使用 xarray 合并 GRIB 2 要素场
本文介绍如何合并使用 xarray.DataArray 表示的 GRIB 2 要素场。
主要用于解决如下问题:
已有表示为 xarray.DataArray 的三维数据,维度是:时间,纬度和经度。
如何增加一个纬度,用于表示预报时效。
简介
xarray 数据包含坐标 (coords) 和维度 (dims),其中维度是数据实际的维数,维度均包含在坐标中;但坐标可以是非维度坐标,用于提供对数据的附加描述。
例如,使用 nwpc-data 加载某个 GRIB 2 要素场,返回的 xr.DataArray 对象类似下面的截图:
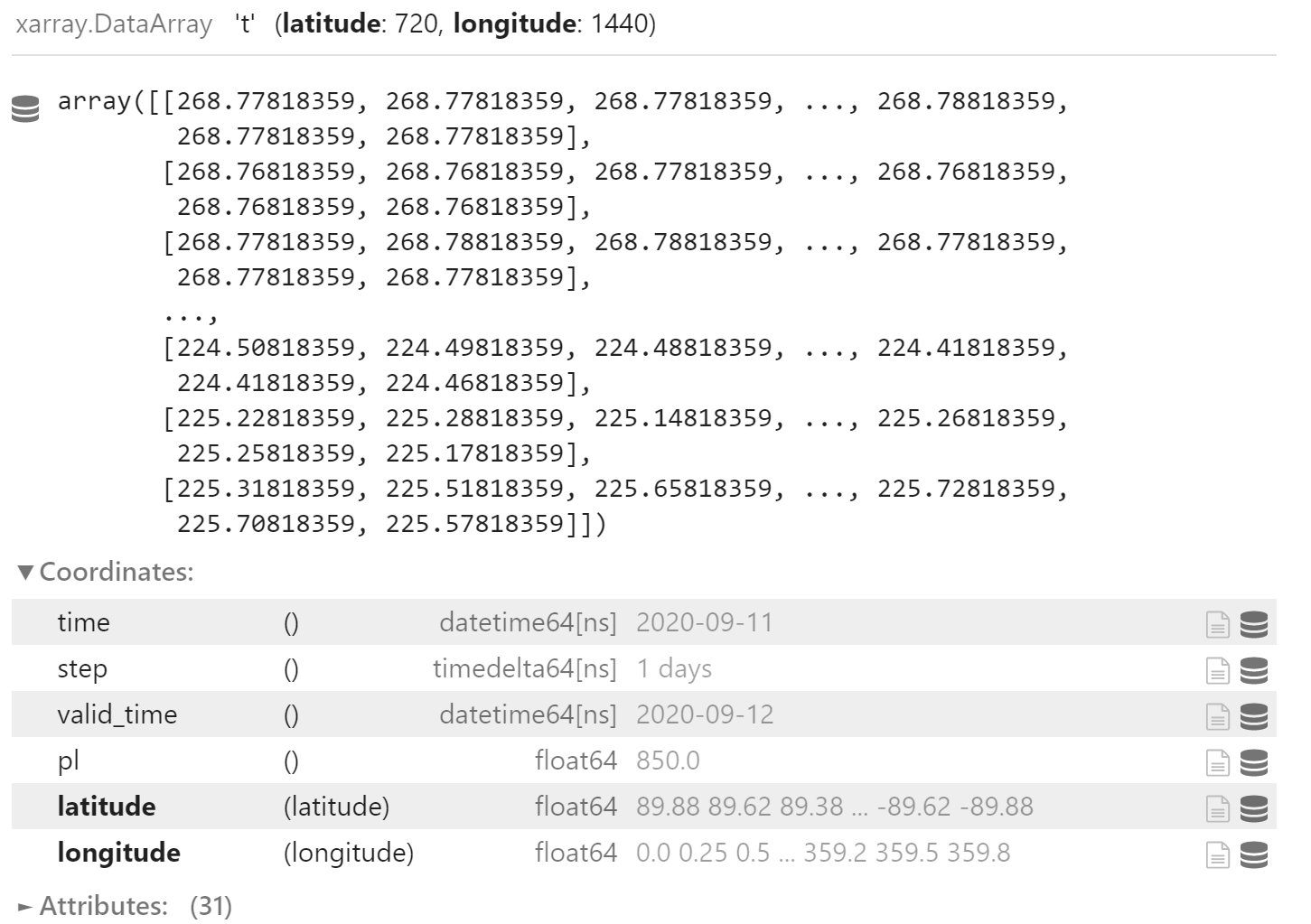
可以看到在单个要素场中仅有经纬度 (latitude, longitude) 两个坐标是维度,其余坐标 (time, step, valid_time 和 pl) 均不是维度坐标。
也就是说,返回的要素场是二维的。
如果需要增加的维度已在数据的坐标对象 coords 中,则可以使用 expand_dims 方法将其转为维度坐标,再使用 xr.concat 函数沿某个维度合并多个数据。
本文首先介绍如何实现开头提出的问题,即在时间,纬度和经度三个维度基础上增加预报时效维度。
最后介绍 nwpc-data 库中提供的类似功能。
准备
本文使用 nwpc-data 库从 GRIB 2 文件中加载要素场。
import xarray as xr
import pandas as pd
import numpy as np
from nwpc_data.data_finder import find_local_file
from nwpc_data.grib.eccodes import (
load_field_from_file,
load_field_from_files,
)单个要素场
以单个要素场为例,说明如何对 nwpc-data 库加载的 GRIB 2 消息进行处理。
查找 2020 年 9 月 11 日 GRAPES GFS 模式 24 时效原始分辨率 GRIB2 文件的路径
file_path = find_local_file(
data_type="grapes_gfs_gmf/grib2/orig",
start_time=pd.Timestamp("2020-09-11 00:00:00"),
forecast_time="24h",
)使用 nwpc-data 加载 850hPa 温度场
field = load_field_from_file(
file_path,
parameter="t",
level_type="pl",
level=850
)
field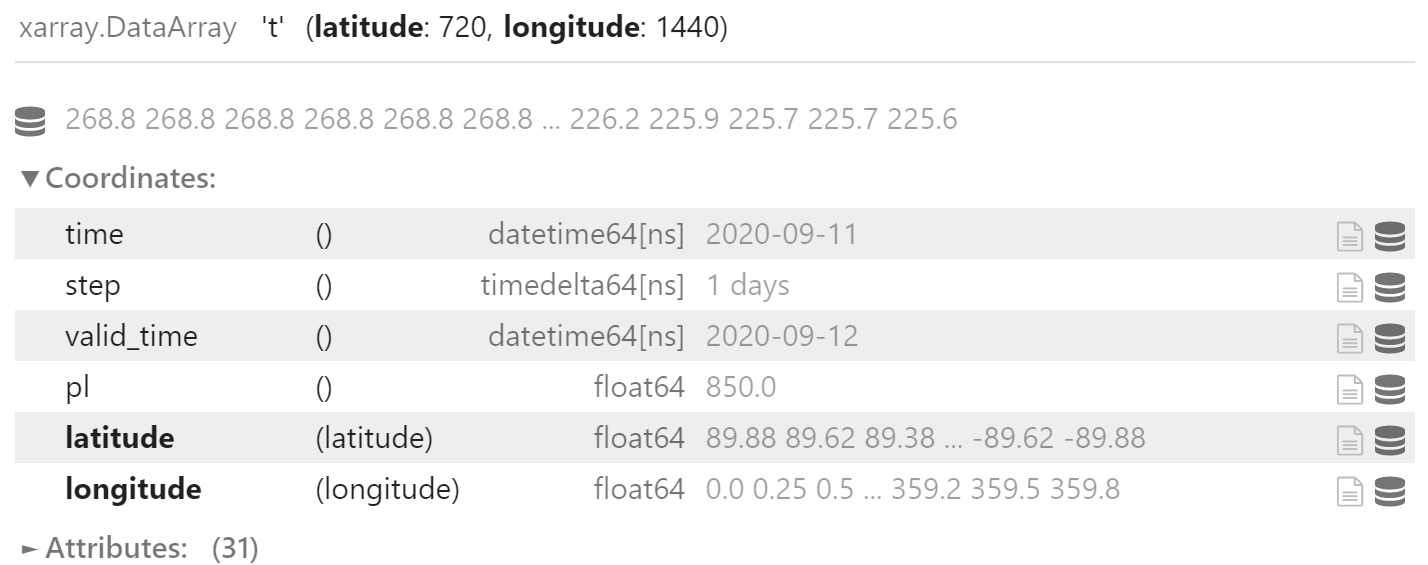
为了支持合并数据,可以使用 expand_dims 方法将非维度坐标转为维度。
field.expand_dims(["time", "step"])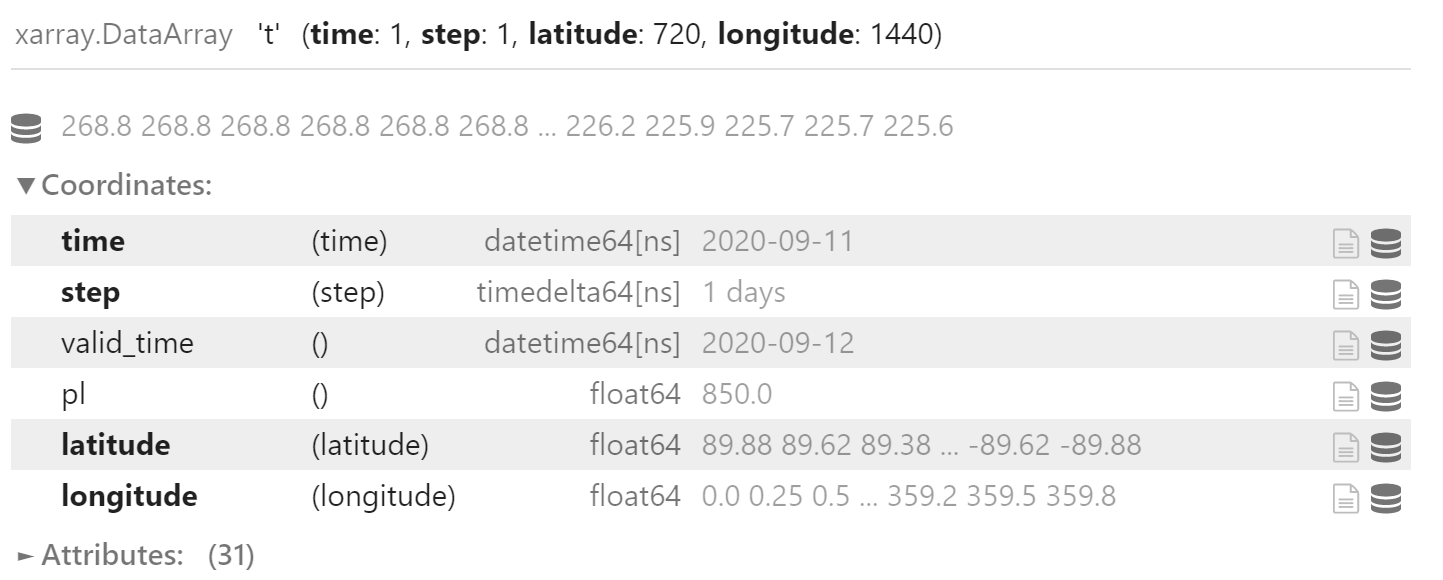
为了构造满足问题要求的数据,使用 reset_coords 删掉不需要的坐标。
grid_field = field.reset_coords(
["step", "valid_time", "pl"],
drop=True
)
grid_field
合并数据
下面我们合并 GRAPES GFS 模式 2020 年 9 月 1 日至 3 日所有预报时次 024 和 048 两个预报时效的要素场。
构造三维数据
为每个预报时效构造三维数据,维度是时次、纬度和经度。
首先获取 024 时效的数据的文件路径列表
file_list_24 = []
for start_time in pd.date_range(start="2020-09-01", end="2020-09-03", freq="6h"):
forecast_hour = 24
file_path = find_local_file(
data_type="grapes_gfs_gmf/grib2/orig",
start_time=start_time,
forecast_time=f"{forecast_hour}h",
)
if file_path is None:
raise FileNotFoundError("grib file is not found")
file_list_24.append(file_path)
file_list_24[PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090100/ORIG/gmf.gra.2020090100024.grb2'),
PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090106/ORIG/gmf.gra.2020090106024.grb2'),
PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090112/ORIG/gmf.gra.2020090112024.grb2'),
PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090118/ORIG/gmf.gra.2020090118024.grb2'),
PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090200/ORIG/gmf.gra.2020090200024.grb2'),
PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090206/ORIG/gmf.gra.2020090206024.grb2'),
PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090212/ORIG/gmf.gra.2020090212024.grb2'),
PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090218/ORIG/gmf.gra.2020090218024.grb2'),
PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090300/ORIG/gmf.gra.2020090300024.grb2')]
加载所有 024 时效 850hPa 温度的要素场,仅保留时次、纬度和经度三个坐标。
field_list = []
for file_path in file_list_24:
print(file_path)
field = load_field_from_file(
file_path,
parameter="t",
level_type="pl",
level=850,
).reset_coords(["step", "valid_time", "pl"], drop=True)
field_list.append(field)使用 xr.concat 将得到的要素场列表沿时次 (time) 维度合并,得到三维数据
合并时会自动将非维度坐标 time 转为维度坐标。
data_24 = xr.concat(field_list, "time")
data_24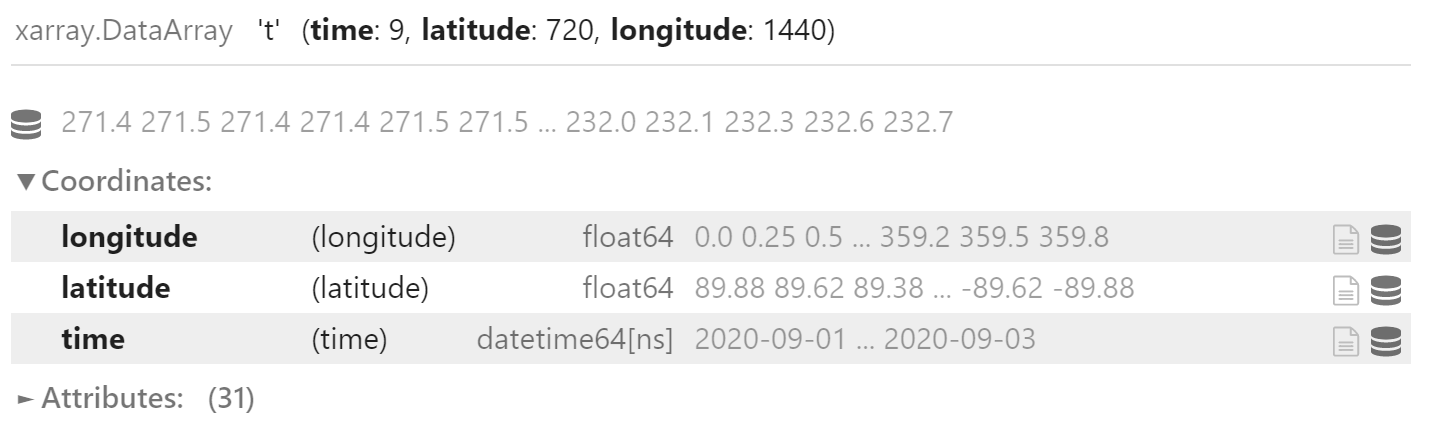
以同样的方式加载 048 时效要素场并合并为单个对象
file_list_48 = []
for start_time in pd.date_range(start="2020-09-01", end="2020-09-03", freq="6h"):
forecast_hour = 48
file_path = find_local_file(
data_type="grapes_gfs_gmf/grib2/orig",
start_time=start_time,
forecast_time=f"{forecast_hour}h",
)
if file_path is None:
raise FileNotFoundError("grib file is not found")
file_list_48.append(file_path)
field_list = []
for file_path in file_list_48:
print(file_path)
field = load_field_from_file(
file_path,
parameter="t",
level_type="pl",
level=850,
).reset_coords(["step", "valid_time", "pl"], drop=True)
field_list.append(field)
data_48 = xr.concat(field_list, "time")
data_48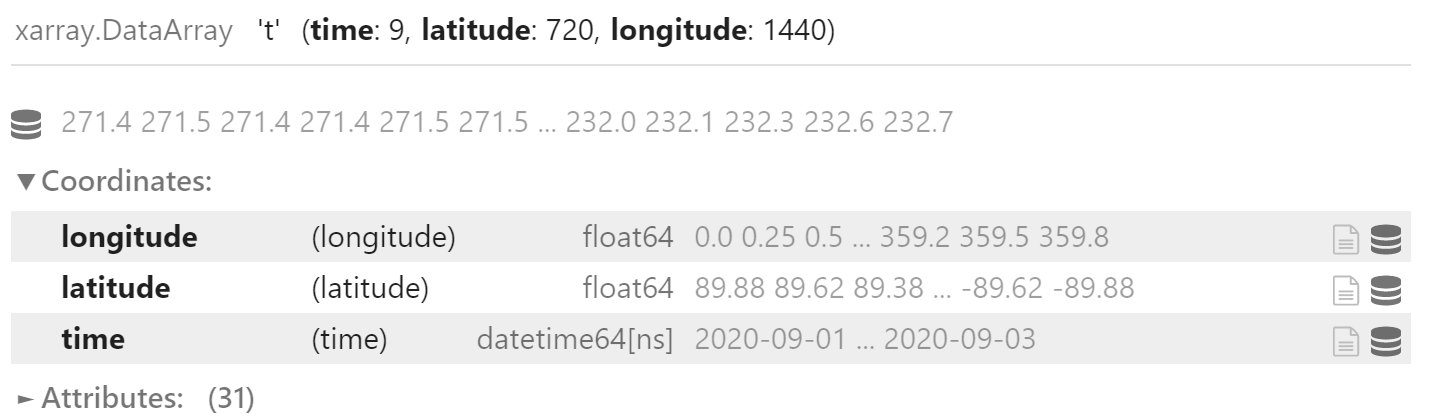
合并
为 data_24 和 data_48 手动添加新的坐标 step,表示预报时效
data_24.coords["step"] = 24
data_48.coords["step"] = 48
data_24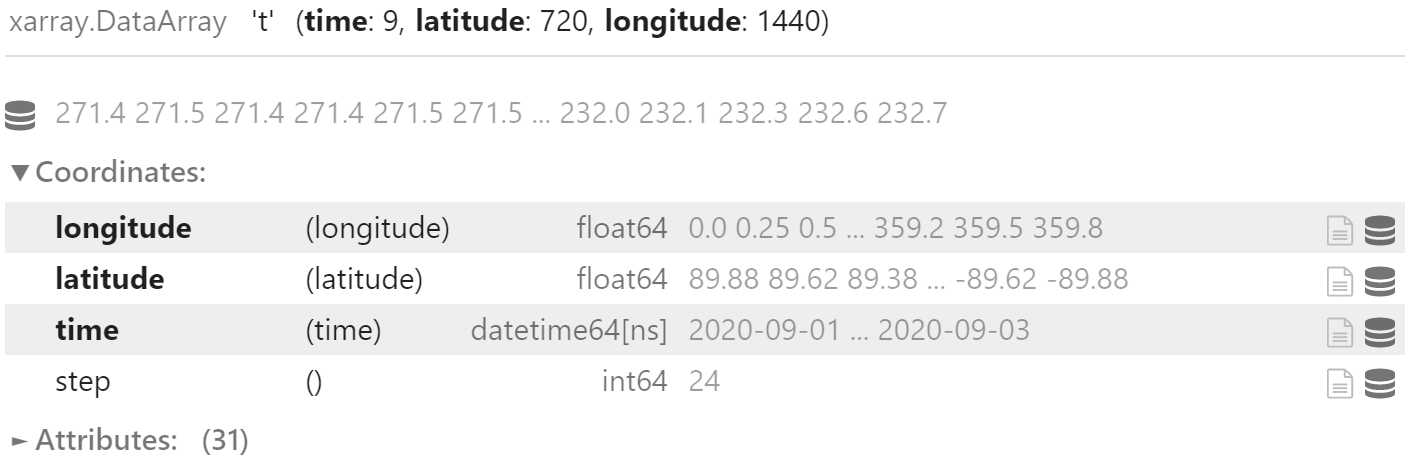
可以看到,添加坐标并不改变数据的维度,数据依然还是三维的。
使用 xr.concat 函数沿新添加的 step 坐标合并数据,得到四维数据。
data_combine = xr.concat([data_24, data_48], "step")
data_combine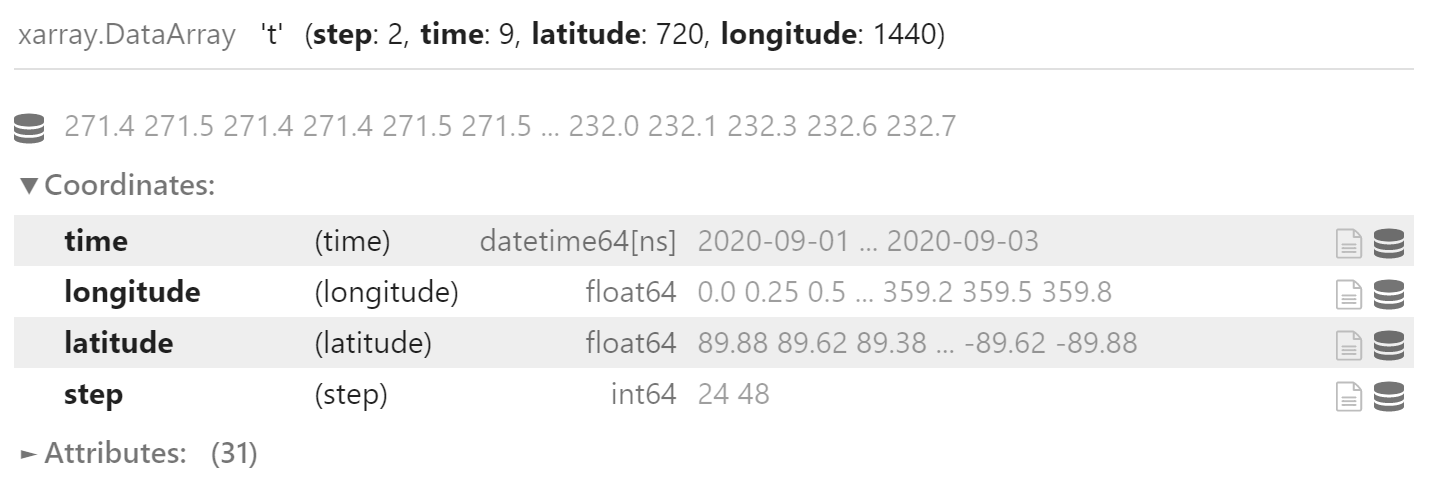
合并后的数据中 step 是第一个维度。
可以使用 transpose 方法变换维度次序。
data_combine = data_combine.transpose("time", "step", ...)
data_combine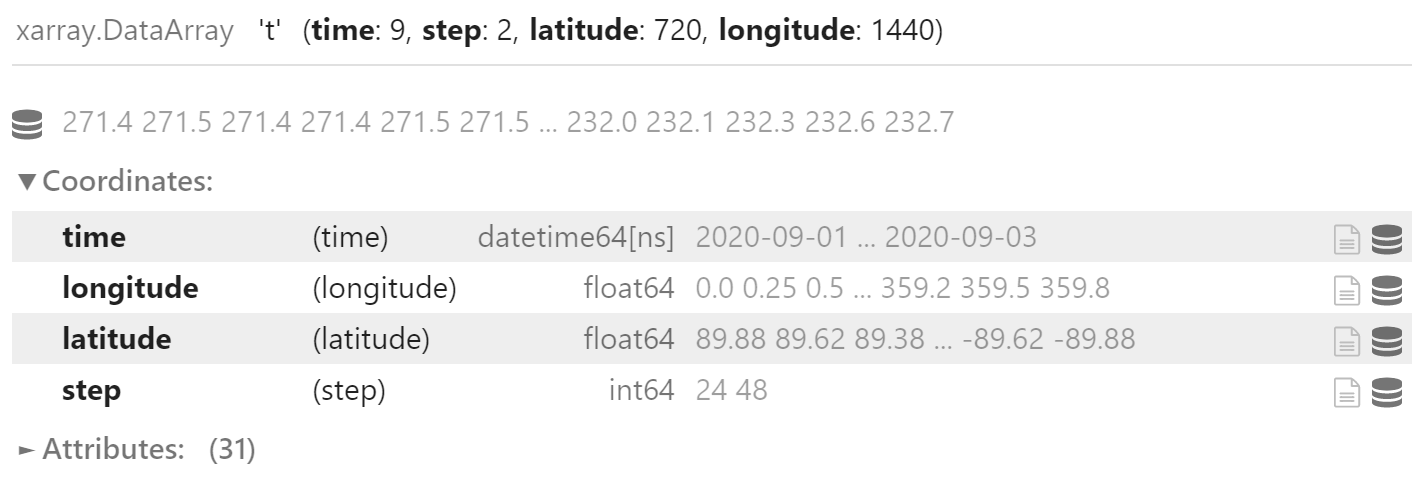
集成
nwpc-data 库中已集成该项功能,load_field_from_files 函数支持从多个文件中加载同一类型的要素场。
获取文件列表
file_list = []
for start_time in pd.date_range(start="2020-09-01", end="2020-09-03", freq="6h"):
for forecast_hour in np.arange(0, 49, 24):
file_path = find_local_file(
data_type="grapes_gfs_gmf/grib2/orig",
start_time=start_time,
forecast_time=f"{forecast_hour}h",
)
if file_path is None:
raise FileNotFoundError("grib file is not found")
file_list.append(file_path)加载文件列表中所有的 850hPa 温度场
field = load_field_from_files(
file_list,
parameter="t",
level=850,
level_type="pl",
)
field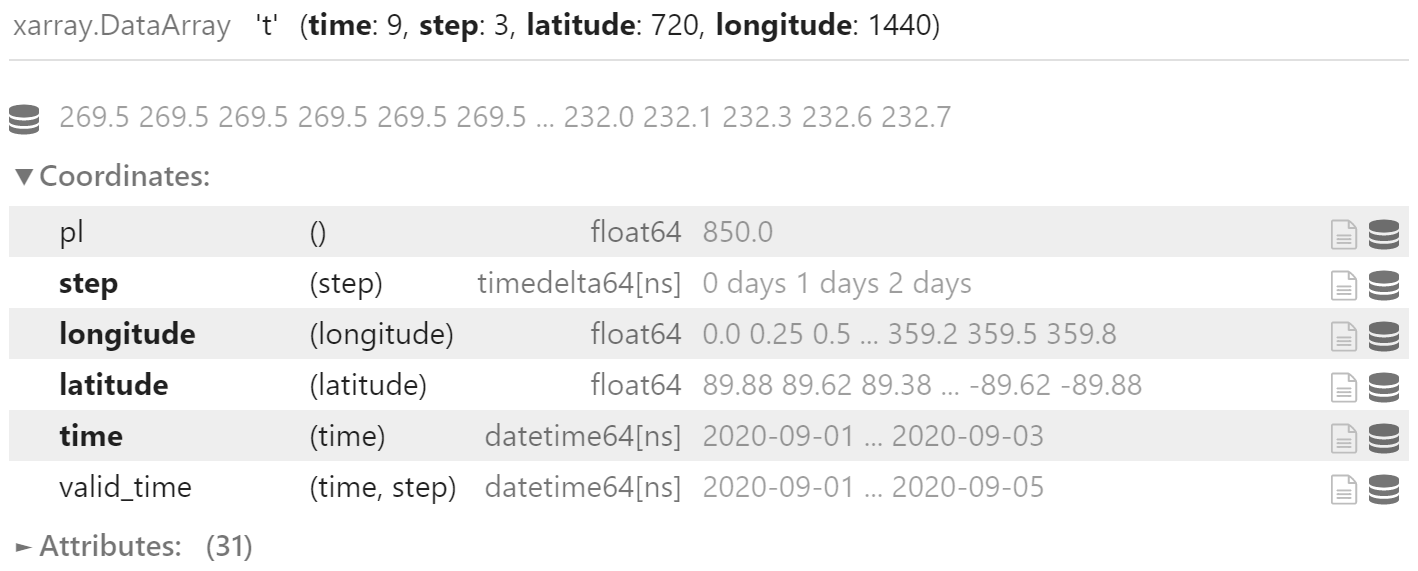
实现
简要介绍下该函数内部如何实现
从文件列表中依次加载要素场。 加载后的要素场仅有经纬度两个维度坐标。
field_list = []
for file_path in file_list:
field = load_field_from_file(
file_path,
parameter="t",
level_type="pl",
level=850,
)
field_list.append(field)将 time 和 step 两个非维度坐标展开为维度坐标,要素场从二维变为四维。
field_list[0].expand_dims(["time", "step"])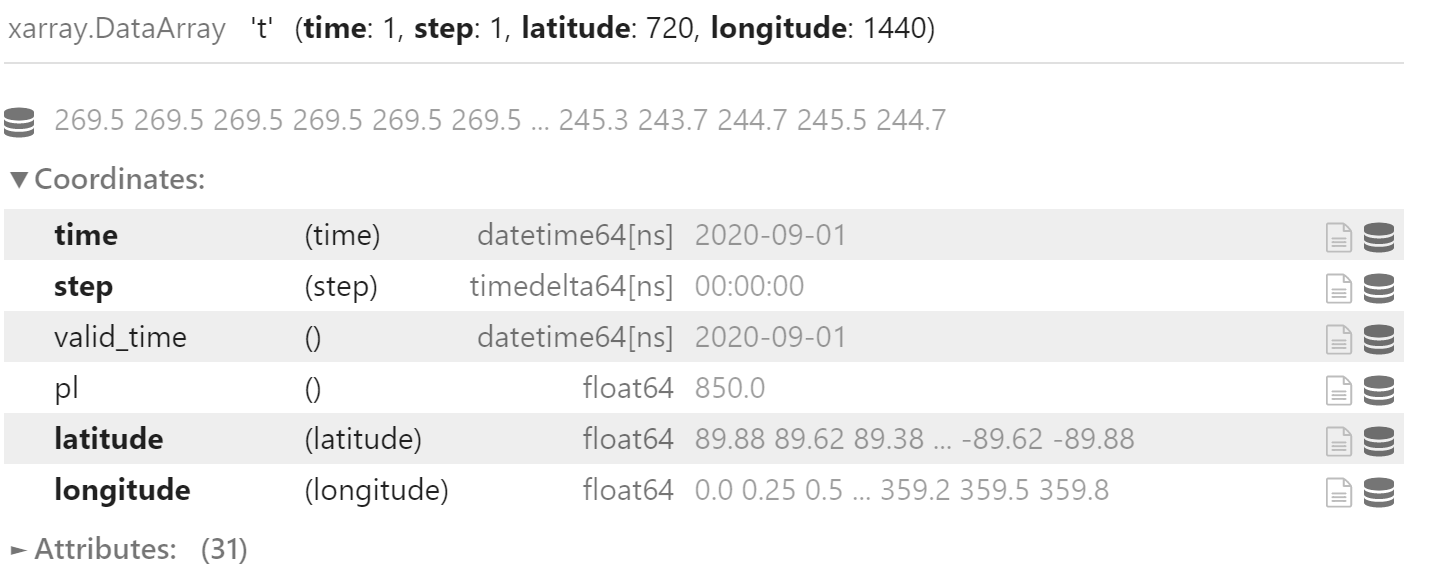
将 xr.DataArray 转为数据集 xr.Dataset,方便后续合并
field_list[0].expand_dims(["time", "step"]).to_dataset()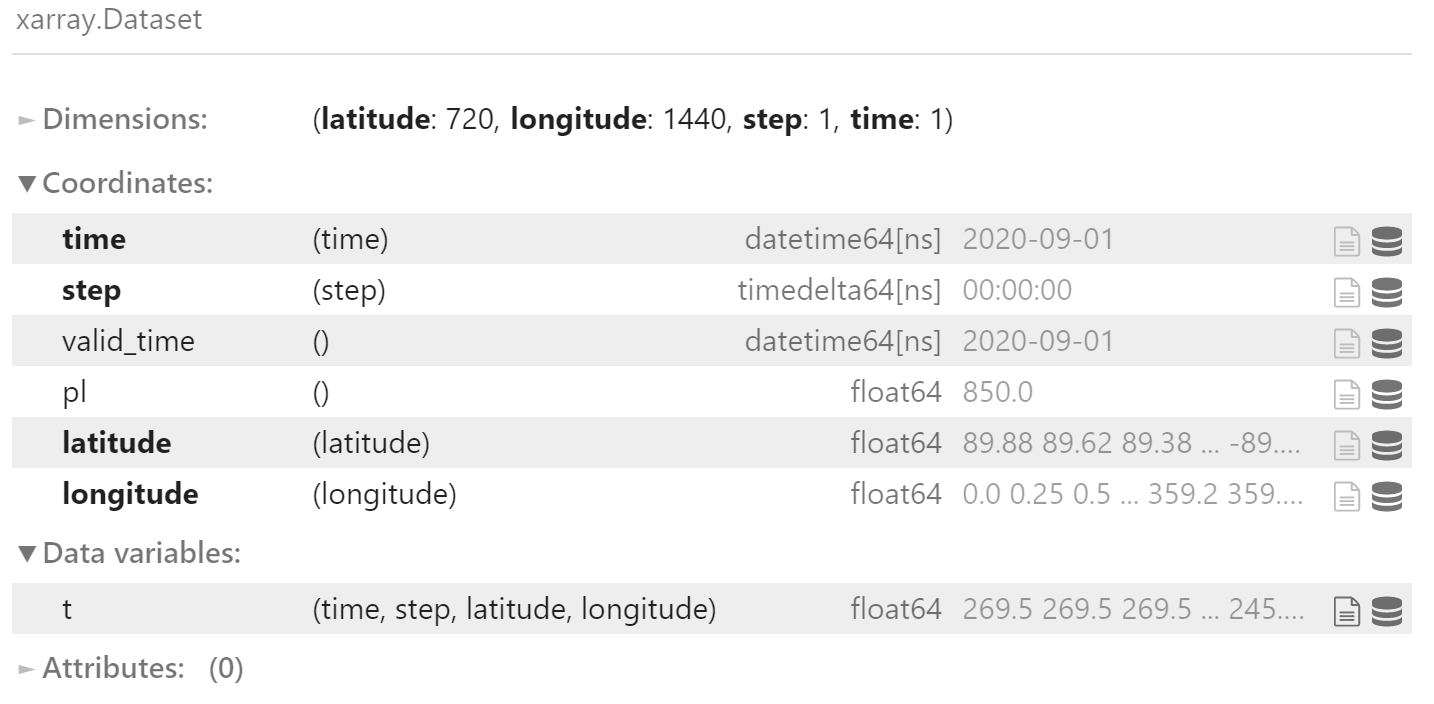
按以上方式对所有要素场进行处理,并使用 xr.combine_by_coords 合并数据集
data_set = xr.combine_by_coords(
[f.expand_dims(["time", "step"]).to_dataset() for f in field_list]
)
data_set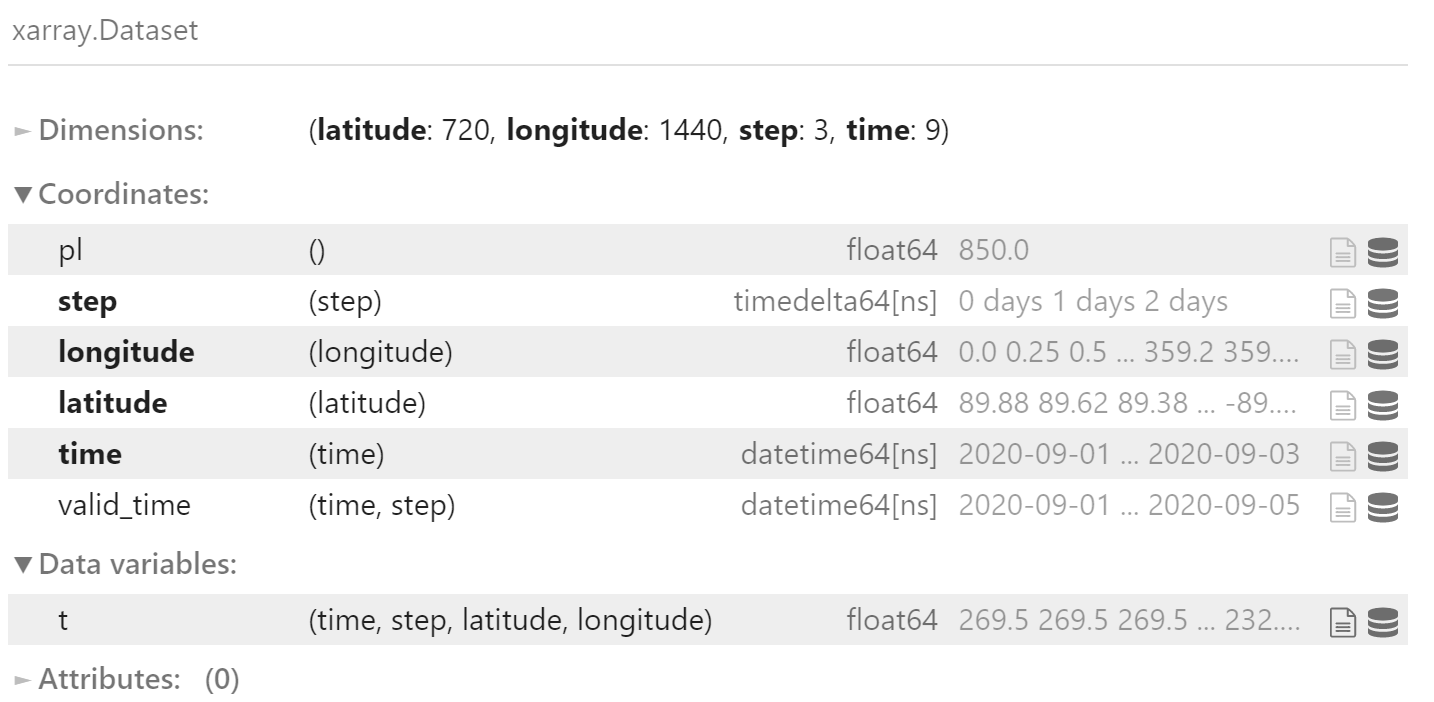
数据集中的 t 变量即是合并后的温度场数据
t = data_set.t
t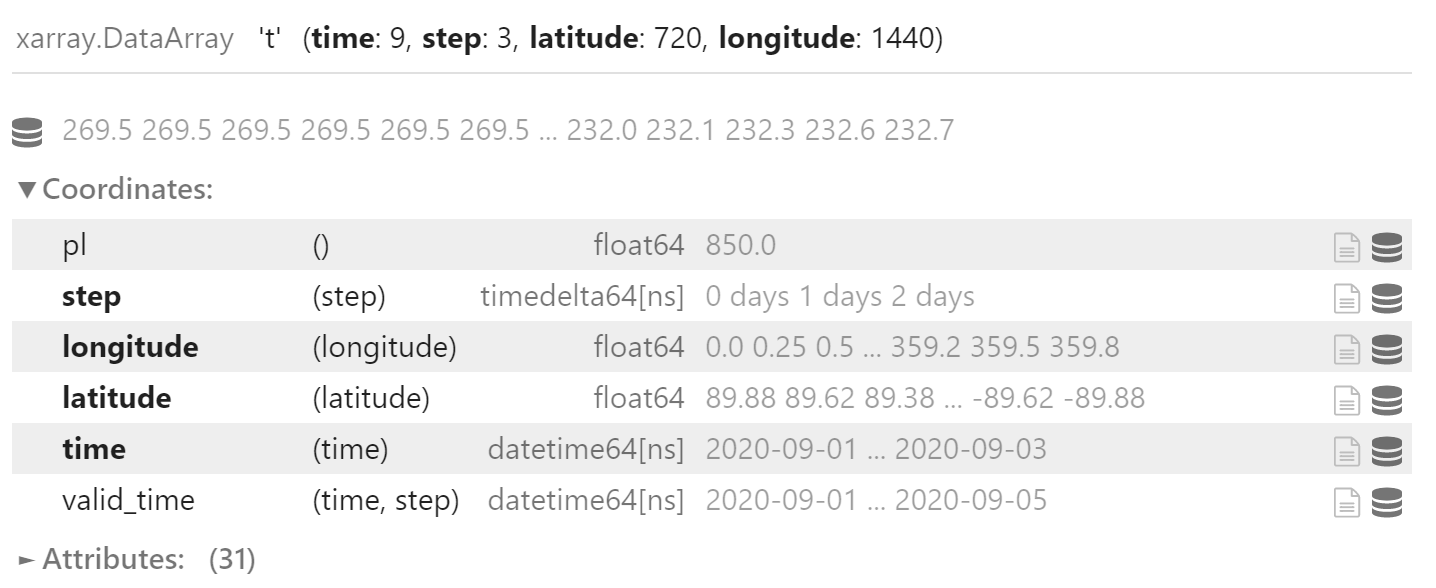
可以进一步调整维度顺序,当然对于本文来说,并不需要这一步。
t = t.transpose("time", "step", ...)进一步
上述示例中,time 和 step 坐标对应的所有要素场都存在,所以合并后的数据对象中,对于每种坐标组合都有实际的要素场相对应。
如果某个组合下对应的要素场不存在,合并后的数据集是否有意义?
本节用一个简单的试验来说明。
同样使用上面的文件路径列表 file_list,不过删掉该列表中的两项。
file_list = []
for start_time in pd.date_range(start="2020-09-01", end="2020-09-03", freq="6h"):
for forecast_hour in np.arange(0, 49, 24):
file_path = find_local_file(
data_type="grapes_gfs_gmf/grib2/orig",
start_time=start_time,
forecast_time=f"{forecast_hour}h",
)
if file_path is None:
raise FileNotFoundError("grib file is not found")
file_list.append(file_path)file_list.pop(2)PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090100/ORIG/gmf.gra.2020090100048.grb2')
file_list.pop(10)PosixPath('/g1/COMMONDATA/OPER/NWPC/GRAPES_GFS_GMF/Prod-grib/2020090118/ORIG/gmf.gra.2020090118048.grb2')
使用 load_field_from_files 函数依然可以加载要素场。
time 和 step 维度坐标的取值也与之前一样。
field = load_field_from_files(
file_list,
parameter="t",
level=850,
level_type="pl",
)
field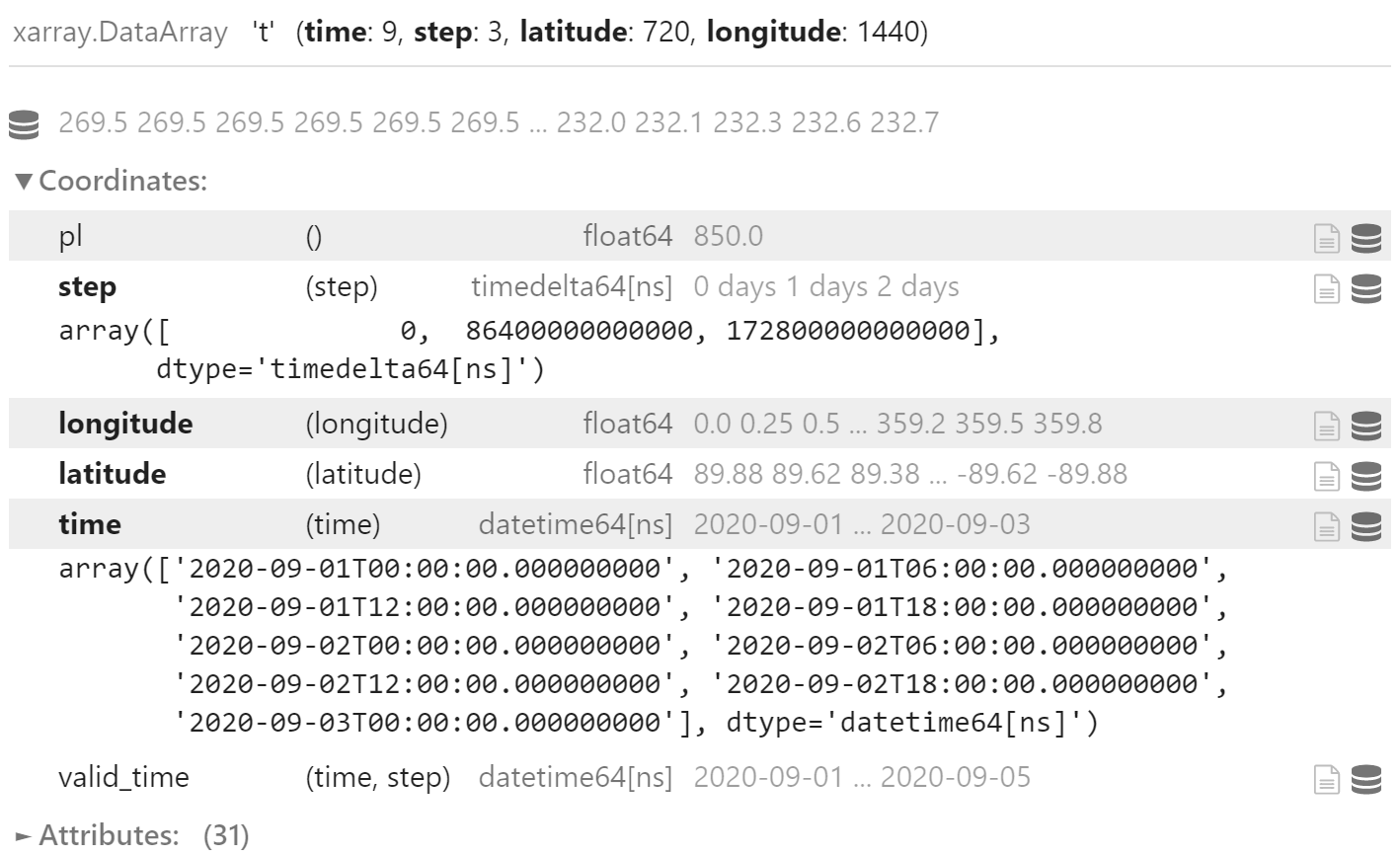
但是,当访问删掉项目对应的坐标时,返回数组中所有值均为 np.nan
field.sel(
time="2020-09-01 00:00:00",
step=pd.Timedelta(hours=48)
)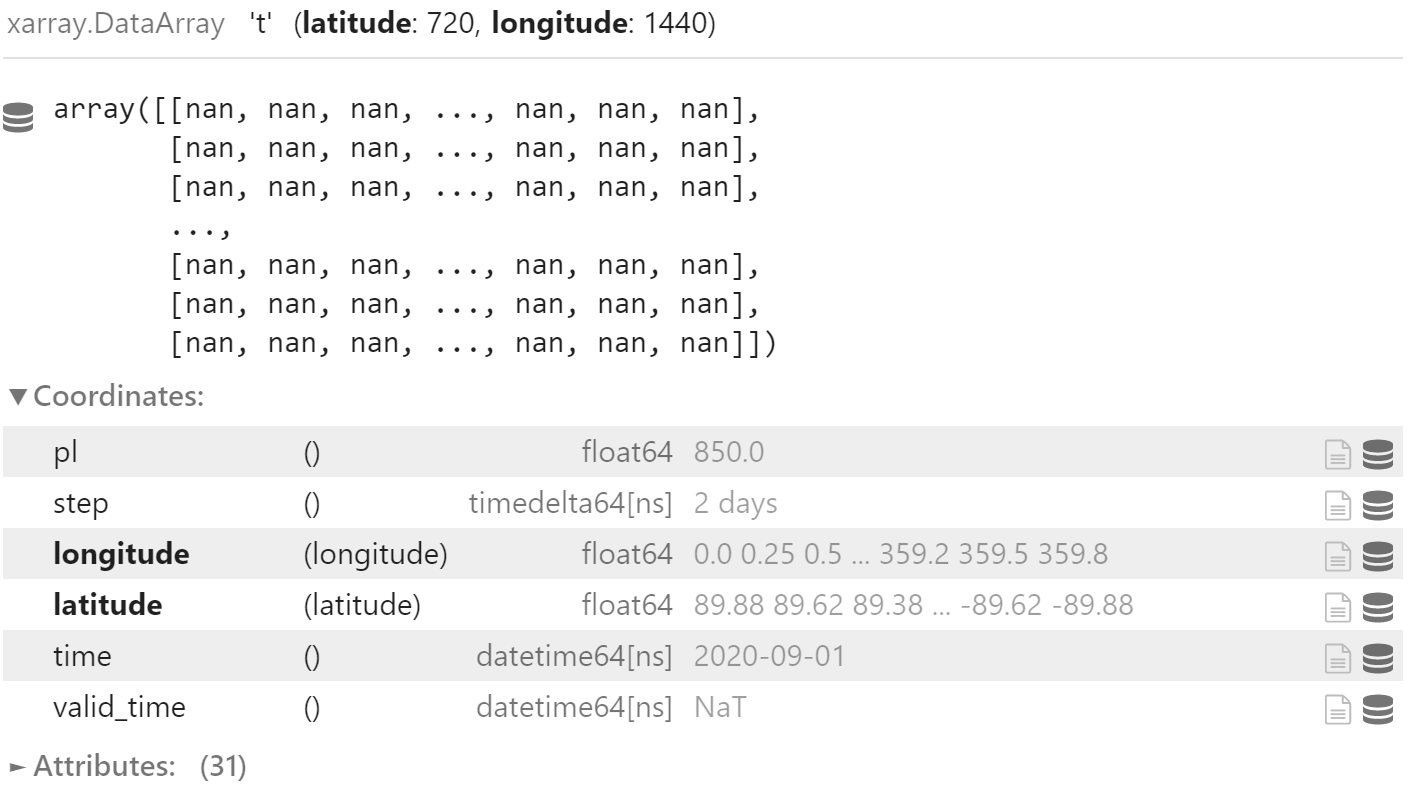
这说明当数据“不全”时,合并依然有效。
笔者后续会进一步研究不同要素场的合并问题。
参考
介绍 xarray 合并的三篇文章:
介绍 nwpc-data 库的文章:
nwpc-data 库地址: