Dask教程:分布式
本文翻译自 dask-tutorial 项目
到目前为止,我们已经看到,Dask 允许您简单地构建具有依赖关系的任务图,以及在数据集合上使用函数式、Numpy 或 Pandas 语法为您自动创建图。
如果没有以并行和内存感知方式执行这些图的方法,那么这些都不会非常有用。
到目前为止,我们一直在调用 thing.compute() 或 dask.compute(thing) 而不必担心这意味着什么。
现在我们将讨论可用于该执行的选项,特别是带有附加功能的分布式调度器。
Dask 带有四个可用的调度器:
- “threaded” (aka “threading"):由线程池支持的调度器
- “processes":由进程池支持的调度器
- “single-threaded” (aka “sync"):同步调度器,适合调试
- distributed:用于在多台机器上执行图的分布式调度器,见下文
要选择其中之一进行计算,您可以在请求结果时指定,例如,
myvalue.compute(scheduler="single-threaded") # 用于调试
您也可以临时设置默认调度器
with dask.config.set(scheduler="processes"):
# 仅临时为本代码块设置
# 本代码块中所有的计算请求将使用指定的调度器
myvalue.compute()
anothervalue.compute()
或者全局设置
# 设置直至另行通知
dask.config.set(scheduler="processes")
让我们在熟悉的航班数据案例上尝试一些调度器。
准备数据
%run prep.py -d flights
构建计算图
import dask.dataframe as dd
from pathlib import Path
df = dd.read_csv(
Path("data", "nycflights", "*.csv"),
parse_dates={
"Date": [0, 1, 2]
},
dtype={
"TailNum": object,
"CRSElapsedTime": float,
"Cancelled": bool
}
)
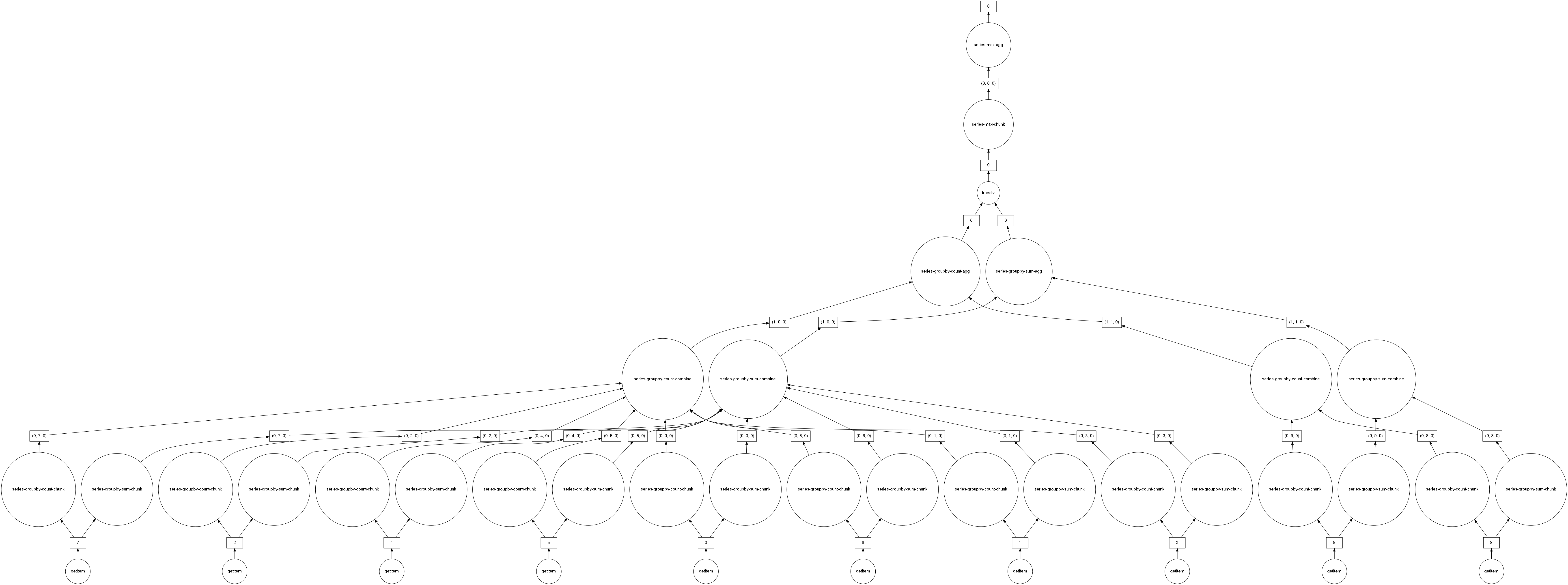
# 按机场分组的最大平均未取消延误
largest_delay = df[~df.Cancelled].groupby("Origin").DepDelay.mean().max()
largest_delay
dd.Scalar<series-..., dtype=float64>
largest_delay.visualize(optimize_graph=True)
以下每个都给出相同的结果(您可以检查!)
有什么惊喜吗?
import time
for sch in ["threading", "processes", "sync"]:
t0 = time.time()
r = largest_delay.compute(scheduler=sch)
t1 = time.time()
print(f"{sch:>10}, {t1 - t0:0.4f} s; result, {r:0.2f} hours")
threading, 8.3206 s; result, 10.35 hours
processes, 16.2249 s; result, 10.35 hours
sync, 7.8912 s; result, 10.35 hours
需要考虑的一些问题
- 此任务可以实现多少加速 (提示,请查看任务图)。
- 考虑这台机器上有多少个内核,并行调度器比单线程调度器快多少。
- 使用线程比单线程快多少? 为什么这与最佳加速不同?
- 为什么这里的多处理调度器要慢得多?
threaded 调度器是在单台机器上处理大型数据集的不错选择,只要所使用的函数大部分时间都释放 GIL。
NumPy 和 Pandas 在大多数地方都释放 GIL,因此 threaded 调度器是 dask.array 和 dask.dataframe 的默认设置。
分布式调度器 (可能带有 processes=False) 也适用于单台机器上的这些工作负载。
对于持有 GIL 的工作负载,就像 dask.bag 和用 dask.delayed 包装的自定义代码一样,我们建议使用分布式调度器,即使在单台机器上也是如此。
一般来说,它比 processes 调度器更智能并提供更好的诊断。
https://docs.dask.org/en/latest/scheduling.html 提供了一些有关选择调度器的其他详细信息。
为了跨集群扩展工作,需要分布式调度器。
创建集群
简单方法
dask.distributed 系统由单个集中式调度程序和一个或多个工作进程组成。
部署远程 Dask 集群需要一些额外的工作。
但是在本地执行只涉及创建一个 Client 对象,它允许您与“集群” (您机器上的本地线程或进程) 进行交互。
有关更多信息,请参见此处。
注意 Client() 有很多可选参数,用于配置进程/线程数、内存限制等
from dask.distributed import Client
# 创建一个本地集群
# 默认为每个核设置 1 个工作负载
client = Client()
client.cluster
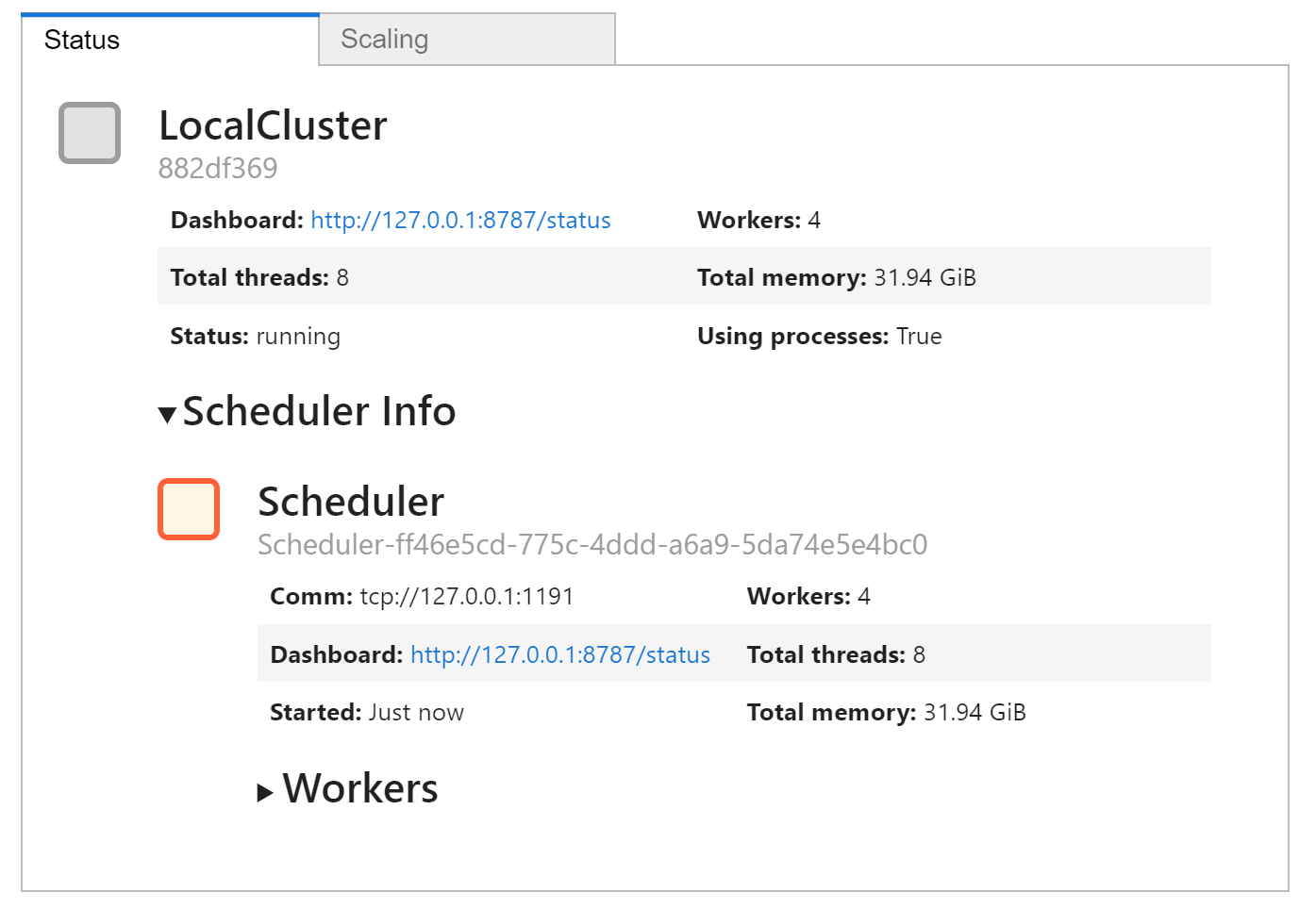
如果您不在 jupyterlab 中并使用 dask-labextension,请务必单击仪表板链接以打开诊断仪表板。
使用分布式客户端执行
考虑一些琐碎的计算,例如我们之前使用过的,我们添加了 sleep 语句以模拟正在完成的实际工作。
from dask import delayed
import time
def inc(x):
time.sleep(5)
return x + 1
def dec(x):
time.sleep(3)
return x - 1
def add(x, y):
time.sleep(7)
return x + y
默认情况下,创建 Client 将使其成为默认调度器。
任何对 .compute 的调用都将使用您的客户端所连接的集群,除非您另行指定,如上所述。
x = delayed(inc)(1)
y = delayed(dec)(2)
total = delayed(add)(x, y)
total.compute()
3
任务将在集群处理时出现在 Web UI 中,最终,结果将作为上述单元格的输出打印出来。 请注意,内核在等待结果时被阻塞。 生成的任务块图可能如下所示。 将鼠标悬停在每个块上会给出它相关的功能,以及执行所需的时间。
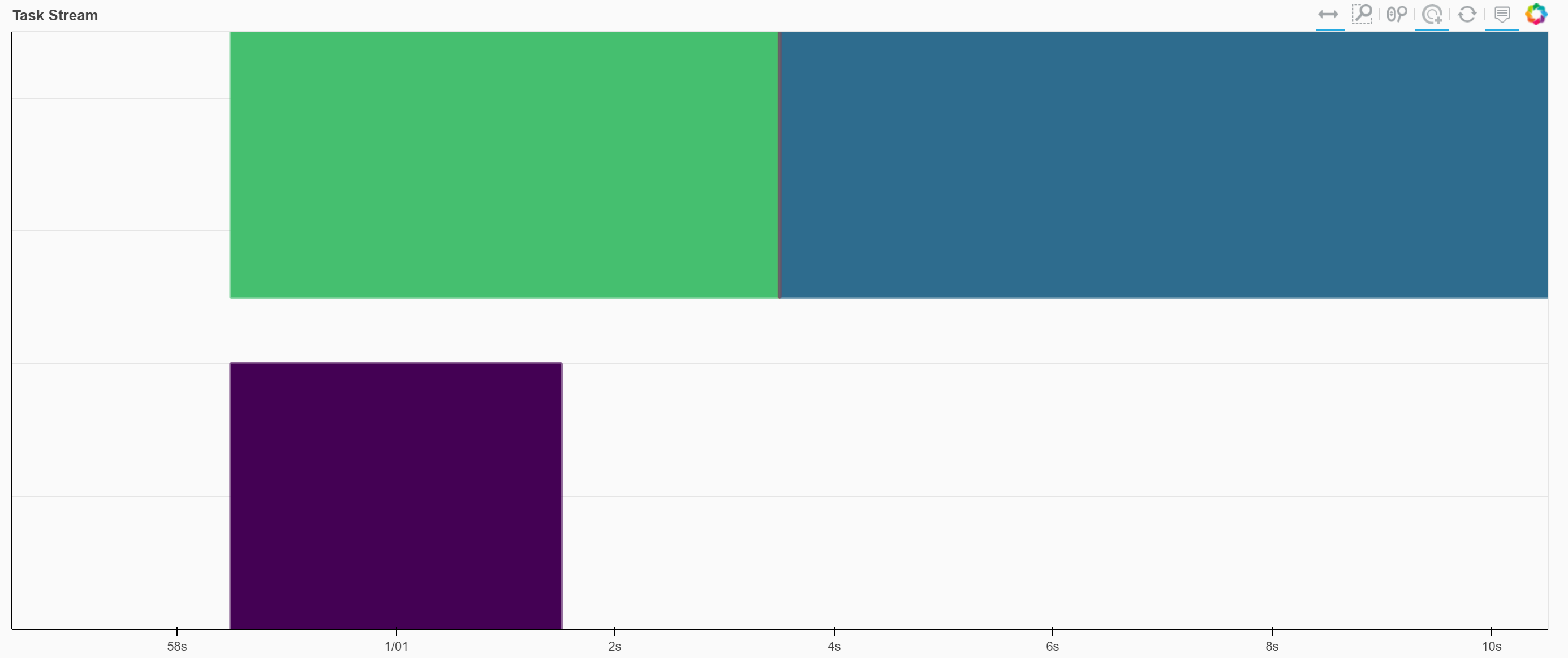
只要计算正在进行中,您还可以在仪表板的 Graph 窗格中看到正在执行的图形的简化版本。
让我们回到之前的航班计算,看看仪表板上发生了什么 (您可能希望笔记本和仪表板并排放置)。 与之前相比,这表现如何?
%time largest_delay.compute()
Wall time: 4.33 s
10.351298909519874
在这种特殊情况下,这应该与上面的最佳情况 (threading) 处理一样快或更快。 你认为这是为什么? 您应该从这里开始阅读,特别要注意分布式调度器是完全重写的,在共享中间结果以及哪些任务在哪个工作负载上运行方面具有更多智能。 在某些情况下,这将导致更好的性能,但与线程调度器相比仍然有更大的延迟和开销,因此在极少数情况下它的性能更差。 幸运的是,仪表板现在为我们提供了更多诊断信息。 查看仪表板的 Profile 页面,找出我们刚刚执行的计算占用 CPU 时间最多的部分是什么?
如果您只想执行使用 delayed 创建的计算,或者运行基于更高级别数据集合的计算,那么这就是将工作扩展到集群规模所需的全部内容。
但是,有更多关于分布式调度器的详细信息将有助于有效使用。
请参阅 Distributed, Advanced 一章。
练习
在查看诊断页面的同时运行以下计算。 在每种情况下,什么花费的时间最多?
# 航班数量
_ = len(df)
# 未取消航班的数量
_ = len(df[~df.Cancelled])
# 每个机场的未取消航班数量
_ = df[~df.Cancelled].groupby("Origin").Origin.count().compute()
# 每个机场的平均起飞延误时间
_ = df[~df.Cancelled].groupby("Origin").DepDelay.mean().compute()
# 每周平均出发延误
_ = df.groupby(df.Date.dt.dayofweek).DepDelay.mean().compute()
结束
client.close()
参考
Dask 教程
