CEMC数值天气预报业务系统建设介绍(2023版)
本文来自笔者 2023 年 8 月 7 日参与单位新职工培训的 PPT《CEMC 业务系统介绍》。
声明:本文仅代表笔者个人观点,所选材料截止时间为 2023 年 8 月,不代表当前的业务系统建设现状。 CEMC 已于 2024 年 5 月完成内设机构改革,本文内容已不再完全适用。 如果想了解最新信息,请咨询 CEMC 相关部门。
1. 业务系统简介
1.1 单位简介
注:本节内容不是最新的机构设置情况。
CEMC 于 2021 年 10 月 1 日成立,设有 3 个职能处室和 9 个业务处室。
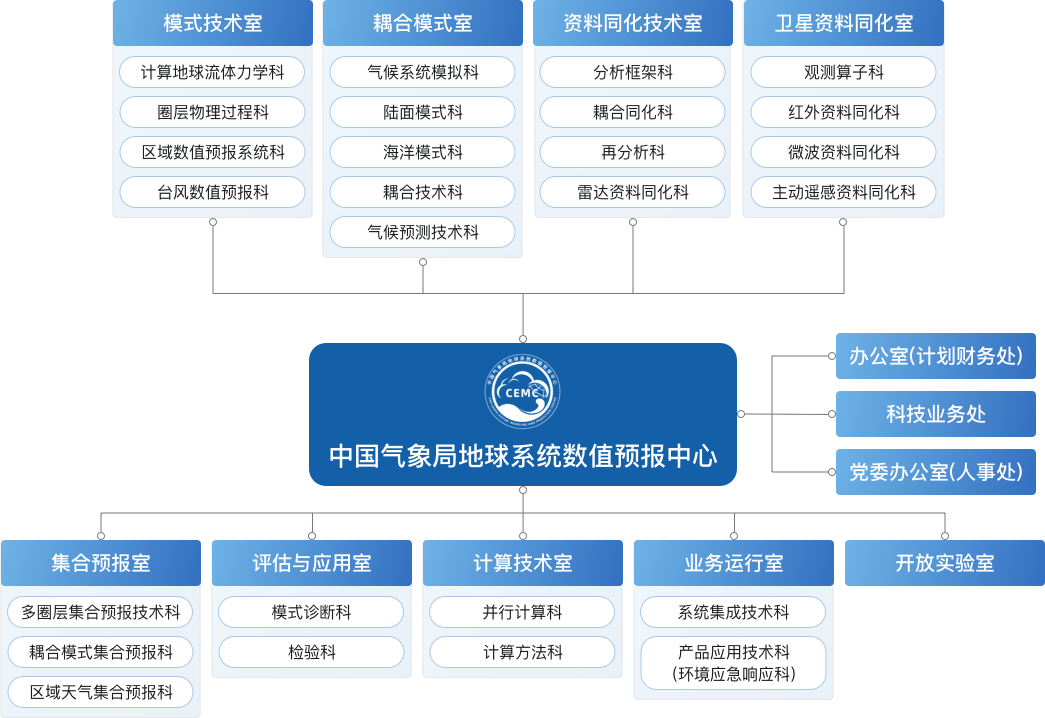
图 CEMC 组织架构图,来自 CEMC 官网。
我来自业务运行室的系统集成技术科。业务室的主要职责有三项:
- 业务集成与运行:发展地球模式系统的业务化集成和运行技术
- 产品应用技术:发展模式系统后处理技术并拓展产品应用能力
- 模式研发支撑技术:发展支撑地球系统模式协同中试的信息技术
1.2 数值天气预报业务系统
业务运行室目前负责建设并维护 CEMC 的数值天气预报业务系统,包括:
- 确定性模式
- 集合预报模式
- 环境模式与系统
- 产品系统
下图是业务运行室目前负责维护的业务系统。 图中黄色部分是 5 个以 GRAPES 模式为核心的数值天气预报业务系统,包括 3 个确定性模式和 2 个集合预报模式,绿色部分是专业数值预报业务系统,蓝色是产品系统。 其中特殊服务保障系统和大气扩散应急响应模式系统因涉及模式较多而未绘制与其它系统的连接线。 另外,该图仅是由业务运行室负责维护的业务系统,不包含其他处室维护的业务系统和实时系统,例如气候模式由集合室和耦合室维护,检验诊断系统由评估室维护。

图 CEMC 数值天气预报业务系统。不包括气候模式和检验诊断业务系统。
1.3 运行平台环境
当前数值天气预报模式业务系统运行在 CMA-PI 高性能计算机的业务分区。
业务系统通常由观测资料预处理、模式同化 + 预报、模式后处理和产品分发四个核心部分构成。
业务系统通过两种方式从天擎(CMADaaS)获取原始观测资料。
- 大部分观测资料由 CTS 通过文件推送的方式保存到 HPC 共享目录中,观测资料预处理程序会从共享目录中读取相应资料。
- 少部分观测资料在业务系统开始运行的时候通过天擎 MUSIC 接口进行实时检索。
为了降低业务高峰期对网络带宽的需求,建议尽量采用文件推送的方式接入观测资料。
观测资料预处理模块生成模式可以识别的输入数据,提供给模式同化模块,同化模块生成模式积分初始场,提供给预报模块进行模式积分。 在模式积分生成输出文件同时会运行模式后处理程序,对模式输出的原始结果进行后处理,制作数据和图片产品。
业务产品通过 FTP 等方式发给 CMA 同城内网的直属单位,通过 FTP 传给 CTS,由 CTS 负责产品转发,包括业务产品下发,接入天擎和下载平台等。

图 CEMC 数值天气预报业务系统运行平台环境
1.4 业务系统维护
康威定律 (Conway’s Law)
设计系统的架构受制于产生这些设计的组织的沟通结构。
下图展示了当前 CEMC 天气预报模式业务系统的运行方式。 业务运行室负责 7x24 小时运维值班和业务系统建设,运维值班岗位负责处理一般故障,遇到无法解决的复杂和未知故障时联系业务建设岗位解决。 仅在特殊情况无法让模式继续运行下去时,才会联系研发处室一同查找原因。

图 CEMC 天气模式业务系统维护示意图,以 5 个业务系统为例进行说明
当前业务系统建设和运维方式源于过去二十多年,尤其是过去十多年老数值中心形成的实践。 而新数值中心相对于老中心来说,业务处室从 2 个增加到 9 个,研发人员从近 100 人增加到 200 人以上,当前业务建设和运维方式是否适应未来地球系统模式业务系统仍是一个需要进一步探讨的课题。 希望大家积极参与到业务系统建设工作中,为模式集成和流程建设带来新理念、新方法。
2. 业务集成工作介绍
2.1 集成简介
接下来介绍业务集成工作到底是做什么的,希望通过这次介绍能让大家更进一步了解业务集成工作。
在介绍之前首先说明一个问题,即建设和维护数值预报业务系统最关心的问题是什么 (见下图)。

图 建设和维护数值预报业务系统最关心的问题
业务系统最重要的一点是要保证时效性,确保在规定时间内完成产品分发。 天气预报需要在固定的时间点之前完成制作,比如每晚 19:30 新闻联播后的天气预报就是在每天 18:00 制作的,只能使用在 18:00 之前生成的模式产品。 超过截止时间生成的产品不具有任何应用价值,也就相当于白跑了。 同时,数值天气预报业务系统都是滚动循环的,尤其是未来运行的逐小时快速循环同化预报系统,如果前一时次产品生成延迟时间较长,后一时次的产品可能就已经生成了,那么前一时次的产品就没用了。 所以,时效性是业务系统运维过程中最优先保障的一点。
业务系统关注的第二点是完整性,需要提供完整时间序列的产品,这一点在气象大模型时代尤为重要。 数值预报业务系统生成的产品往往是下游其他业务系统的输入数据。 比如多模式集成的图片产品需要使用多个业务模式的预报结果,如果某个系统某个时效数据缺失可能会影响产品生成。 通常对接模式输出结果的系统一般不会考虑数据缺失情况下如何自动处理,因此产品缺失会导致一系列问题,属于严重故障。 业务系统的回算成本较高,甚至可能因为计算资源限制、超算软件环境、模式系统版本的问题导致无法完成历史回算任务。 因此需要在业务系统实时运行的有效期内确保制作完整时间序列的基础数据产品。
业务系统关注的第三点是正确性。 对于模式研发来说,正确性是最核心的指标,但对于业务系统来说,则是在保证时效性和完整性的基础上,尽可能保障产品的预报效果。 因此,我们在处理业务系统故障的时候,为了保证按时提供完整的产品,可能会选用严重影响预报效果的运行方案,甚至会采用破坏时间连续性的数据替换方案。
以上三点同时也是模式研发关注的问题,但优先级与业务运行正好相反,模式研发最关心正确性,其次是完整性,最后才是时效性。
同时业务系统也关注可维护性。 业务系统建设和维护的团队成员并不完全重叠,因此业务系统必须能方便进行维护,保证能让没有参与系统建设的运维同事能快速定位故障。 对于某个故障要尽可能找到解决方案,并尽可能实现自动处理,减少人工干预。
上述四个目标都可以通过系统集成工作来实现。
随着对业务系统了解的逐渐深入,大家也许会遇到关于业务系统集成、建设工作的常见问题:
- 为什么要安排专人投入不短的时间进行业务流程建设?
- 业务系统已有流程,为什么每次升级都需要时间开发流程,而不是直接替换可执行程序?
比这两点更深入的一个问题,也是从 CEMC 成立以来就一致困扰业务运行团队的问题,那就是:系统科除了运维值班还做了哪些工作?
当然这些问题不属于培训内容,也没有标准答案。 我从三个方面来介绍业务系统集成的主要工作,希望大家能在后续工作过程中能多多了解系统集成相关工作。

图 业务系统集成的三项主要工作
首先是流程建设,需要建立滚动循环的工作流,并对模式试验脚本进行优化改造。
其次是数据流转,模式试验一般使用经过预处理后的观测数据,而业务系统则从原始数据开始,同时模式试验通常不包含产品制作步骤,业务系统集成需要增加产品后处理和产品分发任务。
最后是异常处理,模式试验出错后可以重复提交多次来进行调试,但业务系统在时效性的要求下无法任意重复提交,因此需要建立容错机制,并为各种异常情况提供运维预案。
下面分别介绍这三项工作的具体内容。
2.2 流程建设
流程建设的核心任务是将不同研发小组的成果整合成一个可以实时运行的业务系统,主要包括版本集成和流程建设两个部分。

图 集成工作示意图,包括版本集成和流程建设两个步骤
在建设业务系统之前首先需要将各个研发部门的成果通过版本集成形成模式基础版本。版本集成后得到的基础版本有多种形式。
- 目前 CEMC 使用 Perforce 版本控制系统管理模式代码,后续培训课程的两位老师会介绍如何从 Perforce 中获取 CMA-GFS 和 CMA-MESO 当前业务系统版本。
- 一些业务系统没有使用 Perforce 管理代码,而是将集成的版本保存在 HPC 的某个目录中,甚至分布在不同账户的多个目录中。 这种方式有极大的风险,一旦 HPC 目录被误删,之前的工作就白费了。
- 还有一些业务系统或者部分模块的源代码不知道放在哪儿,业务集成时只提供了可执行程序,这类模块存在极大的风险,可能需要从制度层面进行规范。
我们强烈推荐使用版本控制系统管理所有业务系统的源代码,在后续业务集成工作中也会逐步强调提供源代码而不是可执行程序。 未来中心的代码仓库会逐步切换到 NMIC 开发的 Metcode 平台,版本控制软件会从 Perforce 切换到 Git。 希望大家在未来工作中多多学习 Git 的使用方法。
通过版本集成得到模式基础版本后,会开展相应系统的流程建设工作,将分散的模式程序组织到一起,编写 ecFlow 工作流,ecFlow 任务脚本,编译程序,优化脚本,准备静态数据和配置文件等等,最终形成可以实时运行的业务系统。
从狭义上看,集成工作仅仅包括版本集成,从更广泛的业务系统角度来看,集成工作则包含了版本集成和业务集成两项工作。 目前天气模式的业务集成工作主要由业务室负责,而版本集成尚未形成标准的工作流程,将在后续制定模式版本管理规范时逐步完善。
系统构建技术
CEMC 的系统构建技术经历从脚本到工作流工具的三个发展阶段,如下图所示。

图 CEMC 业务系统流程建设发展历程
2000 年之前使用 Shell 脚本直接运行业务系统,和目前模式试验的运行方式一致,在一个主控脚本中顺序运行所有任务,使用 crontab 控制脚本定时运行。 脚本中使用 print 之类的命令输出日志信息,查看运行状态需要查看脚本输出日志,或者直接查看模式运行目录的输出数据。 业务系统的开发与运行都在同一个账户环境中,甚至因为脚本和 HPC 账户环境和目录设置深度绑定,运行脚本只能在开发账户中运行而无法迁移到其它账户或目录。
从 2000 年开始,CEMC 引进了 ECMWF 开发的工作流调度工具 SMS (Supervisor Monitor Scheduler),使用 SMS 调度按任务拆分后的 Shell 脚本,使用 SMS 提供的监控界面 XCDP 可视化监控业务系统的运行情况。 引入工作流调度工具极大提高了系统运维的效率,但因此也增加了业务系统流程建设的成本。 为此,CEMC 通过组建单独的业务系统建设小组来负责模式系统从研发到业务的转化工作,这也是目前系统科的职责之一。
2018 年 CMA 的超算平台从 IBM 更新到曙光,CEMC 使用由 ECMWF 开发的 SMS 升级版本 ecFlow 重新建设业务系统,使用 ecFlow 提供的 Python API 接口构建系统流程。 相对于 SMS 流程定义语言 CDP 的类 Shell 语法,基于 Python 的流程定义脚本可以使用诸如函数、循环、类等通用编程语言元素,可以很方便搭建复杂的运行流程。 今年,CMA 建成了新一代超算平台,在新平台上我们将继续使用 ecFlow 来调度数值预报业务系统。
工作流调度与脚本运行
那么,为什么要使用工作流调度工具来构建数值预报业务系统? 脚本运行有哪些优点,有哪些不方便的地方呢?
下图是 CMA-GFS 模式主控脚本与业务 ecFlow 流程的对比。 从流程上看大体一致,都是顺序执行,但在细节处理上略有不同。

图 CMA-GFS 主控脚本与 ecFlow 流程对比
工作流调度方式有多项优势:
- 精确控制系统流程,方便分拆任务。 工作流调度工具提供了多种机制来定义任务之间的执行顺序,可以根据需要将模式流程主控脚本分拆为大量的小任务。 如上图所示,GFS 主控脚本中使用带标号的注释来说明不同的任务,而 ecFlow 使用类似目录的树形结构表示整个工作流,更容易掌握整个系统的运行流程。
- 提高运维效率,GUI 界面方便监控,内置出错自动重做功能。 工作流调度工具一般都带有图形界面,在界面中可以很直观地查看系统的运行情况,在任务出错时,也会有类似弹出窗口等的明显的提示信息,方便监控人员第一时间发现系统故障。 同时,工作流调度软件通常会内置故障恢复功能,比如自动重做出错任务功能非常适合因硬件环境瞬时故障导致临时性故障的自动处理。
当然,工作流调度方式也有一定的劣势:
- 与模式研发批量试验使用的脚本运行方式不同。 虽然工作流调度工具执行的任务实际上也是 shell 脚本,但毕竟与纯脚本运行不一致,在故障排查时需要首先确定是工作流任务运行脚本的故障还是应用程序本身的问题。
- 需要额外维护一套工作流调度“脚本”。 在 CMA-GFS 的源码中大家可以看到研发试验的 shell 脚本放在 RUN 目录中,业务系统 ecFlow 脚本放在 ECFLOW 目录中。 每次升级更新需要同时更新两套“脚本”,这也导致了业务系统升级前必须留有一定的时间进行系统集成工作。
- 需要专门团队进行研发到业务的转化工作。这也是业务室系统科的核心工作任务之一。
为了减少模式研发和业务运行之间的差异,业务室正在从两个方面开展研发工作。
- 第一种方案是统一研发试验和业务系统的运行方式,让模式研发也使用 ecFlow 来跑实验。 当然,为了降低 ecFlow 的学习成本,我们会提供一系列工具来帮助研发同事快速运行试验。 正在开发中的科创平台就提供自动生成 ecFlow 运行流程的功能,可以在科创网站中通过使用内置的试验模版并修改参数来快速创建模式试验流程,科创平台会在后台自动完成试验 ecFlow 流程的创建和运行。
- 第二种方案是使用一套脚本同时支持 shell 和 ecFlow 两种运行方式。 巧妙设计 shell 脚本的调用层次结构,将主要业务逻辑封装到单一的脚本中,实现快速创建 ecFlow 脚本。 CMA-GFS 的脚本就遵循该方案进行设计,ecFlow 任务脚本不再负责具体的业务逻辑,而是对研发 shell 脚本的调用,从而实现策略和机制的分离。
业务室将持续研发业务系统集成技术,致力于提高数值预报模式系统从研发到业务的转化效率。
下面简单介绍 ecFlow 软件。
ecFlow概述

图 ecFlow 概述
ecFLow 是 ECMWF 开发的工作流管理软件,是用于在异构环境中调度大量计算作业的通用应用程序,帮助科研和业务部门设计、提交和监视计算作业。
当前 CEMC 主要数值天气预报业务系统都运行在 CMA-PI 超算平台,并使用 ecFlow 调度运行,包括
- 3 个 HPC 账户 (nwp, nwp_qu, nwp_pd)
- 4 个 ecFlow 服务 (nwpc_op, nwpc_qu, nwpc_qu_eps, nwpc_pd)
- 20+ ecFlow 工作流 (CMA-GFS, CMA-GEPS, CMA-MESO, CMA-TYM, CMA-REPS, …)
- 10万+ 每天作业数
脚本优化
接下来介绍流程建设中的脚本优化工作。脚本优化是保证可维护性的最佳实践。下图展示了脚本集成的两种方案。

图 脚本集成的两种方案
第一种方案是调用 Shell 脚本。 左图是台风应急产品系统中的 ftp2ncl 任务,该任务直接调用研发同事提供的 ftp2ncl.csh_v1 脚本。 该方案的优势是集成方便,ecFlow 任务仅需要拷贝/链接需要执行的脚本,并准备输入数据,直接调用脚本即可;同时在系统更新时只需要替换研发脚本,而不需要修改 ecFlow 任务脚本。 该方案的劣势是任务的核心业务逻辑隐藏在调用的二级脚本中,出错不方便定位,而且系统建设和维护人员很可能不熟悉研发脚本,在出错时需要联系研发同事处理。
第二种方案是将研发 Shell 脚本嵌入到 ecFlow 任务脚本中并进行改造。 右图是 CMA-GEPS 系统的 plot_gmas 任务,使用 wgrib2 处理数据并使用 ncl 脚本绘图。 该方案的劣势是集成时需要修改 ecFlow 的任务脚本,系统建设人员需要花时间研发脚本代码,因此需要更多的集成时间。 但该方案的优势是出错方便定位故障点,因为系统建设者需要吃透研发脚本,所以能处理除了应用程序本身之外的绝大部分故障。
脚本优化是研发到业务转化工作最耗时的工作任务,业务系统建设时会根据各种各样的情况来决定每个任务的集成方式,还没有形成统一的标准。 GFS 和 MESO 主模式流程建设者也是研发 shell 脚本的维护者,也是版本管理做得最好的业务系统。 而其他业务系统存在流程建设与研发脚本分离的问题,所以很多时候业务系统出错常常要首先确认 ecFlow 流程与研发流程是否一致。 业务系统建设工作就是要在快速搭建业务系统运行流程和提高可维护性之间做权衡。 相信大家在后续工作中也会遇到类似的问题,业务工作往往不是寻找某个唯一的标准答案,而是在众多可行的方案中选择不一定是最完美却是最符合当下需求的那一个选项。
2.3 数据流转
接下来介绍系统集成涉及的另一方面工作,即业务系统需要搭建从端到端的数据流转流程。
业务系统需要实时获取最新的观测资料数据,并将业务输出的模式预报产品及时分发给下游用户。 而模式研发过程中很少考虑以上两点。
下图给出了研发试验和业务系统中不同种类数据的对比情况。

