Dask应用:批量转换GRIB2文件中的要素场
本文介绍如何编写 Dask 程序实现对 GRIB 2 文件中的所有要素场进行批量转换。
需求
对数值预报模式生成的 GRIB 2 数据文件进行再加工是数值预报产品后处理系统最常见的任务。 目前 NWPC 生成的很多产品都是对原始 GRIB 2 数据文件中的所有要素场进行批量转换,生成新的 GRIB 2 文件。 例如:
- GRAPES GFS 东北半球产品 (grib2-ne):裁剪区域
- GRAPES TYM 陕西气象局产品 (grib2-shaanxi):裁剪区域
这类数据产品需要保证新生成文件的要素场排序与原始文件相同。
下面首先介绍目前 NWPC 业务系统中使用的两种 GRIB 2 要素场批量处理方案,然后介绍如何使用 Dask 实现并发处理。
现有方案
目前 NWPC 在对单个 GRIB 2 文件中所有 GRIB 2 消息进行批量转换时使用两种串行程序:
- NWPC 内部程序
grib_post wgrib2
grib_post
grib_post.exe 是 NWPC 开发的内部程序。下面代码来自 GRAPES GFS 产品后处理系统中制作 grib2-ne 产品的脚本:
./gribpost.exe -s ${ORIG_DIR}/gmf.gra.${start_time}${forecast_hour}.grb2 | \
./gribpost.exe -i ${ORIG_DIR}/gmf.gra.${start_time}${forecast_hour}.grb2 \
-domain ${NLAT}:${SLAT}:${WLON}:${ELON} \
-dx 0.25 -dy 0.25 -nx 721 -ny 360 \
-grib2 ./ne_gmf.gra.${start_time}${forecast_hour}.grb2
该程序逐个转换 GRIB 2 要素场,生成 grib2-ne 的单个时效产品耗时 6 - 7 分钟。
wgrib2
wgrib2 同样可以执行区域裁剪操作。下面代码来自 GRAPES TYM 产品后处理系统中制作 grib2-shaanxi 产品的脚本:
wgrib2 ${orig_grib2_file_path} \
-small_grib ${slon}:${elon} ${slat}:${elat} \
sx_postvar_${init_time}${forecast_time}.grb2
Dask 方案
处理 GRIB 2 数据最耗时的步骤就是对 GRIB 2 消息进行 JPEG 压缩和解压缩,如果并发执行对多个消息的编解码操作,会提高数据处理的效率。 在并发执行环境中,不一定能保证各任务的执行顺序,但本文数据产品要求 GRIB 2 消息保存顺序必须与原文件保持一致。 所以必须使用额外机制确保在写入新文件时保持 GRIB 2 消息的先后顺序。
本文使用 Dask 提供的 Futures 接口保证写入操作的顺序性。 下图是并发处理单文件全部要素场的示意图。
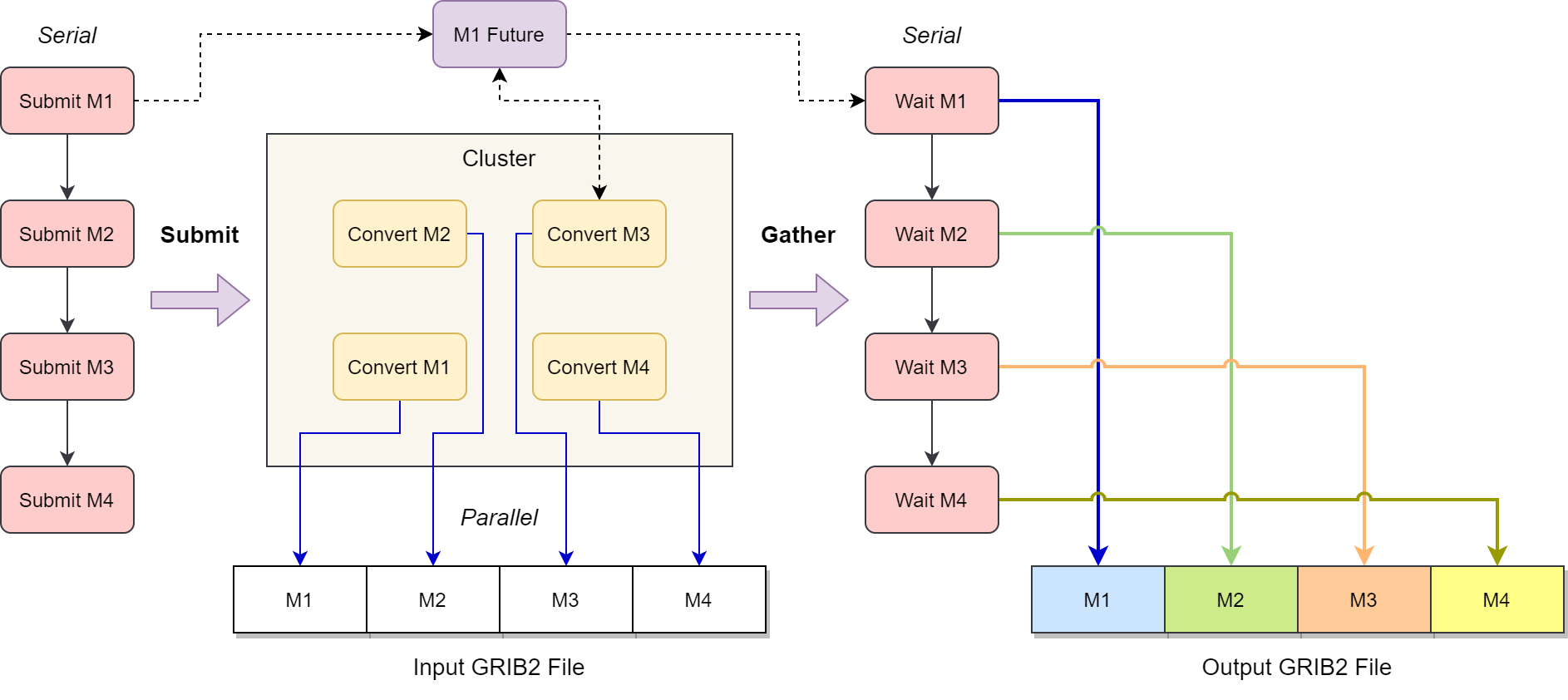
并发处理单个 GRIB 2 文件所有要素场,通过 Dask 任务的 Futures 接口保证写入消息的顺序性
整个流程可以分为三个部分:
提交转换任务。客户端 (在 MPI 环境中是一个单独的进程) 获取 GRIB 2 文件总消息数 (M1-M4,共 4 个),对每个 GRIB 2 消息 (M1),依次向 Dask 集群 (Cluster) 提交转换任务 (Convert M1),并将该转换任务的 Future 对象 (M1 Future) 按顺序保存到一个数组中。Future 对象用来监听转换任务的执行进度,在 Dask 任务运行完成后可以获取计算结果。
运行转换任务。集群中的转换任务 (Convert M1) 会根据消息序号从输入 GRIB 2 文件 (Input GRIB2 File) 中加载 GRIB 2 消息,执行区域裁剪操作,并生成新的 GRIB 2 消息编码后的字节数组。
获取转换结果并写入文件。客户端顺序遍历 Future 对象数组,等待转换任务结束,获取编码后的字节数组 (Gather),写入到新文件 (Output GRIB2 File) 中。
实现
下面仅介绍目前对上述算法的试验性质实现,尚未在业务系统中运行。
获取 GRIB 2 消息总数
使用 ecCodes Python 接口的 codes_count_in_file() 函数获取 GRIB 2 文件中 GRIB 2 消息总数:
import eccodes
with open(file_path, "rb") as f:
total_count = eccodes.codes_count_in_file(f)
提交任务
创建 Dask 集群
from dask.distributed import Client
client = Client(threads_per_worker=1)
注:如果需要在 CMA-PI HPC 的并行节点中创建 Dask 集群,请浏览《在Slurm中使用Dask》。
按 GRIB 2 消息序号,使用 client.submit() 函数向 Dask 集群提交任务 get_message_bytes,参数是文件路径 file_path 和消息序号 i。
submit() 函数返回 Dask 任务的 Future 对象 f,将其保存到数组 bytes_futures 中。
bytes_futures = []
for i in range(1, total_count+1):
f = client.submit(get_message_bytes, file_path, i)
bytes_futures.append(f)
使用 submit() 提交的任务会立即在集群中开始调度运行。
数据转换
使用 nwpc-oper/nwpc-data 库读取 GRIB 2 要素场并截取区域。
eccodes.codes_get_message() 函数返回编码后的 GRIB 2 消息字节数组对象
from nwpc_data.format.grib.eccodes import load_message_from_file
from nwpc_data.format.grib.eccodes.operator import extract_region
def get_message_bytes(
file_path,
count,
) -> bytes:
message = load_message_from_file(file_path, count=count)
message = extract_region(
message,
0, 180, 89.875, 0.125
)
message_bytes = eccodes.codes_get_message(message)
eccodes.codes_release(message)
return message_bytes
获取结果
顺序遍历任务 Future 列表 bytes_futures,使用 client.gather() 函数等待并获取编码数组,写入到新文件中。
注意需要手动删掉任务的 Future 对象 (del fut),告诉 Dask 集群删掉暂存在集群内存中的计算结果。
with open(output_file_path, "wb") as f:
for i, fut in enumerate(bytes_futures):
message_bytes = client.gather(fut)
del fut
f.write(message_bytes)
del message_bytes
参考
Dask 相关文章:
Dask 应用系列文章: