。
from dask import delayed
import time
def inc(x):
time.sleep(5)
return x + 1
def dec(x):
time.sleep(3)
return x - 1
def add(x, y):
time.sleep(7)
return x + y
x = c.submit(inc, 1)
y = c.submit(dec, 2)
total = c.submit(add, x, y)
total
Future: add status: pending, type: None, key: add-132b2dd01fa80047a9bde283fd14250a
c.gather(total)
3
每个 future 代表集群持有或评估的结果。 因此我们可以控制中间值的缓存 —— 当一个 future 不再被引用时,它的值就会被遗忘。 在上面的解决方案中,为每个函数调用保留 future。 如果我们选择提交更多需要它们的工作,则不需要重新评估这些结果。
我们可以使用 scatter() 显式地将数据从本地会话传递到集群中,但通常更好的是构造函数来在工作负载内部加载数据,这样就不需要序列化和通信数据。
Dask 中的大多数加载函数,例如 dd.read_csv,都是这样工作的。
类似地,我们通常不希望 gather() 在内存中太大的结果。
分布式调度器的 完整 API 提供了与集群交互的详细信息,请记住,集群可以在您的本地机器上,也可以在大规模计算资源上。
futures API 提供了一种 work submission 风格,可以轻松模拟许多人可能熟悉的 map/reduce 范式 (参见 c.map())。
由 future 代表的中间结果可以传递给新任务,而不必从集群本地拉取,并且可以将新工作分配给尚未开始的先前工作的输出。
通常,任何使用 .compute() 执行的 Dask 操作都可以使用 c.compute() 提交异步执行,这适用于所有集合。
这是之前在 Bag 章节中看到的计算示例。
我们已经用分布式客户端版本替换了那里的 .compute() 方法,因此,我们可以继续提交更多的工作 (可能基于计算结果),或者,在下一个单元格中,按照进度计算。
类似的进度条出现在监控 UI 页面中。
%run prep.py -d accounts
import dask.bag as db
import os
from pathlib import Path
import json
filename = Path("data", "accounts.*.json.gz")
lines = db.read_text(filename)
js = lines.map(json.loads)
f = c.compute(
js.filter(lambda record: record["name"] == "Alice")
.pluck("transactions")
.flatten()
.pluck("amount")
.mean()
)
from dask.distributed import progress
# 注意为了显示,进度条必须是单元格中的最后一行
progress(f)

# 获取结果
c.gather(f)
1250.3844879997416
# 通过删除 futures 来释放结果
del f, fut, x, y, total
Persist
考虑哪些数据应该由 worker 加载,而不是传递,以及哪些中间值要保留在 worker 内存中,在许多情况下将决定进程的计算效率。
在这里的例子中,我们重复了 Array 章节中的一个计算 —— 注意每次调用 compute() 的速度大致相同,因为每次都包括数据的加载。
%run prep.py -d random
import h5py
from pathlib import Path
f = h5py.File(Path("data", "random.hdf5"), mode="r")
dset = f["/x"]
import dask.array as da
x = da.from_array(dset, chunks=(1000000,))
%time x.sum().compute()
%time x.sum().compute()
Wall time: 35.4 s
Wall time: 2.66 s
999980540.0
相反,如果我们预先将数据保存到 RAM 中 (这需要几秒钟才能完成 - 我们可以在此过程中使用 wait()),那么进一步的计算会快得多。
# 将 x 从一组 delayed 处方更改为一组指向 RAM 中数据的 futures
# 在 UI 仪表板上查看此内容。
x = c.persist(x)
%time x.sum().compute()
%time x.sum().compute()
Wall time: 2.35 s
Wall time: 1.43 s
999980540.0
自然地,沿途持久化每个中间体是一个坏主意,因为这往往会填满所有可用的 RAM 并使整个系统变慢 (或崩溃!)。 理想的持久点通常是在一组数据清理步骤的末尾,此时数据处于一种经常被查询的形式。
练习:一旦我们知道我们已经完成了它,与 x 关联的内存是如何释放的?
del x
异步计算
使用 future API 的一个好处是您可以进行动态计算,随着事情的进展进行调整。 在这里,我们通过在结果进来时循环访问来实现一个简单的朴素搜索,并在其他点仍在运行时提交新点进行计算。
在此运行时观察诊断仪表板,您可以看到计算正在并发运行,同时正在提交更多计算。 这种灵活性对于需要某种程度的同步的并行算法非常有用。
让我们使用动态规划来执行一个非常简单的最小化。 感兴趣的函数称为 Rosenbrock:
# a simple function with interesting minima
import time
def rosenbrock(point):
"""
计算 resenbrock 函数,并返回点和结果
"""
time.sleep(0.1)
score = (1 - point[0])**2 + 2 * (point[1] - point[0]**2)**2
return point, score
初始设置,包括创建图形。 我们为此使用 Bokeh,它允许在结果出现时动态更新图形。
from bokeh.io import output_notebook, push_notebook
from bokeh.models.sources import ColumnDataSource
from bokeh.plotting import figure, show
import numpy as np
output_notebook()
# 设置绘图背景
N = 500
x = np.linspace(-5, 5, N)
y = np.linspace(-5, 5, N)
xx, yy = np.meshgrid(x, y)
d = (1 - xx)**2 + 2 * (yy - xx**2)**2
d = np.log(d)
p = figure(
x_range=(-5, 5),
y_range=(-5, 5)
)
p.image(
image=[d],
x=-5,
y=-5,
dw=10,
dh=10,
palette="Spectral11"
)
我们从 (0, 0) 处的一个点开始,并在其周围随机散布测试点。 每次评估需要大约 100 毫秒,随着结果的出现,我们测试是否有新的最佳点,并在搜索框缩小时在新的最佳点周围选择随机点。
每次有新的最佳值时,我们都会打印函数值和当前最佳位置。
from dask.distributed import as_completed
from random import uniform
scale = 5 # 初始随机扰动尺度
best_point = (0, 0) # 初始猜测
best_score = float("inf") # 目前最好的得分
startx = [uniform(-scale, scale) for _ in range(10)]
starty = [uniform(-scale, scale) for _ in range(10)]
# 设置绘图
source = ColumnDataSource({
"x": startx,
"y": starty,
"c": ["grey"] * 10
})
t = show(p, notebook_handle=True)
# 初始化 10 个随机点
futures = [c.submit(rosenbrock, (x, y)) for x, y in zip(startx, starty)]
iterator = as_completed(futures)
for res in iterator:
# 选择一个完成的点,是否有提高?
point, score = res.result()
if score < best_score:
beat_score, best_point = score, point
print(score, point)
x, y = best_point
newx, newy = (x + uniform(-scale, scale), y + uniform(-scale, scale))
# 更新绘图
source.stream({
"x": [newx],
"y": [newy],
"c": ["grey"]
}, rollover=20)
push_notebook(document=t)
# 添加新点,动态,在集群中工作
new_point = c.submit(rosenbrock, (newx, newy))
iterator.add(new_point) # 同样开始跟踪新任务
# 缩小搜索范围并考虑停止
scale *= 0.99
if scale < 0.001:
break
point
调试
当分布式作业出现问题时,很难弄清楚问题出在哪里以及如何处理。 当任务引发异常时,该异常将在收集该结果或依赖于它的其他结果时显示。
考虑由集群计算的以下延迟计算。 像往常一样,我们返回一个 future,集群正在计算它 (对于微不足道的过程,这发生得非常缓慢)。
from dask import delayed
@delayed
def ratio(a, b):
return a // b
ina = [5, 25, 30]
inb = [5, 5, 6]
out = delayed(sum)([ratio(a, b) for (a, b) in zip(ina, inb)])
f = c.compute(out)
f
Future: sum status: pending, type: None, key: sum-05163712-648b-41db-bd34-19ffae849ab2
我们只有在收集结果时才知道发生了什么
(这对于 out.compute() 也是如此,除非我们在此期间无法做其他事情)。
对于第一组输入,它工作正常。
c.gather(f)
11
但是如果我们引入了错误的输入,就会引发异常。
异常发生在 ratio 中,但只有在计算总和时才会引起我们的注意。
ina = [5, 25, 30]
inb = [5, 0, 6]
out = delayed(sum)([ratio(a, b) for (a, b) in zip(ina, inb)])
f = c.compute(out)
c.gather(f)
...
ZeroDivisionError: integer division or modulo by zero
这种情况下的显示使异常的来源显而易见,但情况并非总是如此。 这应该如何调试,我们将如何找出导致异常的确切条件?
当然,第一步是编写经过良好测试的代码,在出现问题时对其输入做出适当的断言并清除警告和错误消息。 这适用于所有代码。
最典型的做法是在本地线程中执行部分计算,这样我们就可以运行 Python 调试器并查询异常发生时事物的状态。 显然,在集群上处理大数据时,这不能在整个数据集上执行,但即使这样,一个合适的样本也可能会这样做。
import dask
with dask.config.set(scheduler="sync"):
# 这里不要使用 `c.compute(out)`
# 我们特别不想要分布式调度器
out.compute()
...
ZeroDivisionError: integer division or modulo by zero
# 取消注释以进入事后 (post-mortem) 调试器
# %debug
这种方法的问题在于 Dask 用于执行大型数据集/计算 —— 您可能无法简单地在一个本地线程中运行整个计算,否则您一开始就不会使用 Dask。
所以上面的代码应该只用于一小部分也表现出错误的数据。
此外,当您处理 future (例如上面的 f 或持久化之后) 而不是基于延迟的计算时,该方法将不起作用。
作为替代方案,您可以要求调度器分析您的计算并找到导致错误的特定子任务,并仅在本地拉取它及其依赖项以执行。
c.recreate_error_locally(f)
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-29-37e6c8a5bc9f> in <module>
----> 1 c.recreate_error_locally(f)
~\Anaconda3\envs\nwpc-data\lib\site-packages\distributed\recreate_exceptions.py in recreate_error_locally(self, future)
175 self.client.loop, self._recreate_error_locally, future
176 )
--> 177 func(*args, **kwargs)
<ipython-input-25-daf1cba59e73> in ratio(a, b)
3 @delayed
4 def ratio(a, b):
----> 5 return a // b
6
7 ina = [5, 25, 30]
ZeroDivisionError: integer division or modulo by zero
# 取消注释以进入事后 (post-mortem) 调试器
# %debug
> <ipython-input-2-daf1cba59e73>(5)ratio()
3 @delayed
4 def ratio(a, b):
----> 5 return a // b
6
7 ina = [5, 25, 30]
ipdb> exit
最后,当我们需要查看调度器/工作线程的状态时,还有异常以外的错误。 在我们开始的标准 “LocalCluster” 中,我们可以直接访问这些。
[
(k, v.state) for k, v
in c.cluster.scheduler.tasks.items()
if v.exception is not None
]
[('ratio-2cc06ec2-95b4-4eaa-a467-70081a00ec68', 'erred')]
结束
c.shutdown()
参考
Dask 教程