- 输入数据:研发试验直接使用预处理后的数据,一般不需要考虑观测资料的来源问题; 而业务系统则需要从获取原始观测资料开始,经过预处理等步骤得到模式输入数据。
- 中间数据:研发试验一般根据需要保留特定的中间数据,而业务系统为了方便查错会保留每个步骤生成的中间数据。
- 输出产品:研发试验通常没有后处理,也不制作产品,甚至在部分业务化能力评审时不包含后处理产品制作模块;业务系统则包含后处理、产品制作、产品分发等完整流程。
- 数据归档:受限于紧张的存储资源,研发试验通常只保留用于分析的简化输出数据,或者只保留分析结果(诊断、检验指标等);而业务系统则归档全流程的数据。
2.4 异常处理
系统集成第三方面的工作就是处理各种各样的异常情况。
墨菲定律 (Murphy’s Law):
凡事只要有可能出错,那就一定会出错。
If it can go wrong, it will.
实时运行的业务系统没有侥幸,只要有 BUG,就一定会出错。 反过来说,如果业务系统出错了,那很可能是因为某个未知的 BUG 导致的,所以决不能忽略任何一个故障。
系统集成就需要在流程设计和任务脚本中处理各种可能出现的异常情况。
- 业务系统要尽早报错,尽量能自动判断故障类型,输出明确的错误信息,方便运维人员快速定位故障点。 如果某个任务报错是因为它依赖的上一个任务生成了错误的结果,那么应该在上一个任务运行结束前就报错,而不是由运维人员依靠经验来判断实际的错误来源。
- 为各类异常情况开发自动处理流程,减少人工干预。 我们每天运行超过 10 万个任务,如果每类故障都需要值班员手动处理,会极大降低故障的处理效率。 比如 MESO、TYM、REPS 等区域模式使用 NCEP GFS 数据作为背景场,依赖外部数据就需要考虑数据缺失的情况。为此,业务系统脚本中增加了等待及降级机制,如果当前时次数据没到,等待一段时间再检查,如果依然没到,则会使用前一个时次的数据,如果依然有问题,则会降级使用 CMA-GFS 数据驱动。
- 如果不能自动处理,要提供故障处理预案,方便运维人员快速处理故障。比如我们专门为多个模式业务系统准备了模式积分溢出处理方案。
下面介绍三个方面的异常情况处理。
数据环境
模式试验通常都在观测数据完整的情况下开展,但实时运行的业务系统必须考虑观测资料缺失情况下的应对方案。
下图展示了业务系统中卫星资料的使用量,可以看到每天的使用量都不同,还有资料缺失的情况。
注:CMA-GFS 卫星资料使用量图片仅内部使用,下面使用 ECMWF 网站上类似的图片代替。
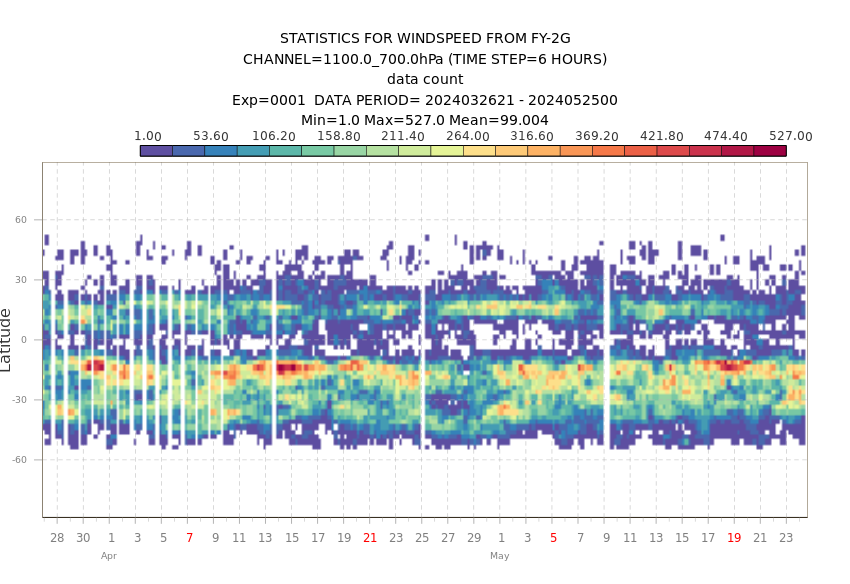
图 ECMWF 使用 FY2G 风速资料情况示意图,图片来自 ECMWF 网站
在系统集成过程中会根据资料特点及重要程度,结合运维的具体情况,来确定资料缺失情况下的应对方案。
下面代码来自 CMA-GFS 中处理 FY3C 微波辐射计资料任务 (fy3cmwhs)。 因为单个卫星资料的缺失不影响模式整体的运行情况,所以资料缺失时直接使用 set +e 忽略。
set +e
cp fy3c_amb* ${PF_ANAL}/input/atovs/
cp *txt ${DATABAK_DIR}/4DVAR_DIAG/
#----archive thin data -----------
test -d ${ARCH_obsthin} || mkdir -p ${ARCH_obsthin}
cp fy3c_amb* ${ARCH_obsthin}/
set -e
下面代码来自 CMA-MESO 3KM 的常规资料处理模块 (gts_get)。资料缺失仅在 00-09 时次报错,半夜运行的 12-21 时次不报错。 这主要是因为资料缺失需要联系相关直属单位处理,而夜间很难联系到相关技术人员,所以直接忽略。 而白天通常有充足的时间来排查故障,可以通过报错引入人工处理步骤。
ls ${GRAPES_M4DV_DIR}/data/input/GTS |grep $begintime
if [ $? -ne 0 ] && [ $HH -ge 0 -a $HH -lt 12 ]; then
echo "Failed to get conventional observations, please check it."
asdfasdf
fi
运行环境
也许大家在工作过程中会遇到类似的问题,昨天能正常运行的脚本为什么今天不能运行了?
这就和超算运行环境有关联,随着计算规模越来越庞大,超算存储系统越来越慢,超算硬件逐渐老化,超算运行环境可能会带来各种意想不到的运行故障。 业务系统中看似不知道有什么用处的异常处理代码都和超算环境有关联。
比如下面的代码来自 CMA-GEPS 的模式积分任务 (forecast),计算参数配置文件 namelist.input 的 MD5 值。 这有什么用呢? 在正常情况下没有任何用处,还会浪费 CPU 资源。但我们运维过程中确实遇到过因为 namelist.input 文件导致积分程序报错的罕见情况。 经过排查发现任务运行时的 namelist.input 和故障排查阶段看到的 namelist.input 不一样,这可能和并行共享文件系统的文件同步机制有一些关系。 所以脚本中加上了计算 MD5 值的命令,用于判断是否因为这个原因导致故障。但因为该故障过于罕见,这段代码还没发挥作用。
md5sum ./namelist.input
srun ${RUN_MODEL_DIR}/grapes_global.exe
下图展示了模式积分任务某步耗时过长的问题,一个积分步超过十分钟,正常应该只有零点几秒。 这种情况不影响模式程序继续积分,但会影响产品生成的时效,也可能会有潜在的风险。 为此我们开发了一套监控系统,能够自动识别模式任务运行超时的情况并自动发送报警信息。
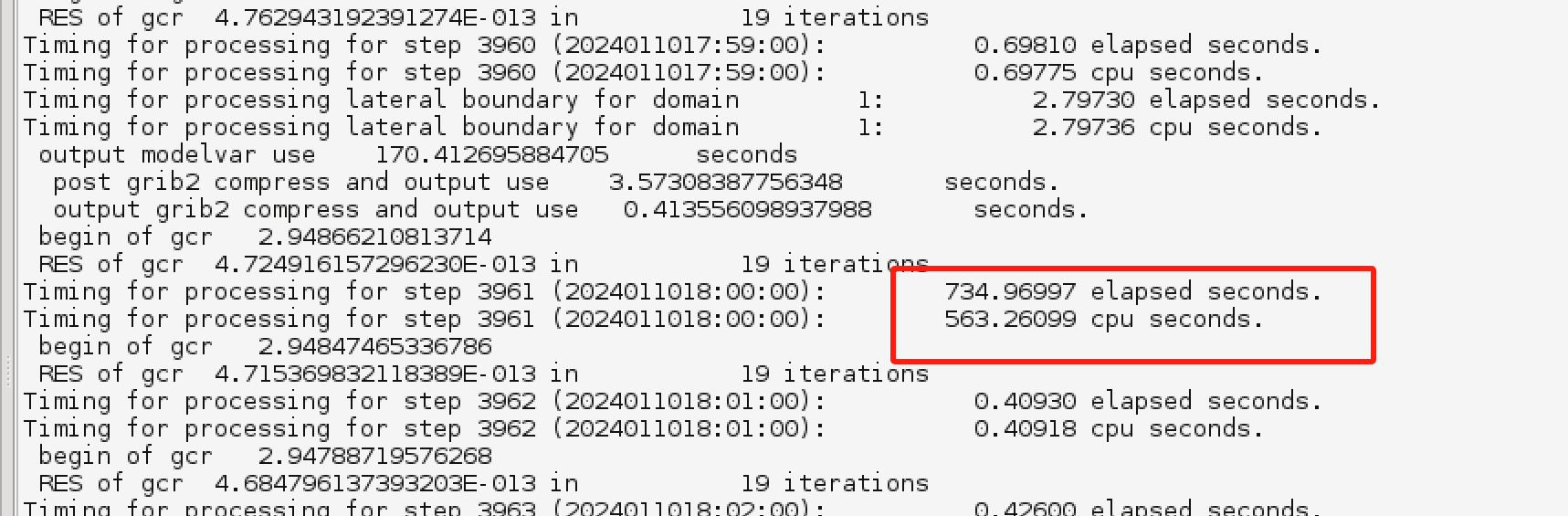
图 模式积分任务某步耗时过长
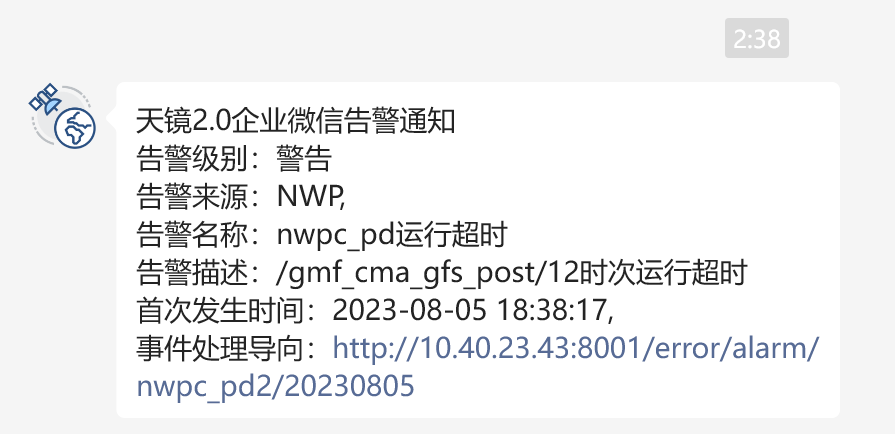
图 运行超时自动报警
但仍有一些运行环境导致的异常情况缺乏自动检测和自动处理方案。 下面两张图分别展示了 md5sum 和 ln 命令运行异常的情况。 在第一张图中,运行超时触发了 ecFlow 任务的报错代码,能正确报错。 而第二张图中,ln 命令异常导致运行脚本直接退出,没有触发 ecFlow 的报错代码,导致 ecFlow 认为该任务一直处于运行 (active) 状态,需要靠运维人员主动发现。

图 md5sum 命令运行超时
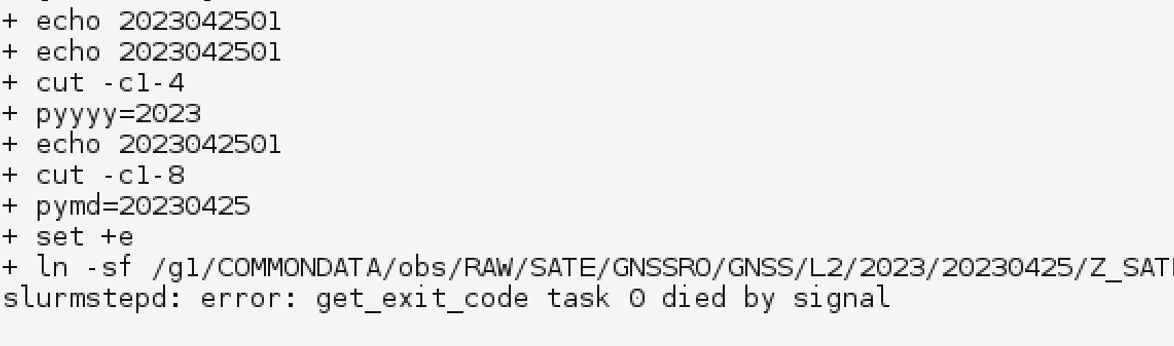
图 ln 命令运行超时
所有靠主观能动性才能发现的故障都有严重的隐患,需要寻找各种异常情况的自动检测和处理方法。因此:
- 对于业务运维人员,不要放过任何一个故障,仔细排查原因。
- 对于系统建设人员,针对每种故障研究自动识别、自动处理方法。
模式程序
复杂的程序可能因为各种原因而运行出错。模式研发和系统建设需要寻找自动处理方案,或者提供人工处理预案。
一种典型的模式程序故障是模式积分并行程序算不下去导致程序直接崩了,今年上半年业务系统模式积分溢出了 46 次。 为此我们为各个系统都准备了模式积分溢出故障处理办法。 比如针对 CMA-GFS 积分溢出故障,可以采用减少积分步长等方案重新运行。
某些程序故障可以进行自动处理。
下面代码来自 CMA-GFS 的四维变分同化任务 (an_m4dvar_HL)。 在第一次运行结束后检测日志文件中是否出现错误关键字 (DPTSV 或 SSTEQ),如果出现,则修改配置文件中的最小化方案设置并自动重新运行。
#------checking DPTSV------
line=`tail -1 std.out.0000`
echo $line
chars=$(echo $line |cut -c8-12 )
echo $chars
if [ $chars = "DPTSV" -o $chars = "SSTEQ" ]; then
echo "--------------" >> ${DATABAK_DIR}/DPTSV.error
echo ${SMSDATE}${HH} >> ${DATABAK_DIR}/DPTSV.error
echo $line >> ${DATABAK_DIR}/DPTSV.error
cat namelist.4dvar | sed "s/minimizer = 2/minimizer = 1/g" > namelist.4dvar_new
mv namelist.4dvar_new namelist.4dvar
set +e
rm -f std*
rm -f CoLM/idata/ini-g*
rm -f CoLM/odata/*
set -e
ulimit -s unlimited
module load compiler/intel/composer_xe_2017.2.174
module load mpi/intelmpi/2017.2.174
export I_MPI_PMI_LIBRARY=/opt/gridview/slurm17/lib/libpmi.so
srun --export=all --mpi=pmi2 ${BIN_DIR}/grapes4dvar.exe
sleep 20
else
echo "no DPTSV"
fi
#------end of checking DPTSV-----
下面代码来自 CMA-REPS 的模式输出结果检测任务 (copymem)。 如果集合预报的成员积分出错没有生成完整序列的结果,任务会自动拷贝控制预报 (编号00) 的积分结果到成员积分的运行目录。 也就是当 REPS 成员积分报错时不会再次运行积分程序,而是直接使用控制预报结果作为集合成员的预报结果。 当然从科学上说这样的做法有问题,但是因为产品任务不支持集合成员缺失的情况,所以这种方案主要是为了保证后续产品任务能正常运行。
print "lack output ;then copy output "
copymem=00
memdir=${DATADIR}/fcst/run${copymem}
cd ${DATADIR}/fcst/run${MEM}
print "cd ${DATADIR}/fcst/run${MEM} then cp ..."
cp -p ${memdir}/postvar${begintime}${TTT}00 .
cp -p ${memdir}/post.ctl_${begintime}${TTT}00 .
cp -p ${memdir}/modelvar${begintime}${TTT}00 .
cp -p ${memdir}/model.ctl_${begintime}${TTT}00 .
print "already copy output !!!"
3. 业务系统组织结构
下面介绍业务系统的组织结构。
3.1 业务系统流程类型
下图展示了目前系统科负责建设和运维的所有数值天气预报业务系统流程。
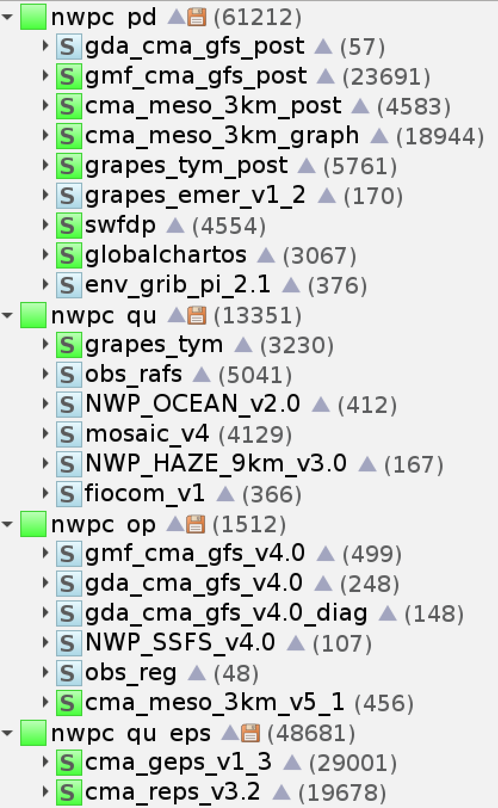
图 cemc-oper负责建设和运维的 23 个 ecFlow 工作流,均部署在 CMA-PI 超算平台中
明明只有 7 个天气模式业务,怎么 ecFlow 界面中有这么多的系统,不能将它们合并么?
这个问题就涉及到了我们是如何设计业务系统运行流程的。
我们目前的业务系统有两种类型的运行流程结构:单流程和多流程。
- 单流程:系统所有环节均在一个系统中
- 多流程:系统不同环节在不同的系统中
在我们构建业务系统时首先要考虑系统的特点与开发分工。 比如整个系统的程序都由哪几个部门负责,业务系统流程建设有几个人参与。 最简单的开发形式就是一个人负责一个系统,所以多人合作建系统天然就适合创建多个运行流程。
同时也要权衡实现难度与变更维护便捷性。 系统越复杂,流程数量越多,实现难度越高。 但从维护方面来看,多流程结构分离了系统的不同运行步骤,一个流程的修改一般不会影响另外的流程,所以适合多人同时维护。
下图展示了 CEMC 业务系统使用的流程类型。 其中 CMA-GFS 和 CMA-MESO 使用了多流程结构,CMA-TYM 处于单流程到多流程的过渡中,其他系统使用单流程结构。 我们推荐新建系统均采用多流程结构,正在开展集合预报系统的流程拆分工作,计划在下一次业务升级时将单一流程拆分为模式和后处理两个子流程。

图 CEMC 业务系统使用的流程类型,包括单流程和多流程
3.2 单流程
单流程结构是一个工作流完成全部任务,包括从观测资料获取到产品分发的全流程。
CMA-GEPS 属于典型的单流程结构,包括奇异向量计算、控制预报、成员预报和产品制作等环节。

图 CMA-GEPS 的单流程结构,包括奇异向量计算、控制预报、成员预报和产品制作等多个环节
单流程的优势:
- 任务集中,流程清晰,便于查错。所有任务都在同一个流程中,任务之间有明确的依赖关系,当任务出错时很容易顺着依赖链定位具体的故障点。
- 可以很容易地应对产品制作的数据依赖问题。比如集合预报产品任务一般要在所有成员都生成数据后才运行,可以通过 ecFlow 提供的触发器机制实现任务的调度。
单流程的劣势:
- 牵一发而动全身,任何一处修改都可能影响整个流程。每次修改都需要重新加载整个流程。
- 较难实现多人建设和多人维护。单人负责单个业务流程从管理上讲更简单。
3.3 多流程
多流程由多个工作流组合完成任务。比如 CMA-MESO 系统分成观测资料预处理、主模式和后处理三个子流程。

图 CMA-MESO 1KM 成都大运会系统由 3 个子流程构成,为了能保证系统能够正常滚动运行,将每个时次运行时间较长的主模式和后处理两个子系统 1 天 24 个时次拆分成上午、下午两个流程
多流程的优势:
- 拆分后的流程方便多人建设和多人维护。
- 每个流程可以独立修改。
- 使用不同账户运行不同流程。比如我们使用了单独的账户运行所有的后处理流程。
多流程的劣势:
- 需要设计额外流程处理数据依赖问题。因为 ecFlow 无法实现跨 ecFlow 服务的依赖关系,所以需要通过运行任务来手动实现依赖关系,比如循环检查数据是否准备好。
- 系统太多,任务分散,流程复杂,难以查错。比如模式子流程的资料预处理任务报错,可能是因为观测子流程的某个任务没有检索到资料,需要对业务系统有一定的熟悉才能快速定位故障点。
虽然多流程不方便维护,但我们有一整个经验丰富的系统建设和运维团队,随着运维经验的积累,故障定位不会成为太难的事情。 从系统建设角度考虑,笔者倾向于采用多流程结构。
3.4 未来可能的流程类型
随着我们业务系统逐步发展,当前的业务系统结构可能不适应未来的地球系统数值预报模式,我们需要探索新的业务系统流程结构。
笔者认为一种可能的趋势是将业务系统建设从不同系统间的切分转为功能模块间的切分。
比如每个系统都有观测资料预处理和产品后处理,我们是否可以构建统一的观测资料预处理系统和产品后处理系统,同时支撑不同模式的同化和积分流程。

图 预想:按功能模块切分业务系统运行流程
当然,这种方式从工程上说对现有系统改动较大,从科学上说也很难整合不同系统的观测资料预处理任务。
业务室计划从整合台风预报产品系统开始开展对业务系统运行流程改造的全新尝试,包括多个步骤:
- 建立独立的台风报文检索系统,对接相关模式系统
- 将多模式集成台风预报产品整合到同一个系统中
- 将台风预报图片产品整合到同一个系统中
流程建设与数值预报模式本身的运行方式息息相关,业务系统流程建设离不开研发同事的理解和支持,期待大家在后续工作中能够在模式运行方面带来新的思路。
4. 业务系统组件简介
下面介绍业务系统使用的一些技术。 同时也会从系统建设和运维人员角度出发,介绍业务系统目前存在的一些问题,以及需要进一步开展的一些工作。 希望能给大家后续工作带来一些启发,也希望有更多的同事能为业务系统建设工作建言献策。
4.1 资料预处理
资料预处理需要考虑的问题
资料预处理环节用于获取观测资料,并将其处理为模式可以识别的格式。
下图列出了资源预处理需要考虑的三个问题。

图 资料预处理环节需要考虑的问题
第一个问题是从哪里获取资料。业务系统需要用最快的速度拿到最全的资料。
每当增加一个新的观测资料到数值预报模式业务系统中前,首先要确定业务系统能不能在实时运行时获取到该资料,该资料的来源是否有业务级别的保障。 业务系统往往具备 7x24 小时的专业运维团队,出现故障能第一时间响应,并在有限时间内解决绝大部分故障,所以业务系统应当从业务渠道获取观测资料。 我们强烈建议所有观测资料均从 CMA 的天擎大数据云平台获取,而不要将其他渠道的观测资料引入到业务系统中。 另外,也需要考虑如何能快速地检索并处理到所需的资料,如果时间过长会显著延后模式同化和积分任务,也最终会影响产品的分发时效。 数值预报模式业务系统在刚启动时会从大量观测资料生成初始场,同一时间大量检索观测资料会带来一定的隐患,所以这也引出了下面一点。
第二个问题是什么时间检索资料。确定资料检索时间点(即资料截断时间)是构建数值预报业务系统最重要的一环。
资料截断时间决定模式什么时间启动运行,也决定了如何设计观测资料检索流程。 前面老师介绍了并行计算相关内容,数值模式的并行优化非常具有挑战性,需要既熟悉模式代码又熟悉并行计算技术的专业技术人才,将模式积分运行时间减少十分钟、二十分钟都需要开展大量的技术研发工作,并行优化也是 CEMC 计算室的核心工作任务之一。 假如我们将模式启动时间提前二十分钟呢,只需要修改一行代码就可以实现,但问题在于,不知道提前运行对业务系统的预报效果会有什么样的影响。 这就需要咱们同化室和卫星室的同事来研究不同的截断时间对模式预报效果的影响。 甚至只要一部分资料可以提前检索并处理,就可以将这些资料放到单独的资料预处理流程中提前运行。 这样既节省了模式预报前的资料准备时间,又给处理资料故障留有更充裕的时间。 欢迎感兴趣的同事开展观测资料截断时间的相关研究。
第三个问题是资料缺失该怎么办。缺失资料是否会影响模式正常运行,同时也决定系统是否需要人工干预。
业务系统的特点就是任何想到和想不到的情况都可能发生。 作为数值模式业务系统外部输入信息的观测资料受多种因素影响可能会发生资料缺失的问题。 那么,每当引入一个新的资料到业务系统时,都需要考虑如果该资料缺失了该怎么办。 如果资料缺失对模式预报效果的影响很小,那么业务流程中则会直接忽略该资料,进行后续任务。 如果资料缺失对模式预报效果的影响很大,那么资料缺失会导致模式运行中断,需要运维人员人工干预。 不过,需要注意的是,所有需要人工干预的步骤都有不确定性,人工操作可能会滞后,也可能会误操作。 所以需要根据每个系统的实际情况来确定如何处理资料缺失故障。
比如区域模式系统使用美国 NCEP GFS 预报数据作为背景场。 业务会查找当前时次的 NCEP GFS 数据是否到达,如果没有则查找上一个预报时次的数据是否到达,如果再没有则会切换到 CMA-GFS 数据。 上述流程均自动实现,无需人工干预。
以上三个问题中,第一个问题需要由系统建设同事来制定运行策略,而后两个问题则是由模式研发同事来决定运行策略。
业务系统使用观测资料的方式
目前业务系统通过三种方式使用观测资料:
- 使用天擎 MUSIC 接口检索资料
业务系统使用 MUSIC 的 Fotran 和 Python SDK 从国家级天擎服务检索观测资料。
资料种类包括
- 常规观测
- 地面观测站
- 探空
- 飞机
- 云导风
- CLDAS
- 台风报文
- …
这些资料数据量较小,检索速度快。常规资料对模式效果影响比较大,所以常规资料缺失会导致系统报错,需要运维同事及时排查故障原因并联系相关部门处理。
- 直接向 HPC 推送观测资料或直接使用 HPC 上的资料
资料种类包括:
- 卫星
- 雷达
- NCEP GFS预报产品
- CMA-RA 再分析产品
- …
这些资料数据量较大,原始资料都是多个文件的形式。 如果在业务启动时间检索,会在短时间内占用大量网络带宽,影响天擎的稳定性。 所以将资料检索的过程前移,每当 CTS 接收到一个资料文件,就会将该文件直接推送到 HPC 的特定目录,在更长的时间段内完成网络传输任务。 业务系统启动后直接访问推送目录获取相应的资料,仅进行资料预处理,而不再执行资料检索操作。 这也是业务系统最常用的资料获取方式。
- 从直属单位等其他来源获取观测资料
资料种类包括:
- NMC 台风报文
- NSMC FY4A 部分资料
- …
这类资料主要是因为历史原因或其他原因导致无法使用前两种方式检索。 在业务系统建设过程中,我们通常不接收这类观测资料,因为无法保证该资料是否具有业务维护级别。
为了减少业务运行高峰时间段大量下载资料占用网络带宽,降低对天擎检索压力,推荐使用直接推送 HPC 方式。
资料预处理系统种类
观测资料预处理系统分为两类。
第一种是单独的观测资料预处理系统。 提前处理观测资料,减少模式预报主流程中预处理环节的时间。 有助于尽早发现资料缺失等问题,保证模式预报主流程按时运行。
下图列出了 CMA-MESO 3KM 系统的观测检索任务。 模式主流程中的资料预处理任务 (obs4an_get, obs4others_get) 使用的观测资料来自 2 个观测资料检索子流程获取的数据 (obs_rafs, mosaic_v4)。

图 CMA-MESO 观测资料检索,包括 2 个观测资料检索子流程
第二种是集成到模式流程中的观测资料预处理环节。 在模式启动时间点运行是为了使用尽可能多的观测资料。 通常直接使用推送到 HPC的观测资料,而不是从天擎大量检索数据。
下面给出了两个示例。 CMA-GFS 系统在模式启动时处理观测资料,包括常规观测、卫星观测、海温、陆面同化数据、台风报文等等资料。 CMA-TYM 系统在模式启动时处理当前时次的 NCEP GFS 背景场,等待 15 分钟不到则使用上一时次背景场 (前 6 小时)。

图 集成到模式流程中的观测资料预处理环节
观测资料检索程序
业务系统使用了封装天擎 MUSIC 接口 Fortran SDK 的应用程序检索观测资料。 该程序在 INI 配置文件中设置非时间参数,并通过命令行写入的方式获取时间参数。

图 CEMC 业务系统观测资料检索程序,时间参数通过命令行提供
配置文件示例如下所示:
[RSURF_CH]
data_logo_f=GM_RSURF_CH
dtype_f=RGWST
data_name_f=Hourly observations of surface data in China
MaxFltRet_f=20500000
MaxStrRet_f=520000
interfaceId_f=getSurfEleInRectByTimeRange
datacode_f=dataCode=SURF_CHN_MUL_HOR
bracket_l=[
bracket_r=)
elements_f=elements=Station_Id_d,Lat,Lon,Alti,Day,Hour
eelements_f=PRS_Sea,TEM,DPT,WIN_D_INST,WIN_S_INST,PRE_1h,PRE_6h,PRE_24h,PRS
qelements_f=Q_PRS_Sea,Q_TEM,Q_DPT,Q_WIN_D_INST,Q_WIN_S_INST,Q_PRE_1h,Q_PRE_6h,Q_PRE_24h,Q_PRS,Station_Id_C
num_head_f=6
minLat_f=minLat=3.51
maxLat_f=maxLat=53.33
minLon_f=minLon=73.33
maxLon_f=maxLon=135.05
paramCnt_f=8
orderBy_f=orderBy=Station_Id_d:asc
data_type_f=1
mode_type_f=1
filename_f=rec_RGWST_~_&_-.dat
savePath_f=./data/
webdataPath_f=./webdata_interface/GM
webdataname_f=GM_RSURF_CH-~.json
4.2 资料同化与模式积分
资料同化与模式积分程序都是大规模并行程序,需要大量计算和存储资源。
不能在业务时限内提供产品的业务系统是没有实际应用价值的。 并行程序需要权衡时效性和稳定性,也需要考虑HPC平台的计算能力。
当设计业务系统并行程序的运行方案时,需要综合考虑三个因素:
- 时效性:业务系统算得越快越好。即使出错了也留有足够的时间进行故障处理。
- 稳定性:出错重算会严重影响时效。因为我们的模式系统没有断点重启机制,所以模式出错后需要从头开始算,运行时间直接翻倍。
- 计算能力:是否影响其他业务系统。随着业务系统越来越多,需要考虑超算平台的总体计算能力,合理安排模式运行时间和计算资源。
下图给出了 CMA-GFS V4.0 业务升级前粗略统计的业务运行高峰时间段计算资源情况。 可以看到在 GFS、MESO、TYM 和 GEPS 重叠运行的时段内,系统需要使用的总节点大于整个超算平台的总节点数,这就意味着后运行的 GEPS 系统有部分集合成员积分任务会排队,等待 GFS 积分任务运行结束释放资源后才能实际运行。
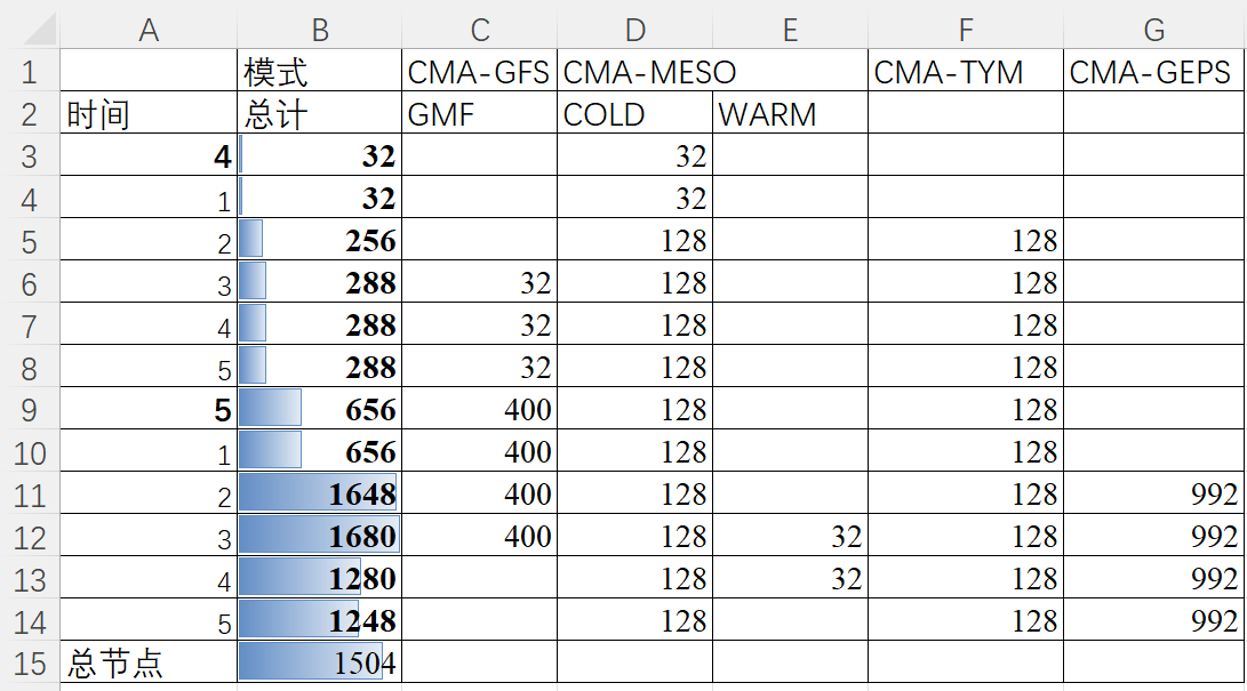
图 业务运行高峰时间段计算资源统计,粗略统计
目前,我们的业务系统规模已经到了需要考虑超算平台整体计算能力的阶段,而不仅仅是业务与研发计算资源的占比问题。 好在今年新建的超算平台将极大增强计算能力,不过我们还有更多的业务系统升级尚未完成,计算能力永远赶不上业务需求。 期望大家在后续工作中能充分优化程序运行性能,提高并行效率。
在设计运行流程时,通常会将一些关键参数设置为 ecFlow 变量,方便运维同事在 ecFlow 图形界面中修改。 比如下图展示的 CMA-GFS 将模式积分步长作为 ecFlow 变量,CMA-MESO 则设置了一系列开关项用于控制任务运行。

图 业务系统使用 ecFlow 变量设置关键参数
4.3 产品后处理
产品后处理环节是将模式原始输出转换为模式产品,进一步生成定制产品并完成产品分发。
下图展示了 CEMC 数值天气预报模式业务系统产品后处理环节的基本流程。 模式积分生成二进制格式的模式面数据 (modelvar),统一后处理程序根据模式面数据计算生成两种类型的 GRIB2 数据。 一种数据是模式面的 GRIB2 数据,主要采用压缩技术减少文件大小。另一种是用于提供预报服务的基础 GRIB2 数据产品,主要包含等压面、地面等层次类型。 后处理系统对基础 GRIB2 数据产品进行二次加工,生成其他数据产品,同时也使用基础 GRIB2 数据绘制图片产品。 数据产品和图片产品通过 FTP 等方式完成产品分发。

图 数值预报业务系统中产品后处理环节的基本流程
产品分发渠道主要分为两种形式:
FTP
- NMIC CTS FTP 服务器。数据产品最重要的分发渠道,上传天擎、下发省局的产品全部通过 CTS 转发。
- NMC MICAPS FTP 服务器。向 MICAPS 服务器直接发送 GRIB2 数据,提供预报员使用。未来可能会被 CTS 转发替代。
- NMC 图片产品库 FTP 服务器。CEMC 尚未建立自己的图片产品库,内外网网站图片展示均使用 NMC 的图片产品库。
- 各直属单位其他 FTP 服务器。在某些特殊情况下,会直接向大院内 FTP 服务器直接传输产品。 不过每个单位对 FTP 服务的维护力度各不相同,这种方式已不再推荐,业务室会严格控制新增接入的 FTP 服务地址。
HPC 专用队列
- 二级存储。超算系统中只有部分节点可以挂载了二级存储 NAS,使用专用队列可以访问到挂载后的二级存储。
产品后处理中最常见的两个任务是数据处理和图形绘制。
数据处理
CEMC 数值天气预报业务系统中的数据处理任务使用了一些开源工具,主要包括:
- wgrib2:使用 wgrib2 抽取要素场,或者将 GRIB2 要素转为 GrADS 可以直接读取的二进制格式
- eccodes:少部分任务使用 eccodes 的命令行工具,比如使用 grib_copy 将多个文件合并为一个文件
- NCL / GrADS:一部分任务使用 NCL 或者 GrADS 脚本来处理数据,比如用 NCL 抽取站点数据并生成 NetCDF 格式文件等
- python:较多应用在观测资料预处理任务中,产品后处理也逐渐开始采用 Python 实现
同时,CEMC 也开发了一系列用于数据处理的 Fortran 程序:
- GRIB_UTIL:由业务室老师开发的 GRIB 编解码工具。 包括 GRIB2 编码静态链接库,及 GRIB2 数据处理和 GrADS 转 GRIB2 的命令行工具,几乎应用在 CEMC 所有的天气预报业务系统中。 当前业务应用的版本依赖 ECMWF 的 GRIB_API 实现 GRIB2 编解码,GRIB_UTIL 的最新版本已实现编解码技术的自研,不再依赖 GRIB_API,将在后续的业务系统升级中全面替代现有版本。
- 面向特定需求开发的 Fortran 程序。比如集合预报产品需要计算多成员的概率、分位数、最值等等,通常使用 Fortran 实现。
图形绘制
绘制图片使用的主要工具:
- NCL
- GrADS
- Python(matplotlib + basemap)
大部分图片均使用 NCL 和 GrADS 绘制,少部分图片使用 Python 绘制。 因为 NCL 已于 2019 年停止更新,未来使用 Python 绘图将成为趋势。
图 绘图示例
4.4 数据归档
数据归档目录是不同系统对接的基础。 业务系统一般有 4 种目录。
- 运行目录:程序运行的原始目录,下一次运行前会被清空
- 临时归档目录:运行空间的临时归档目录,保留最近数据(3天左右),用于查错
- HPC归档目录:HPC 共享目录,保留较长时间数据(半年左右)
- 二级存储目录:历史数据归档目录,保留更长时间数据。
前三个目录均在超算的共享文件系统中,可以直接访问。二级存储需要使用特殊方式访问。
业务系统一般都有专门的任务负责将数据拷贝到归档目录。 下图展示了 CMA-TYM 模式主流程中的模式积分进度监控与数据归档任务。 grapes_monitor 任务负责监控模式积分运行的进度,按照模式输出时效顺序检查文件是否存在,每检测到一个文件就修改任务的标尺值,触发后续的数据拷贝任务。 copy_output 任务将模式生成的数据拷贝到临时归档目录和 HPC 归档目录。
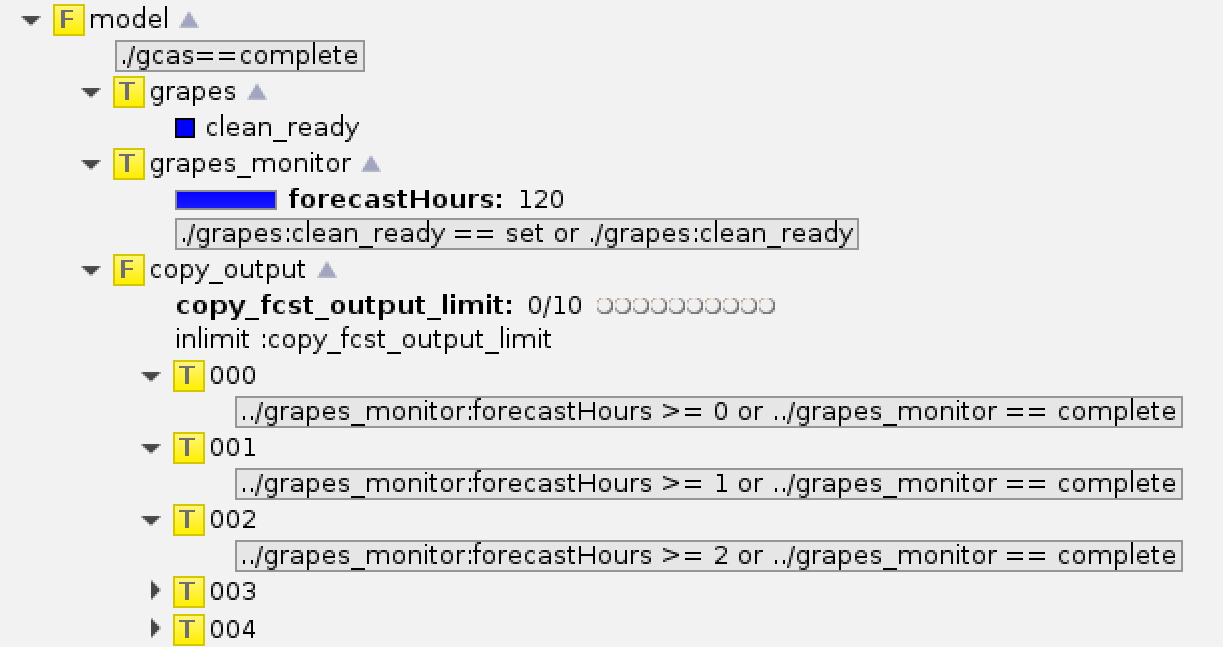
图 CMA-TYM 模式主流程,积分进度监控与数据归档任务
5. 总结
本文介绍了四个方面的内容,包括
- 业务系统简介
- 业务集成工作介绍
- 业务系统组成结构
- 业务系统组件简介
希望通过前面的介绍让大家对业务系统集成建设有初步的了解。
当前业务系统建设还存在很多问题,期望大家在后续工作中能多多参与到业务建设工作中,为业务系统建言献策。