ISLR实验:简单线性回归
本文源自《统计学习导论:基于R语言应用》(ISLR) 中《3.6 实验:线性回归》章节
简单线性关系
$$ Y \approx \beta_{0} + \beta_{1}X $$
通过拟合计算模型参数 \beta_{0} 和 \beta_{1},使用下面的表达式计算预测值
$$ \hat{y} = \hat{\beta_{0}} + \hat{\beta_{1}}X $$
评价准确性
假设 X 和 Y 之间的真实关系可以表示为
$$ Y = \beta_{0} + \beta_{1}X + \epsilon $$
其中:
- beta_{0} 是截距,当 X=0 时 Y 的值
- beta_{1} 是斜率,当 X 增加一个单位是 Y 的平均增幅
- epsilon 是均值为零的随机误差项
残差
观测到的响应值和用线性模型预测出的响应值之间的差距
$$ e_{i} = y_{i} - \hat{y_{i}} $$
残差平方和
residual sum of squares,RSS
$$ RSS = e_{1}^{2} + e_{2}^{2} + \cdots + e_{n}^{2} $$
在简单线性回归中 RSS 等价为
$$ RSS = (y_{1} - \hat{\beta_{0}} - \hat{\beta_{1}}x_{1})^2 + (y_{2} - \hat{\beta_{0}} - \hat{\beta_{1}}x_{2})^2 + \cdots + (y_{3} - \hat{\beta_{0}} - \hat{\beta_{1}}x_{n})^2 $$
标准误差
standard error
用样本均值估计总体均值
$$ Var(\hat{\mu}) = SE(\hat{\mu})^2 = \frac {\sigma ^2} {n} $$
其中 \sigma 是变量 Y 的每个实现值 y_i 的标准差
残差标准误
residual standard error,RSE
RSE 是对 \epsilon 的标准偏差的估计。 大体而言,RSS 是响应值会偏离真正的回归直线的平均量
$$ RSE = \sqrt{\frac {1} {n-2} RSS} = \sqrt{\frac {1} {n-2} \sum_{i=1}^{n}(y_i - \hat{y_i})^2} $$
t 统计量
标准误差可以用来对系数进行假设检验:
- 零假设:X 和 Y 之间没有关系,即 beta_1 = 0
- 备择假设:X 和 Y 之间有一定的关系,即 beta_1 != 0
为了检验零假设,需要确定 \hat{\beta_1} 距离零是否足够远
下面的 t 统计量测量 beta_1 偏离 0 的标准偏差。
$$ t = \frac {\hat{\beta_1} - 0} {SE(\hat{\beta_1})} $$
如果 X 和 Y 无关,则上式将服从自由度为 n-2 的 t 分布。
p 值
p-value
假设 beta_1 = 0,任意观测值大于等于 |t| 的概率是 p 值。
粗略地说,p 值可以解释如下:
一个很小的 p 值表示,在预测变量和响应变量之间的真实关系位置的情况下,不太可能完全由于偶然而观察到预测变量和响应变量之间的强相关。 因此,如果看到一个很小的 p 值,就可以推断预测变量和响应变量之间存在关联。
如果 p 值足够小,我们则拒绝零假设,即声明 X 和 Y 之间存在关系。
总平方和
total sum of squares,TSS
测量响应变量 Y 的总方差
$$ TSS = \sum_{i=1}^{n} (y_i - \hat{y})^2 $$
TSS 可以认为是在执行线性回归之前响应变量中的固有变异性
相应的,RSS 测量的是进行回归后仍无法解释的变异性。
因此 RSS - TSS 测量的是响应变量进行线性回归之后被解释的(或被消除)的变异性
R^2 统计量
$$ R^2 = \frac{TSS - RSS} {TSS} = 1 - \frac{RSS} {TSS} $$
R^2 测量的是 Y 的变异中能被 X 解释的部分所占比例。
相关性
correlation
$$ Cor(X, Y) = \frac {\sum_{i=1}^{n} (x_i - \bar{x}) (y_i - \bar{y})} { \sqrt{\sum_{i=1}^{n} (x_i - \bar{x})^2} \sqrt{\sum_{i=1}^{n} (y_i - \bar{y})^2} } $$
对于简单线性回归模型,R^2 = r^2,r = Cor(X, Y)
准备
library(MASS)
library(ISLR)数据
使用 MASS 包的 Boston 数据集,记录波士顿周围 506 个街区的 medv 房产中位数
head(Boston)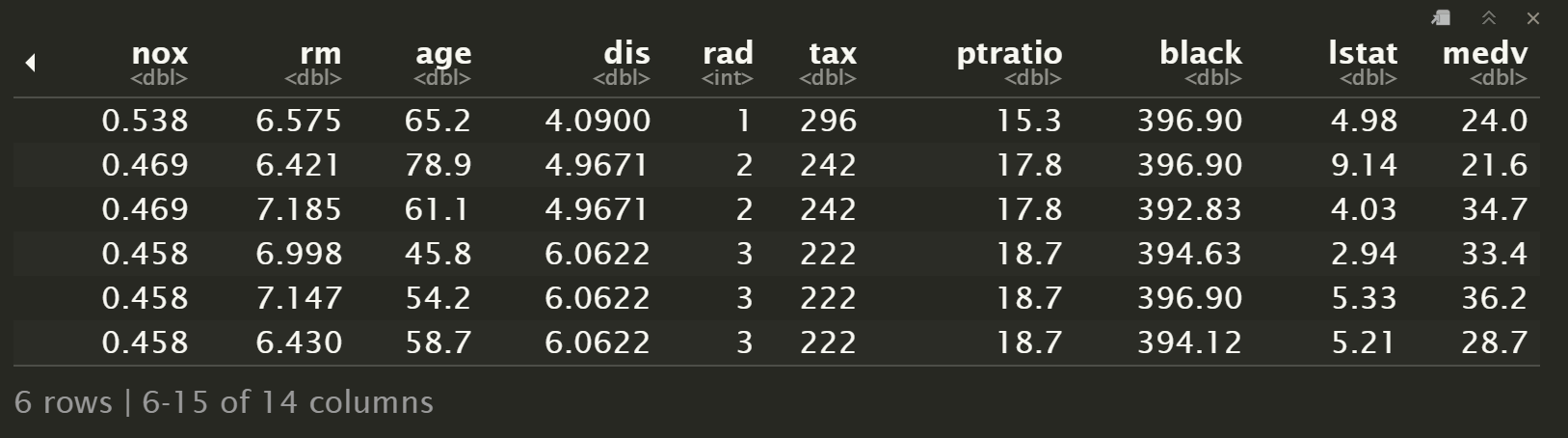
names(Boston)[1] "crim" "zn" "indus" "chas" "nox" "rm" "age" "dis"
[9] "rad" "tax" "ptratio" "black" "lstat" "medv"
拟合
使用 lm() 函数拟合一个简单线性回归模型,将 lstat 作为预测变量,medv 作为响应变量
lstat:社会经济地位低的家庭所占比例medv:房产价值中位数 ($1000s)
lm() 的基本语法
lm(y~x, data)其中 y 是响应变量,x 是预测变量,data 是数据集
lm.fit = lm(medv~lstat, data=Boston)如果使用 attach() 绑定数据集,可以不指定 data 参数
attach(Boston)
lm.fit = lm(medv~lstat)直接输入变量,显示基本信息,包括截距和系数
lm.fitCall:
lm(formula = medv ~ lstat)
Coefficients:
(Intercept) lstat
34.55 -0.95
使用 summary() 函数显示更详细的信息,包括
- 残差 (Residuals)
- 系数估计值 (Estimate),标准误 (Std. Error),t 值 (t value) 和 p 值 (Pr(>|t|)
- 模型的残差标准误 (Residual standard error), R^2 统计量 (R-squared) 和 F 统计量 (F-statistic)
summary(lm.fit)Call:
lm(formula = medv ~ lstat)
Residuals:
Min 1Q Median 3Q Max
-15.168 -3.990 -1.318 2.034 24.500
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 34.55384 0.56263 61.41 <2e-16 ***
lstat -0.95005 0.03873 -24.53 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 6.216 on 504 degrees of freedom
Multiple R-squared: 0.5441, Adjusted R-squared: 0.5432
F-statistic: 601.6 on 1 and 504 DF, p-value: < 2.2e-16
使用 names() 函数列出 lm.fit 对象中存储的信息
names(lm.fit) [1] "coefficients" "residuals" "effects" "rank" "fitted.values"
[6] "assign" "qr" "df.residual" "xlevels" "call"
[11] "terms" "model"
可以使用以上名称访问对象的组件
lm.fit$coefficients(Intercept) lstat
34.5538409 -0.9500494
可以使用 coef() 等函数以更安全的方式提取
coef(lm.fit)(Intercept) lstat
34.5538409 -0.9500494
使用 confint() 函数获取系数的置信区间
confint(lm.fit) 2.5 % 97.5 %
(Intercept) 33.448457 35.6592247
lstat -1.026148 -0.8739505
预测
使用 predict() 函数进行预测
predict(
lm.fit,
data.frame(
lstat=c(5, 10, 15)
)
) 1 2 3
29.80359 25.05335 20.30310
predict() 函数还同时支持计算置信区间和预测区间
置信区间 (confidence interval) 针对样本的统计量,这里用的是均值
predict(
lm.fit,
data.frame(
lstat=c(5, 10, 15)
),
interval="confidence"
) fit lwr upr
1 29.80359 29.00741 30.59978
2 25.05335 24.47413 25.63256
3 20.30310 19.73159 20.87461
预测区间 (prediction interval) 针对样本本身
predict(
lm.fit,
data.frame(
lstat=c(5, 10, 15)
),
interval="prediction"
) fit lwr upr
1 29.80359 17.565675 42.04151
2 25.05335 12.827626 37.27907
3 20.30310 8.077742 32.52846
绘图
绘制 medv 和 lstat 的散点图和最小二乘回归直线
plot(lstat, medv)
abline(lm.fit)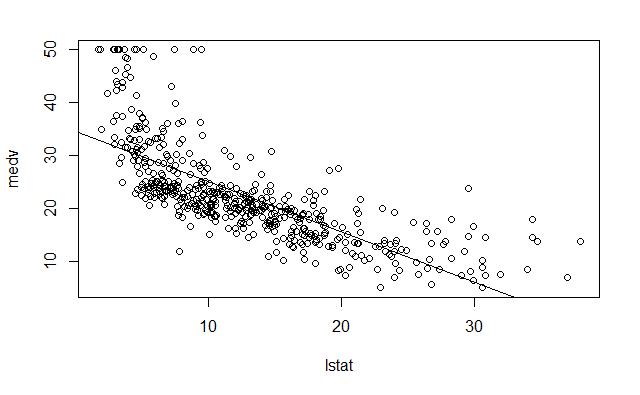
lwd 参数设置线宽,pch 参数选择不同的图形符号
plot(lstat, medv, col="red")
abline(lm.fit, lwd=3)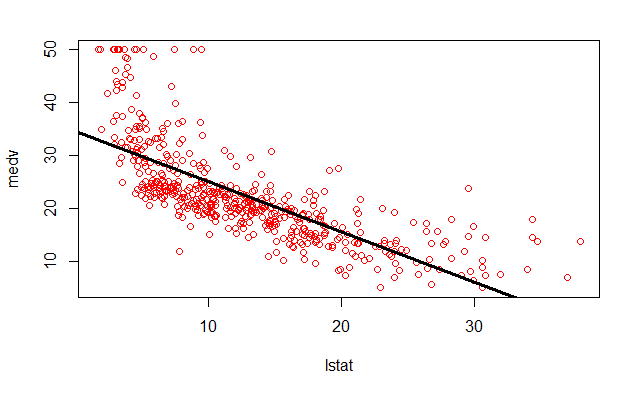
plot(lstat, medv, pch=20)
abline(lm.fit, lwd=3, col="red")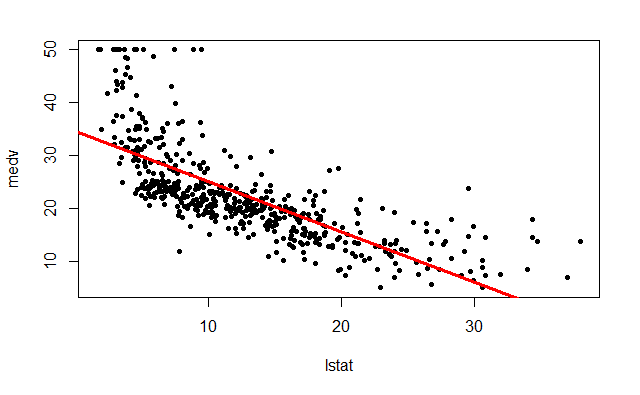
plot(lstat, medv, pch="+")
abline(lm.fit)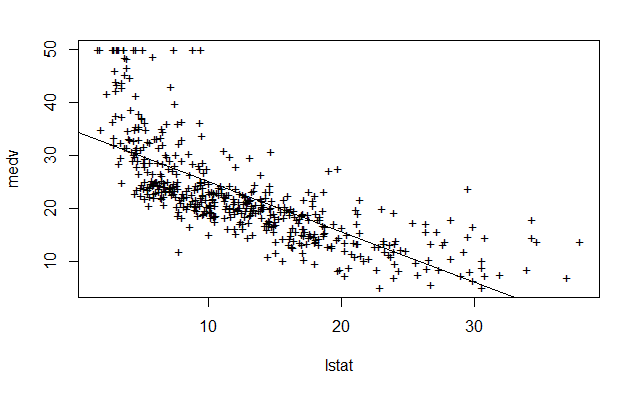
绘制 pch 参数支持的前 20 种符号
plot(1:20, 1:20, pch=1:20)
多图显示
对 lm() 的输出直接调用 plot() 函数会自动生成四幅诊断图。
使用 par() 函数将显示屏分为不同的面板,支持同时显示多张图片
par(mfrow=c(2, 2))
plot(lm.fit)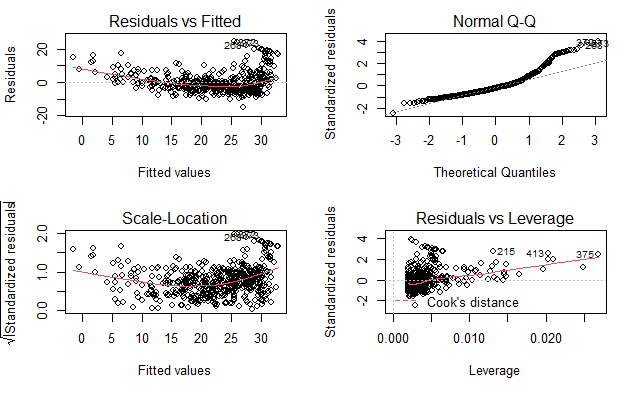
第一幅图:残差图 (residual plot)
残差与预测值(或拟合值)的散点图。 理想情况下,残差图显示不出明显的规律
第二幅图
绘制标准化残差的平方根与拟合值的散点图。
第三幅图
绘制学生化残差 (standardized residuals) 图
学生化残差由残差 e_i 除以它的估计标准误得到
学生化残差绝对值大于 3 的观测点可能是离群点
第四幅图
绘制杠杆统计量 (leverage statistic) 与学生化残差的关系
杠杆统计量
$$ h_i = \frac {1} {n} + \frac {(x_i - \bar{x})^2} {\sum_{i=1}^{n} (x_i - \bar{x})^2} $$
手动计算
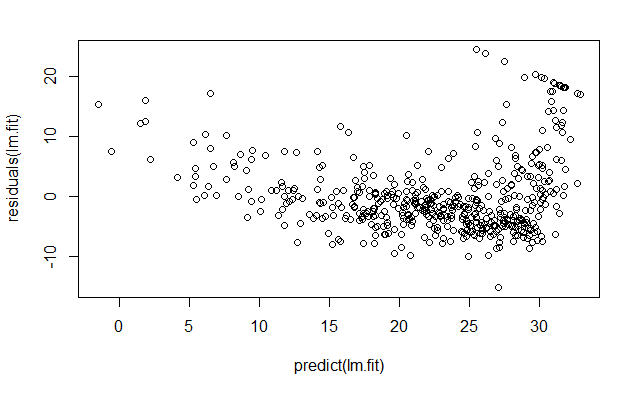
residuals() 函数计算线性回归拟合的残差
plot(
predict(lm.fit),
residuals(lm.fit)
)
rstudent() 计算学生化残差
plot(
predict(lm.fit),
rstudent(lm.fit)
)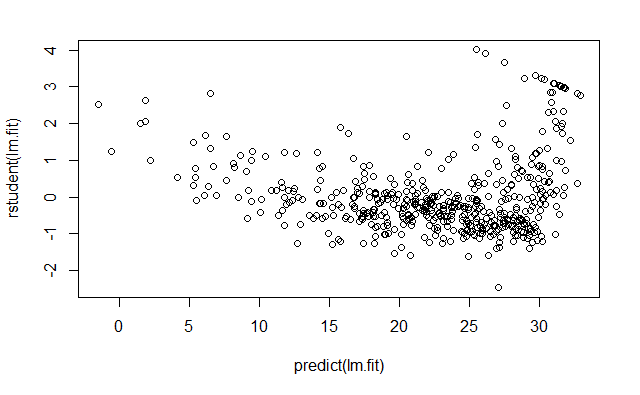
残差图中的一些证据表明数据有非线性 (?)
hatvalues() 函数计算预测变量的杠杆统计量
plot(hatvalues(lm.fit))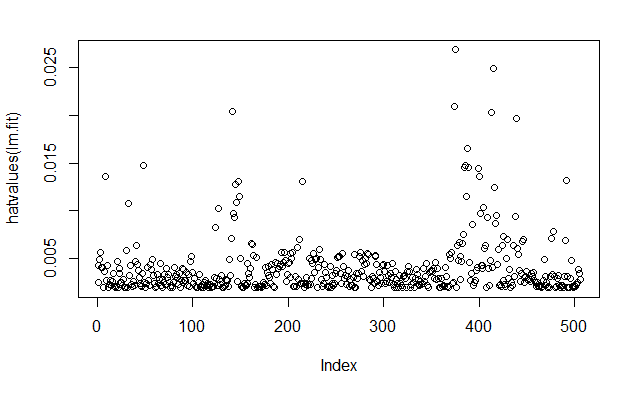
which.max() 函数可用于识别向量中最大元素的索引,找出具有最大杠杆统计量的观测
which.max(hatvalues(lm.fit))375
375
参考
https://github.com/perillaroc/islr-study
ISLR实验系列文章
线性回归
分类
重抽样方法
线性模型选择与正则化