GRIB笔记:使用cfgrib加载GRIB文件
cfgrib 是 ECMWF 开发的 GRIB Python 接口,支持 Unidata’s Common Data Model v4,符合 CF Conventions。 高层 API 接口为 xarray 提供 GRIB 解码引擎。 底层访问和解码由 ECMWF 的 ecCodes 库实现。
功能
cfgrib 正在开发中,处于 Beta 版本的功能有:
- 支持 xarray 使用
engine="cfgrib"读取 GRIB文 件。 - 使用
cfgrib.open_datasets能读取大部分 GRIB 1 和 2 文件,包括包含不同层次类型的文件 - 支持所有现代 Python 版本,包括 3.9,3.8,3.7,3.6 和 PyPy3
- 支持 Python 2 的 0.9.6.x 系列将继续维护并接收重要的错误修正,
- 支持 Linux、MacOS 和 Windows,唯一的依赖是 ecCodes 的 C 库
- 所有支持的平台都可以使用 conda-forge 包安装
- 延迟和高效读取数据,节省内存占用和磁盘访问
- 允许使用 dask 进行大于内存的分布式处理
- 支持将坐标转换为不同的数据模型和命名约定
- 支持将 GRIB 文件的索引写入磁盘,以在打开时保存全文件扫描
处于 Alpha 的功能有:
- 安装
cfgrib实用程序,该程序可以将 GRIB 文件转换为to_netcdf,并可以选择将其转换为特定的坐标数据模型 - 支持将精心设计的
xarray.Dataset写入 GRIB 1 或 GRIB 2 文件
安装
推荐使用 conda 安装
conda install -c conda-forge cfgrib
如果使用中国气象局的 CMA-PI 高性能计算机,则需要手动安装。
推荐使用 apps/python/3.6.3/gnu 环境。 从 PyPi 网站中下载 cfgrib,attrs 和 cffi 三个包的 wheel 文件,将这三个包安装到本地用户目录。
例如使用下面的命令安装 cfgrib 的预编译包。
pip install cfgrib-0.9.8.5-py2.py3-none-any.whl --user
我在 CMA-PI 上的个人账户中安装了 Anaconda3 环境,也可以直接使用:
source /g1/u/wangdp/start_anaconda3.sh
conda activate nwpc-data
注:后续 env 名称可能会有变动
准备
从 ECMWF 官网下载 ERA5 的示例文件:
wget http://download.ecmwf.int/test-data/cfgrib/era5-levels-members.grib
首先载入需要用到的一些库
import xarray as xr
import cfgrib
读取示例文件
读取示例文件,返回 xarray.Dataset
data_set = xr.open_dataset(
"era5-levels-members.grib",
engine="cfgrib",
)
data_set
<xarray.Dataset>
Dimensions: (isobaricInhPa: 2, latitude: 61, longitude: 120, number: 10, time: 4)
Coordinates:
* number (number) int64 0 1 2 3 4 5 6 7 8 9
* time (time) datetime64[ns] 2017-01-01 ... 2017-01-02T12:00:00
step timedelta64[ns] ...
* isobaricInhPa (isobaricInhPa) int64 850 500
* latitude (latitude) float64 90.0 87.0 84.0 81.0 ... -84.0 -87.0 -90.0
* longitude (longitude) float64 0.0 3.0 6.0 9.0 ... 351.0 354.0 357.0
valid_time (time) datetime64[ns] ...
Data variables:
z (number, time, isobaricInhPa, latitude, longitude) float32 ...
t (number, time, isobaricInhPa, latitude, longitude) float32 ...
Attributes:
GRIB_edition: 1
GRIB_centre: ecmf
GRIB_centreDescription: European Centre for Medium-Range Weather Forecasts
GRIB_subCentre: 0
Conventions: CF-1.7
institution: European Centre for Medium-Range Weather Forecasts
history: 2020-03-16T13:44:28 GRIB to CDM+CF via cfgrib-0....
可以通过设置 backend_kwargs 中的 read_keys,增加需要读取的 GRIB key。
data_set = xr.open_dataset(
"era5-levels-members.grib",
engine="cfgrib",
backend_kwargs={
"read_keys": [
"experimentVersionNumber",
],
})
data_set.t.attrs['GRIB_experimentVersionNumber']
'0001'
过滤 GRIB 文件
xr.open_dataset() 仅能读取有同样 shortName 且能放到同一个超立方体 (hypercube) 中,即同样的要素、相同的层次类型。
GRAPES GFS 模式每个时效生成一个单一的 GRIB2 文件,包含所有要素场。
获取 GRAPES GFS 模式 GRIB 2 数据文件的路径
提示:本示例中的文件保存在 CMA-PI 高性能计算机,请在 CMA-PI 上运行或修改为本地文件路径。
from nwpc_data.data_finder import find_local_file
data_path = find_local_file(
"grapes_gfs_gmf/grib2/orig",
start_time="2021031000",
forecast_time="24h"
)
data_path
PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2021031000/ORIG/gmf.gra.2021031000024.grb2')
下面代码展示使用 xr.open_dataset 直接读取 GRIB 2 文件会抛出异常。
data_set = xr.open_dataset(
data_path,
engine="cfgrib",
backend_kwargs={
"indexpath": "",
},
)
data_set
...
DatasetBuildError: multiple values for unique key, try re-open the file with one of:
filter_by_keys={'typeOfLevel': 'surface'}
filter_by_keys={'typeOfLevel': 'nominalTop'}
filter_by_keys={'typeOfLevel': 'heightAboveGround'}
filter_by_keys={'typeOfLevel': 'atmosphere'}
filter_by_keys={'typeOfLevel': 'meanSea'}
filter_by_keys={'typeOfLevel': 'isobaricInhPa'}
filter_by_keys={'typeOfLevel': 'isobaricInPa'}
filter_by_keys={'typeOfLevel': 'depthBelowLandLayer'}
filter_by_keys={'typeOfLevel': 'heightAboveGroundLayer'}
注:默认情况下,cfgrib 会在数据文件目录下生成索引文件。
因为 data_path 指定的文件存在共享存储区,无法写入,所以这里使用 indexpath 设置索引文件的保存路径。
如果不需要索引文件,可以将 indexpath 设置为 ""
在 backend_kwargs 中的 filter_by_keys 中使用 GRIB Key 设置过滤条件。
下面的代码筛选文件中不小于 1hPa 的等压面层 ("typeOfLevel": "isobaricInhPa") 的温度场 ("shortName": "t")。
data_set = xr.open_dataset(
data_path,
engine="cfgrib",
backend_kwargs={
"indexpath": f"./{data_path.name}.index",
"filter_by_keys": {
"shortName": "t",
"typeOfLevel": "isobaricInhPa"
}
}
)
data_set
<xarray.Dataset>
Dimensions: (isobaricInhPa: 36, latitude: 720, longitude: 1440)
Coordinates:
time datetime64[ns] ...
step timedelta64[ns] ...
* isobaricInhPa (isobaricInhPa) int64 1000 975 950 925 900 850 ... 5 4 3 2 1
* latitude (latitude) float64 89.88 89.62 89.38 ... -89.38 -89.62 -89.88
* longitude (longitude) float64 0.0 0.25 0.5 0.75 ... 359.2 359.5 359.8
valid_time datetime64[ns] ...
Data variables:
t (isobaricInhPa, latitude, longitude) float32 ...
Attributes:
GRIB_edition: 2
GRIB_centre: babj
GRIB_centreDescription: Beijing
GRIB_subCentre: 0
Conventions: CF-1.7
institution: Beijing
history: 2021-03-10T12:39:33 GRIB to CDM+CF via cfgrib-0....
数据集中 t 变量就是包含 36 个层次的温度场。
t = data_set.t
t
<xarray.DataArray 't' (isobaricInhPa: 36, latitude: 720, longitude: 1440)>
[37324800 values with dtype=float32]
Coordinates:
time datetime64[ns] ...
step timedelta64[ns] ...
* isobaricInhPa (isobaricInhPa) int64 1000 975 950 925 900 850 ... 5 4 3 2 1
* latitude (latitude) float64 89.88 89.62 89.38 ... -89.38 -89.62 -89.88
* longitude (longitude) float64 0.0 0.25 0.5 0.75 ... 359.2 359.5 359.8
valid_time datetime64[ns] ...
Attributes: (12/29)
GRIB_paramId: 130
GRIB_shortName: t
GRIB_units: K
GRIB_name: Temperature
GRIB_cfName: air_temperature
GRIB_cfVarName: t
... ...
GRIB_jScansPositively: 0
GRIB_latitudeOfFirstGridPointInDegrees: 89.875
GRIB_latitudeOfLastGridPointInDegrees: -89.875
long_name: Temperature
units: K
standard_name: air_temperature
选择 850hPa 的温度场。
t.sel(isobaricInhPa=850)
<xarray.DataArray 't' (latitude: 720, longitude: 1440)>
[1036800 values with dtype=float32]
Coordinates:
time datetime64[ns] ...
step timedelta64[ns] ...
isobaricInhPa int64 850
* latitude (latitude) float64 89.88 89.62 89.38 ... -89.38 -89.62 -89.88
* longitude (longitude) float64 0.0 0.25 0.5 0.75 ... 359.2 359.5 359.8
valid_time datetime64[ns] ...
Attributes: (12/29)
GRIB_paramId: 130
GRIB_shortName: t
GRIB_units: K
GRIB_name: Temperature
GRIB_cfName: air_temperature
GRIB_cfVarName: t
... ...
GRIB_jScansPositively: 0
GRIB_latitudeOfFirstGridPointInDegrees: 89.875
GRIB_latitudeOfLastGridPointInDegrees: -89.875
long_name: Temperature
units: K
standard_name: air_temperature
使用 xarray 自带的绘图功能
t.sel(isobaricInhPa=850).plot.contourf(
size=5,
aspect=2,
cmap="coolwarm",
levels=20
)
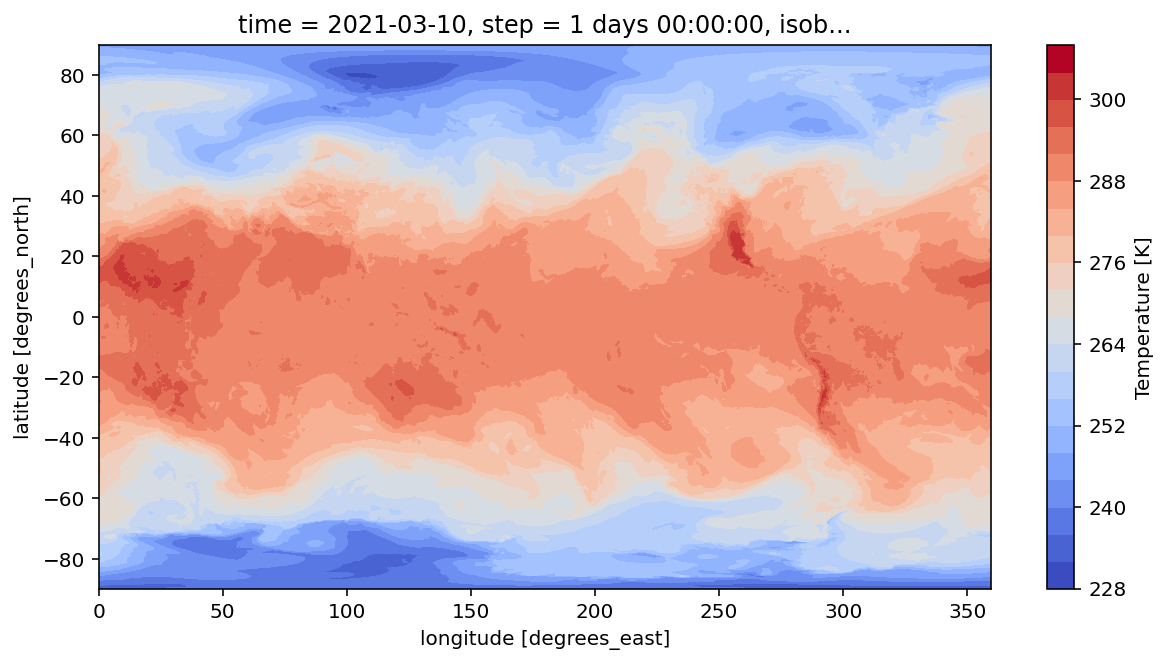
使用 xarray 绘制 850hPa 温度场
自动过滤
cfgrib 提供 open_datasets() 函数用于自动选择合适的 filter_by_keys 并返回所有有效的 xarray.Dateset 列表。
下面代码载入整个时效的文件,运行速度很慢。
data_set = cfgrib.open_datasets(
data_path,
engine="cfgrib",
backend_kwargs={
"indexpath": "",
},
)
data_set
截取一段返回结果,可以看到返回结果中将层次类型为 surface 的变量放到同一个 xarray.Dataset 中。
[
...
<xarray.Dataset>
Dimensions: (latitude: 720, longitude: 1440)
Coordinates:
time datetime64[ns] 2021-03-10
step timedelta64[ns] 1 days
surface int64 0
* latitude (latitude) float64 89.88 89.62 89.38 ... -89.38 -89.62 -89.88
* longitude (longitude) float64 0.0 0.25 0.5 0.75 ... 359.2 359.5 359.8
valid_time datetime64[ns] 2021-03-11
Data variables: (12/23)
paramId_0 (latitude, longitude) float32 ...
t (latitude, longitude) float32 ...
sp (latitude, longitude) float32 ...
slhf (latitude, longitude) float32 ...
ssr (latitude, longitude) float32 ...
str (latitude, longitude) float32 ...
... ...
ulwrf (latitude, longitude) float32 ...
sx (latitude, longitude) float32 ...
hflux (latitude, longitude) float32 ...
uswrf_cs (latitude, longitude) float32 ...
dlwrf_cs (latitude, longitude) float32 ...
al (latitude, longitude) float32 ...
Attributes:
GRIB_edition: 2
GRIB_centre: babj
GRIB_centreDescription: Beijing
GRIB_subCentre: 0
Conventions: CF-1.7
institution: Beijing ,
...
]
文件访问
cfgrib 存储从 GRIB 2 文件中筛选的要素场的元数据和索引信息,包括文件路径,消息起始偏移量。
每次读取数据时需要打开文件并加载 GRIB 2 消息场并获取要素场值 (values)。
例如下面的代码在执行 print 语句时会两次打开文件并加载相同的要素场
ds = xr.open_dataset(
data_path,
engine="cfgrib",
backend_kwargs={
"filter_by_keys": {
"shortName": "t",
"typeOfLevel": "isobaricInhPa",
}
}
)
t = ds.t
print(t.sel(isobaricInhPa=850).mean())
print(t.sel(isobaricInhPa=850).mean())
如果将 t.sel(isobaricInhPa=850) 赋值给单独的变量 (例如 t850),那么仅会在第一次访问时会从文件中载入要素场值。
注:可能每次调用
t.sel()函数生成新的对象
ds = xr.open_dataset(
data_path,
engine="cfgrib",
backend_kwargs={
"filter_by_keys": {
"shortName": "t",
"typeOfLevel": "isobaricInhPa",
}
}
)
t = ds.t
t850 = t.sel(isobaricInhPa=850)
print(t850.mean())
print(t850.mean())
可以使用 xr.Dataset 和 xr.DataArray 的 load() 方法将所有相关要素场全部加载到内容中,这样在后续访问时就不会再次访问文件。
例如下面的代码使用 t.load() 将所有场的值加载到内存中,后续在 print() 语句中的数据访问操作就不会读取文件。
ds = xr.open_dataset(
data_path,
engine="cfgrib",
backend_kwargs={
"filter_by_keys": {
"shortName": "t",
"typeOfLevel": "isobaricInhPa",
}
}
)
t = ds.t
t.load()
print(t.sel(isobaricInhPa=850).mean())
print(t.sel(isobaricInhPa=850).mean())
print(t.sel(isobaricInhPa=500).mean())
如果数据操作需要重复访问相同的要素场,一定要考虑是否会发生不必要的文件重复读取。
高级特性
cfgrib 的 engine 支持 xarray 的所有只读特性,例如:
- 使用
xarray.open_mddataset()将多个 GRIB 文件合并到一个单一的 dataset - 使用 dask 处理大于内存的数据集
- 使用 dask.distributed 进行分布式处理
后续会研究如何使用这些特性。
另外 cfgrib 还支持写入 GRIB 文件等特性。
