ecFlow笔记:基于ecFlow构建后台服务监控系统
本文介绍如何使用 ecFlow 定时检查后台程序运行情况,实现对 HPC 登录节点上后台服务的监控,并在程序退出时实现自动重启。
背景
前两年笔者开发的监控程序通常部署在 HPC 外的 Linux 服务器上,使用 SSH 协议或者 TCP 端口远程连接 HPC 获取监控数据。 但这类程序存在不少问题。
比如下面两个近期没有更新的项目:
nwpc-hpc-exporter
nwpc-oper/nwpc-hpc-exporter 项目为 Prometheus 提供 HPC 监控指标。 该项目运行在 Linux 服务器上,通过 SSH 协议使用账户名和密码远程连接到 HPC 执行命令行程序,定时获取 HPC 的运行状态。
保持与高性能计算的 SSH 长时间连接并不是百分之百可靠的。 所以,需要设置重新连接机制。
nwpc-ecflow-collector
nwpc-oper/nwpc-ecflow-collector 项目使用 ecFlow 的 Python API 获取系统的运行状态。
该项目在 NWPC 监控平台 (NWPC Monitor Platform, NMP) 中应用时,从 Linux 服务器远程连接 ecFlow 服务绑定的 TCP 端口,获取节点运行状态。
但 ecFlow 的 API 没有对数据进行压缩,对于挂载任务数比较多的服务(例如集合预报和产品后处理系统等),整个获取过程速度很慢。
为此,笔者开发 nwpc-oper/ecflow-client-cpp 项目,将 ecFlow 的采集程序放到高性能计算机的登陆节点上,使用 gRPC 向外提供服务。
详情请参看以下文章:
但上述程序缺乏像 ecflow 程序一样稳定性,可能会因为不明原因退出。 笔者已对工具进行了优化,详情请参看以下文章:
但仍不能保证程序可以一直提供服务。 所以,需要类似 Supervisor 一样监视程序运行情况的机制。
NWPC 的核心业务系统都运行在 HPC 上,但只是 HPC 的普通用户,无法启动操作系统级的守护进程。
NWPC 使用 ecFlow 调度和监控数值天气预报业务系统。 根据多年使用经验,ecFlow 进程很少因为异常原因而退出,能一直保持运行。 所以,笔者使用 ecFlow 构建 HPC 登陆节点上后台服务的监控系统。
方案
监控系统定时启动任务,检查后台服务是否运行,如果没有找到后台服务,会重新启动后台服务。
下图是监控系统运行流程的示意图。
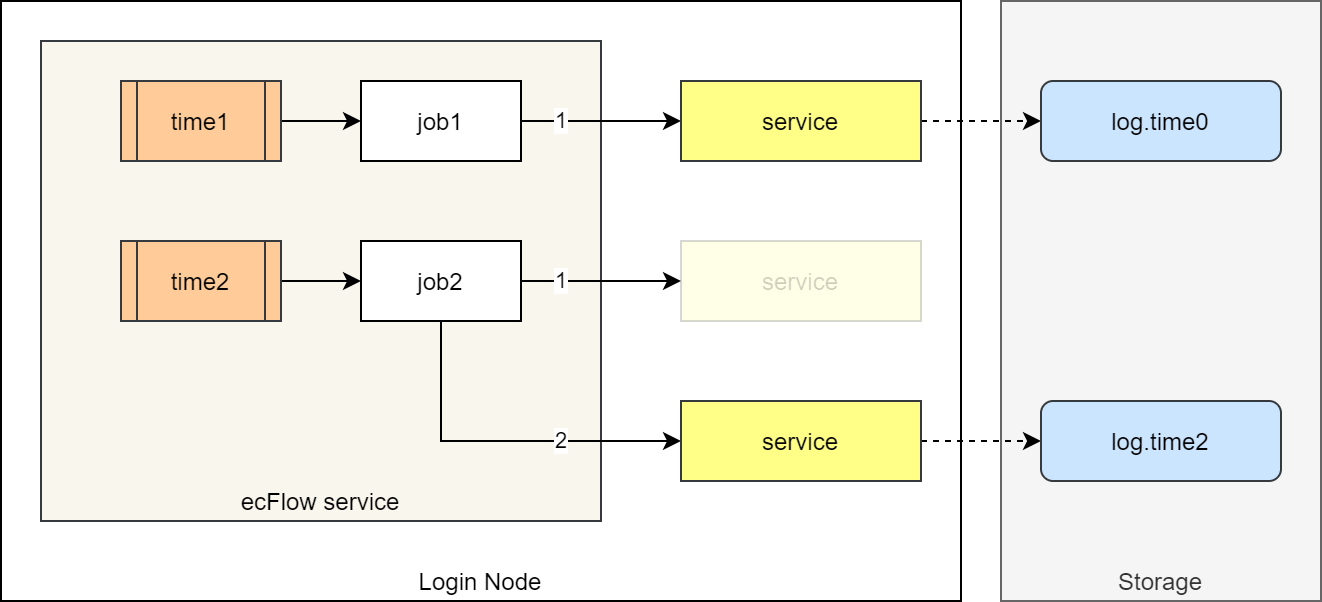
基于 ecFlow 的服务监控系统运行流程示意图
假设之前已在 time0 时刻启动后台服务 service,服务的日志写入 log.time0 文件中。
在 time1 时刻,ecFlow 服务运行作业 job1,检测到 service 已运行,作业 job1 运行结束。
假设某一时刻因某种原因,后台服务 service 异常结束。
在之后的 time2 时刻,ecFlow 服务运行作业 job2,检测到 service 没有运行,作业 job2 会重新运行后台服务 service,并让服务的日志写入新的 log.time2 文件中。
实现
后台运行程序
使用 nohup 命令实现将程序在当前节点的后台运行。
下面的代码在后台运行 nwpc_message_client 程序,并将标准输出和标准错误输出打印到同一个日志文件中。
nohup ${message_client_base}/bin/nwpc_message_client \
broker \
--address=${message_address} \
>${message_broker_data}/log/log.${current_log_name} 2>&1 &NWPC 的 ecFlow 服务运行在高性能计算机的登陆节点上,所以 ecFlow 运行的本地任务中启动的后台服务也同样运行在登录节点中。
检查进程
检测后台服务是否运行可以检查服务进程是否存在。
pgrep 会返回所有符合筛选条件的进程号,如果没有匹配的进程,退出码为 1。
pgrep -f "ecflow_watchman"168710
如果后台服务同时只可能有 一个 程序在运行时,就可以使用 pgrep 实现进程检查的功能。
下面代码检查是否有包含 ecflow_watchman 的进程,如果不存在则重启,如果存在则忽略。
if ! pgrep -f "ecflow_watchman" &> /dev/null 2>&1; then
echo "checking ecflow_watchman...failed"
# restart program
else
echo "checking ecflow_watchman...successful"
fi如果单个节点中可能同时运行 多个 后台服务程序,则无法使用上述方法。
检查 TCP 端口
如果服务使用 TCP 端口,可以通过检查端口是否被占用判断后台服务是否运行。
lsof 可以列出打开的 TCP 端口。
下面的程序查找 33384 端口是否被占用,输出结果表明该端口已被占用。
lsof -i :33384 -sTCP:LISTENCOMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nwpc_mess 216353 nwp_pd 3u IPv6 73939062 0t0 TCP *:33384 (LISTEN)
如果端口没有被占用,上述命令输出结果为空。
下面代码根据 lsof 返回结果的行数是否为 0 判断后台服务 nwpc_message_client broker 是否运行。
check_result=$(lsof -i :${message_port} -sTCP:LISTEN | wc -l)
if [ ${check_result} -eq 0 ]; then
echo "checking nwpc_message_client...failed"
# restarting nwpc_message_client...
else
echo "checking nwpc_message_client...successful"
fi这种方法适合同一节点上同时运行多个相同程序的情况。
定时检查
ecFlow 提供的 Cron 可以实现定时检查后台服务的功能。
NWPC 数值预报业务系统的 ecFlow 每天滚动循环。 整个系统所有任务都完成后,日期才会增加 1 天。
但 ecFlow 中设置 Cron 的任务永远不会完成,所以不能使用上述的日期滚动机制。
不过检查程序不依赖于具体时间,可以直接使用系统时间。
下面代码创建一个定时检查的任务,从 00:01 到 23:58 每 5 分钟运行一次。
with suite.add_family("message") as fm_message:
with fm_message.add_task("check_broker") as tk_broker:
cron = Cron("00:01 23:58 00:05")
tk_broker.add_cron(cron)
tk_broker.add_variable(common.sjob())
tk_broker.add_variable(
"ECF_SCRIPT_CMD",
"cat {ecf_files}/check_message_broker.ecf".format(
ecf_files=self.suite_attrs['ECF_FILES']
)
)日志
为了方便查看自动重启的情况,服务监控系统在每次启动程序时,将程序的输出重定向到一个新的日志文件中。
文件名包含启动程序的时间,例如:
current_log_name=${broker_user}.${broker_host}.${broker_port}.$(date "+%%Y-%%m-%%d.%%H-%%M-%%S")
nohup ${message_client_base}/bin/nwpc_message_client \
broker \
--address="[::]:${message_port}" \
>${message_broker_data}/log/log.${current_log_name} 2>&1 &生成的日志文件名类似
log.nwp_pd.login_b06.33384.2020-07-24.13-16-47
当然,这只是一种折衷方案。 服务的日志不应该只写入到一个文件中。 从文件名判断后台服务运行情况也不够精确。 后续笔者计划在重启服务时向 NWPC 消息平台发送一种通知消息,无需对日志的文件名进行约束。
运行情况
服务监控系统 (service_checker) 已在 NWPC 实时运行,处于评估阶段。
业务技术研发的不同阶段:
构建 -> 评估 -> 测试 -> 运行
系统的 ecFlow UI 截图如下所示:
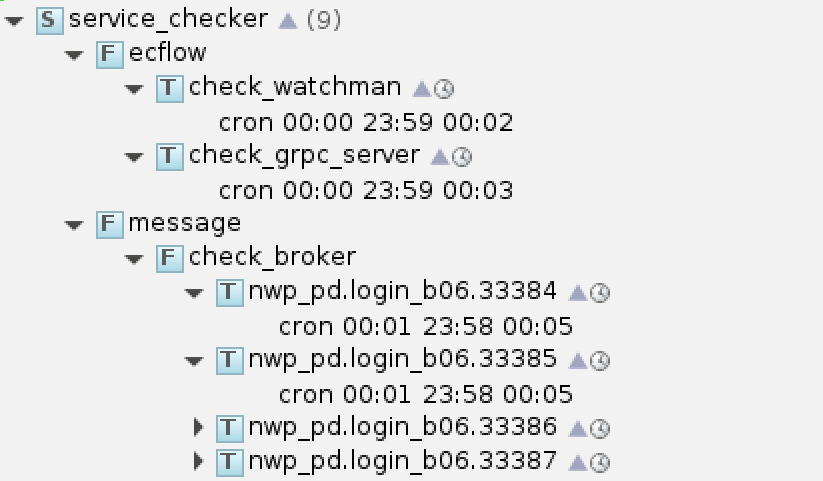
服务监控系统 service_checker
监控的后台服务包括:
- ecFlow 节点运行状态监控程序 (checker_watchman)
- ecFlow 运行状态 gRPC 服务 (checker_grpc_server)
- NWPC 消息平台 HPC 代理服务 (checker_broker)
从日志目录可以看到,除了 7 月份 HPC 用户目录迁移期间外,各个后台服务均稳定运行。 迁移目录期间因为找不到链接库而导致服务无法正常启动时,监控系统也能一直尝试重启。
总体来说,基于 ecFlow 构建的服务监控系统能满足业务需求,能有效保障后台服务的持续运行。
参考
ecFlow 的 cron 文档: