Meteva笔记:计算站点降水的检验指标
Meteva 是由 nmc 开源的全流程检验程序库,提供了常用的各种气象预报检验评估的算法函数,气象检验分析的图片和表格型产品的制作函数,以及检验评估系统示例。
本文以 24 小时累积降水为例,说明如何根据二分类预报列联表计算常用检验指标。 同时会介绍如何使用 Meteva 中的函数进行计算。
数据
使用上一篇文章《Meteva笔记:计算站点降水的检验指标 - 列联表》中计算的列联表。
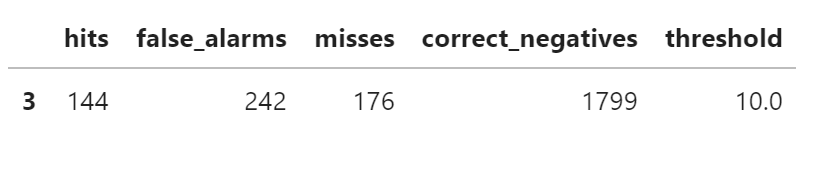
以 10 mm 降水为例说明二分式 (dichotomous, yes/no) 预测的检验指标
df_10 = df_matrix[df_matrix["threshold"] == 10]
df_10
总数
total = df_10[["hits", "false_alarms", "misses", "correct_negatives"]].sum().sum()
total
2361
同时会将计算结果与 Meteva 进行对比。
为了结果一致性,从 Meteva 计算的结果中减去 2 个样本
hfmc_10_orig = hfmcs[3]
hfmc_10_orig
array([[1801, 176, 1977],
[ 242, 144, 386],
[2043, 320, 2363]])
hfmc_10_mod = hfmc_10_orig - np.array(
[
[2, 0, 2],
[0, 0, 0],
[2, 0, 2],
]
)
hfmc_10_mod
array([[1799, 176, 1975],
[ 242, 144, 386],
[2041, 320, 2361]])
meteva.method 中的方法使用 4 个元素的数组表示列联表
命中,空报,漏报,正确否定
hfmc_10 = np.array([[
hfmc_10_mod[1, 1],
hfmc_10_mod[1, 0],
hfmc_10_mod[0, 1],
hfmc_10_mod[0, 0]
]])
hfmc_10
array([[ 144, 242, 176, 1799]])
hfmc_10.shape
(1, 4)
导入 Meteva 包
import meteva.method as mem
指标
Accuracy
Accuracy, fraction correct
准确率
回答问题:总体而言,预报正确的比例是多少?
范围:0 到 1
完美分数:1
特性
简单,直观。可能会引起误解,因为它受最常见类别的影响很大,在罕见天气情况下通常是“无事件”。
accuracy = (
df_10["hits"] + df_10["correct_negatives"]
) / total
accuracy.item()
0.8229563744176197
mem.pc_hfmc(hfmc_10)
0.8229563744176197
Bias score
Bias score, frequency bias
偏差
回答问题:“是”事件的预报频率与观察到的“是”事件的频率相比如何?
范围:0 到 无穷大
完美分数:1
特性
测量预报事件的频率与观察到的事件的频率之比。 表示预报系统是倾向于发生欠预测 (underforecast, BIAS < 1) 还是发生过预测 (overforecast, BIAS > 1) 事件。 不衡量预报与观测值的对应程度,仅衡量相对频率。
bias = (
df_10["hits"] + df_10["false_alarms"]
) / (
df_10["hits"] + df_10["misses"]
)
bias.item()
1.20625
mem.bias_hfmc(hfmc_10)
1.20625
Probability of detection
Probability of detection (POD), hit rate, H
命中率
回答问题:观察到“是”的事件被正确预报的比例是多少?
范围:0 到 1
完美分数:1
特性
对 hits 敏感,但忽略 false alarms。 对事件的气候频率非常敏感。 适用于罕见事件。 可以通过发布更多“是”预报来增加 hits,从而人为地加以改进。 应与 false alarm ratio 结合使用。 POD 还是广泛用于概率预报的 Relative Operating Characteristic (ROC) 的重要组成部分。
pod = df_10["hits"] / (
df_10["hits"] + df_10["misses"]
)
pod.item()
0.45
mem.pod_hfmc(hfmc_10)
0.45
False alarm ratio
False alarm ratio, FAR
空报率
回答问题:预报为“是”的事件中有多少比例实际上没有发生(即 false alarms)?
范围:0 到 1
完美分数:1
特性
对 false alarms 敏感,但忽略 misses。 对事件的气候频率非常敏感。 应与 probability of detection 结合使用。
far = df_10["false_alarms"] / (
df_10["hits"] + df_10["false_alarms"]
)
far.item()
0.6269430051813472
mem.far_hfmc(hfmc_10)
0.6269430051813472
Probability of false detection
Probability of false detection, false alarm rate, POFD, F
报空率
回答问题:在观察到的“否”事件中,有多少比例被错误地预报为“是”?
范围:0 到 1
完美分数:0
特性
对 false alarms 敏感,但忽略 misses。 可以通过发出较少的“是”预报来人为地改进,以减少 false alarms 的数量。 确定性预报通常不进行报告,但是它是广泛用于概率预报的 Relative Operating Characteristic (ROC) 的重要组成部分。
pofd = df_10["false_alarms"] / (
df_10["correct_negatives"] + df_10["false_alarms"]
)
pofd.item()
0.11856932876041157
mem.pofd_hfmc(hfmc_10)
0.11856932876041157
Success ratio
Success ratio, SR
成功率
回答问题:预报为“是”的事件中多少比例被正确观测?
范围:0 到 1
完美分数:1
特性
给出有关观察到的事件的可能性的信息(假设已被预报)。 它对 false alarms 很敏感,但忽略 misses。 SR 等于 1-FAR。 在分类性能图 (categorical performance diagram) 中,相对 SR 绘制 POD。
sr = df_10["hits"] / (
df_10["hits"] + df_10["false_alarms"]
)
sr.item()
0.37305699481865284
mem.sr_hfmc(hfmc_10)
0.37305699481865284
Threat score
Threat score, TS, critical success index, CSI
TS 评分
回答问题:预报的“是”事件与观察到的“是”事件对应的程度如何?
范围:0 到 1,0 表示没有技巧
完美分数:1
特性
测量正确预测的观测和/或预报事件的比例。 可以认为是不考虑 correct negatives 后的准确性,也就是说,TS 仅关注有效的预报。 对 hits 敏感,对 misses 和 false alarms 都会造成惩罚。 不区分预测误差的来源。 取决于事件的气候频率(罕见事件的评分较低),因为某些 hits 可能纯粹是因为随机原因而发生的。
ts_10 = df_10["hits"] / (
df_10["hits"] + df_10["misses"] + df_10["false_alarms"]
)
ts_10.item()
0.25622775800711745
mem.ts_hfmc(hfmc_10)
0.25622775800711745
Equitable threat score
Equitable threat score, ETS, Gilbert skill score, GSS
ETS 评分
回答问题:预报的“是”事件与观察到的“是”事件对应的程度如何(考虑了由于偶然因素造成的 hits)?
范围:-1/3 到 1,0 表示没有技巧
完美分数:1
特性
测量观测和/或正确预报事件的比例,并针对与随机原因相关的 hits 进行调整(例如,在潮湿气候中比在干燥气候中更容易正确预测降雨的发生)。 ETS 通常用于 NWP 模型中的降水验证,因为它的“公平性”可以在不同制度下更公平地比较得分。 对 hits 敏感。 因为它以相同的方式惩罚 misses 和 false alarms,所以它不会区分预测错误的来源。
hits_random = (
df_10["hits"] + df_10["misses"]
) * (
df_10["hits"] + df_10["false_alarms"]
) / total
hits_random.item()
52.31681490893689
ets = (
df_10["hits"] - hits_random
) / (
df_10["hits"] + df_10["misses"] + df_10["false_alarms"] - hits_random
)
ets.item()
0.17988269531529164
mem.ets_hfmc(hfmc_10)
0.17988269531529164
Hanssen and Kuipers discriminant
Hanssen and Kuipers discriminant, HK, True skill statistic, TSS, Peirce’s skill score, PSS
HK 评分
回答问题:预报将“是”事件与“否”事件分开的能力如何?
范围:-1 到 1,0 表示没有技巧
完美分数:1
特性
使用列联表中的所有元素。 不取决于气候事件发生的频率。 该表达式与 HK = POD-POFD 相同,但是 Hanssen and Kuipers score 也可以解释为 (accuracy for events) + (accuracy for non-events) - 1。 对于罕见事件,HK 偏重于第一项(与POD相同),因此此分数可能对于更频繁的事件更有用。 可以用类似于 ETS 的形式表示,除了 hits_random 项是无偏的。
hk = (
df_10["hits"] / (
df_10["hits"] + df_10["misses"]
)
-
df_10["false_alarms"] / (
df_10["false_alarms"] + df_10["correct_negatives"]
)
)
hk.item()
0.33143067123958847
mem.hk_yesorno_hfmc(hfmc_10)
0.33143067123958847
Heidke skill score
Heidke skill score, HSS, Chohen’s K
HSS 评分
回答问题:相对于随机因素,预报的准确性是多少?
范围:-1 到 1,0 表示没有技巧
完美分数:1
特性
在消除纯粹由于随机因素而正确的预报之后,测量正确预报的比例。 这是广义技能评分的一种形式,其中分子中的评分是正确预报的数量,在这种情况下,参考预报是随机因素。 至少在气象学中,随机因素通常不是与之相比的最佳预报 —— 使用气候学(长期平均值)或持续性(预测=最新观察,即无变化)或其他一些标准可能更好。
expected_correct_random = (1/total) * (
(
df_10.hits + df_10.misses
) * (
df_10.hits + df_10.false_alarms
)
+
(
df_10.correct_negatives + df_10.misses
) * (
df_10.correct_negatives + df_10.false_alarms
)
)
expected_correct_random.item()
1759.6336298178737
hss = (
(df_10.hits + df_10.correct_negatives) - expected_correct_random
) / (
total - expected_correct_random
)
hss.item()
0.3049162362148602
mem.hss_yesorno_hfmc(hfmc_10)
0.3049162362148602
Odds ratio
Odds ratio, OR
胜算比
回答问题:“是”预报正确的几率与“是”预报错误的几率之比是多少?
Odds ratio
范围:0 到 无穷大,1 表示没有技巧
完美分数:无穷大
Log odds ratio
范围:负无穷大 到 正无穷大,0 表示没有技巧
完美分数:无穷大
特性
测量 hits 几率与发出 false alarms 的几率之比。 通常使用 odds ratio 的对数代替原始值。 考虑先验概率。 在罕见事件中得分更高。 对 hedging 较不敏感。 如果列联表中的任何单元格都等于 0,请不要使用。 广泛用于医学领域但尚未在气象学中使用。
请注意,odds 与命中概率(hits/# forecasts)与误报概率(false alarms/# forecasts)之比不同,因为这两者都可能取决于气候事件发生的频率(即先验概率)。
odds_ratio = df_10.hits * df_10.correct_negatives / (df_10.misses * df_10.false_alarms)
odds_ratio.item()
6.082268970698723
表示“是”预报正确的概率比“是”预报错误的概率高 6 倍。
Odds ratio skill score
Odds ratio ratio skill score, ORSS, Yule’s Q
回答问题:与随机因素相比,预报有什么改进?
范围:-1 到 1,0 表示没有技巧
完美分数:1
特性
与边际总数无关(即与选择用来分隔“是”和“否”的阈值无关),因此很难对冲 (hedge)。
orss = (
(df_10.hits * df_10.correct_negatives - df_10.misses * df_10.false_alarms)
/
(df_10.hits * df_10.correct_negatives + df_10.misses * df_10.false_alarms)
)
orss.item()
0.7176046252585795
参考
https://www.cawcr.gov.au/projects/verification/
模式检验系列文章
