ISLR实验:子集选择方法
本文源自《统计学习导论:基于R语言应用》(ISLR) 中《6.5 实验1:子集选择方法》章节
介绍筛选预测变量子集的几种方法
library(ISLR)
library(leaps)
数据
棒球数据集,使用若干与棒球运动员上一年比赛成绩相关的变量来预测该运动员的薪水 (Salary)
head(Hitters)
AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits
-Andy Allanson 293 66 1 30 29 14 1 293 66
-Alan Ashby 315 81 7 24 38 39 14 3449 835
-Alvin Davis 479 130 18 66 72 76 3 1624 457
-Andre Dawson 496 141 20 65 78 37 11 5628 1575
-Andres Galarraga 321 87 10 39 42 30 2 396 101
-Alfredo Griffin 594 169 4 74 51 35 11 4408 1133
CHmRun CRuns CRBI CWalks League Division PutOuts
-Andy Allanson 1 30 29 14 A E 446
-Alan Ashby 69 321 414 375 N W 632
-Alvin Davis 63 224 266 263 A W 880
-Andre Dawson 225 828 838 354 N E 200
-Andres Galarraga 12 48 46 33 N E 805
-Alfredo Griffin 19 501 336 194 A W 282
Assists Errors Salary NewLeague
-Andy Allanson 33 20 NA A
-Alan Ashby 43 10 475.0 N
-Alvin Davis 82 14 480.0 A
-Andre Dawson 11 3 500.0 N
-Andres Galarraga 40 4 91.5 N
-Alfredo Griffin 421 25 750.0 A
dim(Hitters)
[1] 322 20
names(Hitters)
[1] "AtBat" "Hits" "HmRun" "Runs" "RBI"
[6] "Walks" "Years" "CAtBat" "CHits" "CHmRun"
[11] "CRuns" "CRBI" "CWalks" "League" "Division"
[16] "PutOuts" "Assists" "Errors" "Salary" "NewLeague"
处理缺失值
sum(is.na(Hitters))
[1] 59
删掉缺失值条目
hitters <- na.omit(Hitters)
dim(hitters)
[1] 263 20
sum(is.na(hitters))
[1] 0
最优子集选择
best subset selection
对 p 个预测变量的所有可能组合分别使用最小二乘回归进行拟合,在所有可能的模型中选取一个最优模型。
leaps 库的 regsubset() 函数。
默认设置下只输出前 8 个变量的筛选结果
regfit_full <- regsubsets(
Salary~.,
data=hitters
)
summary(regfit_full)
Subset selection object
Call: regsubsets.formula(Salary ~ ., data = hitters)
19 Variables (and intercept)
Forced in Forced out
AtBat FALSE FALSE
Hits FALSE FALSE
HmRun FALSE FALSE
Runs FALSE FALSE
RBI FALSE FALSE
Walks FALSE FALSE
Years FALSE FALSE
CAtBat FALSE FALSE
CHits FALSE FALSE
CHmRun FALSE FALSE
CRuns FALSE FALSE
CRBI FALSE FALSE
CWalks FALSE FALSE
LeagueN FALSE FALSE
DivisionW FALSE FALSE
PutOuts FALSE FALSE
Assists FALSE FALSE
Errors FALSE FALSE
NewLeagueN FALSE FALSE
1 subsets of each size up to 8
Selection Algorithm: exhaustive
AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun CRuns
1 ( 1 ) " " " " " " " " " " " " " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " " " " " " " " " " " " "
4 ( 1 ) " " "*" " " " " " " " " " " " " " " " " " "
5 ( 1 ) "*" "*" " " " " " " " " " " " " " " " " " "
6 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " " " "
7 ( 1 ) " " "*" " " " " " " "*" " " "*" "*" "*" " "
8 ( 1 ) "*" "*" " " " " " " "*" " " " " " " "*" "*"
CRBI CWalks LeagueN DivisionW PutOuts Assists Errors NewLeagueN
1 ( 1 ) "*" " " " " " " " " " " " " " "
2 ( 1 ) "*" " " " " " " " " " " " " " "
3 ( 1 ) "*" " " " " " " "*" " " " " " "
4 ( 1 ) "*" " " " " "*" "*" " " " " " "
5 ( 1 ) "*" " " " " "*" "*" " " " " " "
6 ( 1 ) "*" " " " " "*" "*" " " " " " "
7 ( 1 ) " " " " " " "*" "*" " " " " " "
8 ( 1 ) " " "*" " " "*" "*" " " " " " "
使用 nvmax 参数设置预测变量个数。
拟合全部 19 个变量
regfit_full <- regsubsets(
Salary~.,
data=hitters,
nvmax=19
)
regfit_summary <- summary(regfit_full)
regfit_summary
Subset selection object
Call: regsubsets.formula(Salary ~ ., data = hitters, nvmax = 19)
19 Variables (and intercept)
Forced in Forced out
AtBat FALSE FALSE
Hits FALSE FALSE
HmRun FALSE FALSE
Runs FALSE FALSE
RBI FALSE FALSE
Walks FALSE FALSE
Years FALSE FALSE
CAtBat FALSE FALSE
CHits FALSE FALSE
CHmRun FALSE FALSE
CRuns FALSE FALSE
CRBI FALSE FALSE
CWalks FALSE FALSE
LeagueN FALSE FALSE
DivisionW FALSE FALSE
PutOuts FALSE FALSE
Assists FALSE FALSE
Errors FALSE FALSE
NewLeagueN FALSE FALSE
1 subsets of each size up to 19
Selection Algorithm: exhaustive
AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun
1 ( 1 ) " " " " " " " " " " " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " " " " " " " " " " "
4 ( 1 ) " " "*" " " " " " " " " " " " " " " " "
5 ( 1 ) "*" "*" " " " " " " " " " " " " " " " "
6 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " "
7 ( 1 ) " " "*" " " " " " " "*" " " "*" "*" "*"
8 ( 1 ) "*" "*" " " " " " " "*" " " " " " " "*"
9 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " "
10 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " "
11 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " "
12 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " " " "
13 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " " " "
14 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" " " " "
15 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" "*" " "
16 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*" " "
17 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*" " "
18 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*" " "
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*" "*"
CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists Errors
1 ( 1 ) " " "*" " " " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " "*" " " " "
4 ( 1 ) " " "*" " " " " "*" "*" " " " "
5 ( 1 ) " " "*" " " " " "*" "*" " " " "
6 ( 1 ) " " "*" " " " " "*" "*" " " " "
7 ( 1 ) " " " " " " " " "*" "*" " " " "
8 ( 1 ) "*" " " "*" " " "*" "*" " " " "
9 ( 1 ) "*" "*" "*" " " "*" "*" " " " "
10 ( 1 ) "*" "*" "*" " " "*" "*" "*" " "
11 ( 1 ) "*" "*" "*" "*" "*" "*" "*" " "
12 ( 1 ) "*" "*" "*" "*" "*" "*" "*" " "
13 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
14 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
15 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
16 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
17 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
18 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
NewLeagueN
1 ( 1 ) " "
2 ( 1 ) " "
3 ( 1 ) " "
4 ( 1 ) " "
5 ( 1 ) " "
6 ( 1 ) " "
7 ( 1 ) " "
8 ( 1 ) " "
9 ( 1 ) " "
10 ( 1 ) " "
11 ( 1 ) " "
12 ( 1 ) " "
13 ( 1 ) " "
14 ( 1 ) " "
15 ( 1 ) " "
16 ( 1 ) " "
17 ( 1 ) "*"
18 ( 1 ) "*"
19 ( 1 ) "*"
summary() 函数返回模型的 R^2,RSS,调整 R^2,C_p 及 BIC 等。
names(regfit_summary)
[1] "which" "rsq" "rss" "adjr2" "cp" "bic" "outmat"
[8] "obj"
C_p
在训练集 RSS 基础上增加惩罚项,用于调整训练误差倾向于低估测试误差的这一现象。
BIC
贝叶斯信息准则,Bayesian information criterion
通常给包含多个变量的模型施加较重的惩罚
调整 R^2
理论上,拥有最大调整 R^2 的模型只包含了正确的变量,而没有冗余变量
R^2
regfit_summary$rsq
[1] 0.3214501 0.4252237 0.4514294 0.4754067 0.4908036 0.5087146
[7] 0.5141227 0.5285569 0.5346124 0.5404950 0.5426153 0.5436302
[13] 0.5444570 0.5452164 0.5454692 0.5457656 0.5459518 0.5460945
[19] 0.5461159
R^2 随着模型中包含的变量个数增多而单调增加。 仅包含单个变量时 R^2 为 32%,包含所有变量时,R^2 增加到 55%
绘图比较
par(mfrow=c(2, 2))
# 绘制 RSS
plot(
regfit_summary$rss,
xlab="Number of Variables",
ylab="RSS",
type="l"
)
# 绘制调整 R^2
plot(
regfit_summary$adjr2,
xlab="Number of Variables",
ylab="Adjuested Rsq",
type="l"
)
# 标记调整 R^2 最大的模型
adjr2_max <- which.max(regfit_summary$adjr2)
points(
adjr2_max,
regfit_summary$adjr2[adjr2_max],
col="red",
cex=2,
pch=20
)
# 绘制 C_p
plot(
regfit_summary$cp,
xlab="Number of Variables",
ylab="Cp",
type="l"
)
cp_min <- which.min(regfit_summary$cp)
points(
cp_min,
regfit_summary$cp[cp_min],
col="red",
cex=2,
pch=20
)
# 绘制 BIC
plot(
regfit_summary$bic,
xlab="Number of Variables",
ylab="BIC",
type="l"
)
bic_min <- which.min(regfit_summary$bic)
points(
bic_min,
regfit_summary$bic[bic_min],
col="red",
cex=2,
pch=20
)
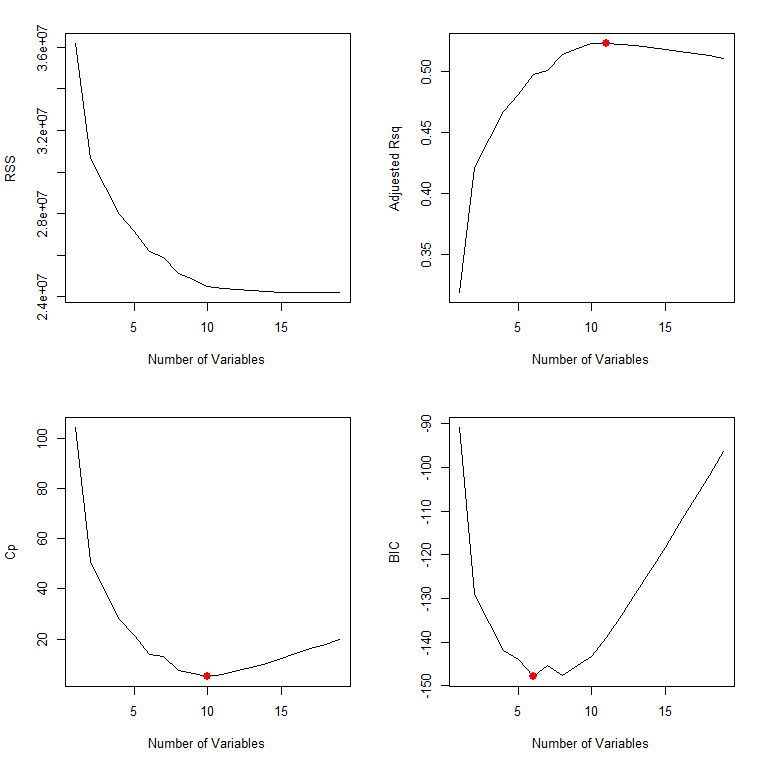
regsubsets() 函数支持 plot()
黑色方块表示选择的最优模型所包含的变量
plot(
regfit_full,
scale="r2"
)
plot(
regfit_full,
scale="adjr2"
)
plot(
regfit_full,
scale="Cp"
)
plot(
regfit_full,
scale="bic"
)
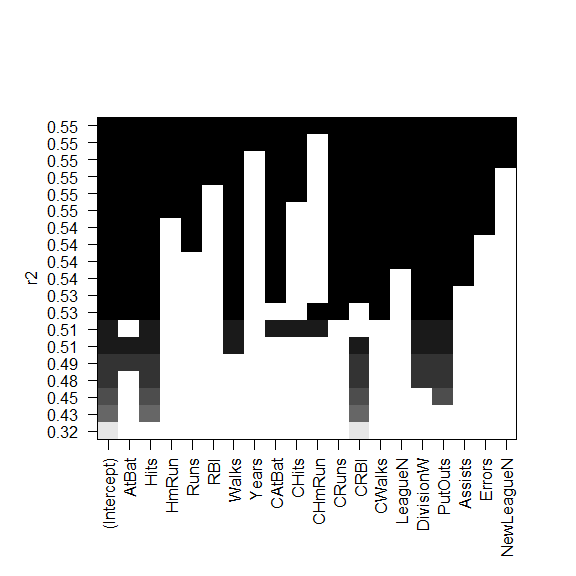


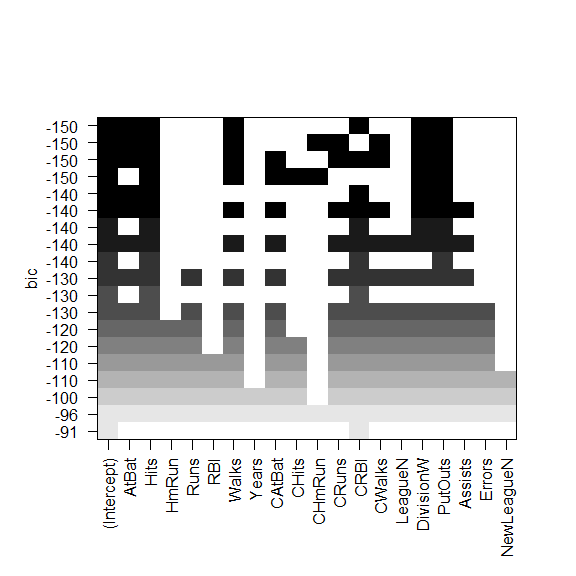
BIC 最小的是六变量模型,包含:
- AtBat
- Hits
- Walks
- CRBI
- DivisonW
- PutOuts
提取该模型的参数估计值
coef(regfit_full, 6)
(Intercept) AtBat Hits Walks CRBI
91.5117981 -1.8685892 7.6043976 3.6976468 0.6430169
DivisionW PutOuts
-122.9515338 0.2643076
向前逐步选择和向后逐步选择
设置 regsubsets() 函数中参数 method
forward:向前逐步选择backward:向后逐步选择
向前逐步选择
forward stepwise selection
以一个不包含任何预测变量的零模型为起点,依次往模型中添加变量,直到所有的预测变量都包含在模型中。
regfit_forward <- regsubsets(
Salary ~ .,
data=hitters,
nvmax=19,
method="forward"
)
summary(regfit_forward)
Subset selection object
Call: regsubsets.formula(Salary ~ ., data = hitters, nvmax = 19, method = "forward")
19 Variables (and intercept)
Forced in Forced out
AtBat FALSE FALSE
Hits FALSE FALSE
HmRun FALSE FALSE
Runs FALSE FALSE
RBI FALSE FALSE
Walks FALSE FALSE
Years FALSE FALSE
CAtBat FALSE FALSE
CHits FALSE FALSE
CHmRun FALSE FALSE
CRuns FALSE FALSE
CRBI FALSE FALSE
CWalks FALSE FALSE
LeagueN FALSE FALSE
DivisionW FALSE FALSE
PutOuts FALSE FALSE
Assists FALSE FALSE
Errors FALSE FALSE
NewLeagueN FALSE FALSE
1 subsets of each size up to 19
Selection Algorithm: forward
AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun
1 ( 1 ) " " " " " " " " " " " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " " " " " " " " " " "
4 ( 1 ) " " "*" " " " " " " " " " " " " " " " "
5 ( 1 ) "*" "*" " " " " " " " " " " " " " " " "
6 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " "
7 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " "
8 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " "
9 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " "
10 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " "
11 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " "
12 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " " " "
13 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " " " "
14 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" " " " "
15 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" "*" " "
16 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*" " "
17 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*" " "
18 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*" " "
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*" "*"
CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists Errors
1 ( 1 ) " " "*" " " " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " "*" " " " "
4 ( 1 ) " " "*" " " " " "*" "*" " " " "
5 ( 1 ) " " "*" " " " " "*" "*" " " " "
6 ( 1 ) " " "*" " " " " "*" "*" " " " "
7 ( 1 ) " " "*" "*" " " "*" "*" " " " "
8 ( 1 ) "*" "*" "*" " " "*" "*" " " " "
9 ( 1 ) "*" "*" "*" " " "*" "*" " " " "
10 ( 1 ) "*" "*" "*" " " "*" "*" "*" " "
11 ( 1 ) "*" "*" "*" "*" "*" "*" "*" " "
12 ( 1 ) "*" "*" "*" "*" "*" "*" "*" " "
13 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
14 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
15 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
16 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
17 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
18 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
NewLeagueN
1 ( 1 ) " "
2 ( 1 ) " "
3 ( 1 ) " "
4 ( 1 ) " "
5 ( 1 ) " "
6 ( 1 ) " "
7 ( 1 ) " "
8 ( 1 ) " "
9 ( 1 ) " "
10 ( 1 ) " "
11 ( 1 ) " "
12 ( 1 ) " "
13 ( 1 ) " "
14 ( 1 ) " "
15 ( 1 ) " "
16 ( 1 ) " "
17 ( 1 ) "*"
18 ( 1 ) "*"
19 ( 1 ) "*"
plot(
regfit_forward,
scale="r2"
)
plot(
regfit_forward,
scale="adjr2"
)
plot(
regfit_forward,
scale="Cp"
)
plot(
regfit_forward,
scale="bic"
)
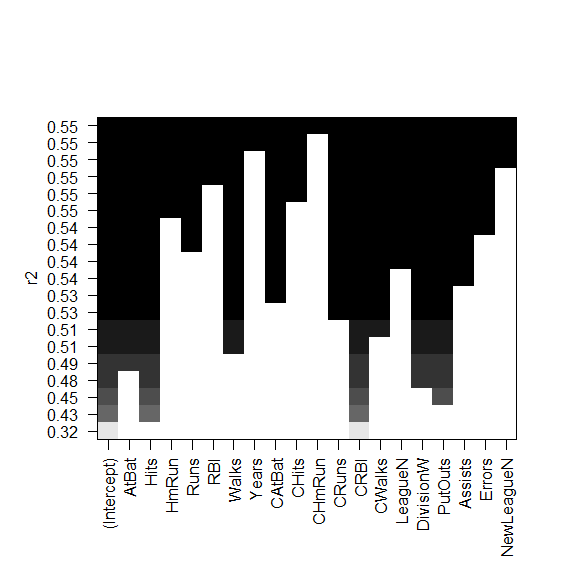


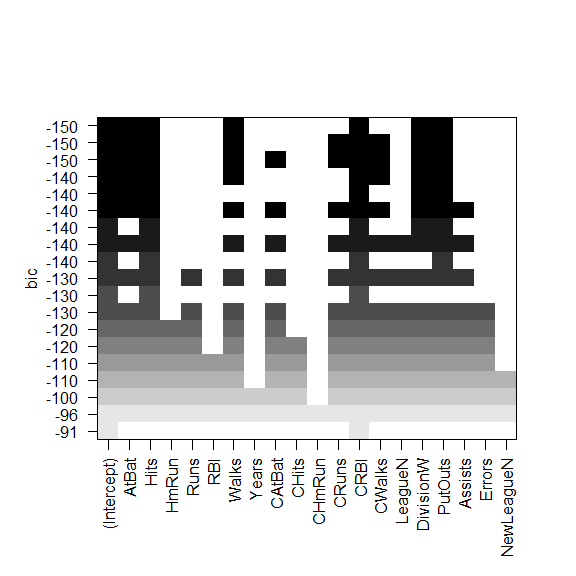
向后逐步选择
backward stepwise selection
以包含 p 个变量的全模型为起点,逐次迭代,每次移除一个对模型拟合结果最不利的变量
regfit_backward <- regsubsets(
Salary ~ .,
data=hitters,
nvmax=19,
method="backward"
)
summary(regfit_backward)
Subset selection object
Call: regsubsets.formula(Salary ~ ., data = hitters, nvmax = 19, method = "backward")
19 Variables (and intercept)
Forced in Forced out
AtBat FALSE FALSE
Hits FALSE FALSE
HmRun FALSE FALSE
Runs FALSE FALSE
RBI FALSE FALSE
Walks FALSE FALSE
Years FALSE FALSE
CAtBat FALSE FALSE
CHits FALSE FALSE
CHmRun FALSE FALSE
CRuns FALSE FALSE
CRBI FALSE FALSE
CWalks FALSE FALSE
LeagueN FALSE FALSE
DivisionW FALSE FALSE
PutOuts FALSE FALSE
Assists FALSE FALSE
Errors FALSE FALSE
NewLeagueN FALSE FALSE
1 subsets of each size up to 19
Selection Algorithm: backward
AtBat Hits HmRun Runs RBI Walks Years CAtBat CHits CHmRun
1 ( 1 ) " " " " " " " " " " " " " " " " " " " "
2 ( 1 ) " " "*" " " " " " " " " " " " " " " " "
3 ( 1 ) " " "*" " " " " " " " " " " " " " " " "
4 ( 1 ) "*" "*" " " " " " " " " " " " " " " " "
5 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " "
6 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " "
7 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " "
8 ( 1 ) "*" "*" " " " " " " "*" " " " " " " " "
9 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " "
10 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " "
11 ( 1 ) "*" "*" " " " " " " "*" " " "*" " " " "
12 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " " " "
13 ( 1 ) "*" "*" " " "*" " " "*" " " "*" " " " "
14 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" " " " "
15 ( 1 ) "*" "*" "*" "*" " " "*" " " "*" "*" " "
16 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*" " "
17 ( 1 ) "*" "*" "*" "*" "*" "*" " " "*" "*" " "
18 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*" " "
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*" "*" "*"
CRuns CRBI CWalks LeagueN DivisionW PutOuts Assists Errors
1 ( 1 ) "*" " " " " " " " " " " " " " "
2 ( 1 ) "*" " " " " " " " " " " " " " "
3 ( 1 ) "*" " " " " " " " " "*" " " " "
4 ( 1 ) "*" " " " " " " " " "*" " " " "
5 ( 1 ) "*" " " " " " " " " "*" " " " "
6 ( 1 ) "*" " " " " " " "*" "*" " " " "
7 ( 1 ) "*" " " "*" " " "*" "*" " " " "
8 ( 1 ) "*" "*" "*" " " "*" "*" " " " "
9 ( 1 ) "*" "*" "*" " " "*" "*" " " " "
10 ( 1 ) "*" "*" "*" " " "*" "*" "*" " "
11 ( 1 ) "*" "*" "*" "*" "*" "*" "*" " "
12 ( 1 ) "*" "*" "*" "*" "*" "*" "*" " "
13 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
14 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
15 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
16 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
17 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
18 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
19 ( 1 ) "*" "*" "*" "*" "*" "*" "*" "*"
NewLeagueN
1 ( 1 ) " "
2 ( 1 ) " "
3 ( 1 ) " "
4 ( 1 ) " "
5 ( 1 ) " "
6 ( 1 ) " "
7 ( 1 ) " "
8 ( 1 ) " "
9 ( 1 ) " "
10 ( 1 ) " "
11 ( 1 ) " "
12 ( 1 ) " "
13 ( 1 ) " "
14 ( 1 ) " "
15 ( 1 ) " "
16 ( 1 ) " "
17 ( 1 ) "*"
18 ( 1 ) "*"
19 ( 1 ) "*"
plot(
regfit_backward,
scale="r2"
)
plot(
regfit_backward,
scale="adjr2"
)
plot(
regfit_backward,
scale="Cp"
)
plot(
regfit_backward,
scale="bic"
)
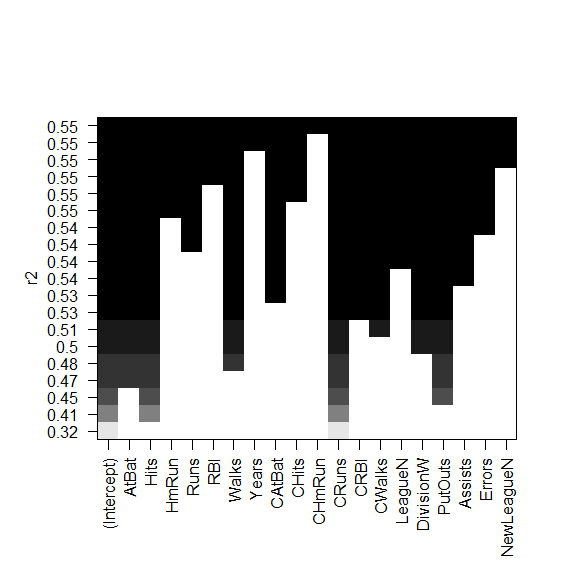


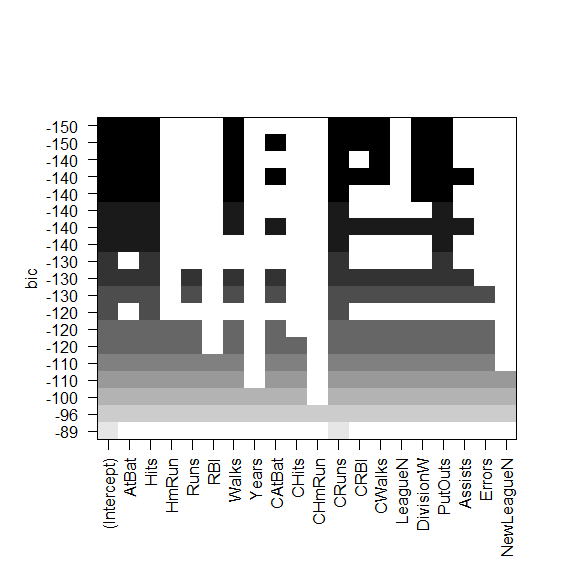
对比
向前逐步选择和向后逐步选择都无法保证找到所有可能模型中的最优模型。
最优七变量模型不同
coef(regfit_full, 7)
(Intercept) Hits Walks CAtBat CHits
79.4509472 1.2833513 3.2274264 -0.3752350 1.4957073
CHmRun DivisionW PutOuts
1.4420538 -129.9866432 0.2366813
coef(regfit_forward, 7)
(Intercept) AtBat Hits Walks CRBI
109.7873062 -1.9588851 7.4498772 4.9131401 0.8537622
CWalks DivisionW PutOuts
-0.3053070 -127.1223928 0.2533404
coef(regfit_backward, 7)
(Intercept) AtBat Hits Walks CRuns
105.6487488 -1.9762838 6.7574914 6.0558691 1.1293095
CWalks DivisionW PutOuts
-0.7163346 -116.1692169 0.3028847
使用验证集方法选择模型
拆分训练集和验证集
构造与数据集长度相同的 TRUE/FALSE 向量
set.seed(1)
train <- sample(
c(TRUE, FALSE),
nrow(hitters),
rep=TRUE
)
test <- (!train)
在训练集上进行最优子集选择
regfit_best <- regsubsets(
Salary ~ .,
data=hitters[train,],
nvmax=19
)
验证集误差
在不同模型大小情况下,计算最优模型的验证集误差
使用测试数据生成回归设计矩阵
设计矩阵 (design matrix, model matrix, regressor matrix) 在统计学和机器学习中,是一组观测结果中的所有解释变量的值构成的矩阵,常用 X 表示。 通常情况下,设计矩阵的第 i 行代表第 i 次观测的结果,第 j 列代表第 j 种解释变量。
test_mat <- model.matrix(
Salary ~ .,
data=hitters[test,]
)
计算测试集的 MSE
每次循环计算参数估计,乘以测试集回归设计矩阵得到预测值,结合实际值计算 MSE
val_errors <- rep(NA, 19)
for (i in 1:19) {
coefi <- coef(regfit_best, id=i)
pred <- test_mat[,names(coefi)] %*% coefi
val_errors[i] <- mean((hitters$Salary[test] - pred)^2)
}
val_errors
[1] 164377.3 144405.5 152175.7 145198.4 137902.1 139175.7 126849.0
[8] 136191.4 132889.6 135434.9 136963.3 140694.9 140690.9 141951.2
[15] 141508.2 142164.4 141767.4 142339.6 142238.2
选择最优模型
which.min(val_errors)
7
最优模型含有 7 个变量
coef(regfit_best, 7)
(Intercept) AtBat Hits Walks CRuns
67.1085369 -2.1462987 7.0149547 8.0716640 1.2425113
CWalks DivisionW PutOuts
-0.8337844 -118.4364998 0.2526925
编写预测函数
为 regsubsets() 函数编写 predict.regsubsets() 函数,以支持 predict() 函数
predict.regsubsets <- function(object, newdata, id, ...) {
form <- as.formula(object$call[[2]])
mat <- model.matrix(form, newdata)
coefi <- coef(object, id=id)
xvars <- names(coefi)
return (mat[,xvars] %*% coefi)
}
计算测试集在最优七变量模型上的预测值
result <- predict(regfit_best, hitters[test,], id=7)
对比
使用整个数据集进行最优子集选择,选出最优的 7 变量模型
regfit_best <- regsubsets(
Salary ~ .,
data=hitters,
nv=19
)
coef(regfit_best, 7)
(Intercept) Hits Walks CAtBat CHits
79.4509472 1.2833513 3.2274264 -0.3752350 1.4957073
CHmRun DivisionW PutOuts
1.4420538 -129.9866432 0.2366813
可以看到,使用全集数据得到的模型包含的变量与使用训练集的到的模型不同。
使用交叉验证法选择模型
在 k=10 个训练集中分别使用最优子集选择法
将数据随机分成 10 组
k <- 10
set.seed(1)
folds <- sample(
1:k,
nrow(hitters),
replace=TRUE
)
cv_errors 矩阵行表示一次循环,列表示最优变量个数
cv_errors <- matrix(
NA, k, 19,
dimnames=list(NULL, paste(1:19))
)
循环计算测试误差
# 计算不同折
for (j in 1:k) {
best_fit <- regsubsets(
Salary ~ .,
data=hitters[folds!=j,],
nvmax=19
)
# 计算不同变量个数
for (i in 1:19) {
pred <- predict(
best_fit,
hitters[folds==j,],
id=i
)
cv_errors[j, i] <- mean(
(hitters$Salary[folds==j] - pred)^2
)
}
}
计算列平均,得到不同变量个数的模型的交叉验证误差
mean_cv_errors <- apply(cv_errors, 2, mean)
mean_cv_errors
1 2 3 4 5 6 7 8
149821.1 130922.0 139127.0 131028.8 131050.2 119538.6 124286.1 113580.0
9 10 11 12 13 14 15 16
115556.5 112216.7 113251.2 115755.9 117820.8 119481.2 120121.6 120074.3
17 18 19
120084.8 120085.8 120403.5
plot(
mean_cv_errors,
type="b",
xlab="Number of Variables",
ylab="Mean CV Errors",
main="Mean CV Errors for All Variables"
)
mean_cv_min <- which.min(mean_cv_errors)
points(
mean_cv_min,
mean_cv_errors[mean_cv_min],
col="red",
cex=2,
pch=20,
)

交叉验证选择了十变量模型
对整个数据集使用最优子集选择,得到十变量模型的参数估计结果
reg_best <- regsubsets(
Salary ~ .,
data=hitters,
nvmax=19
)
coef(reg_best, 10)
(Intercept) AtBat Hits Walks CAtBat
162.5354420 -2.1686501 6.9180175 5.7732246 -0.1300798
CRuns CRBI CWalks DivisionW PutOuts
1.4082490 0.7743122 -0.8308264 -112.3800575 0.2973726
Assists
0.2831680
参考
https://github.com/perillaroc/islr-study
ISLR实验系列文章
线性回归
分类
重抽样方法
线性模型选择与正则化