学习R语言:数据框
目录
本文内容来自《R 语言编程艺术》(The Art of R Programming),有部分修改
数据框 (data.frame) 类似矩阵,有行和列,但数据框中的每一列可以使不同的模式 (mode)。
创建数据框
kids <- c("Jack", "Jill")
ages <- c(12, 10)
d <- data.frame(
kids, ages,
stringsAsFactors=FALSE
)
print(d) kids ages
1 Jack 12
2 Jill 10
stringsAsFactors 参数用于将字符串转换为因子 (factor),默认值为 TRUE。
访问数据框
数据框是一个列表,可以通过索引或者组件名访问
print(d[[1]])[1] "Jack" "Jill"
print(d$kids)[1] "Jack" "Jill"
可以使用类似矩阵的方式
print(d[, 1])[1] "Jack" "Jill"
str() 函数查看数据框
str(d)'data.frame': 2 obs. of 2 variables:
$ kids: chr "Jack" "Jill"
$ ages: num 12 10
扩展案例:考试成绩的回归分析(续)
score <- read.csv("../data/student-mat.csv", header=T)
head(score)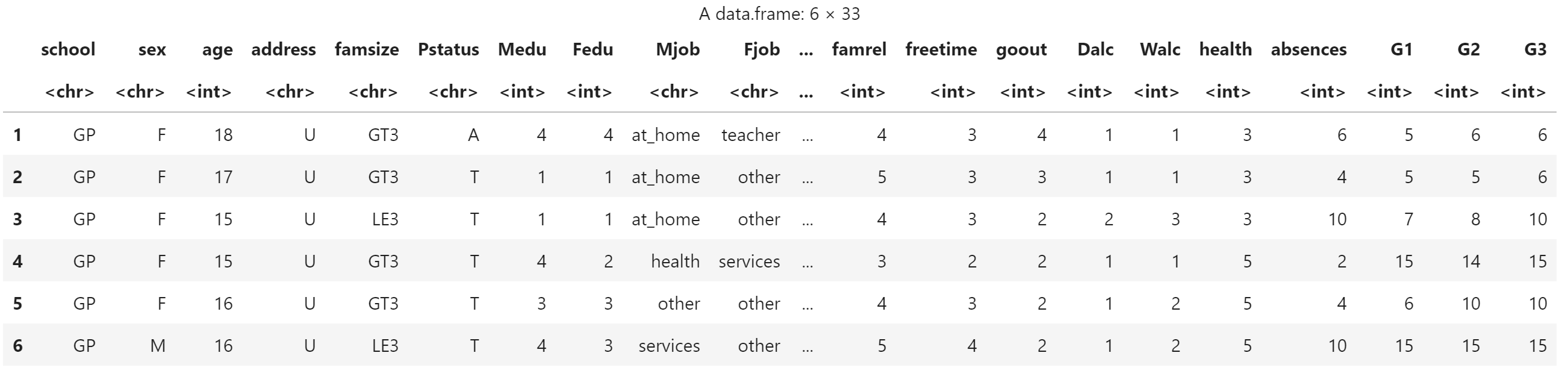
其他矩阵式操作
矩阵操作可以应用到数据框中
提取子数据框
score[2:5,]
print(score[2:5, 32])[1] 5 8 14 10
print(class(score[2:5, 32]))[1] "integer"
print(score[2:5, 32, drop=FALSE]) G2
2 5
3 8
4 14
5 10
print(class(score[2:5, 32, drop=FALSE]))[1] "data.frame"
筛选
score[score$G1 > 17,]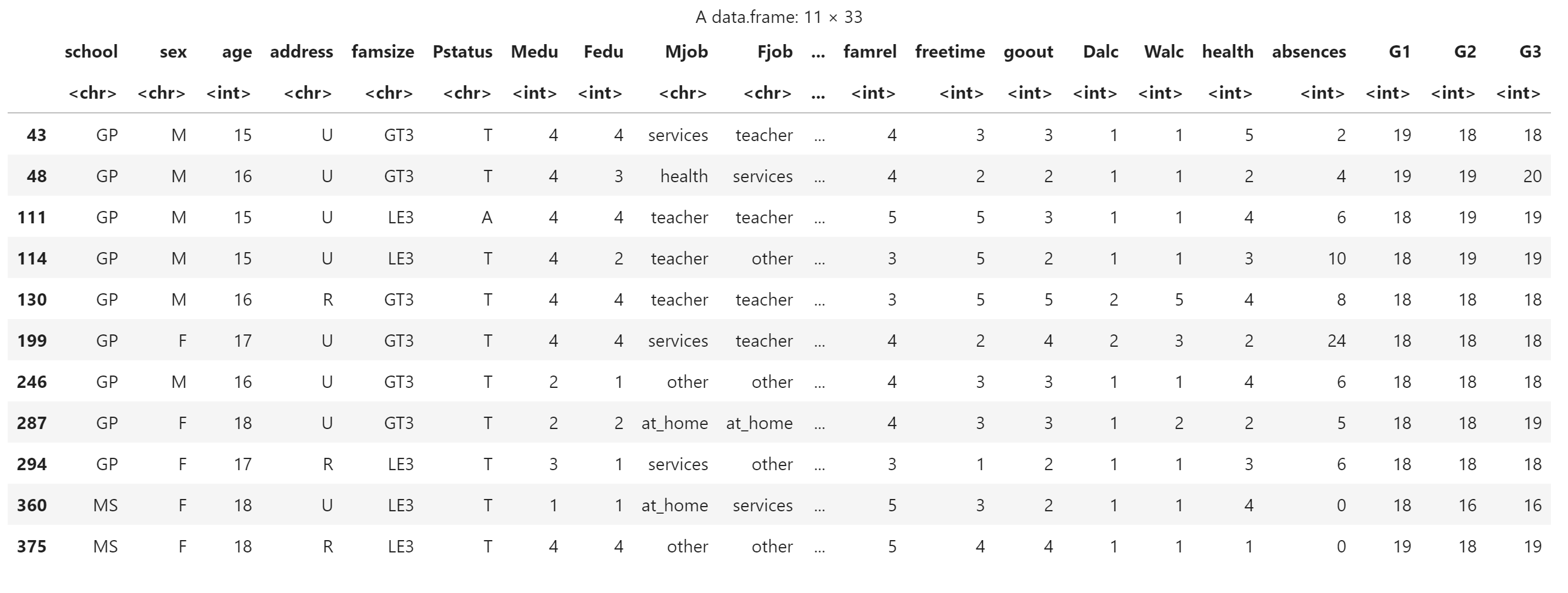
处理缺失值
R 会尽量处理缺失数据,但有些时候需要指定 na.rm=TRUE 告诉函数忽略缺失值
x <- c(2, NA, 4)
print(mean(x))[1] NA
print(mean(x, na.rm=TRUE))[1] 3
subset() 函数会自动忽略缺失值
subset(score, G1>17)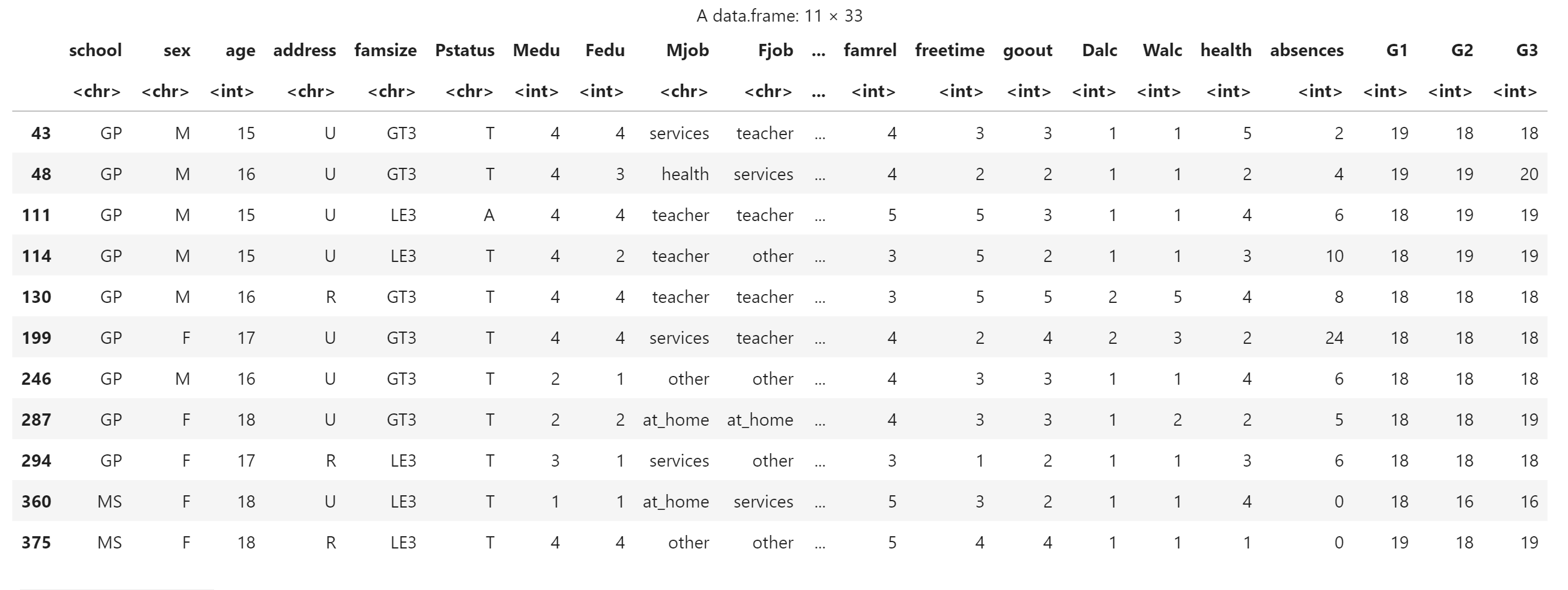
complete.cases() 去掉含有缺失值的观测
kids <- c("Jack", NA, "Jillian", "John")
states <- c("CA", "MA", "MA", NA)
d4 <- data.frame(
kids,
states,
stringsAsFactors=FALSE
)
print(d4) kids states
1 Jack CA
2 <NA> MA
3 Jillian MA
4 John <NA>
print(complete.cases(d4))[1] TRUE FALSE TRUE FALSE
d5 <- d4[complete.cases(d4),]
print(d5) kids states
1 Jack CA
3 Jillian MA
使用 rbind() 和 cbind() 等函数
两个数据框必须有相同的行数或列数
rbind() 添加新行时,添加的行通常是数据框或列表
print(d) kids ages
1 Jack 12
2 Jill 10
print(rbind(
d,
list("Laura", 19)
)) kids ages
1 Jack 12
2 Jill 10
3 Laura 19
使用原有列创建新列
eq <- cbind(
score,
score$G2 - score$G1
)
print(class(eq))[1] "data.frame"
head(eq)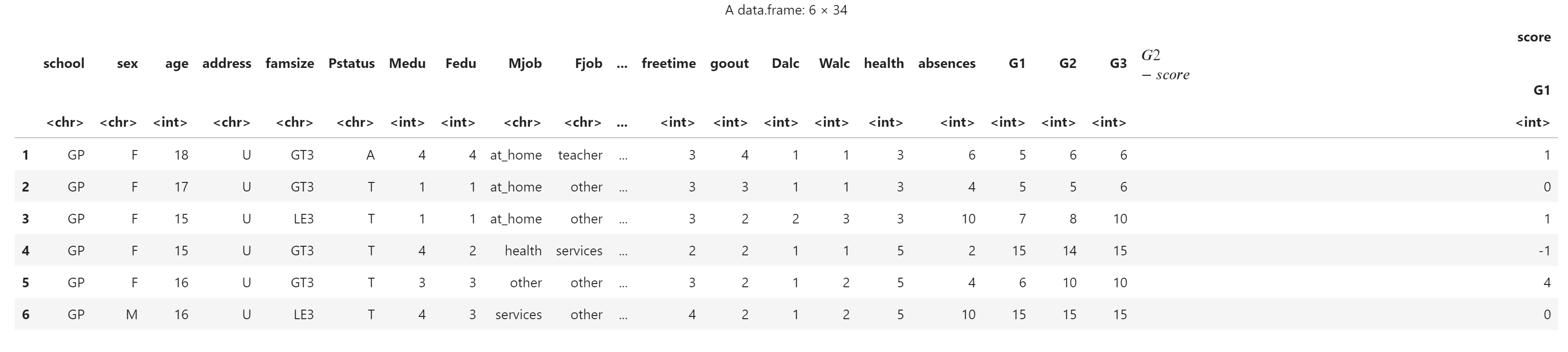
使用数据框的列表属性,增加新列
score$GDiff <- score$G2 - score$G1
head(score)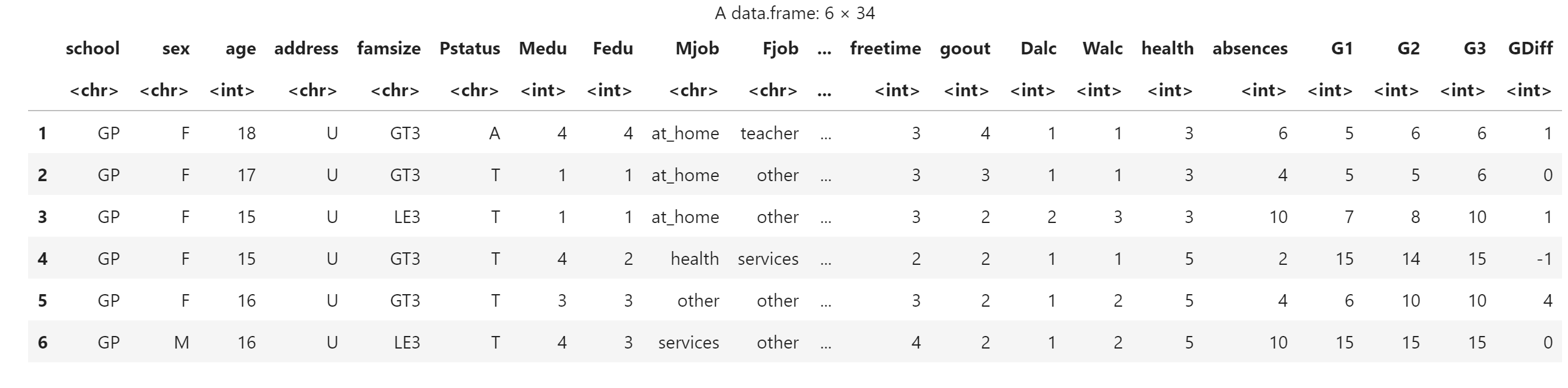
属性方式添加新列也支持循环补齐
print(d) kids ages
1 Jack 12
2 Jill 10
d$ones <- 1
print(d) kids ages ones
