GRIB笔记:cfgrib加载GRIB2要素场速度测试
cfgrib 是由 ECMWF 基于 eccodes-python 库开发的 GRIB 格式 Python 解码库,提供兼容 xarray 的接口,是 xarray 中默认的 GRIB 解码库。
笔者在去年开始尝试使用 cfgrib,发现该库从 GRIB 文件中加载要素场的速度不如直接使用 eccodes-python 库读取要素场。 随后笔者仿照 cfgrib 开发了另一个 GRIB 格式的 xarray 接口,集成在 nwpc-oper/nwpc-data 库中。
本文延续去年的工作,测试对比使用 cfgrib 库和 eccodes-python (使用 nwpc-data 封装的接口) 加载单个 GRIB 2 要素场的速度,尝试对背后的原因进行分析。
注:本文仅单次运行测试代码,得到的时间不够精确
测试 1:文件中查找要素场
从 2021 年 1 月 1-7 日 00 时次的 GRAPES GFS 的 GRIB 2 产品 024 时效文件中抽取 850hPa 的假相当位温 (papt) 并求和。
测试环境:CMA-PI 登录节点 + 自行安装的 Python 版本。
测试方案
测试以下几种方法的运行时间:
- 使用 eccodes-python 加载:
nwpc_data.grib.eccodes.load_message_from_file() - 使用 nwpc-data 封装的 xaray 接口加载:
nwpc_data.grib.eccodes.load_field_from_file() - 使用 cfgrib 加载,不使用索引文件
- 使用 cfgrib 加载,使用索引文件
测试代码
查找数据文件路径
from nwpc_data.data_finder import find_local_file
import pandas as pd
from loguru import logger
file_list = []
for start_time in pd.date_range(start="2021-01-01", end="2021-01-07", freq="D"):
logger.info("searching for {}", start_time)
file_path = find_local_file(
data_type="grapes_gfs_gmf/grib2/orig",
start_time=start_time,
forecast_time="24h",
)
if file_path is None:
raise FileNotFoundError("grib file is not found")
file_list.append(file_path)
使用 eccodes-python 加载要素场并返回数值的函数
from nwpc_data.grib.eccodes._message import load_message_from_file
def get_values(file_path, parameter, level_type, level):
logger.info("load from {}", file_path)
message = load_message_from_file(
file_path,
parameter=parameter,
level_type=level_type,
level=level
)
logger.info("load from {}...done", file_path)
if message is None:
raise RuntimeError(f"field is None: {file_path}")
values = eccodes.codes_get_double_array(message, "values")
eccodes.codes_release(message)
return values
使用 nwpc-data 封装的 xarray 接口版本
from nwpc_data.grib.eccodes import load_field_from_file
def get_values(file_path, parameter, level_type, level):
logger.info("load from {}", file_path)
field = load_field_from_file(
file_path,
parameter=parameter,
level_type=level_type,
level=level
)
logger.info("load from {}...done", file_path)
if field is None:
raise RuntimeError(f"field is None: {file_path}")
values = field.values
return values
使用 cfgrib 不使用索引文件的版本
from nwpc_data.grib.cfgrib import load_field_from_file
def get_values(file_path, parameter, level_type, level):
logger.info("load from {}", file_path)
field = load_field_from_file(
file_path,
parameter=parameter,
level_type=level_type,
level=level
)
logger.info("load from {}...done", file_path)
if field is None:
raise RuntimeError(f"field is None: {file_path}")
values = field.values
return values
使用 cfgrib 并使用索引文件的版本
from nwpc_data.grib.cfgrib import load_field_from_file
def get_values(file_path, parameter, level_type, level):
logger.info("load from {}", file_path)
file_name = pathlib.Path(file_path).name
field = load_field_from_file(
file_path,
parameter=parameter,
level_type=level_type,
level=level,
with_index=f"/g8/JOB_TMP/wangdp/tmp/{file_name}.index"
)
logger.info("load from {}...done", file_path)
if field is None:
raise RuntimeError(f"field is None: {file_path}")
values = field.values
return values
测试主函数 test_run() 的运行时间
注:仅粗略计算函数执行前后的系统时间差,不是程序实际的运行时长
import time
a = time.time()
test_run()
b = time.time()
print(b-a)
测试结果
| 方案 | 运行时长 (s) |
|---|---|
| nwpc-data (eccodes) | 7.7 |
| nwpc-data (xarray) | 8.0 |
| cfgrib (without index) | 24.0 |
| cfgrib (with index) | 14.9 |
结果分析
使用 cfgrib 自带的索引文件能有效提高文件的加载效率,本例从 7 个文件中各读取 1 个要素场,需要时间从 24 秒降低到 15 秒。 但相对于直接使用 eccodes-python 的 nwpc-data 库版本来说,cfgrib 库版本加载单个要素场的速度较慢。 而笔者封装的 xarray 接口也得益于 eccodes-python 版本的加载速度,比 cfgrib 库更快。
测试 2:解码要素场
从 2021 年 3 月 10 日 00 时次GRAPES GFS 全球模式 GRIB 2 产品 024 时效文件中重复加载 850 hPa 温度场。
测试环境:Windwos 10 桌面电脑 + Anaconda3
注:本文仅为测试而设计,实际应用中不会重复加载同一个要素场
测试方案
测试不同方式下的耗时:
| 方案 | 是否使用索引 | 是否预加载 |
|---|---|---|
| none | 否 | 否 |
| load | 否 | 是 |
| index | 是 | 否 |
| index+load | 是 | 是 |
测试代码
加载 t 要素
注意:"indexpath": "" 表示不使用索引,删掉改行则使用索引
import xarray as xr
ds = xr.open_dataset(
data_path,
engine="cfgrib",
backend_kwargs={
"filter_by_keys": {
"shortName": "t",
"typeOfLevel": "isobaricInhPa",
},
"indexpath": ""
}
)
t = ds.t
重复加载 100 次 t850 要素场
注意:第 2 行预加载要素场
def load_fields():
t.load()
for i in range(100):
t850 = t.sel(isobaricInhPa=850)
t850.mean()
load_fields()
使用 PyCharm 的 Profile 统计函数运行时间。
测试结果
| 方案 | 主函数运行时长 (s) | load_fields() 运行时长 (s) |
|---|---|---|
| none | 13.3 | 11.1 |
| load | 6.7 | 4.4 |
| index | 11.2 | 10.9 |
| index+load | 6.0 | 4.4 |
结果分析
使用索引文件对 load_fields() 加载要素场的耗时几乎没有影响,对 xr.open_dataset() 步骤耗时的影响也有限。
但预加载要素场对 load_fields() 步骤耗时有显著的影响。
可见使用 cfgrib 库是要尽量避免对 xarray.DataArray 对象的重复筛选。
笔者推测 cfgrib 使用延迟加载方案,对于尚未加载数据的对象,每次筛选 (sel() 等方法) 返回结果都是一个全新的对象,都需要额外加载数据值。
而对于已加载数据的对象,每次筛选的返回结果会直接带有数据值。
cfgrib 解码 GRIB 2 要素场解析
上述两个测试结果与 cfgrib 内部实现有关系。
下面对测试 2 代码进行简化,来说明 cfgrib 内部的流程。
ds = xr.open_dataset(
data_path,
engine="cfgrib",
backend_kwargs={
"filter_by_keys": {
"shortName": "t",
"typeOfLevel": "isobaricInhPa",
}
}
)
t = ds.t
print(t.sel(isobaricInhPa=500).mean())
代码分为三步:
- 生成包含所有等压面温度场 (层次类型为
isobaricInhPa) 的xr.Dataset对象 - 获取温度
xr.DataArray对象 - 求 500hPa 温度场均值
下图是上述代码执行过程的示意图。
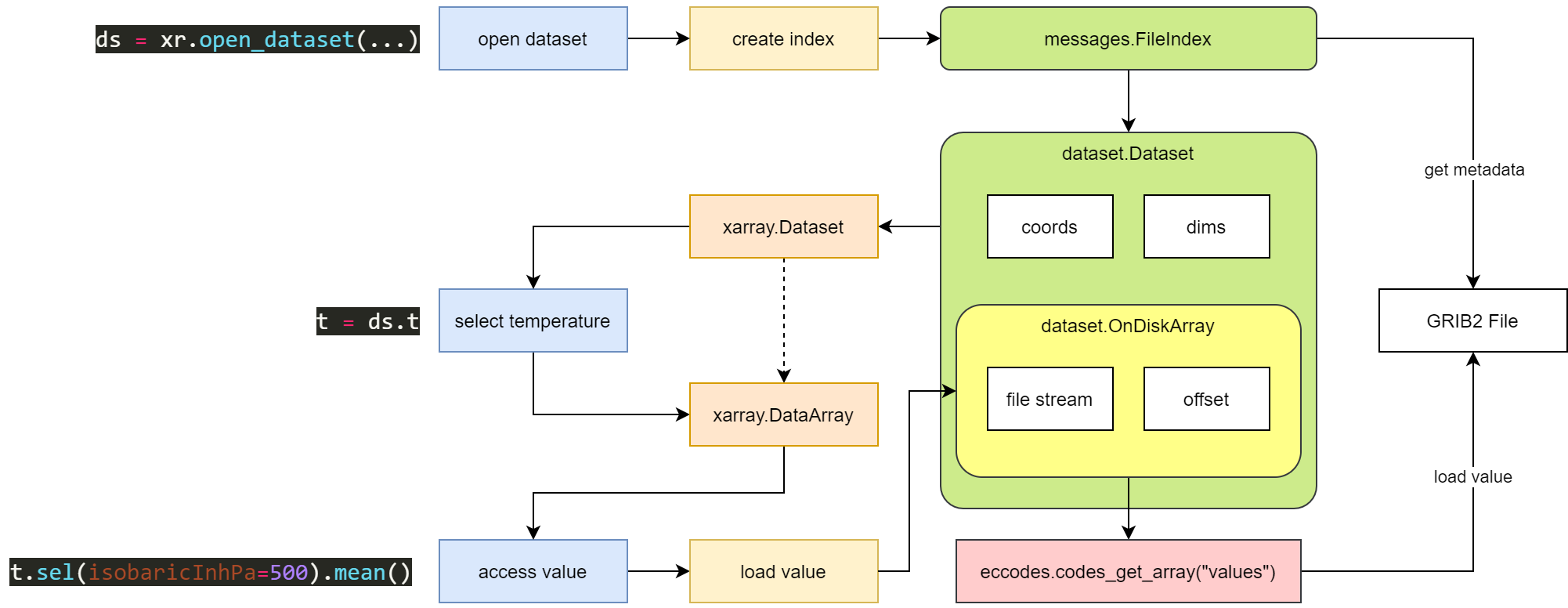
使用 cfgrib 加载 GRIB 2 要素场示意图
cfgrib 首先为整个 GRIB 2 文件生成索引信息,再根据 filter_by_keys 中的条件筛选生成新的索引信息。
cfgrib 根据索引信息生成 xr.Dataset 对象,其中数据值用 dataset.OnDiskArray 对象表示。
dataset.OnDiskArray 对象保存文件位置信息 (stream) 和要素场起始字节 (offset)。
当实际访问数据时,再重新打开文件,跳转到起始字节,使用 eccodes-python 加载要素场并解码数组。
在不使用索引文件的情况下,上述代码至少需要单独打开文件两次。
结论
GRIB 2 文件解码最耗时的部分就是解压缩 JPEG 数据。
cfgrib 将该过程延迟到实际使用数据值时再进行。
而 nwpc-data 封装的 xarray 接口在生成 xr.DataArray 时就已经加载数据值。
两种方式各有利弊。
对于本文示例所使用的仅从文件中加载单个 GRIB 2 要素场来说,nwpc-data 的方式更直接。 而如果需要使用大量的要素场,可能延迟加载更有效率,需要更进一步的对比测试。
最后,再次引用新一期技术雷达中的一个条目,建议大家尽可能使用官方开发的 API 接口。 如果想要自行维护接口,则需要时刻吸收常用库的优秀设计思想,保持更新频率。
以下内容来自由 ThoughtWorks, Inc. 出品的 Technology Radar Vol. 24
https://assets.thoughtworks.com/assets/technology-radar-vol-24-cn.pdf
自研基础设施即代码(IaC)产品
暂缓
那些由公司或社区所支持的(至少在业界引起关注的)产品,正在不断发展。 但有时组织会倾向于在现有的外部产品之上,构建框架或抽象,来满足组织内非常特定的需求,并认为这种适配会比其现有的外部产品具备更多好处。 我们发现一些组织试图基于现有外部产品,创建自研基础设施即代码(IaC)产品。 他们低估了根据其需求不断演进这些自研解决方案而所需投入的工作量。 很快他们就会意识到,所基于的外部产品的原始版本要比他们自己的产品好得多。 在有些情况下,构建在外部产品之上的抽象,甚至削弱了外部产品的原始功能。 虽然目睹过组织自研产品的一些成功案例,但是我们仍然建议要审慎地考虑这种方式。 因为这会带来不可忽视的工作量,并且需要确立长期的产品愿景,才能达到预期的结果。
参考
nwpc-oper/nwpc-data 库
https://github.com/nwpc-oper/nwpc-data