Dask教程:数据存储
本文翻译自 dask-tutorial 项目
高效的存储可以显着提高性能,尤其是在从磁盘重复操作时。
解压文本和解析 CSV 文件的成本很高。
处理中等数据的最有效策略之一是使用二进制存储格式,如 HDF5。
通常这样做的性能提升就足够了,因此您可以再次切换回使用 Pandas 而不是使用 dask.dataframe。
在本节中,我们将学习如何以磁盘上的二进制格式有效地排列和存储数据集。 我们将使用以下内容:
- 基于 HDF5 的 Pandas
HDFStore格式 - 用于以数字方式存储文本数据的分类
主要要点
- 存储格式影响性能一个数量级
- 文本数据即使是像 HDF5 这样的快速格式也会保持缓慢
- 二进制格式、列存储和分区数据的组合将一秒的等待时间变成了 80 毫秒的等待时间
创建数据
%run prep.py -d accounts
读取 CSV
首先,我们像以前一样读取我们的 csv 数据。
CSV 和其他基于文本的文件格式是许多来源数据的最常见存储方式,因为它们需要最少的预处理,可以逐行写入并且是人类可读的。
由于 Pandas 的 read_csv 得到了很好的优化,CSV 是一个合理的输入,但远未优化,因为读取需要大量的文本解析。
from pathlib import Path
filename = Path("data", "accounts.*.csv")
filename
WindowsPath('data/accounts.*.csv')
import dask.dataframe as dd
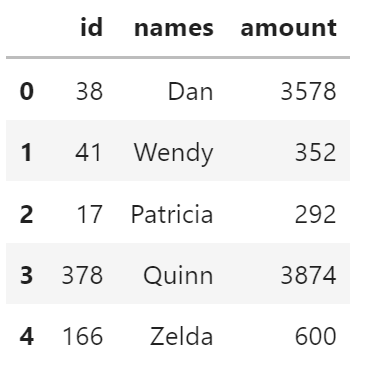
df_csv = dd.read_csv(filename)
df_csv.head()
写入到 HDF5
HDF5 和 netCDF 是科学领域中非常常用的二进制数组格式。
Pandas 包含专门的 HDF5 格式 HDFStore。
dd.DataFrame.to_hdf 方法与 pd.DataFrame.to_hdf 方法完全一样。
target = Path("data", "accounts.h5")
target
WindowsPath('data/accounts.h5')
# 转换为二进制格式,需要一些时间
%time df_csv.to_hdf(target, "/data")
Wall time: 6.4 s
['data\\accounts.h5', 'data\\accounts.h5', 'data\\accounts.h5']
# 和以前一样的数据
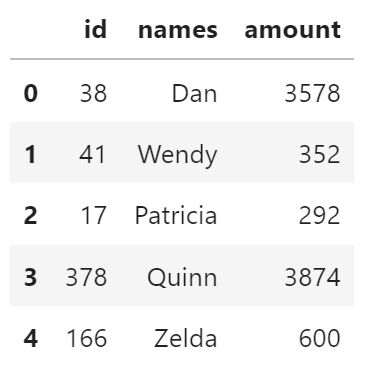
df_hdf = dd.read_hdf(target, "/data")
df_hdf.head()
比较 CSV 和 HDF5 的速度
我们做了一个简单的计算,需要读取我们数据集的一列,并比较 CSV 文件和我们新创建的 HDF5 文件之间的性能。 你期望哪个更快?
%time df_csv.amount.sum().compute()
Wall time: 513 ms
3317585728
%time df_hdf.amount.sum().compute()
Wall time: 2.42 s
3317585728
可悲的是,它们大致相同,甚至可能更慢。
这里的罪魁祸首是 names 列,它是 object 数据类型,因此难以有效存储。
这里有两个问题:
- 我们如何在磁盘上有效地存储
names等文本数据? - 当我们想要的只是
amount量时,为什么我们必须读取names
1. 使用分类有效地存储文本
我们可以使用 Pandas categoricals 用数字表示替换我们的对象数据类型。 这需要更多的时间,但会带来更好的性能。
更多关于分类的信息可以查看 Pandas 文档 和 这篇博文。
# 分类数据,然后存储到 HDFStore
%time df_hdf.categorize(columns=["names"]).to_hdf(target, "/data2")
Wall time: 8.8 s
['data\\accounts.h5', 'data\\accounts.h5', 'data\\accounts.h5']
# 看起来相同
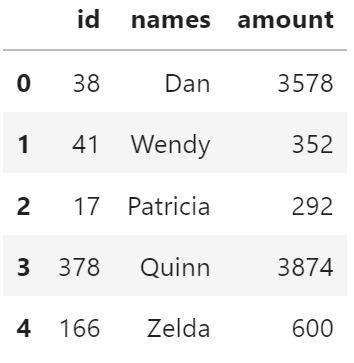
df_hdf = dd.read_hdf(target, "/data2")
df_hdf.head()
# 但是加载更快
%time df_hdf.amount.sum().compute()
Wall time: 269 ms
3317585728
这现在肯定比以前更快。 这告诉我们,不仅是我们使用的文件类型,还有我们如何表示变量也影响存储性能。
读取的性能如何取决于我们使用的调度器? 您可以尝试使用 threaded、processes 和 distributed。
然而,这仍然可以更好。
我们必须读取所有列 (names 和 amount) 才能计算 amount 的总和。
我们将使用 parquet (一种磁盘列存储) 进一步改进这一点。
首先,我们了解如何在 dask.dataframe 中设置索引。
练习
fastparquet 是一个用于与 parquet 格式文件交互的库,parquet 是大数据生态系统中非常常见的格式,被 Hadoop、Spark 和 Impala 等工具使用。
target = Path("data", "accounts.parquet")
df_csv.categorize(
columns=["names"]
).to_parquet(
target,
storage_options={
"has_nulls": True
},
engine="fastparquet"
)
查看生成的新目录中的文件结构 —— 您认为这些文件是做什么用的?
to_parquet 带有许多选项,例如压缩、是否显式写入 NULL 信息 (本例中不需要) 以及如何对字符串进行编码。
您可以试验这些,看看它们对文件大小和处理时间有什么影响,如下所示。
!DIR data\accounts.parquet\
2021/07/14 23:30 <DIR> .
2021/07/14 23:30 <DIR> ..
2021/08/17 18:09 25,002,096 part.0.parquet
2021/08/17 18:09 25,002,096 part.1.parquet
2021/08/17 18:09 25,002,096 part.2.parquet
2021/08/17 18:09 952 _common_metadata
2021/08/17 18:09 2,227 _metadata
5 个文件 75,009,467 字节
2 个目录 278,356,664,320 可用字节
df_p = dd.read_parquet(target)
# 请注意,列名称显示了值的类型 - 我们可以选择是否加载为分类列。
df_p.dtypes
id int64
names category
amount int64
dtype: object
为这个版本的数据重新运行上面的总和计算,并计算需要多长时间。 您可能想多次尝试此操作 —— 许多库在第一次调用时执行各种设置工作是很常见的。
Wall time: 66 ms
3317585728
归档数据时,通常会按具有唯一标识符的列进行排序和分区,以方便以后快速查找。
对于本文数据,该列是 id。
从原始 CSV、HDF5 和 parquet 版本以及最终从应用 set_index('id') 后编写的新 Parquet 版本检索对应于 id==100 的行所需的时间。
原始 CSV 版本
%%time
df_csv = dd.read_csv(filename)
_ = df_csv[df_csv["id"] == 100].compute()
Wall time: 612 ms
%%time
df_hdf = dd.read_hdf(Path("data", "accounts.h5"), "/data")
_ = df_hdf[df_hdf["id"] == 100].compute()
Wall time: 2.3 s
%%time
df_hdf = dd.read_parquet(Path("data", "accounts.parquet"))
_ = df_hdf[df_hdf["id"] == 100].compute()
Wall time: 151 ms
设置 id
df_p.set_index('id').to_parquet(
Path("data", "accounts.id.parquet"),
storage_options={
"has_nulls": True
},
engine="fastparquet"
)
%%time
df_test = dd.read_parquet(Path("data", "accounts.id.parquet"))
df_test.loc[df_test.index == 100].compute()
Wall time: 77 ms

远程文件
Dask 可以访问各种面向云和集群的数据存储服务,例如 Amazon S3 或 HDFS
好处:
- 可扩展的安全存储
缺点:
- 网速成为瓶颈
设置数据框 (和其他集合) 的方式与以前非常相似。
请注意,此处的数据是匿名可用的,但通常可以传递一个额外的参数 storage_options= ,其中包含有关如何与远程存储交互的更多详细信息。
taxi = dd.read_csv(
"s3://nyc-tlc/trip data/yello_tripdata_2015-*.csv",
storage_options={"anon": True}
)
警告:Internet 上的操作可能需要很长时间才能运行。 此类操作在云集群中非常有效,例如从 S3 读取的亚马逊 EC2 机器或从 GCS 读取的 Google 计算机。
参考
Dask 教程