1 Jack 12 1
2 Jill 10 1
使用 apply()
如果数据框中的每一列数据类型相同,可以使用 apply() 函数
exam <- score[,31:33]
print(head(exam)) G1 G2 G3
1 5 6 6
2 5 5 6
3 7 8 10
4 15 14 15
5 6 10 10
6 15 15 15
print(apply(exam, 1, max)) [1] 6 6 10 15 10 15 12 6
......
扩展案例:工资研究
all2006 <- read.csv(
"../data/2006.csv.short",
header=TRUE,
as.is=TRUE
)
head(all2006)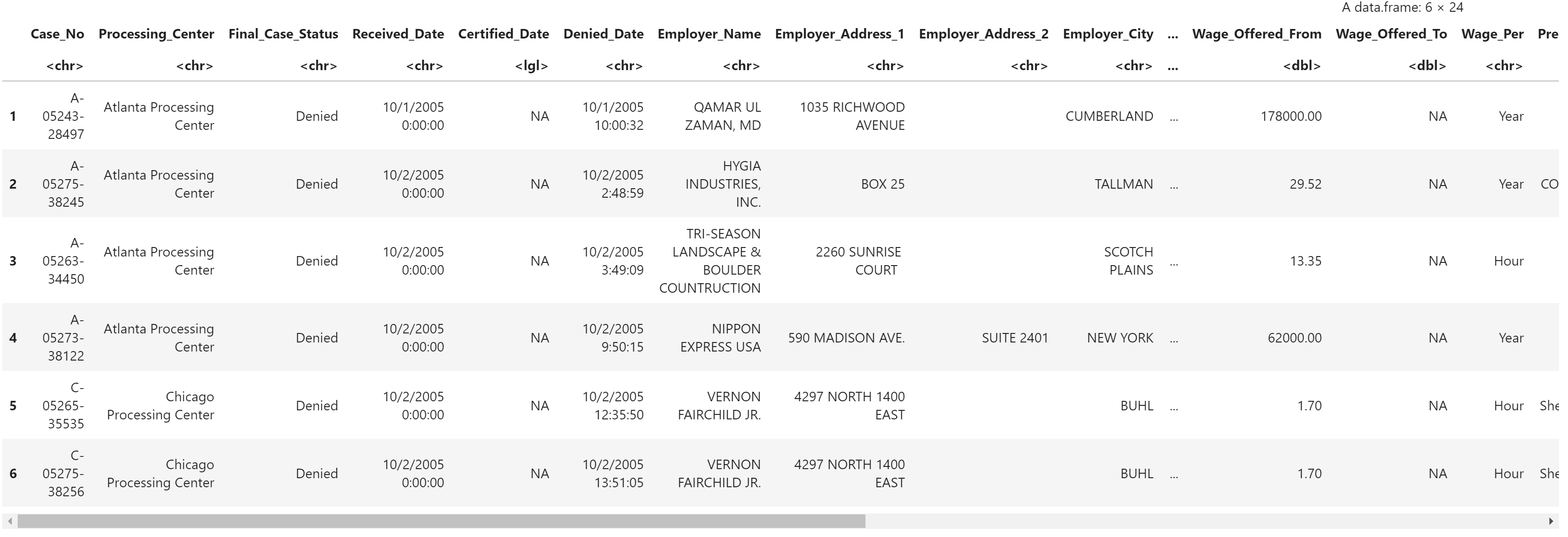
做筛选
all2006 <- all2006[all2006$Wage_Per == "Year",]
all2006 <- all2006[all2006$Wage_Offered_From > 20000,]
all2006 <- all2006[all2006$Prevailing_Wage_Amount > 200,]实际工资与普遍工资的比率
all2006$rat <- all2006$Wage_Offered_From / all2006$Prevailing_Wage_Amount
all2006定义一个函数计算 rat 列的中位数
medrat <- function(dataframe) {
return (median(dataframe$rat, na.rm=T))
}
print(medrat(all2006))[1] 1.002423
se2006 <- all2006[grep("Software Engineer", all2006),]
prg2006 <- all2006[grep("Director", all2006),]
ee2006 <- all2006[grep("Industrial Engineer", all2006),]使用下面的函数提取给定公司的子集
makecorp <- function(corpname) {
t <- all2006[all2006$Employer_Name == corpname,]
return (t)
}corplist <- list(
"THE OGILVY GROUP INC", "ogilvy",
"ITT INDUSTRIES", "itt"
)
for (i in 1:(length(corplist)/2)) {
corp <- corplist[2*i - 1]
newdtf <- paste(corplist[2*i], "2006", sep="")
assign(newdtf, makecorp(corp), pos=.GlobalEnv)
}itt2006
合并数据框
使用 merge() 函数
d1 <- data.frame(
kids=c("Jack", "Jill", "Jillian", "John"),
states=c("CA", "MA", "MA", "HI"),
stringsAsFactors=FALSE
)
print(d1) kids states
1 Jack CA
2 Jill MA
3 Jillian MA
4 John HI
d2 <- data.frame(
ages=c(10, 7, 12),
kids=c("Jill", "Lillian", "Jack"),
stringsAsFactors=FALSE
)
print(d2) ages kids
1 10 Jill
2 7 Lillian
3 12 Jack
d <- merge(d1, d2)
print(d) kids states ages
1 Jack CA 12
2 Jill MA 10
by.x 和 by.y 两个参数可以指定合并的列名
d3 <- data.frame(
ages=c(12, 10, 7),
pals=c("Jack", "Jill", "Lillian")
)
print(merge(
d1, d3,
by.x="kids",
by.y="pals"
)) kids states ages
1 Jack CA 12
2 Jill MA 10
重复匹配可能会得出错误的结果
print(d1) kids states
1 Jack CA
2 Jill MA
3 Jillian MA
4 John HI
d2a <- rbind(
d2,
list(15, "Jill")
)
print(d2a) ages kids
1 10 Jill
2 7 Lillian
3 12 Jack
4 15 Jill
print(merge(d1, d2a)) kids states ages
1 Jack CA 12
2 Jill MA 10
3 Jill MA 15
应用于数据框的函数
在数据框上应用 lapply() 和 sapply() 函数
lapply() 中调用 f(),函数会作用域数据框中的每一列,将返回值置于一个列表中
print(d) kids states ages
1 Jack CA 12
2 Jill MA 10
dl <- lapply(d, sort)
print(dl)$kids
[1] "Jack" "Jill"
$states
[1] "CA" "MA"
$ages
[1] 10 12
将列表强制转为数据框
注:排序后失去了记录的关联关系,这样做没有意义
print(as.data.frame(dl)) kids states ages
1 Jack CA 10
2 Jill MA 12
扩展案例:应用 Logistic 模型
title <- c("Gender", "Length", "Diameter", "Height", "WholeWt", "ShuckedWt", "ViscWt", "ShellWt", "Rings")
aba <- read.csv(
"../data/abalone.data",
header=FALSE,
col.names=title
)将 Gender 列转换为 factor
aba$Gender <- as.factor(aba$Gender)删掉幼鱼数据
abamf <- aba[aba$Gender != "I",]逻辑回归模型训练函数,返回系数
lftn <- function(clmn) {
glm(abamf$Gender ~ clmn, family=binomial)$coef
}在每一列中应用该函数
loall <- sapply(abamf[,-1], lftn)
loall
print(class(loall))[1] "matrix" "array"
参考
学习 R 语言系列文章:
《快速入门》
《向量》
《矩阵和数组》
《列表》
本文的 Jupyter Notebook 代码请访问如下项目: