Dask教程:DataFrames
本文翻译自 dask-tutorial 项目
我们通过使用 dask.delayed 在 CSV 文件目录上构建并行数据框计算来完成章节 1。
在本节中,我们使用 dask.dataframe 自动构建类似的计算,用于表格计算的常见情况。
Dask 数据框的外观和感觉就像 Pandas 数据框,但它们运行在支持 dask.delayed 的相同基础架构上。
在这个笔记本中,我们使用与以前相同的航空公司数据,但现在我们让 dask.dataframe 为我们构建计算,而不是编写 for 循环。
dask.dataframe.read_csv 函数可以采用像 "data/nycflights/*.csv" 这样的匹配字符串,并一次对我们所有的数据进行并行计算。
什么时候使用 dask.dataframe
Pandas 适用于适合内存的表格数据集。
当您要分析的数据集大于机器的 RAM 时,Dask 会变得很有用。
我们正在使用的演示数据集只有大约 200 MB,因此您可以在合理的时间内下载它,但 dask.dataframe 将扩展到比内存大得多的数据集。
dask.dataframe 模块实现了一个分块并行 DataFrame 对象,它模仿了 Pandas DataFrame API 的一个很大的子集。
一个 Dask DataFrame 由许多沿索引分隔的在内存中的 Pandas DataFrame 组成。
Dask DataFrame 上的一个操作会以一种注意潜在并行性和内存限制的方式触发对组成 Pandas DataFrame 的许多 Pandas 操作。
相关文档
主要卖点
- Pandas 用户应该对 Dask DataFrame 比较熟悉
- 数据框的分区对于高效执行很重要
import dask
创建数据
%run prep.py -d flights
配置
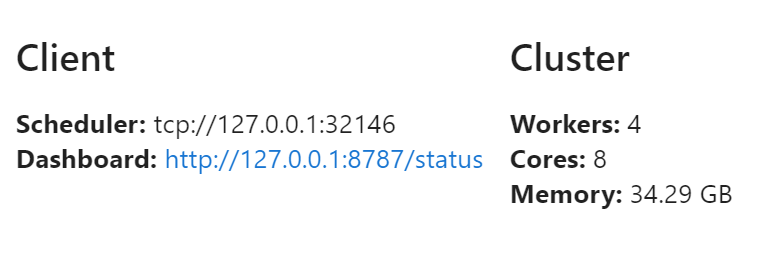
from dask.distributed import Client
client = Client(n_workers=4)
client
创建人工数据
from prep import accounts_csvs
accounts_csvs()
from pathlib import Path
filename = Path("data", "accounts.*.csv")
filename
WindowsPath('data/accounts.*.csv')
文件名包括一个通配符 *,因此路径中匹配该模式的所有文件都将读入相同的 Dask 数据框中。
import dask.dataframe as dd
df = dd.read_csv(filename)
df.head()
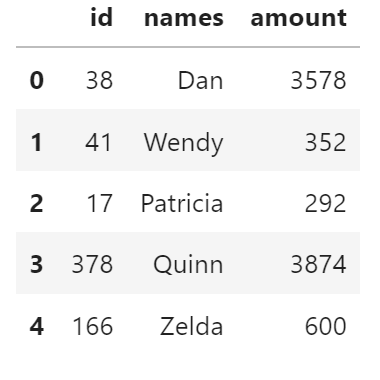
加载并统计行个数
len(df)
3000000
这里发生了什么?
- Dask 调查输入路径,发现有 3 个匹配的文件
- 为每个块智能地创建了一组作业 - 在上例中每个原始 CSV 文件一个
- 每个文件都被加载到一个 Pandas 数据框中,并对其应用
len() - subtotals 被合并为最终的总计
实际数据
让我们通过美国航班几年的摘录来尝试一下。 此数据选择从纽约市地区三个机场起飞的航班。
df = dd.read_csv(
Path("data", "nycflights", "*.csv"),
parse_dates={
"Data": [0, 1, 2]
}
)
注意数据框对象中不包含任何数据 - Dask 仅完成读取第一个文件的开头并推断列名和数据类型的工作。
df
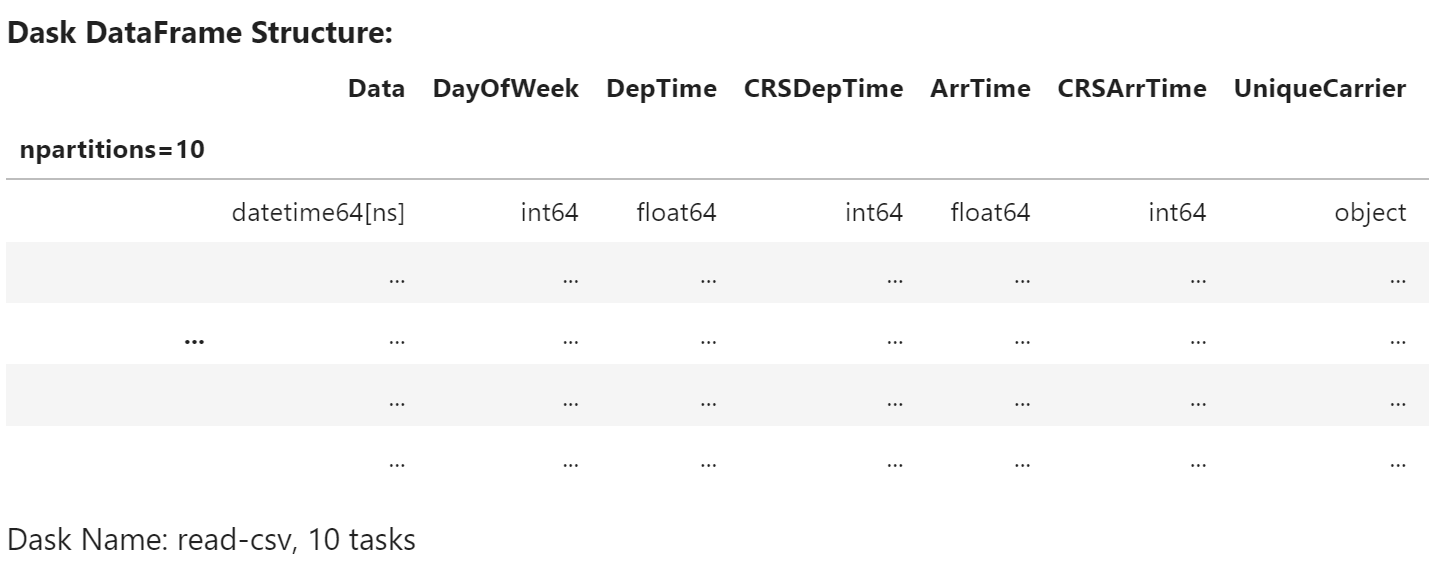
我们可以查看数据的开头和结尾
df.head()
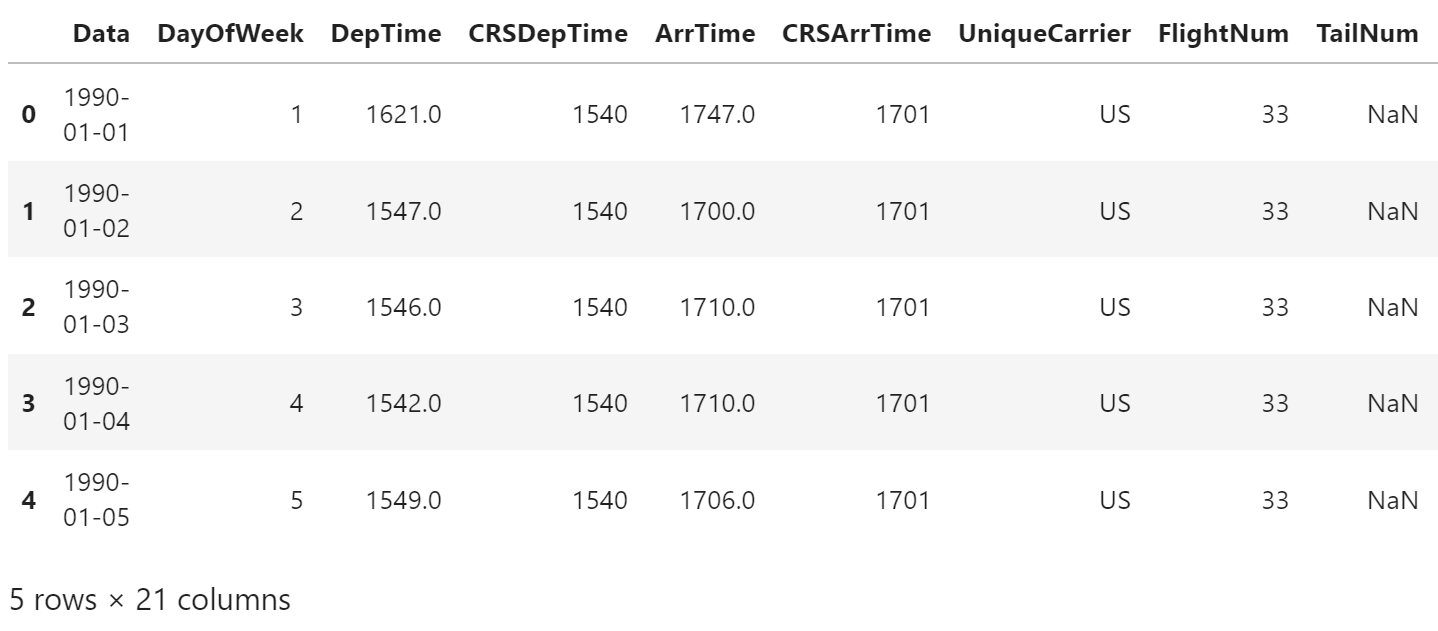
# 会失败
df.tail()
ValueError: Mismatched dtypes found in `pd.read_csv`/`pd.read_table`.
+----------------+---------+----------+
| Column | Found | Expected |
+----------------+---------+----------+
| CRSElapsedTime | float64 | int64 |
| TailNum | object | float64 |
+----------------+---------+----------+
The following columns also raised exceptions on conversion:
- TailNum
ValueError("could not convert string to float: 'N54711'")
Usually this is due to dask's dtype inference failing, and
*may* be fixed by specifying dtypes manually by adding:
dtype={'CRSElapsedTime': 'float64',
'TailNum': 'object'}
to the call to `read_csv`/`read_table`.
刚才发生了什么?
与在推断数据类型之前读取整个文件的 pandas.read_csv 不同,dask.dataframe.read_csv 仅从文件的开头 (或第一个文件,如果使用 glob) 读取样本。
然后在读取所有分区时强制执行这些推断的数据类型。
在这种情况下,样本中推断的数据类型不正确。
前 n 行没有 CRSElapsedTime 值 (pandas 将其推断为浮点数),后来变成字符串 (object dtype)。
请注意,Dask 会提供有关不匹配的信息性错误消息。
发生这种情况时,您有几个选择:
- 直接使用
dtype关键字指定 dtypes。 这是推荐的解决方案,因为它最不容易出错 (显式比隐式更好),而且性能最高。 - 增加示例关键字的大小 (以字节为单位)
- 使用
assume_missing使 dask 假设推断为int的列 (不允许缺失值) 实际上是 float (允许缺失值)。 在我们的特殊情况下,这不适用。
在我们的示例中,我们将使用第一个选项,并为违例列直接指定 dtypes。
df = dd.read_csv(
Path("data", "nycflights", "*.csv"),
parse_dates={
"Date": [0, 1, 2]
},
dtype={
"TailNum": str,
"CRSElapsedTime": float,
"Cancelled": bool
}
)
# 现在可以运行
df.tail()
使用 dask.dataframe 计算
我们计算 DepDelay 列的最大值。
仅使用 pandas,我们将遍历每个文件以找到单个最大值,然后在所有单个最大值中找到最终的最大值
maxes = []
for fn in filenames:
df = pd.read_csv(fn)
maxes.append(df.DepDelay.max())
final_max = max(maxes)
我们可以用 dask.delayed 包装 pd.read_csv 以便它并行运行。
无论如何,我们仍然需要考虑循环、中间结果 (每个文件一个) 和最终归约 (中间最大值的最大值)。
这只是实际任务周围的噪音,Pandas 解决了
df = pd.read_csv(filename, dtype=dtype)
df.DepDelay.max()
data.dataframe 让我们编写类似 Pandas 的代码,可以在大于内存的数据集上进行并行操作。
%time df.DepDelay.max().compute()
Wall time: 6.13 s
1435.0
上述代码为我们编写延迟计算,然后运行它。
一些需要注意的事情:
与
dask.delayed一样,我们需要在完成后调用.compute()。 直到这一点,一切都是延迟的。Dask 尽可能快地删除中间结果 (例如每个文件的全部 pandas 数据框)
- 这让我们可以处理大于内存的数据集
- 这也意味着重复的计算将在每次都加载全部数据 (再次运行上述代码,会比你期待的更快或更慢么?)
与 Delayed() 对象一样,可以使用 .visulize 方法查看底层任务图
# 注意并发度
df.DepDelay.max().visualize(optimize_graph=True)
练习
在本节中,我们进行一些 dask.dataframe 计算。
如果您熟悉 Pandas,那么这些应该很熟悉。
您将不得不考虑何时调用 compute。
1.) 我们的数据集中有多少行?
如果您不熟悉 Pandas,您将如何检查元组列表中有多少条记录?
len(df)
2611892
2.) 总共有多少次未取消的航班?
对于 Pandas,您将使用布尔索引。
len(df[~df["Cancelled"]])
2540961
3.) 每个机场总共有多少个未取消的航班?
提示:使用 df.groupby()
df[~df["Cancelled"]].groupby("Origin").Origin.count().compute()
Origin
EWR 1139451
JFK 427243
LGA 974267
Name: Origin, dtype: int64
4.) 每个机场的平均起飞延误是多少?
请注意,这与您在之前的笔记本中所做的计算相同 (这种方法是更快还是更慢?)
%time df.groupby("Origin").DepDelay.mean().compute()
Wall time: 2.47 s
Origin
EWR 10.295469
JFK 10.351299
LGA 7.431142
Name: DepDelay, dtype: float64
5.) 一周中哪一天的平均出发延误最严重?
%time df.groupby("DayOfWeek").DepDelay.mean().compute()
Wall time: 2.64 s
DayOfWeek
1 8.096565
2 8.149109
3 9.141912
4 10.538275
5 11.476687
6 7.824071
7 8.994296
Name: DepDelay, dtype: float64
共享中间结果
在计算上述所有内容时,我们有时会多次执行相同的操作。
对于大多数操作, dask.dataframe 散列参数,允许共享重复计算,并且只计算一次。
例如,让我们计算所有未取消航班的出发延迟的平均值和标准偏差。 由于 dask 操作是惰性的,因此这些值还不是最终结果。 它们只是获得结果所需的配方。
如果我们通过两次计算调用来计算它们,则中间计算不会共享。
non_cancelled = df[~df.Cancelled]
mean_delay = non_cancelled.DepDelay.mean()
std_delay = non_cancelled.DepDelay.std()
%%time
mean_delay_res = mean_delay.compute()
std_delay_res = std_delay.compute()
Wall time: 5.31 s
但是让我们尝试将两者传递给单一的 compute() 调用
%%time
mean_delay_res, std_delay_res = dask.compute(mean_delay, std_delay)
Wall time: 2.53 s
使用 dask.compute 大约需要 1/2 的时间。
这是因为在调用 dask.compute 时合并了两个结果的任务图,允许共享操作只执行一次而不是两次。
特别是,使用 dask.compute 仅执行以下操作一次:
- 对
read_csv的调用 - 过滤器 (
df[~df.Cancelled]) - 一些必要的归约 (
sum,count)
要查看多个结果之间合并的任务图是什么样的 (以及共享的内容),您可以使用 dask.visualize 函数 (我们可能希望使用 filename='graph.pdf' 将图形保存到磁盘,以便我们可以更容易地缩放):
dask.visualize(mean_delay, std_delay, optimize_graph=True)
这与 Pandas 相比如何?
Pandas 比 dask.dataframe 更成熟、功能更齐全。
如果您的数据适合内存,那么您应该使用 Pandas。
当您对不适合内存的数据集进行操作时,dask.dataframe 模块会为您提供有限的 Pandas 体验。
在本教程中,我们提供了一个由几个 CSV 文件组成的小数据集。 这个数据集在磁盘上有 45 MB,在内存中扩展到大约 400 MB。 该数据集足够小,您通常可以使用 Pandas。
我们选择了这个大小,以便练习快速完成。 Dask.dataframe 只有对比这大得多的问题才真正有意义,尤其是 Pandas 因可怕的下述错误而崩溃:
MemoryError: ...
此外,分布式调度器允许跨集群执行相同的数据帧表达式。
为了实现海量“大数据”处理,可以执行数据摄取功能,例如 read_csv,其中数据保存在每个工作节点(例如亚马逊的 S3)都可以访问的存储中,并且因为大多数操作从仅选择一些列开始,转换和过滤数据,机器之间只需要通信相对少量的数据。
Dask.dataframe 操作在内部使用 Pandas 操作。 除了以下两种情况外,它们通常以大致相同的速度运行:
- Dask 引入了一些开销,每个任务大约 1 毫秒。这通常可以忽略不计。
- 当 Pandas 释放 GIL 时,
dask.dataframe可以在一个进程中并行调用多个 Pandas 操作,提高速度与内核数量成正比。 对于不释放 GIL 的操作,需要多个进程才能获得相同的加速。
Dask DataFrame 数据模型
在大多数情况下,Dask DataFrame 感觉就像一个 Pandas DataFrame。 到目前为止,我们看到的最大区别是 Dask 操作是惰性的;它们建立了一个任务图而不是立即执行。 这让 Dask 可以并行执行操作。
在 Dask Arrays 中,我们看到 dask.array 由许多 NumPy 数组组成,沿着一个或多个维度分块。
它与 dask.dataframe 类似:Dask DataFrame 由许多 Pandas DataFrames 组成。
对于 dask.dataframe,分块仅沿索引发生。
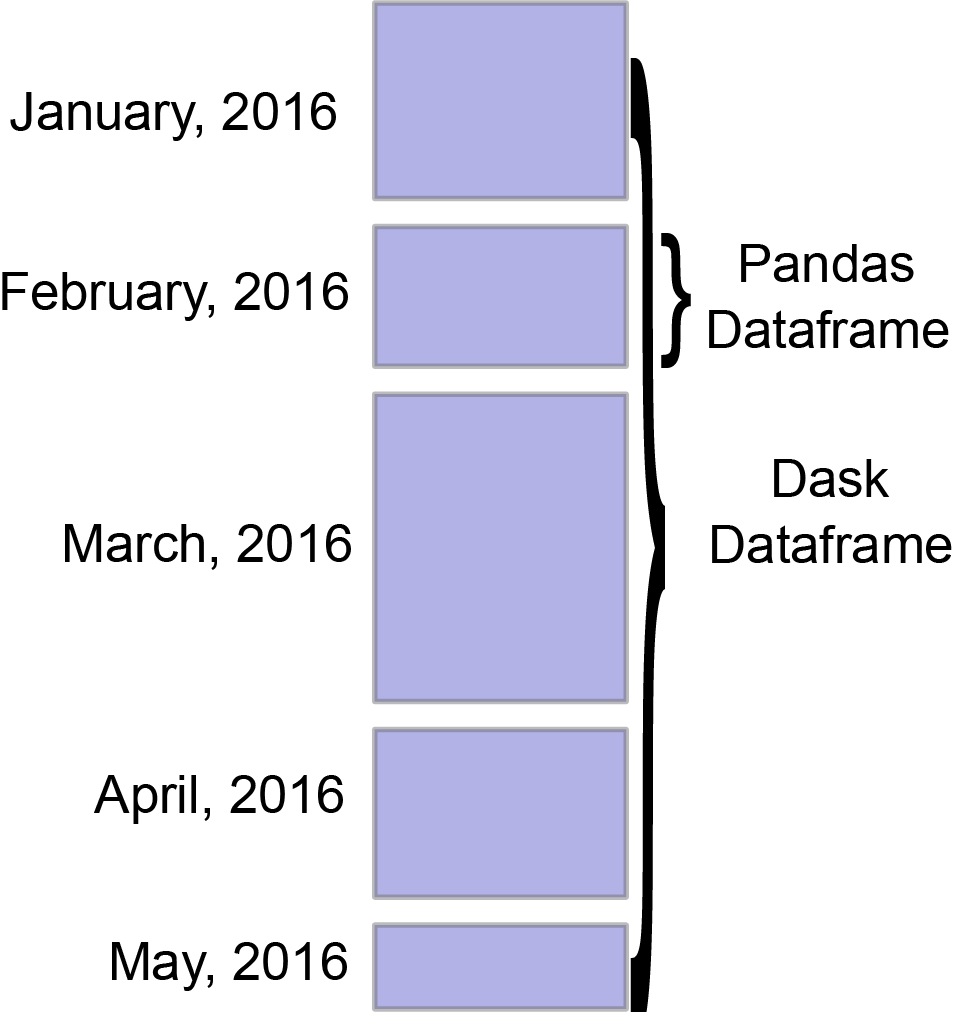
我们称每个 chunk 为一个 partition,上界/下界是 divisions。 Dask 可以存储有关 divisions 的信息。 目前,当您编写自定义函数以应用于 Dask DataFrame 时会出现 partitions。
将 CRSDepTime 转换为时间戳
该数据集将时间戳存储为 HHMM,在 read_csv 中作为整数读入:
crs_dep_time = df.CRSDepTime.head(10)
crs_dep_time
0 1540
1 1540
2 1540
3 1540
4 1540
5 1540
6 1540
7 1540
8 1540
9 1540
Name: CRSDepTime, dtype: int64
要将这些转换为预定出发时间的时间戳,我们需要将这些整数转换为 pd.Timedelta 对象,然后将它们与 Date 列组合。
在 Pandas 中,我们会使用 pd.to_timedelta 函数和一些算术来做到这一点:
import pandas as pd
# 获取前 10 个日期来补充我们的 `crs_dep_time`
date = df.Date.head(10)
# 以整数形式获取小时数,转换为时间增量
hours = crs_dep_time // 100
hours_timedelta = pd.to_timedelta(hours, unit="h")
# 以整数形式获取分钟数,转换为时间增量
minutes = crs_dep_time % 100
minutes_timedelta = pd.to_timedelta(minutes, unit="m")
# 应用 timedeltas 以按出发时间偏移日期
departure_timestamp = date + hours_timedelta + minutes_timedelta
departure_timestamp
0 1990-01-01 15:40:00
1 1990-01-02 15:40:00
2 1990-01-03 15:40:00
3 1990-01-04 15:40:00
4 1990-01-05 15:40:00
5 1990-01-06 15:40:00
6 1990-01-07 15:40:00
7 1990-01-08 15:40:00
8 1990-01-09 15:40:00
9 1990-01-10 15:40:00
dtype: datetime64[ns]
自定义代码与 Dask Dataframe
我们可以将 pd.to_timedelta 换成 dd.to_timedelta 并对整个 dask DataFrame 执行相同的操作。
但是假设 Dask 没有实现适用于 Dask DataFrames 的 dd.to_timedelta。
那你会怎么做?
dask.dataframe 提供了一些方法来更容易地将自定义函数应用于 Dask DataFrames:
map_partitionsmap_overlapreduction
在这里,我们将只讨论 map_partitions,我们可以使用它来自己实现 to_timedelta:
# 查看 `map_partitions` 文档
help(df.CRSDepTime.map_partitions)
基本思想是将一个对 DataFrame 进行操作的函数应用于每个分区。
在这种情况下,我们将应用 pd.to_timedelta。
hours = df.CRSDepTime // 100
# hours_timedelta = pd.to_timedelta(hours, unit="h")
hours_timedelta = hours.map_partitions(pd.to_timedelta, unit="h")
minutes = df.CRSDepTime % 100
# minutes_timedelta = pd.to_timedelta(minutes, unit="m")
minutes_timedelta = minutes.map_partitions(pd.to_timedelta, unit="m")
departure_timestamp = df.Date + hours_timedelta + minutes_timedelta
departure_timestamp
Dask Series Structure:
npartitions=10
datetime64[ns]
...
...
...
...
dtype: datetime64[ns]
Dask Name: add, 90 tasks
departure_timestamp.head()
0 1990-01-01 15:40:00
1 1990-01-02 15:40:00
2 1990-01-03 15:40:00
3 1990-01-04 15:40:00
4 1990-01-05 15:40:00
dtype: datetime64[ns]
练习:重写上面以使用对 map_partitions 的单次调用
这将比两个单独的调用稍微更有效,因为它减少了图中的任务数量。
def compute_departure_timestamp(df):
hours = df.CRSDepTime // 100
hours_timedelta = pd.to_timedelta(hours, unit="h")
minutes = df.CRSDepTime % 100
minutes_timedelta = pd.to_timedelta(minutes, unit="m")
departure_timestamp = df.Date + hours_timedelta + minutes_timedelta
return departure_timestamp
departure_timestamp = df.map_partitions(compute_departure_timestamp)
departure_timestamp.head()
0 1990-01-01 15:40:00
1 1990-01-02 15:40:00
2 1990-01-03 15:40:00
3 1990-01-04 15:40:00
4 1990-01-05 15:40:00
dtype: datetime64[ns]
限制
什么无法实现?
Dask.dataframe 只涵盖了 Pandas API 中一小部分但使用良好的部分。 这种限制有两个原因:
- Pandas API 是巨大的
- 有些操作真的很难并行执行 (例如排序)
此外,一些重要的操作如 set_index 可以工作,但比 Pandas 慢,因为它们包括大量的数据混洗,并且可能会写出到磁盘。
了解更多
client.shutdown()
参考
Dask 教程
