视界:ECMWF在Maestro项目中的借调
Secondment at ECMWF on the Maestro project
by Domokos Sarmany and Miloš Lompar
31 January 2022
https://www.ecmwf.int/en/about/media-centre/science-blog/2022/secondment-ecmwf-maestro-project
原文发表于 ECMWF 网站科学博客文章《Secondment at ECMWF on the Maestro project》,介绍在 Maestro 项目中借调人员 Miloš Lompar 的工作。
以下正文章节是对该文章的节选翻译,并根据笔者个人理解有所修改,如有偏差敬请谅解。
正文
数值天气预报可以生成多少预报数据?
非常多,但远远不够。
ECMWF 的 IFS 目前每天生成 120 TiB 业务预报数据。 但更准确的天气预报需要提高模式分辨率,意味着当前数据量与未来预报将产生的数据量相比相形见绌。 这就带来了技术挑战。
数值天气预报 (NWP) 一直是高性能计算 (HPC) 领域技术创新的早期采用者,并部署了世界上性能最好的一些超级计算机。 最新的例子是 ECMWF 即将推出的 ATOS 超算。 然而,多年来,科学家面临的技术挑战发生了变化。
几十年来,执行浮点运算 (floating-point operations, flops) 的绝对速度和相关计算成本是主要问题,带来针对浮点运算进行优化的软件栈和编程模型,但将数据处理视为二等公民。 在内存中访问足够的数据以及最近以来的存储吞吐量,在过去的二十年中已成为重大瓶颈 ———— 这种现象通常被称为 IO 性能差距 (performance gap)。

图片来自原文,ECMWF 的下一台超级计算机将由四个 Atos BullSequana XH2000 集群组成,并计划于 2022 年投入使用
中心的产品生成引擎 (Product generation engine, PGen) 使用了 70% 的业务预报数据来生成最终产品,并分发给成员国、合作国以及商业用户。
产品生成是一个高度 I/O 密集过程。 在一个小时的时间关键窗口内,预报输出被持续写入到硬盘中,同时 PGen 读取和处理可用的数据。 由此产生的 I/O 阻塞是中心当前业务系统最主要的瓶颈之一。 随着未来几年内模式分辨率计划提高到 5km 或甚至 1km,显然需要探索 数据移动 (data movement) 领域的新途径。
迈向新的数据移动中间件:Maestro 项目
Maestro 项目的 Maestro 中间件用于实现跨复杂科学工作流的高效数据移动。
ECMWF 以 IFS 参与该项目,属于 ECMWF 可扩展性计划 (ECMWF Scalability Programme) 的一部分 ———— 有助于确保 ECMWF 能够充分利用未来计算架构的潜力,并为更高分辨率的预报奠定基础。
下图展示在 ECMWF 业务工作流程使用 Maestro 中间件的一种潜在应用:
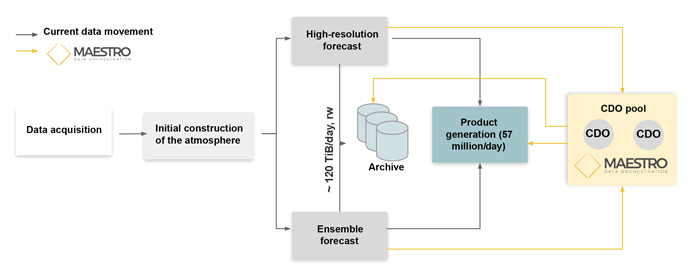
图片来自原文,在 ECMWF 业务工作流中使用 Maestro 中间件的潜在结构。核心数据对象 (Core Data Object, CDO) 表示数据的基本单元,例如单个二维全球场
测试将数据通过 Maestro 中间件从预报模式传递给 PGen,下图展示高层设计。 一个关键组件是 Maestro 池管理器 (Maestro pool manager),在数据生产者和消费者之间组织数据移动。ECMWF 中:
- 生产者:高分辨率模式和集合预报模式生成的输出数据
- 消费者:PGen 实例将预报数据处理成产品
每个消费者都被实现为一个多线程程序,其中一个代理响应来自池管理器的数据可用性通知,多个工作线程执行后处理工作。
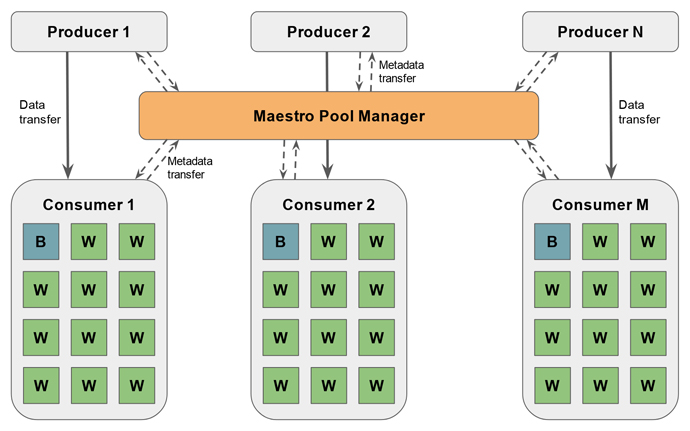
图片来自原文,适用于 Maestro 中间件的 I/O 基准测试。池管理器 (PM) 协调生成模拟天气预报的多个生产者和运行产品生成的多个消费者之间的数据流。所有元数据通信都通过 PM 执行,而数据传输直接发生在生产者和消费者之间。每个消费者都被实现为一个多线程程序,具有一个代理 (B) 和多个工作线程 (W)
至关重要的是,上图所示的设计将元数据通信与数据传输分离,并避免将两者写入磁盘。 由于中间件使用远程直接内存访问 (remote direct memory access, RDMA),超级计算机节点之间的数据传输速度特别快。 RDMA 允许超级计算机的两个节点在不涉及处理器、缓存或操作系统的情况下访问彼此的内存。 因此,只有 PGen 生成的输出产品被写入磁盘。
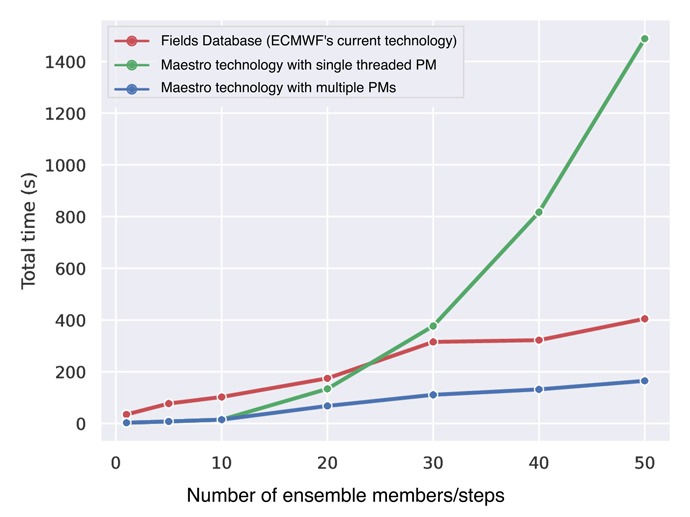
图片来自原文,不同数量的集合成员和预报步数的总工作流执行时间:当前技术 (ECMWF 的要素数据库(FDB))(红色);单线程池管理器 (PM)(绿色)的 Maestro 技术;使用多个单线程池管理器 (PM) 的 Maestro 技术作为模拟多线程池管理器(蓝色)的一种方式。
上图显示 50 个生产者和 50 个消费者的测试结果。
- 元数据通信的作用至关重要,因为应用单个池管理器会降低速度(绿线)
- 只要应用足够多的池管理器 (蓝线与红线和绿线相比),该创新技术可以实现显着(高达 2.5 倍)加速
Maestro 技术仍处于早期开发阶段,但我们的原型实施显示了一条通往技术的潜在途径,该技术可能会缓解生成更精确的全球业务预报数据的主要障碍之一。
讨论
本文介绍的 Maestro 中间件主要用于提供高效的数据移动,尤其是在 HPC 内部的模式预报系统和产品制作系统之间的数据流动将在内存中实现,而不需要将文件写入到 HPC 的分布式文件系统中。 Maestro 项目正处于开发阶段,ECMWF 会将正在开发和当前已有的组件集成到 Maestro 中间件中,包括:
以上三个组件在 CEMC 的 NWP 系统中都有相似的功能:
- 模式输出的二进制文件使用并行 MPI IO 写入到文件系统中
- 数据管理采用目录方案,按照一定规则将模式数据存放在分级目录中,并保持 HPC 分布式文件系统和 NAS 二级存储文件系统中的目录一致性
- 统一后处理模块实现并发诊断量产品生成并编码成 GRIB2 格式写入到文件系统中
模式输出
CEMC 数值天气预报模式业务系统中产品制作任务使用的程序、脚本均面向本地文件系统开发,即依赖支持 POSIX 协议的文件系统。
模式积分模块输出二进制格式的模式面要素场及筛选的部分等压面/地面要素场,通过并行 IO 以同步方式写入到 HPC 的分布式文件系统中。 业务系统 ecFlow 工作流会运行一个脚本按照文件的输出顺序,在模式积分运行目录中依次检测文件是否输出,并将文件拷贝到 HPC 上的归档目录。 上述两个步骤均可能受到文件系统 IO 速度的影响。
从模式运行日志中统计模式积分耗时和文件输出耗时,单位为秒:
CMA-MESO 模式积分耗时与文件输出耗时
| 时次 | 模式积分 | 文件输出 | 文件输出占比 |
|---|---|---|---|
| 2022051100 | 6632 | 957 | 14% |
| 2022051112 | 6646 | 1342 | 20% |
| 2022051200 | 10562 | 5222 | 49% |
| 2022051200 rerun | 5587 | 325 | 6% |
| 2022051212 | 6337 | 1117 | 18% |
| 2022051300 | 6793 | 1312 | 19% |
| 2022051312 | 6431 | 1180 | 18% |
| 2022051400 | 6644 | 1153 | 17% |
| 2022051412 | 6475 | 1269 | 20% |
| 2022051500 | 9418 | 826 | 9% |
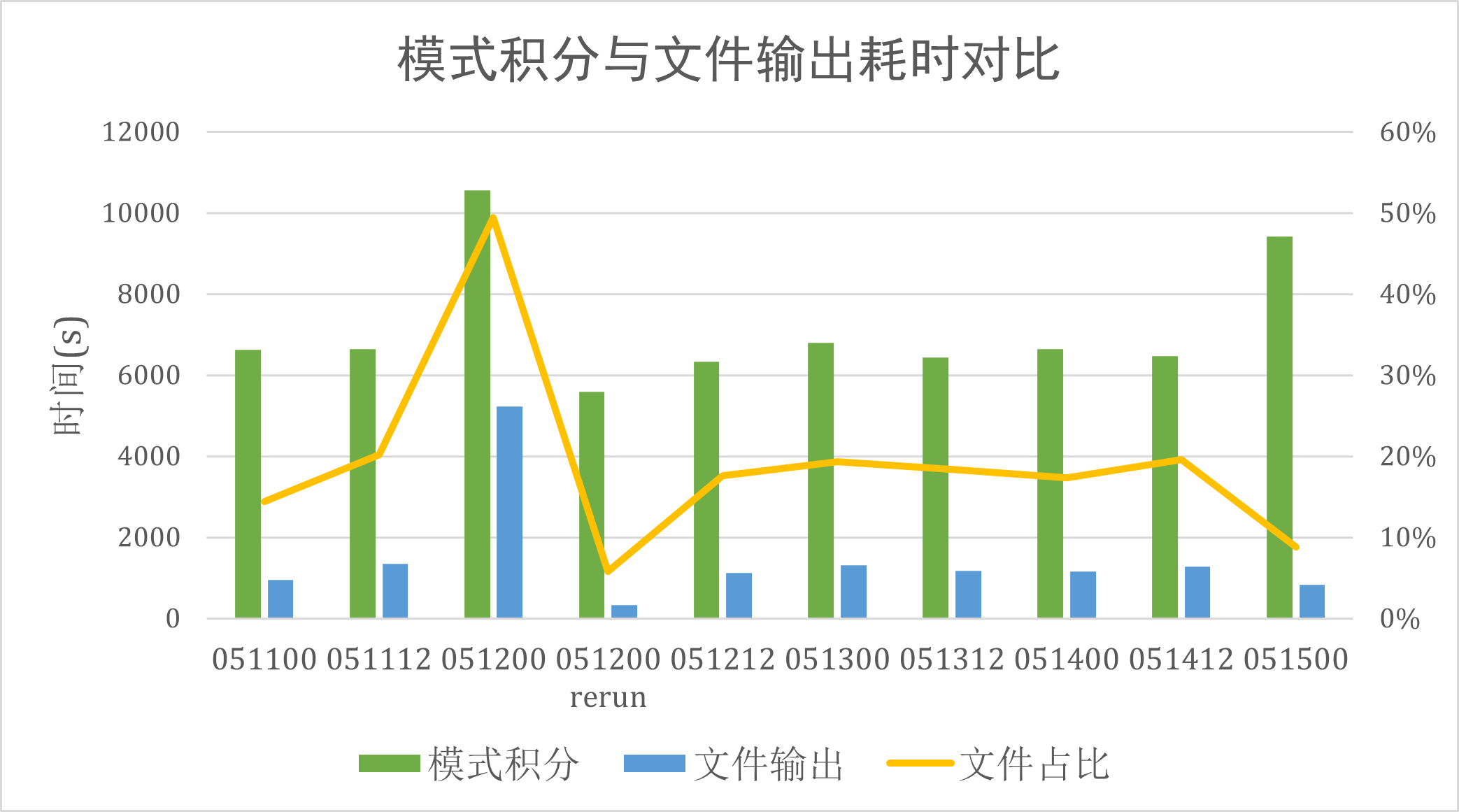
CMA-MESO 冷启动时次模式积分耗时 (051100 至 051500)
文件输出耗时与模式积分耗时的比例在 10% 至 20% 之间,也就是 100 分钟模式计算加上 10 到 20 分钟文件输出。 2022051200 时次文件输出耗时异常,同时该次积分结果中一个 MODELVAR 文件异常导致后处理模块出错。 笔者尚不清楚两者之间的是否存在对应关系,具体原因有待进一步排查。 笔者也不清楚文件输出耗时波动是否与磁盘 IO 速度有关。
文件拷贝 (cp) 耗时异常则是已经被证实的问题。
比如下图中的 fcst_monitor 是每个模式系统中的常见任务,监控模式积分进度,并将模式输出拷贝到归档目录中(参考博文《NWPC笔记:获取模式积分任务的执行进度》)。
文件系统 IO 速度变慢可能会导致文件拷贝速度赶不上模式积分速度的现象。
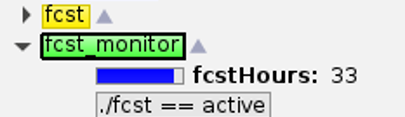
CMA-MESO 某时次模式 36 小时积分任务 fcst 运行结束,但数据拷贝任务 fcst_monitor 尚在运行
随着模式水平分辨率提高,同样时间窗内生成的数据量会急剧增长。
模式积分过程中采用同步方式将输出写入到分布式系统中的方式将会越来越受到文件系统 IO 速度的制约,而通过 cp 等命令顺序移动数据的方式也会成为整个业务系统的瓶颈。
为此,在即将到来的 CMA-GFS V3.3 版本中,我们计划将模式积分系统的运行环境从普通磁盘分区 (/g2) 迁移到 SSD 分区 (/g0),以期能提高文件读写的效率。
但受限于 SSD 分区的容量,不可能将全部业务系统的运行目录都迁移到高速分区,期待新一代 HPC 能提供更多的高速存储设备。
另一种可行的思路就是将同步输出改为异步输出,模式输出结果写入到内存数据库/内存文件系统中,再由模式积分之外的程序将该输出写入到磁盘中。 之前看到过有使用 Redis 内存数据库的研究项目,与 Maestro 的部分思路不谋而合。 当前 HPC 上暂时没有实施的迹象,期待下一代 HPC 能提供专用硬件来支持内存文件系统,或提供专门工具和计算节点来支持持续运行的内存数据库。 直接从内存中读取数据也会极大提高产品后处理任务的要素场访问效率,会改变实时业务系统访问要素场的方式,这就涉及到数据管理问题。
数据管理
目前数值预报业务系统采用目录方式管理数据,将数据产品分别保存到不同的目录中,参考《NWPC高性能计算机环境介绍:数据管理》。 业务系统将数据保存到不同的磁盘文件系统中,实时数据存储在 HPC 分布式文件系统中,历史数据保存在 NAS 二级存储中,同时部分重要数据会备份到在办公室存放的离线硬盘中。 因此数值预报业务系统产品制作任务也就会对接本地文件系统中的数据文件,使用的工具栈也都要求使用本地文件。
使用多层目录存放数据是最直观的数据管理方式,也有诸多优势。 但只有文件目录一种方式则会带来不少问题,比如:
- 用户必须了解目录规则,目录规则改变会直接影响下游对接该目录的业务系统。虽然我们开发数据文件查找工具 nwpc-oper/nwpc-data-client 将数据种类与文件目录解耦,试图降低对固定目录规则的要求,但目前该工具仅在部分产品制作系统中应用,尚未有用户使用。
- 需要提供在同一个平台访问多个文件系统的工具,例如 CMA-PI 上访问二级存储的 cmafs (参考《CMA-PI上共享存储访问工具cmafs介绍》)
- 缺乏访问特定要素场的合适方法,尤其是在 CMA-PI 上访问二级存储需要将全部数据文件下载到 HPC 本地文件系统中
- 单一的多层目录管理方式会制约数据治理工作的推进,目前仅有零散的 WORD 文档,缺乏统一且容易获取的数据内容说明,要素表格,数据汇总信息等等
参加工作以来,笔者所在部门一直致力于构建数值预报业务数据管理平台系统,已有阶段性成果并搭建试运行的数据平台,但尚未正式投入业务运行,没有向全单位推广应用,也没有在业务系统流程中应用。 至于为什么会是今天这种状态,可能一两篇文章也说不完,更可能是我自己就身在局中而不自知。 简单来说,有软硬两方面原因:
- “软”因素:技术储备不够扎实,研发目标不够明确,开发合作方式不够高效。
- “硬”因素:缺乏可以自己掌控的数据管理硬件基础设施,数据管理方向与 NMIC 的研究领域有重叠,数据管理平台不是单位的核心需求。
我们一直想要开发类似 ECMWF MARS 一样的数据管理平台,但总是在自行开发与使用 NMIC 现有技术之间反复摇摆。 顶层设计希望彻底贯彻集约化思想,充分开展合作开发,将数据平台融入到气象大数据云平台中。 但现实情况是几乎没有看到合作开发的成功案例,连附带应用开发资源的云平台账号都少有申请。 至少笔者就担心如果单位都不使用云平台基础设施进行开发,或者涉及云平台的系统都由工程项目来实现,那还有必要去研发仅能在云平台上使用的技术么?
不过,对于应用在实时业务系统中的ECMWF 要素数据库 FDB,我们确实可以模仿实现。 产品制作任务,尤其是图形绘制任务,需要的不是数据文件全集,而是某些特定要素场。 虽然目前从全集数据文件中抽取绘图需要的要素场不是性能瓶颈,但绑定本地数据文件的绘图脚本缺乏灵活性,无法使用远程数据绘图。 而且如果未来模式改为异步输出,也会需要类似 FDB 的要素数据库。 但从想法到实现还有很长一段路要走,笔者认为要素数据库是需要自研的核心技术,需要探索合适的合作开发机制,要考虑如何利用现有的成果,要确定技术选型,要设计可行的开发路线图。
无论最终数据平台由谁来建设,最终会是什么样子,业务系统中的产品制作任务始终是数据平台必须首先考虑并实现的应用场景。
产品制作
数值预报业务中的统一后处理系统是独立于模式系统的软件包,使用 MPI + GRIB API 实现诊断量产品的并行计算及 GRIB2 编码。 在该软件包的支持下,CEMC 的模式系统大多保持模式积分与产品制作相分离系统构建策略。 同时因为 CEMC 数值预报模式的大部分产品都只使用单一模式系统的输出数据,因此每个模式系统都有自己的独立于模式积分流程的产品后处理 ecFlow 工作流。 上述方式已成功支撑十年以上的业务运行需求,但随着CMA 模式的自身发展和国内外形势的复杂变化,当前的产品制作流程逐渐暴露出一些问题:
增加系统复杂性:模式积分与产品制作分离的策略虽然利于保持模式积分流程的稳定性,但却增加了需要维护的业务系统总数,增加了构建系统的工作量,也增加了整个业务系统的复杂性。
无法应对多模式产品:每个模式单独的后处理系统能应对单模式产品,但不适合制作使用多个模式数据的产品。 因为当前分离的模式后处理系统只能通过检测文件是否存在来判断是否启动相应的产品制作任务,多模式产品需要监听多个目录下的数据文件,导致系统会变得比较复杂。 随着各类服务保障工作开展,多模式集成产品会越来越多,有必要思考更高效合理的产品制作系统构建方式。
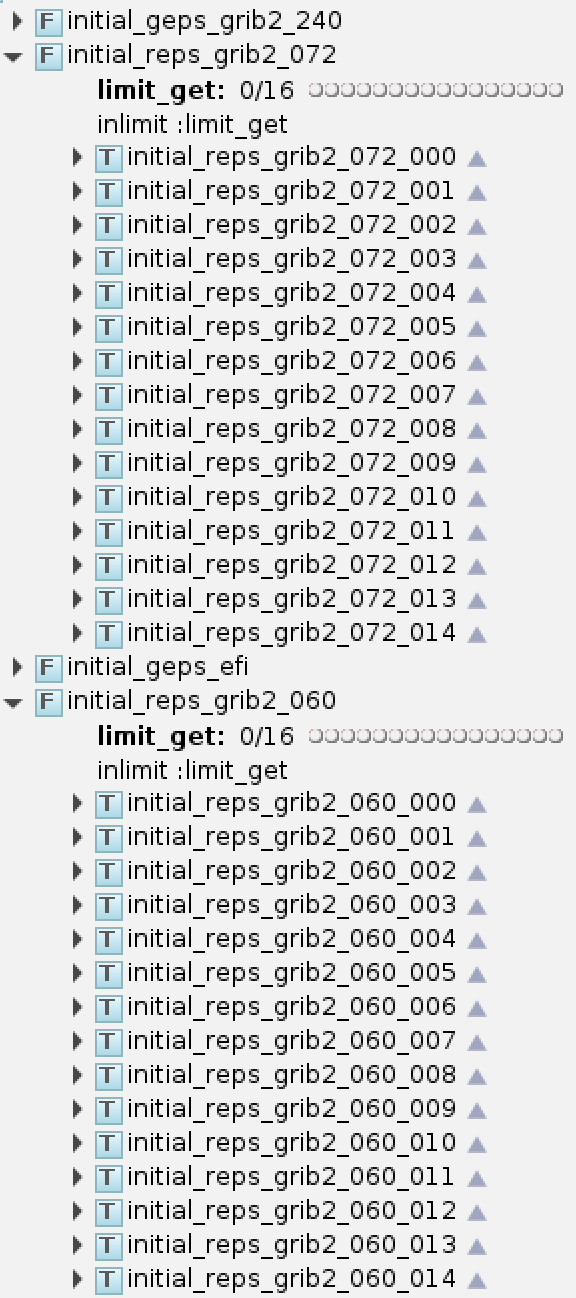
多模式集成产品需要为每类数据编写单独的数据检查脚本
当前正在对产品后处理系统流程进行云化改造,将 HPC 上的串行产品制作任务包装成 CMADaaS 上的算法,迁移到加工流水线上运行。 沿袭现有基于数据文件的产品制作方式,只不过将某些串行任务从 HPC 迁移到云平台。 该方案通过 FTP 将模式输出的基础 GRIB2 产品传输到 CTS 系统,CTS 系统将接收到的文件转发到 CMADaaS 的模式专题库中,CMADaaS 完成数据存储后会向天镜发送 DI 消息。 产品制作系统需要订阅该消息,触发在加工流水线上部署的特定算法,在 CMADaaS 计算资源池中启动容器运行算法,容器会自动挂载模式专题库的基础数据集,在运行目录生成图片并通过分发算法发给下游用户,同时图片产品也会保存在模式专题库中的产品库中。

数值预报业务系统融入天擎大数据云平台示意图,v2022.05.1
上述方案通过消息机制启动后处理任务,让多模式集成产品任务能更方便地监控数据可用性。 但该方案进一步增加了业务系统的复杂性,从 HPC 单一平台变为 HPC + Cloud 多平台,无论从系统开发还是系统维护方面来讲都会给当前运维团队带来严峻的挑战。 上述方案目前正通过工程项目来实现,未来产品制作任务到底应该如何运行还需要进一步探讨。 不过考虑到云平台上的系统平台更适合通过工程项目方式来实现,以及后续很可能会引入社会化运维服务,依照谁开发谁维护的 DevOps 理念,将业务系统的非核心部分从 HPC 分解到 Cloud 上就显得非常有必要。
虽然向云平台集约是趋势,但笔者一直对从 HPC 转向云平台心存犹豫。 在单位中从事某类同方向人稀少(或者就一个人)的研发工作(尤其是气象信息化方面)既有优势又有劣势,优势就是至少在单位内部不会形成内卷,劣势是可能大家都不知道你在干什么。
笔者认为上述方案还有一个问题:通过 FTP 向 CTS 传输模式数据是否会有性能瓶颈?
当前数值预报模式业务系统一天生成的模式原始数据量为 25TB 左右,基础 GRIB2 产品为 1TB。 根据《中国气象科技发展规划(2021-2035 年)》,模式数据后处理能力到 2025 年要超过每天 200 TB,到 2035 年要超过每天 1PB。 无论规划中的数字指的是原始数据量还是编码后的 GRIB2 数据量,2025 年目标都远远高于当前数据量。 如果继续采用 FTP 文件传输的方式,不知道网络带宽能否满足时效性需求,基于 FTP 的大规模数据迁移是否能应对海量的产品制作需求。
CMA天气模式一天数据量,v2022.05.1
| 模式 | 模式原始输出(TB) | 基础GRIB2产品(TB) | 模式面GRIB2产品(TB) |
|---|---|---|---|
| CMA-GFS | 1.61 | 0.09 | 0.106 |
| CMA-MESO | 6.79 | 0.4 | 0.6 |
| CMA-TYM | 3.54 | 0.14 | 0.4 |
| CMA-GEPS | 8.19 | 0.26 | |
| CMA-REPS | 4.36 | 0.16 | |
| 合计 | 24.50 | 1.05 | 1.11 |
鉴于以上分析,笔者认为未来可行的方向是开发 CEMC 版本的 PGEN 系统,利用实时要素库 FDB 作为数据源,让产品制作系统不再依赖本地或网络文件系统。
当然只有真正用起来,才能知道到底行不行。本节内容全都是主观臆断,仅代表个人观点,不排除未来想法会改变。
参考
文章原文:Secondment at ECMWF on the Maestro project
相关文章:
