视界:HPC 2020 - ECMWF 新高性能计算机
ECMWF 最新一期的 Newsletter 中介绍了它们的下一代高性能计算机 HPC2020。 虽然我们部门不负责 HPC 项目,但作为深度用户,即便我们未来也许会采用不一样的技术路线,也可以学习一下。
声明
本文正文内容翻译自 ECMWF Newsletter Number 163 - Spring 2020 中 Mike Hawkins 和 Isabella Weger 的文章《HPC2020 – ECMWF’s new High-Performance Computing Facility》,版权归原作者所有。 翻译底稿来自 Google 翻译和必应翻译。
正文
ECMWF 的高性能计算设施(HPCF)是业务和科研活动的核心,平均每四到五年进行升级。 作为 HPC2020 项目的一部分,ECMWF 最近为新系统签订了合同,该系统由四个 Atos Sequana XH2000 群集组成,将提供由两个 Cray XC40 群集组成的当前系统大约五倍的性能。
HPC2020 项目
更换 ECMWF 的 HPCF 经过多年的努力。 HPC2020 项目最早于 2017 年启动,并获得了商务案例的开发和批准,随后于 2019 年底完成了国际采购。 HPC2020 的实施阶段于 2020 年初开始(图1)。

图1 HPC2020 项目已从商务案例和采购阶段转到实施阶段。
商务案例和采购过程
ECMWF 的《2016-2025年战略》中设定的目标包括: 在最多两周之前对高影响天气做出精确的整体预报,并在未来四周之前预报大规模模式和天气变化(large-scale patterns and regime transitions),并在全球范围内提前一年预测异常情况。 这些雄心勃勃的目标只有通过适当的高性能计算能力才能实现。
2017 年 12 月,ECMWF 理事会审议并批准了 HPC2020 商务案例,以增加对计算资源的投资。 理事会认识到 HPC 资源对于成功实施该战略至关重要,批准将 HPC 预算增加约 75%,其中包括预期的四年服务期限内 HPC 服务合同的成本以及对系统用电成本的贡献。
ECMWF 的采购方法是在可用预算范围内最大化主要应用程序的性能。 因此,性能基准是基于运行与 ECMWF 相关的两个不同工作流: 能力基准,以潜在的未来分辨率模拟时间紧迫的预报(包括产品生成)工作流; 以及基于典型科研工作流的容量,评估预期科研负载的系统吞吐量。 为了近似实际的工作流,这些基准测试由相互依赖的任务组成,包括输出和从保存完整业务数据集的持久存储中读取数据。
关于提供高性能计算设备的招标邀请于 2018 年 11 月发布,并于 2019 年 3 月结束。 在 2019 年 12 月理事会成员国委员会对采购结果进行审查之后,授权 ECMWF 总干事签署与中标者 Atos UK Ltd. 的合同。 新的 HPCF 根据协议将提供为期四年的服务,并且根据对时间要求严格的性能和容量基准,性能将比当前系统提高约 5 倍。 它将安装在位于意大利博洛尼亚的 ECMWF 的新数据中心中,并将与现有的 Cray HPCF 并行运行直到 2021 年 9 月,届时新的 Atos 系统将接管四年的业务服务,直到 2025 年秋天。
新的数据中心,新的超级计算机
ECMWF 位于英国雷丁的新菲尔德公园的现有数据中心在40多年时间里已经很好地实现了宗旨,将不再适合托管下一代超级计算机。 因此,ECMWF 成员国于 2017 年 6 月批准了意大利政府和 Emilia Romagna 地区在意大利博洛尼亚托管 ECMWF 新数据中心的提案(译者注:英国于 2016 年 6 月公投决定脱欧)。 新的数据中心位于新的博洛尼亚 Tecnopolo 园区内,该处以前的烟草工厂的闲置建筑物和场地正在重新开发(图2)。

图2 ECMWF在意大利博洛尼亚 Tecnopolo di Bologna 的新数据中心(艺术家的印象)。(图片:gmp von Gerkan,Marg & Partner)
HPC2020 项目是更广泛的博洛尼亚数据中心计划(BOND)的一部分,该计划还包括新数据中心的交付。 HPC2020 的时间表与数据中心的交付紧密相连。 它们的设计旨在使新的 HPCF 在 ECMWF 当前的 HPCF 合同到期之前就可以投入使用,从而为两个项目的发展提供必要的灵活性以适应时间表。
随着 ECMWF 整个数据中心运营转移到博洛尼亚,迁移不仅包括 HPC 应用程序,例如 ECMWF 的 IFS 系统。 迁移项目正在管理科学应用程序迁移以及数据处理系统中保存的数百 PB 数据的移动。
新的 HPC2020 设施
新系统的规范基于 ECMWF 在 HPC 方面的长期经验和新要求。 在这里,我们介绍一些关键概念,系统配置和软件环境。
通用概念
在较高的层次上,设计中有一些重要的概念:
HPC 设备
该项目将提供一个完整的 HPC 设备,而不仅仅是一台新的超级计算机。 要求包括 24x7 全天候的硬件和软件支持,专职应用程序分析师以及为支持机器而定制的数据中心。
多集群
ECMWF HPC 工作负载主要由短时运行的高吞吐量作业构成:系统中 90% 的资源由需要少于 8,000 个处理器核心的作业所使用。 这一特性与 ecFlow 工作负载管理的灵活性相结合,消除了将所有资源都放在一个大型集群中的需求。 因此,ECMWF 的许多代 HPC 系统都有两个独立的集群,即使一个集群发生故障或为了维护而关闭,也可以运行业务系统。 拆分计算资源还可以减少对共享组件(例如作业调度程序和网络)的争用,从而使系统更加可靠和可管理。 对于 HPC2020,群集数增加到四个,以进一步提高弹性。 例如,可以将一个集群升级到最新的软件级别作为测试,同时仍为保持弹性业务系统。
拆分科研和业务文件系统
业务系统的时间表非常紧张。 系统在研究到生产(R2O)的转化过程中经过仔细设置和测试,以满足产品时刻表,良好的 I/O 性能是其中的关键部分。 为避免可预测的业务作业可能与来自其他来源的 I/O 密集型作业相竞争,有专门的和独立的文件系统用于业务和科研工作。
多文件系统
与拥有多个计算集群类似,拥有多个文件系统可以提高伸缩性和可维护性,并限制大规模资源争用。 这些考虑对于存储子系统特别重要。 这部分是由于所使用的 Lustre 文件系统的设计所致,该系统在每个文件系统中只有一个元数据服务器,部分是由于磁盘是可能发生故障的机械设备。 所有文件系统都连接到所有四个群集。 这具有可以将作业调度到任何群集的巨大好处,但是它的确引入了整个系统的常见故障点,因为有故障的文件系统可能会影响所有群集。
通用和交互登陆节点(GPIL)
HPC 系统始终运行不同类型的工作负载,主要是在多个节点上运行的并行作业,但也有仅需要一个节点甚至一个核心的作业。 将整个 128 核节点用于仅需要一个处理器内核的作业显然会浪费资源,因此,通常将此类工作分配给专用节点,在该专用节点上,多个作业可以有效地共享该节点。 过去,ECMWF 的 Linux 集群 lxc,lxop 和 ecgate 还提供了其他位置来运行此类的工作负载。 随着数据量的显着增加,越来越不希望将大量数据移至其他平台。 因此,由于应用程序的大量重叠,这项工作的所有资源都包含在新的 HPC 系统中。 另外,由于数据量大,我们希望在系统上进行更多的交互式数据分析,可视化和软件开发。 这些活动还将在一组专用 GPIL 节点上运行。
时间关键型存储层次结构
自从 ECMWF 购买最后一个 HPC 系统以来,固态磁盘(SSD)已变得司空见惯。 它们具有更好的访问时间和更低的延迟。 因此,它们是在少量存储空间中实现高 I/O 性能的宝贵手段,尤其是在访问小文件时。 但是不幸的是,在相同容量下,它们仍然比传统的基于磁盘的存储昂贵。 因此,新的 HPCF 具有分层存储设计,除了传统的磁盘存储池外,还具有两个 SSD 存储池。 每个 SSD 池旨在将由业务预报系统生成的数据保存几天。 在此时间之后,系统会将数据移到容量更大但性能较低的存储池中。
Home 文件系统
除高性能并行文件系统外,还需要通用存储空间。 在当前的 HPCF 中,无法从系统外部看到 HPCF 上的 “home” 和 “perm” 文件系统。 在新的 HPCF 中,HPCF 和其他系统之间的 home 空间和 perm 空间是通用的。
Atos Sequana XH2000 系统配置
Atos的主要系统由四个独立的集群组成,也称为 “complexes”(表1)。 每个群集都连接到所有高性能存储。 有两种类型的节点在运行用户工作负载:用于并行作业的 “计算节点” 和用于通用和交互式工作负载的 “GPIL节点”。 其他节点具有特殊功能,例如管理系统,运行调度程序以及连接到存储。 有关单个群集的示意图,请参见图3。
7488 个计算节点构成系统的大部分,位于 Bull Sequana XH2000 高密度机架中。 每个机架有 32 个刀片(图 4),每个刀片有三个双插座节点,并使用 Direct Liquid Cooling 从处理器和存储器中提取热量到机架中的液体冷却回路。 这种冷却方法允许计算节点密集包装,并将机架数量降至最低。
机架底部的热交换器连接到建筑物的水冷却系统。 机架中的冷却系统允许水流入的温度高达40°C。 这为仅使用外部空气进行冷却提供了很多机会,而无需使用耗能的冷却器,减少了系统所需的电量并提高了整体效率。
表格1 Cray XC40 系统和新的 Atos Sequana XH2000 系统
| Cray XC40 | Atos Sequana XH2000 | |
|---|---|---|
| Clusters | 2 | 4 |
| Processor type | Intel Broadwell | AMD Epyc Rome |
| Cores | 18 cores/socket, 36 cores/node | 64 cores/socket, 128 cores/node |
| Base frequency | 2.10 GHz | 2.25 GHz (compute) 2.5 GHz (GPIL) |
| Memory/node | 128 GiB (compute) | 256 GiB (compute) 512 GiB (GPIL) |
| Total number of compute nodes | 7,020 | 7,488 |
| General purpose ‘GPIL’ nodes | 208 | 448 |
| Total memory | 0.9 PiB | 2.19 PiB |
| Total number of cores | 260,208 | 1,038,848 |
| Water-cooled racks | 40 | 80 |
| Air-cooled racks | 0 | 10 |

图 3 HPC 群集的概述,系统中有四个。
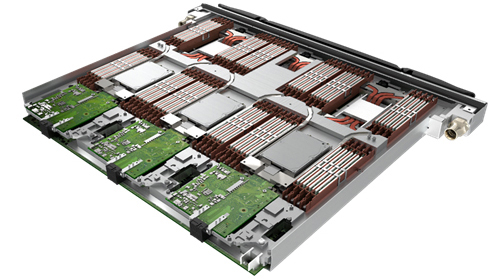
Sequana XH2000 AMD 计算刀片,包含三个节点。
系统中第二种类型的节点是 GPIL 节点,它们以略高的频率运行,并且比计算节点有更多的内存。 不同的节点类型允许 Atos 在每个节点中包括一个 1 TB 固态磁盘,用于本地高性能存储。 具有 GPIL 节点的机架比计算节点机架的密度较低,因此可以使用更简单的冷却基础架构。 风扇从 GPIL 节点带走热量,并通过水冷散热器“后门”热交换器将热空气吹出。 尽管与直接液体冷却相比,这是一种效率较低的冷却方法,并且虽然它不能处理相同类型的热负荷或冷却水温度,但使用标准服务器有助于维护且成本较低。
ECMWF 的存储需求一直是任何系统需求的很大一部分。 如表2所示,新系统的存储使用 Lustre 并行文件系统,并由 DataDirect Networks(DDN)EXAScaler 设备提供。 使用 Lustre 文件系统使解决方案非常像当前系统上的存储。 但是,较新的 Lustre 版本包含诸如 “Data on Metadata” 之类的功能,以提高性能。 主要用于处理大文件的存储阵列和 Lustre 在处理许多小文件时可能会非常慢。 新的元数据功能允许将较小的文件存储在控制器上,而不是存储在主磁盘存储阵列上,这将显着提高性能。
表2 高性能存储
| Time critical – short term | Time critical – working | 科研 | |
|---|---|---|---|
| IO Fabric racks | 1 (shared) per hall, 2 in total | ||
| Storage racks | 3 per hall | 9 per hall | |
| Total racks (air cooled) | 13 per hall, 26 in total | ||
| Storage | DDN ES200NV | DDN ES7990 | DDN ES7990 |
| Usable storage | 1.4 PB | 12 PB | 77 PB |
| Bandwidth | 614 GB/s | 224 GB/s | 1,570 GB/s |
高性能计算机与机架中的许多单台计算机之间的关键区别因素是将节点连接在一起并允许它们高效交换信息的网络。 Atos 系统使用 Mellanox 生产的最先进的“高数据速率”(HDR)InfiniBand 网络。 HDR 技术通过将延迟(消息从一个节点发送到另一个节点的时间)降低到不到一微秒,并使每个群集的对等带宽每秒超过 300 兆比特(对应于同步播放 3750 万部高清电影),从而提高了应用程序性能。
群集中的计算节点分为四个 Sequana 机架的“单元”。 每个单元都有“叶子”和“脊椎”开关。 每个计算节点都连接到一个叶子交换机,每个叶子交换机都连接到该单元中的每个主干交换机,因此,一个单元中的所有 384 个节点都连接在无阻塞的“胖树”网络中。 每个主干交换机均与每个其他单元中的相应主干都有连接,从而产生“全带宽 Dragonfly +”拓扑。 GPIL 节点已连接到高性能互连,因此它们可以完全访问高性能并行文件系统。
除了用于计算和存储流量的网络连接之外,还需要与其余 ECMWF 的网络连接。 网关路由器从高性能互连模块连接到新 ECMWF 数据中心网络中的四个独立网络,从而可以从其他计算机直接访问 HPC 系统中的节点。
软件环境
“Atos Bull Supercomputing Suite” 是适用于 HPC 环境的 Atos 软件套件。 它提供了一个标准环境,包括基于 Mellanox InfiniBand 驱动程序的最新 Linux 发行版(RedHat Linux RHEL 7),SchedMD 的 Slurm 调度程序,DDN 的 Luster 并行文件系统以及 Intel 编译器。 此外,还将提供 PGI 和 AMD 编译器套件以及开发工具。
为了进行深入的性能分析和调试,可以使用 ARM Forge 产品。 该软件包包括并行调试器(DDT)和性能分析工具(MAP)。 还提供了 Lightweight Profiler Atos LWP)。 它提供全局和每个进程的统计信息。 LWP 附带了 Bull binding checker,允许用户确认他们正在使用的进程绑定是否符合预期。 这是一项重要功能,可通过大量内核,多核处理器和超线程来获得更好的 CPU 性能。
可以使用标准命令通过 Slurm 运行容器化软件。 Atos 提供了一个基于 Singularity 软件包的完整框架以及一个用于提交和记帐的 Slurm 插件,和一个帮助用户创建容器的工具。
表3 新 HPCF 的主要软件组件
| Component | Description |
|---|---|
| Operating system | Red Hat Enterprise Linux |
| Main compiler suite | Intel Parallel Studio XE Cluster Edition |
| Secondary compiler suites | PGI compilers and development tools / AMD AOCC compilers and development tools |
| Profiler / debug tool | ARM Forge Professional |
| Batch Scheduler | Slurm |
实施计划
在以前的 HPC 迁移中,项目负责交付系统和迁移应用程序,而这次工作与以前不同,项目被分为两部分。 这反映了以下事实:迁移是一个比平常大得多的项目,因为它涉及其他群集和网关系统以及新的交互式环境。 HPC 项目提供系统,而 BOND 程序中的迁移项目负责应用程序的迁移。 这两个项目预计将于 2021 年 9 月完成(图5)。
作为 HPC 服务合同的一部分,Atos 将提供一个位于 Shinfield Park 的全职应用程序支持分析师,以帮助用户和开发人员移植代码并充分利用该系统。 正在开发一个完整的培训计划,将在迁移过程中提供给用户和开发人员。
测试和早期迁移系统
为使移植和测试工作尽快开始,新菲尔德公园数据中心已安装了一个临时的 60 节点“测试和早期迁移系统”(TEMS)。 该系统自 2020 年 3 月中旬开始对用户可用,尽管可以运行的作业的大小和数量受到限制,但它可以移植和测试所有 ECMWF 库,实用程序和应用程序。
一旦新 HPCF 的第一个主要组件在博洛尼亚安装,雷丁系统将被拆除并运往意大利,其组件将在后来的集群中重复使用。 表 4 显示了初始 TEMS 系统的配置。 在此系统中,与主系统中不同,计算节点和 GPIL 节点具有相同的规格。 由于 GPIL 节点是冷气的,TEMS 可以安装在 ECMWF 的现有数据中心中,而无需进行昂贵的安装水冷却基础设施的工作。
由于系统配置相对较小,因此限制 ECMWF 应用程序迁移团队和通过邀请的成员国用户访问。 建议感兴趣的会员国用户通过服务台联系用户支持。
在合同期间,将在博洛尼亚安装一个较小的测试系统,以提供测试新软件和程序的平台。
验收流程
HPCF 的验收流程很复杂,包括一些测试,以确认系统的功能和性能是否符合 ECMWF 的期望和供应商的合同承诺,以及可靠性测试。 从以前的 HPC 迁移的经验中学到,实施时间表和验收测试程序可为安装和将应用程序迁移到新系统提供更多时间。
测试步骤为:
Factory Test
主系统的很大一部分构建在供应商工厂中。 ECMWF 运行为期 5 天的功能测试,以验证系统是否符合合同规定的性能和功能。 这为 ECMWF 提供了一个机会,可以在过程的早期发现任何问题。 在工厂进行测试期间,供应商将有很多人来查看和解决可能发现的任何问题。 如果系统通过了此测试,则可以将其运送到博洛尼亚数据中心。
Site Functional Test
在意大利安装完系统的大部分后,将进行功能测试,以确认它在装运后仍能正常工作,进行工厂无法执行的任何测试,并确定工厂测试发现的重要错误是否已解决。 该测试确定系统是否已准备好供用户访问。
User Acceptance Test
该测试是可靠性测试中的第一个。 要通过它,Atos 必须证明系统满足特定的可用性目标。 在此测试阶段,Atos 将逐步构建完整的最终系统,从一个集群到所有四个集群,并利用这段时间解决所有未解决的问题。 在此期间,将允许首次用户访问系统,而 BOND 项目将使用这段时间来迁移应用程序。 预计将在 2020 年底或 2021 年初实现用户访问。
Operational Test
操作测试包括两个部分:最终功能测试,它将验证系统是否完全确认所承诺的性能水平和功能规格;以及 30 天的运行可靠性测试,其中 Atos 必须证明该系统完全满足可用性和可靠性要求。 在此测试期间,预计 BOND 迁移项目将在实时测试中运行对时间要求严格的业务系统,以证明我们能够满足预测的交付计划。
Reliability Test
最后一项测试是系统可靠性和可用性的最终验证。 在此期间,ECMWF 将向外部用户分发测试数据,以便他们可以测试其工作流,并为将业务工作负载传输到新的 HPCF 做好准备。 在此期间,ECMWF 和会员国用户将负责移植剩余的科研工作负载。

图5 实施阶段时间表。时间可能会有所变化,具体取决于当前 COVID-19 大流行对 BOND 计划的可能影响。
表4 在雷丁安装的测试和早期迁移系统
| Component | Quantity | Description |
|---|---|---|
| Compute node | 40 | 2 x AMD ‘Rome’, 64 cores/socket, 512 GiB, 1 TB SSD |
| GPIL node | 20 | 2 x AMD ‘Rome’, 64 cores/socket, 512 GiB, 1 TB SSD |
| General purpose storage | 1 | NetApp E2800 storage device with 64 TB |
| High performance storage | 1 | DDN ES7990 EDR appliance with 450 TB |
| High performance networking | Mellanox InfiniBand HDR 200 Gb/s |
展望
从 2021 年起,新的 Atos Sequana HPCF 将在接下来的四年中支持 ECMWF 的业务和科研活动。
在以前的 HPC 采购中,计算需求是由合同期初 high-resolution forecast(HRES)的分辨率升级驱动的,随后是该阶段后期的其他预报改进。 这导致了一个分为两个阶段的实施方法:首先是进行具有足以执行 HRES 分辨率升级的性能的初始安装,然后是中期升级。
《2016-2025年战略》呼吁采取另一种方法,因为它着重于大幅提高集合预报(ENS)的分辨率。 从一开始,这需要在计算能力和容量方面进行重大改进,而不是两个较小的步骤。 预计在新的 HPCF 业务运行后不久实现将整体预报水平分辨率从目前的 18 km 升级到 9 km(或在任何情况下,将达到 10 km 左右,具体分辨率取决于将要进行的测试)。 因此,HPC2020 合同是为期四年的服务合同,没有合同规定的中期升级。
但是,HPC2020 合同包括 ECMWF 可以在合同期内增加其 HPC 资源的选项。 根据将来要达成的协议,ECMWF 可能会获得额外的资金来运行新服务,包括为额外的 HPC 需求提供资金。 这可能需要增强 HPC 设施并显着增加容量。 此外,为了使系统的配置与不断变化的要求保持一致,可以设想对系统进行潜在的较小的增强或调整。 这些可能包括通过添加更多的计算节点或存储基础架构来增强计算性能,或者引入其他硬件(例如通用 GPU)以支持使用最新的 HPC 和 AI 技术对 ECMWF 应用程序进行持续开发。
思考
HPC 上操作系统和应用软件会严重制约业务系统的发展,在气象局上一代 IBM HPC 上就有很明显的体现。 2018 年投入使用的新一代 HPC 派-曙光带来新全新的系统工具,使得我们业务系统建设有了极大的进步。
气象局将于今年开始启动新一代高性能计算机项目,代号是 “派-2020”(感兴趣的同行可以查询:气预函〔2019〕50号)。 期望新一代 HPC 能带来更大的变化。
以我个人在 HPC 上的工作经验来看,文章中提到的几个通用概念也适用于我们的 HPC 系统。 下面简要阐述一些不成熟的观点。
多集群
我们与 ECMWF 一样,都使用科研和业务两个集群。为了避免资源浪费,业务分区实际上也运行科研任务,科研分区也有业务系统运行。 正文中指出,ECMWF 的 HPC2020 将分区提升到 4 个,可以将某个分区中将软件升级进行测试,而不影响其余的业务系统。这一点我深有感触。
上一代 IBM HPC 从 2014 年开始运行,一直存在提交 LoadLeveler 作业失败的问题,直到去年,大部分业务系统迁移到派-曙光后,才升级 LoadLeveler 系统,就是因为不能确保升级后还能提供和之前一样的业务性能。 派-曙光上的工具库也很少有持续的更新。如果有测试系统,也许能改变现有的缓慢更新策略。
文件系统
我不了解文件系统,但从派-曙光的文件系统来看,小文件的读写效率确实不高。 模式积分需要 40 分钟,但打包压缩单个时次的 ecFlow 日志文件可能需要 20 分钟。 另外,业务系统出现多次文件拷贝后大小为 0 的问题,可能就与文件系统本身性能有关系。
随着未来模式分辨率提升,输出的文件会越来越大,磁盘 I/O 将成为一个关键制约因素。 ECMWF 考虑使用固态磁盘(SSD)来提升读写效率,不知道未来我们是否会采用类似的方案。
通用和交互节点
之前一直以为未来 HPC 中只会保留涉及并行的高性能计算,而类似串行作业会迁移到类似气象大数据云平台之类的其他计算资源中。 我们目前准备将业务数据推送给气象大数据云平台,并将部分产品制作和分发任务迁移到云平台上。
从本文看,ECMWF 显然不只这一条路线。 虽然 ECMWF 正在开发 European Weather Cloud 等云平台,但在新一代 HPC 中依然保留类似串行作业的在线交互分析任务,并且指出数据量增加后,不适合将大量数据移至其他平台计算。
另外,ECMWF 的下一代 HPC 中还提供 Singularity 用于容器开发,可以看到未来 HPC 上并不是只有模式研发一条道路可行,业务系统级工具依然有很大的开发潜力。 这对于目前正处在 HPC 与气象大数据云平台之间摇摆的我来说,很有参考价值。 虽然气象大数据云平台是未来可期,但毕竟现有的制约条件太多,缺乏深入研究的空间。
参考
原文
去年写的介绍 NWPC 高性能计算机的系列文章:
