Cloud-Ws 2021:格点数据的数据服务Gridefix
本文正文部分来自 ECMWF 于 2021 年 2 月召开的 Virtual workshop: Weather and climate in the cloud (Cloud-WS 2021) 中的如下演讲:
Data service for gridded data
Code name: Gridefix
by Philipp Falke, Matthieu Bernard, Gabriela Aznar
at Cloud-WS 2021
基于 zarr 和 xarray 面向强天气数据的数据服务
正文

图片来自幻灯片
简介
背景
当作者三年前入职时,天气数据的存储方式仅有文件。。。

图片来自幻灯片
格点数据库的最初原型
文件编目
支持 NWP 模式和卫星数据
基于 OPeNDAP API 对文件概念进行抽象
- 总是需要 2 个 API 调用:catalogue 和 dataset
- 数组的冗余切片
- 大量的即时处理
- 难以使用随机方式 (random manner) 访问数据
需求
图片来自幻灯片
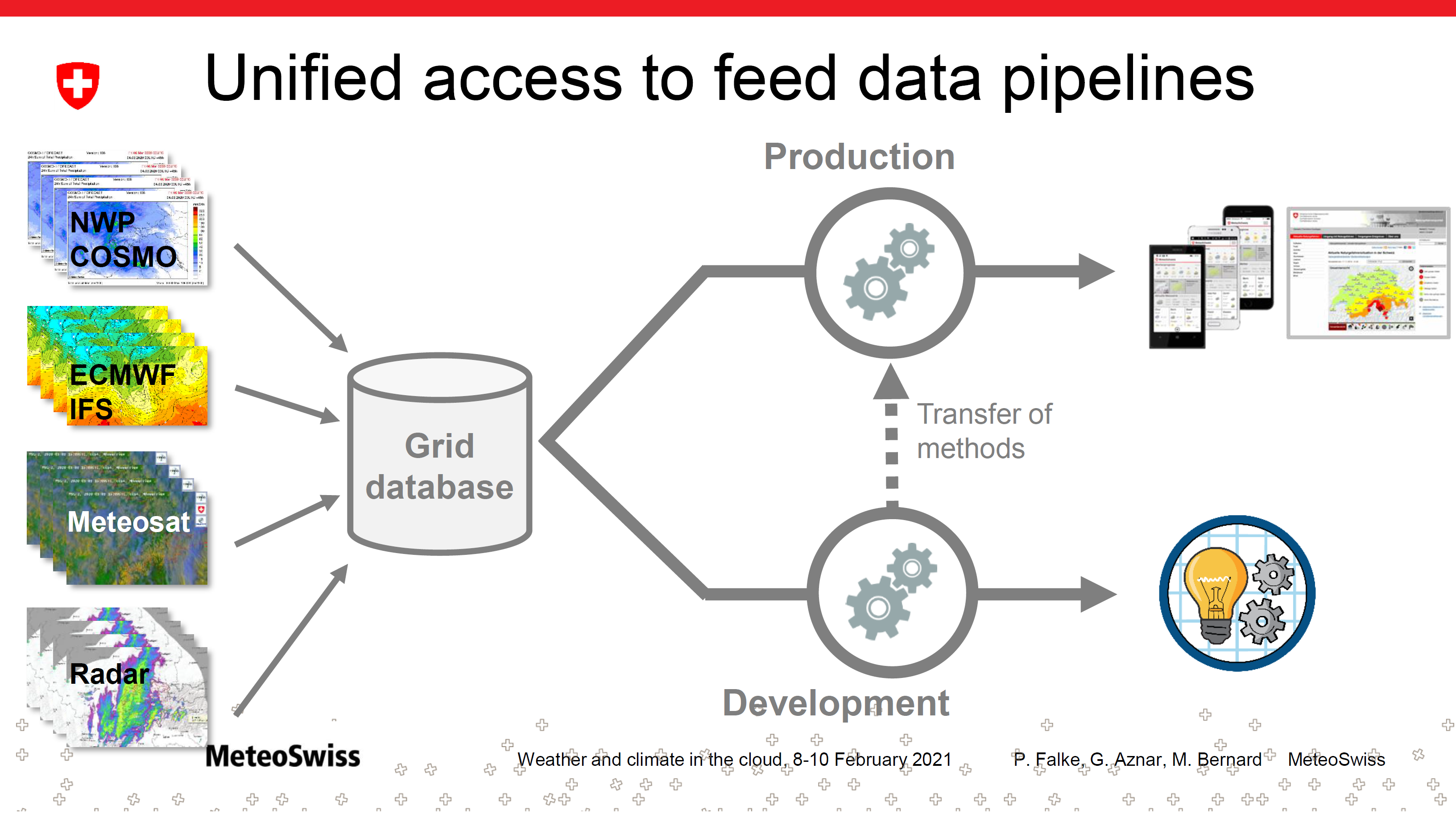
数据管道的统一访问
用途
两种主要使用场景
产品
- 数据的近实时可用性
- 滚动存档
- 发布格点数据
- 业务实时处理
研发
- 模式输出和其他格点数据的历史归档
- 后处理 (包括机器学习),检验,气候的开发和训练
满足以上两种场景的需求
- 存储多维数据 (reference time, lead time, members, levels, x, y)
- 导入异构数据
- 语言无关的数据访问
- 数据目录,用于查找正确的数据
- 数据的实时可用性
- 沿每个维度的数据访问都具有足够的性能
实现选择
灵感来自 2018 Workshop on developing Python frameworks for earth system sciences

图片来自幻灯片,缺少 Pangeo 图标
云原生
- 横向可扩展性
- 通过 APIs 提供服务
- 对象存储
导入 (import) 而不是 索引 (indexing)
架构
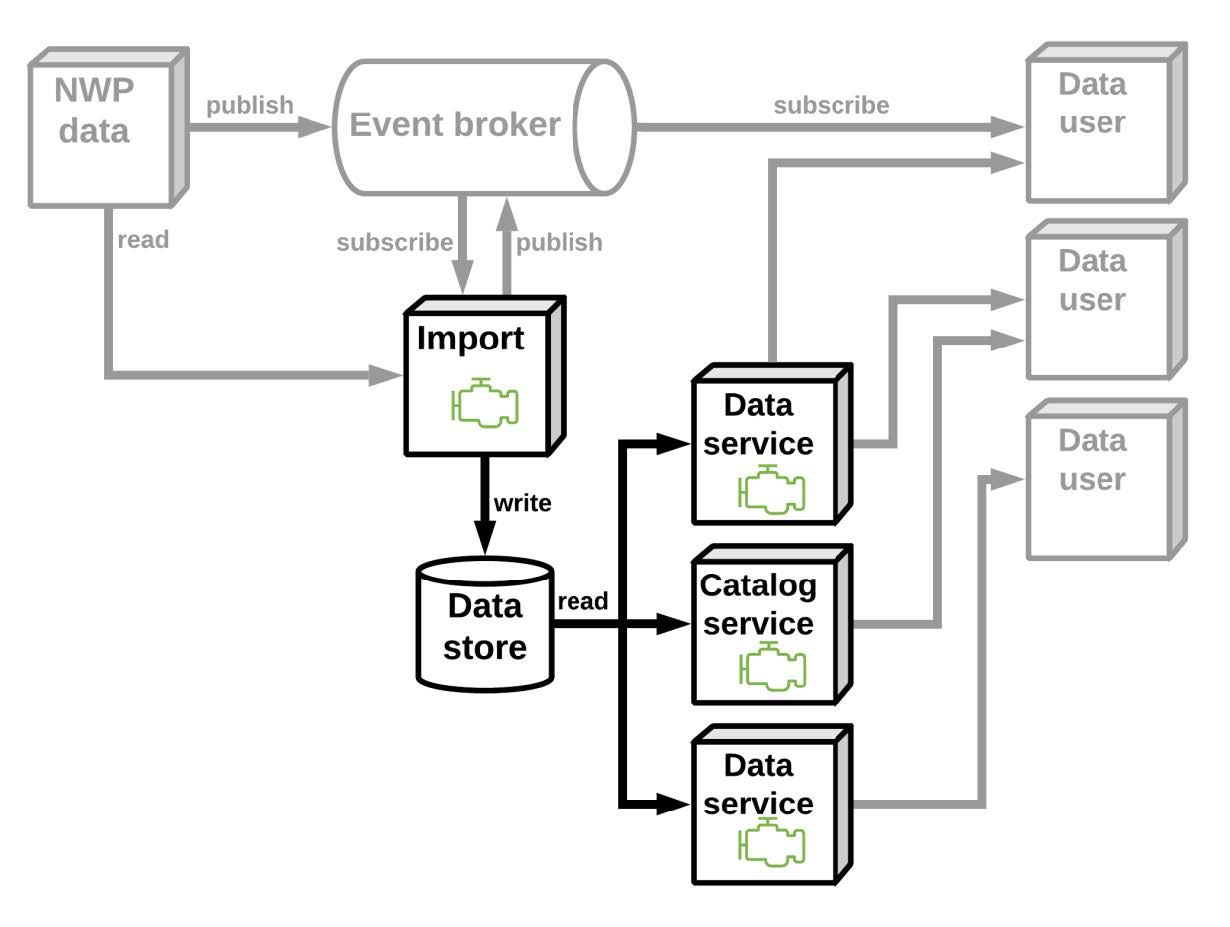
图片来自幻灯片
带符号的是通用数据访问层
不同的服务提供关于数据的不同视图
潜在的多种数据服务
基于消息的数据发布和订阅机制将在后续实现
数据访问层:gridefix-core
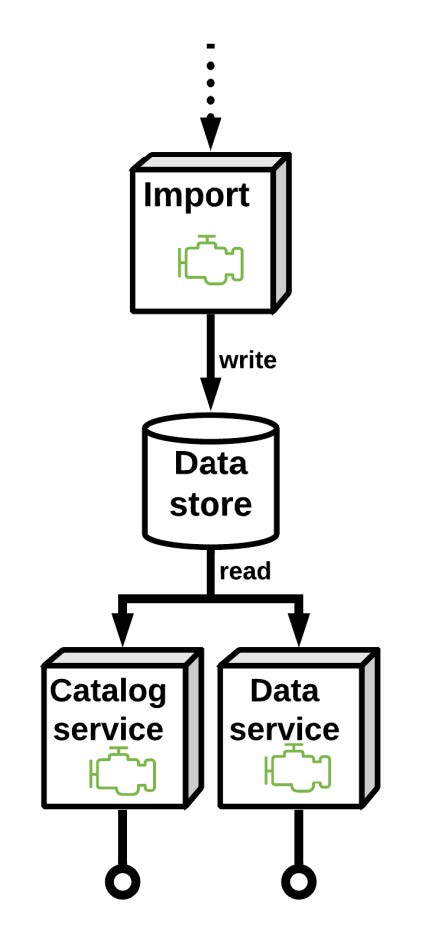
图片来自幻灯片
用于数据存储访问的抽象层
Python 库可实现与存储的高效交互
实现存储格式 (Zarr)
加强数据模型
将存储的数据公开为 xarray 数据集
使用 xarray 访问器
数据模型
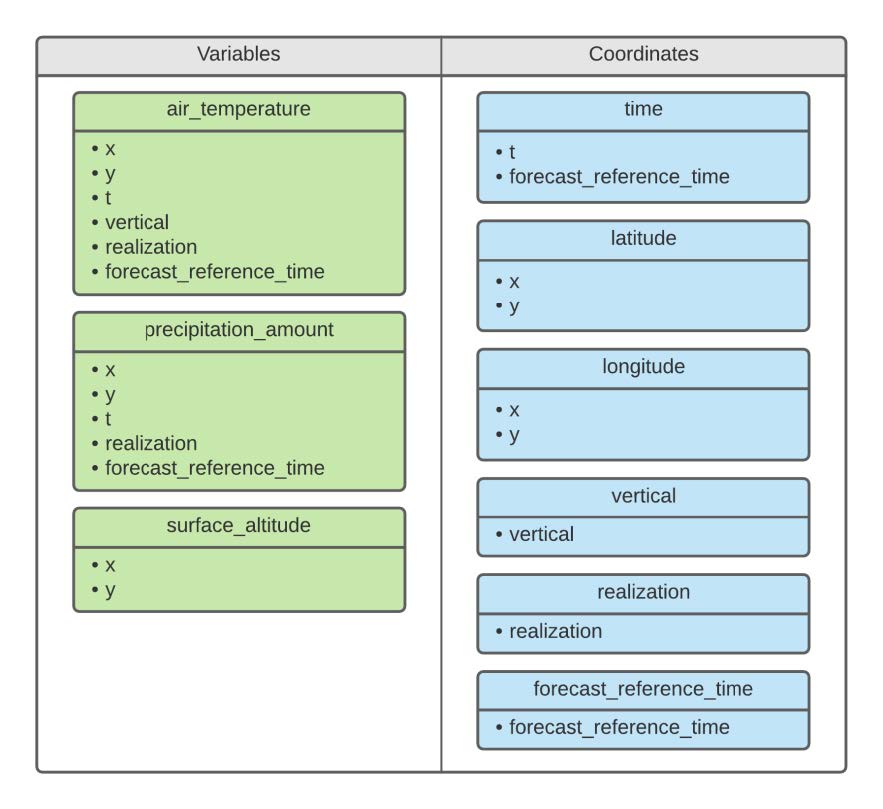
图片来自幻灯片
变量名符合 NetCDF CF Metadata Convention 规范
坐标保存到 latitude/longitude
可以在多种对象中设置属性,包括数组、变量、坐标、主时间轴等
数据集
name + tag
几乎没有层次关系:数据集可以被源名称 (例如模式名) 和一组唯一的标签 (例如业务预报、回算、分析、观测) 标识
定义两个概念:
- Array:包含多个变量的多维数组
- Dataset:可以包含多个数组,沿主时间轴合并,以避免存储/传输 NaN 块
存储格式
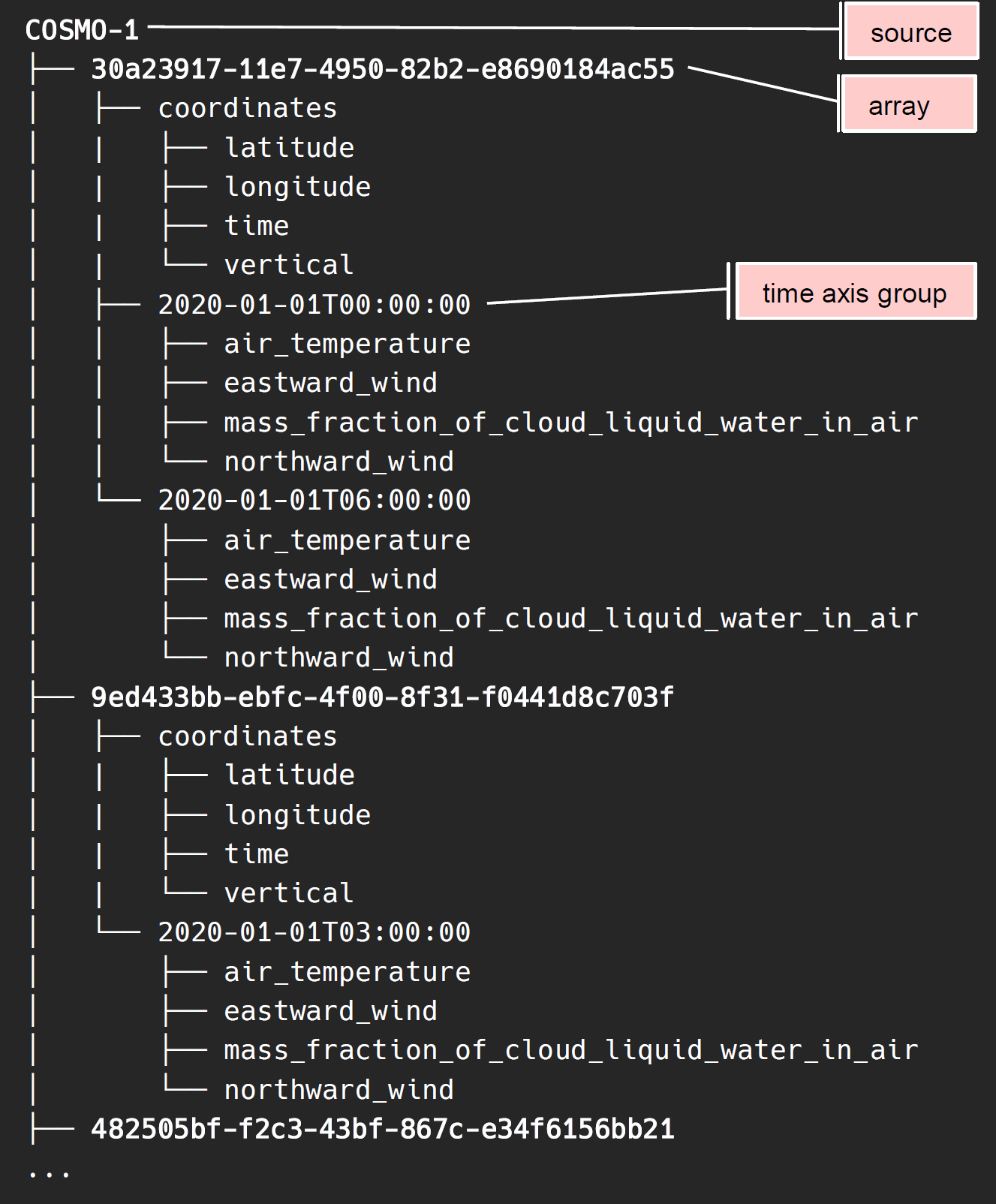
图片来自幻灯片
- 利用 zarr 和 dask
- 沿主时间轴滚动存档
- 相关层次结构级别上的属性
性能优化:
- MongoDB 或 Redis 保存 zarr 元数据
- 对象存储保存 zarr chunks
数据目录:gridefix-discover
编程方式获取所有元数据的高级接口
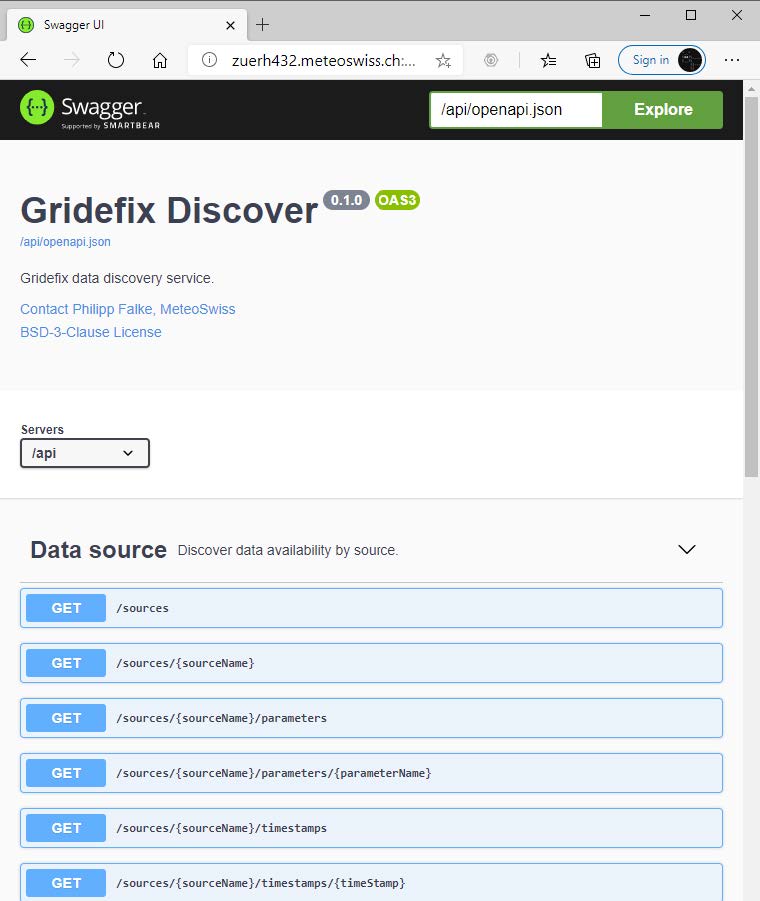
图片来自幻灯片
示例
curl "http://gride.fix/discover/api/sources"
[
"COSMO-1E",
"COSMO-2E",
"ECMWF_IFS",
"INCA"
]
❯ curl "http://gride.fix/discover/api/sources?parameter=air_temperature"
[
"COSMO-1E",
"COSMO-2E",
"ECMWF_IFS"
]
❯ curl "http://gride.fix/discover/api/sources?tags=nowcasting"
[
"INCA"
]
NetCDF:gridefix-retrieve
自己实现的 OPeNDAP
https://github.com/MeteoSwiss/opendap-protocol
依赖延迟加载准则:
- 按单个数据对象方式打开历史数据
- 通过 NetCDF 库实现切片
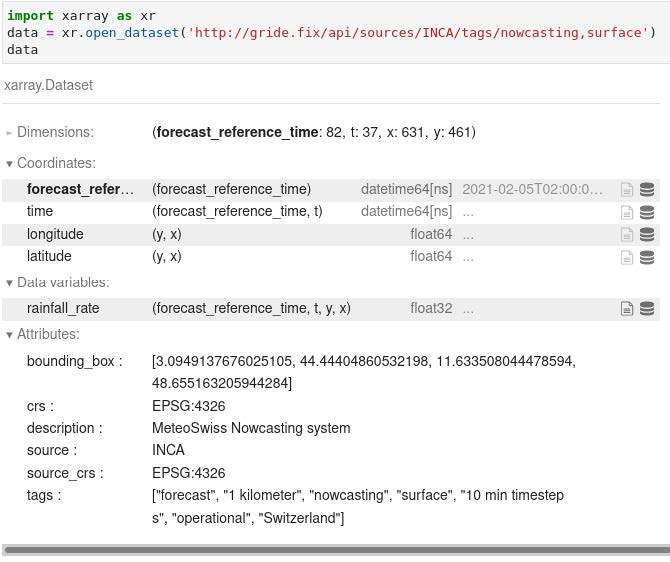
图片来自幻灯片
数据导入:gridefix-ingest
- 独立实体,用于导入各种数据
- 数据导入通常由数据提供者开发
- 支持大多数常见任务的帮助程序库
- 坐标处理
- 转换为目标数据模型
- 验证数据模型
- 验证 CF 兼容性
后续开发
AWS 上的概念验证开发:
- EKS:API 服务 (ingest, discover, retrieve)
- S3:对象存储
- DocumentDB:兼容 MongoDB
前提条件
- OpenShift 集群:API 服务 + 数据库
- Minio:对象存储
展望
技术
- 完成开发,包括事件部分
- 考虑其它序列化格式
- WMS
- Protocol Buffers
- 容纳不规则网格
非技术
- 发布为 OSS
- 用作 MeteoSwiss 格点数据的通用解决方案
- 在 EWC 上部署
讨论
关键点:
- 对数据进行修改
- 对象存储 + Zarr
- 使用 OPeNDAP 协议
- 支持 xarray
修改数据
在是否对元数据进行修改这一问题上,本文和 NWPC 有不同的选择。
导入数据
本文选择按照特定的准则修改、重组数据,类似 CMIP6 对数据的一系列要求。
优势:
- 使用同一套元信息描述不同来源的数据,屏蔽不同数据文件在要素场描述上的差异
- 更灵活地选用适合需求的数据存储格式
劣势:
- 需要单独设计工作流
- 处理后的数据占用额外空间
- 如果不保留原始数据,需要调整后端应用,对接数据平台 API 接口
索引数据
NWPC 的数据平台保存原始数据的索引,根据索引从原始数据中直接读取要素场。
优势:
- 实现简单
- 存储需求小,索引仅占少量空间
- 保留原始数据,现有后端应用依然可用
劣势:
- 访问效率依赖文件系统 (虽然可以用缓存)
- 对于 GRIB2 数据,单次请求必须要加载整个要素场
- 不同数据源的索引内容可能不完全一致
NWPC 现有的数据处理、绘图脚本大多与模式 GRIB2 文件紧耦合,所以必须要保留原始文件。 同时 NWPC 缺乏足够的存储资源,也就无法保存处理后的数据。 因此,NWPC 目前选择以数据索引的形式构建数据平台。
不过,我觉得未来如果有机会能利用气象大数据云平台提供的基础设施进行开发,还是应该尝试数据导入的方式,尤其要选择有利于分布式处理的数据存储方案。
存储格式
zarr 支持将数据分块保存为压缩格式,非常值得研究,适合将数据保存到云平台的对象存储中。
访问协议
NWPC 主要使用 POSIX 协议和 FTP 协议获取和访问数据,数据处理和绘图脚本大多对接磁盘文件。 需要注意到,越来越多的数据源支持 HTTP 协议。 比如气象大数据云平台的 MUSIC 接口使用 HTTP 协议,ECMWF 的数据平台也提供 HTTP API 接口,本文使用 OPeNDAP 协议同样基于 HTTP 协议。 所以,设计数据平台的访问接口时,需要考虑如何以 HTTP API 的方式提供服务。
Python 工具栈
Python 科学工具栈已在多领域广泛应用,xarray 非常适合保存格点数据。 即便 HPC 上的 xarray 版本比较早,不支持插值等功能,也不能放弃对 xarray 的研究和应用。 我在开发数据工具时,应该尽量利用 xarray、pandas 等通用库提供的数据类型,而不要设计新的数据结构。
参考
Virtual workshop: Weather and climate in the cloud
Data service for weather data based on zarr and xarray
幻灯片:https://events.ecmwf.int/event/211/contributions/1868/attachments/986/1734/Cloud-WS_Falke.pdf
视频:https://vimeo.com/510830697