Dask教程:Bag - 半结构化数据的并行列表
本文翻译自 dask-tutorial 项目
Dask-bag 擅长处理可以表示为任意输入序列的数据。
我们将其称为“杂乱”数据,因为它可能包含复杂的嵌套结构、缺失字段、数据类型的混合等。
函数式编程风格非常适合标准 Python 迭代,例如可以在 itertools 模块中找到。
当第一次消耗大量原始数据时,在数据处理管道的开始阶段经常会遇到凌乱的数据。
初始数据集可能是 JSON、CSV、XML 或任何其它不强制执行严格结构和数据类型的格式。
出于这个原因,最初的数据处理和处理通常是使用 Python lists、dicts 和 sets 来完成的。
这些核心数据结构针对通用存储和处理进行了优化。
使用迭代器/生成器表达式或诸如 itertools 或 toolz 之类的库添加流计算,让我们可以在小空间中处理大量数据。
如果我们将其与并行处理相结合,那么我们可以处理大量数据。
Dask.bag 是一个高层 Dask 集合,用于自动化这种形式的常见工作负载。 简而言之
dask.bag = map, filter, toolz + parallel execution
相关文档
创建数据
%run prep.py -d accounts
设置
同样,我们将使用分布式调度器。 调度器将在后面深入解释。
from dask.distributed import Client
client = Client(n_workers=4)
client
创建
可以从 Python 序列、文件、S3 上数据等创建 Bag。
我们演示使用 .take() 来显示数据元素。
执行 .take(1) 会产生一个包含一个元素的元组。
注意数据是分块的,每个块有很多项。 在第一个示例中,两个分区各包含五个元素,在接下来的两个示例中,每个文件被划分为一个或多个字节块。
import dask.bag as db
每个元素是一个整数
b = db.from_sequence(
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
npartitions=2
)
b.take(3)
(1, 2, 3)
每个元素是一个文本文件,每行是一个 JSON 对象。 注意会自动处理压缩。
from pathlib import Path
b = db.read_text(Path("data", "accounts.*.json.gz"))
b.take(1)
('{"id": 0, "name": "Jerry", "transactions": [{"transaction-id": 513, "amount": 2412}, ...)
编辑 source.py 确定源码位置
import sources
sources.bag_url
's3://dask-data/nyc-taxi/2015/yellow_tripdata_2015-01.csv'
需要 s3fs 库。
每个分区是一个远程 CSV 文本文件。
b = db.read_text(
sources.bag_url,
storage_options={"anon": True}
)
b.take(1)
('VendorID,tpep_pickup_datetime,tpep_dropoff_datetime,passenger_count,trip_distance,pickup_longitude,pickup_latitude,RateCodeID,store_and_fwd_flag,dropoff_longitude,dropoff_latitude,payment_type,fare_amount,extra,mta_tax,tip_amount,tolls_amount,improvement_surcharge,total_amount\n',)
操纵
Bag 对象包含 Python 标准库、toolz 或 pyspark 等项目中的标准函数 API,包括 map、filter、groupby 等。
对 Bag 对象的操作会创建新的 Bag。
调用 .compute() 方法来触发执行,正如我们在 Delayed 对象中看到的那样。
def is_even(n):
return n % 2 == 0
b = db.from_sequence(
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
)
c = b.filter(is_even).map(lambda x: x ** 2)
c
dask.bag<lambda, npartitions=10>
阻塞形式:等待完成 (在本例中非常快)
c.compute()
[4, 16, 36, 64, 100]
示例:账户 JSON 数据
我们在您的数据目录中创建了一个 gzip JSON 数据的假数据集。
这类似于我们稍后将看到的 DataFrame 示例中使用的示例,不同之处在于它已将每个单独 id 的所有条目捆绑到单个记录中。
这类似于您可能从文档存储数据库或 Web API 收集的数据。
每一行都是一个 JSON 编码的字典,带有以下键:
- id:顾客的唯一标识符
- name:顾客名
- transactions:
transaction-id、amount对的列表,该文件中客户的每笔交易对应一个
filename = Path("data", "accounts.*.json.gz")
lines = db.read_text(filename)
lines.take(3)
('{"id": 0, "name": "Jerry", "transactions": [{"transaction-id": 513, "amount": 2412}, ...)
我们的数据作为文本行从文件中出来。
请注意,文件解压缩是自动发生的。
我们可以通过将 json.loads 函数映射到我们的包上来使这些数据看起来更合理。
import json
js = lines.map(json.loads)
js.take(3)
({'id': 0,
'name': 'Jerry',
'transactions': [{'transaction-id': 513, 'amount': 2412},
{'transaction-id': 1789, 'amount': 2584},
{'transaction-id': 2469, 'amount': 2227},
{'transaction-id': 3114, 'amount': 3164},
...
)
基本查询
一旦我们将 JSON 数据解析为正确的 Python 对象 (dicts、lists 等),我们就可以通过创建在我们的数据上运行的小型 Python 函数来执行更有趣的查询。
filter:只保留序列的一些元素
js.filter(lambda record: record["name"] == "Alice").take(5)
({'id': 12,
'name': 'Alice',
'transactions': [{'transaction-id': 385, 'amount': 7603},
{'transaction-id': 476, 'amount': 8224},
{'transaction-id': 651, 'amount': 7991},
...
)
map:在每个元素上应用一个函数
def count_transactions(d):
return {"name": d["name"], "count": len(d["transactions"])}
(js.filter(lambda record: record["name"] == "Alice")
.map(count_transactions)
.take(5))
({'name': 'Alice', 'count': 173},
{'name': 'Alice', 'count': 370},
{'name': 'Alice', 'count': 321},
{'name': 'Alice', 'count': 126},
{'name': 'Alice', 'count': 439})
pluck:从字典中选择一个字段, element[field]
(js.filter(lambda record: record["name"] == "Alice")
.map(count_transactions)
.pluck("count")
.mean()
.compute())
221.43718079673135
使用 flatten 去嵌套
在下面的示例中,我们看到使用 .flatten() 来展平结果。
我们计算所有 Alice 的所有交易的平均金额。
(js.filter(lambda record: record["name"] == "Alice")
.pluck("transactions")
.take(3))
([{'transaction-id': 385, 'amount': 7603},
{'transaction-id': 476, 'amount': 8224},
{'transaction-id': 651, 'amount': 7991},
...
)
(js.filter(lambda record: record["name"] == "Alice")
.pluck("transactions")
.flatten()
.take(3))
({'transaction-id': 385, 'amount': 7603},
{'transaction-id': 476, 'amount': 8224},
{'transaction-id': 651, 'amount': 7991})
(js.filter(lambda record: record["name"] == "Alice")
.pluck("transactions")
.flatten()
.pluck("amount")
.take(3))
(7603, 8224, 7991)
(js.filter(lambda record: record["name"] == "Alice")
.pluck("transactions")
.flatten()
.pluck("amount")
.mean()
.compute())
1250.3844879997416
Groupby 和 Foldby
通常我们想通过一些函数或键对数据进行分组。
我们可以使用 .groupby 方法来做到这一点,该方法很简单,但会强制对数据进行完全洗牌 (昂贵),或者使用更难使用但速度更快的 .foldby 方法,该方法将 groupby 和 reduction 相结合。
groupby:混洗数据,使具有相同键的所有项目都在相同的键值对中foldby:遍历数据累积每个键的结果
注意:完整的 groupby 尤其糟糕。
在实际工作负载中,如果可能的话,最好使用 foldby 或切换到 DataFrames。
groupby
Groupby 收集您集合中的项目,以便将某些函数下具有相同值的所有项目收集在一起,形成一个键值对。
b = db.from_sequence([
"Alice",
"Bob",
"Charlie",
"Dan",
"Edith",
"Frank"
])
b.groupby(len).compute() # 按长度分组人名
[(7, ['Charlie']), (3, ['Bob', 'Dan']), (5, ['Alice', 'Edith', 'Frank'])]
b = db.from_sequence(list(range(10)))
b.groupby(lambda x: x % 2).compute()
[(0, [0, 2, 4, 6, 8]), (1, [1, 3, 5, 7, 9])]
b.groupby(lambda x: x % 2).starmap(lambda k, v: (k, max(v))).compute()
[(0, 8), (1, 9)]
foldby
起初,foldby 可能很奇怪。
它类似于其他库中的以下函数:
toolz.reducebypyspark.RDD.combineByKey
使用 foldby 时,您提供:
- 用于对元素进行分组的关键函数
- 一个二元运算符,例如您将传递给
reduce的二元运算符,用于对每个组执行归约 - 一个组合二元运算符,可以组合对数据集不同部分的两次
reduce调用的结果。
你的归约必须是可结合的。
它会在数据集的每个分区中并行发生。
然后所有这些中间结果将由 combine 二元运算符组合。
b.foldby(lambda x: x % 2, binop=max, combine=max).compute()
[(0, 8), (1, 9)]
账户数据示例
我们寻找同名的人数
groupby 版本
警告:这个需要一段时间…
%%time
result = js.groupby(
lambda item: item["name"]
).starmap(
lambda k, v: (k, len(v))
).compute()
print(sorted(result))
[('Alice', 235), ('Alice', 237), ..., ('Zelda', 550)]]
Wall time: 7.41 s
foldby 版本
这个速度相对较快,并产生相同的结果。
%%time
from operator import add
def incr(tot, _):
return tot + 1
result = js.foldby(
key="name",
binop=incr,
initial=0,
combine=add,
combine_initial=0
).compute()
print(sorted(result))
[('Alice', 979), ('Bob', 1031), ..., ('Zelda', 1100)]
Wall time: 1.76 s
练习:计算每个人名的总金额
我们希望对人名键进行 groupby (或 foldby),然后将每个人名的所有金额相加。
步骤:
- 创建一个小函数,给定类似下面的字典
{
'name': 'Alice',
'transactions': [
{'amount': 1, 'id': 123},
{'amount': 2, 'id': 456}
]
}
生成总金额,例如 3
- 稍微更改上面
foldby示例的二元运算符,以便二元运算符不计算条目数,而是累加数量的总和。
def add_amount(t, item):
for transacion in item["transactions"]:
t += transacion["amount"]
return t
result = js.foldby(
key="name",
binop=add_amount,
initial=0,
combine=add,
combine_initial=0
).compute()
print(sorted(result))
[('Alice', 271067102), ... , ('Zelda', 95401295)]
DataFrames
出于 Pandas 通常比纯 Python 更快的相同原因,dask.dataframe 可以比 dask.bag 更快。
稍后我们将更多地使用 DataFrames,但从 Bag 的角度来看,它通常是数据摄取“混乱”部分的终点 —— 一旦数据可以制成数据帧,然后进行复杂的 split-apply-combine 逻辑将变得更加直接和高效。
您可以使用 to_dataframe 方法将具有简单元组或平面字典结构的 bag 转换为 dask.dataframe。
df1 = js.to_dataframe()
df1.head()

这现在看起来像一个定义良好的 DataFrame,我们可以有效地对其应用类似 Pandas 的计算。
使用 Dask DataFrame,我们之前计算同名人数需要多长时间?
事实证明 dask.dataframe.groupby() 比 dask.bag.groupby() 高出一个数量级以上;
但对于这种情况,它仍然无法匹配 dask.bag.foldby()。
%time df1.groupby("name").id.count().compute().head()
Wall time: 2.69 s
name
Alice 979
Bob 1031
Charlie 1100
Dan 1150
Edith 600
Name: id, dtype: int64
非规则化 (Denormalization)
这种 DataFrame 格式不是最优的,因为 transactions 列填充了嵌套数据,因此 Pandas 必须恢复为 object dtype,这在 Pandas 中非常慢。
理想情况下,我们希望仅在我们将数据展平后才转换为数据帧,以便每条记录都是单个 int、string、float 等。
def denormalize(record):
# 为每个人返回一个列表,每笔交易一个项目
return [
{
"id": record["id"],
"name": record["name"],
"amount": transaction["amount"],
"transaction-id": transaction["transaction-id"]
} for transaction in record["transactions"]
]
transactions = js.map(denormalize).flatten()
transactions.take(3)
({'id': 0, 'name': 'Jerry', 'amount': 2412, 'transaction-id': 513},
{'id': 0, 'name': 'Jerry', 'amount': 2584, 'transaction-id': 1789},
{'id': 0, 'name': 'Jerry', 'amount': 2227, 'transaction-id': 2469})
df = transactions.to_dataframe()
df.head()
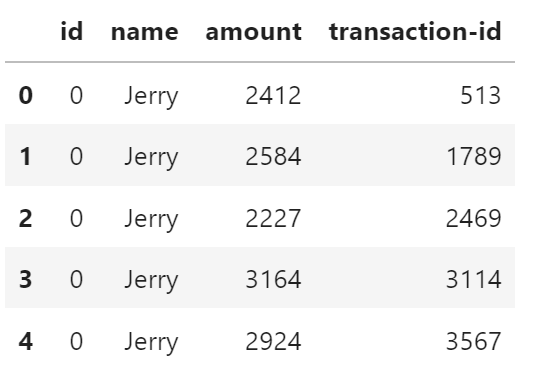
每个人名的交易数量。
请注意,这里的时间包括数据加载和摄取
%%time
df.groupby("name")["transaction-id"].count().compute()
Wall time: 4.58 s
name
Alice 216787
Bob 290576
Charlie 178297
Dan 237217
Edith 97034
Frank 98895
George 152913
Hannah 300460
Ingrid 181407
Jerry 238426
Kevin 215422
Laura 185680
Michael 166500
Norbert 107357
Oliver 207861
Patricia 172278
Quinn 214132
Ray 183470
Sarah 153870
Tim 205468
Ursula 179576
Victor 222057
Wendy 185882
Xavier 195166
Yvonne 214829
Zelda 198440
Name: transaction-id, dtype: int64
限制
Bags 提供了非常通用的计算 (任何 Python 函数)。 这种通用性是有代价的。 Bags 有以下已知限制:
- Bag 操作往往比 array/dataframe 计算慢,就像 Python 比 NumPy/Pandas 慢一样
Bag.groupby很慢。如果可能,您应该尝试使用Bag.foldby。使用Bag.foldby需要更多的思考。更好的是,考虑创建一个规范化的数据框。
学习更多
关闭
client.shutdown()
参考
Dask 教程
