Meteva笔记:计算站点降水的检验指标 - 列联表
Meteva 是由 nmc 开源的全流程检验程序库,提供了常用的各种气象预报检验评估的算法函数,气象检验分析的图片和表格型产品的制作函数,以及检验评估系统示例。
本文以 24 小时累积降水为例,说明如何根据站点观测计算二分类预报的列联表,为后续计算检验指标提供基础数据。 同时会介绍如何使用 Meteva 根据站点观测表格数据计算列联表。
准备
载入需要使用的库
import numpy as np
import pandas as pd
import xarray as xr
import geopandas as gpd
from shapely.geometry import Polygon
import matplotlib.pyplot as plt
import pathlib
from nwpc_data.grib.eccodes import load_field_from_file
from nwpc_data.data_finder import find_local_file参数
区域范围,仅计算区域内的观测
domain = [20, 55, 70, 145]降水阈值,单位为 mm。为每个阈值分别计算列联表
thresholds = [0.1, 1, 5, 10, 25, 50, 100]观测时刻,2020 年 8 月 1 日 00 时次
current_date = pd.to_datetime("2020-08-01 00:00:00")选择 12 时次预报
current_start_hour = pd.Timedelta(hours=12)数据目录
forecast_root = "/g2/nwp_vfy/operation/EC"数据
观测数据
使用《Meteva笔记:加载本地观测数据》中介绍的观测数据。 nwpc-data 库已内置该数据的路径。
站点观测数据路径
obs_file_path = find_local_file(
"muvos/obs/gts",
start_time=current_date,
data_class="vfy",
)
obs_file_pathPosixPath('/g2/nwp_vfy/MUVOS/obs/station/GTS/202008/gts2020080100.txt')
载入站点观测资料数据
from nwpc_data_tool.verify.data.obs import load_obs_gts_file
df = load_obs_gts_file(obs_file_path)
df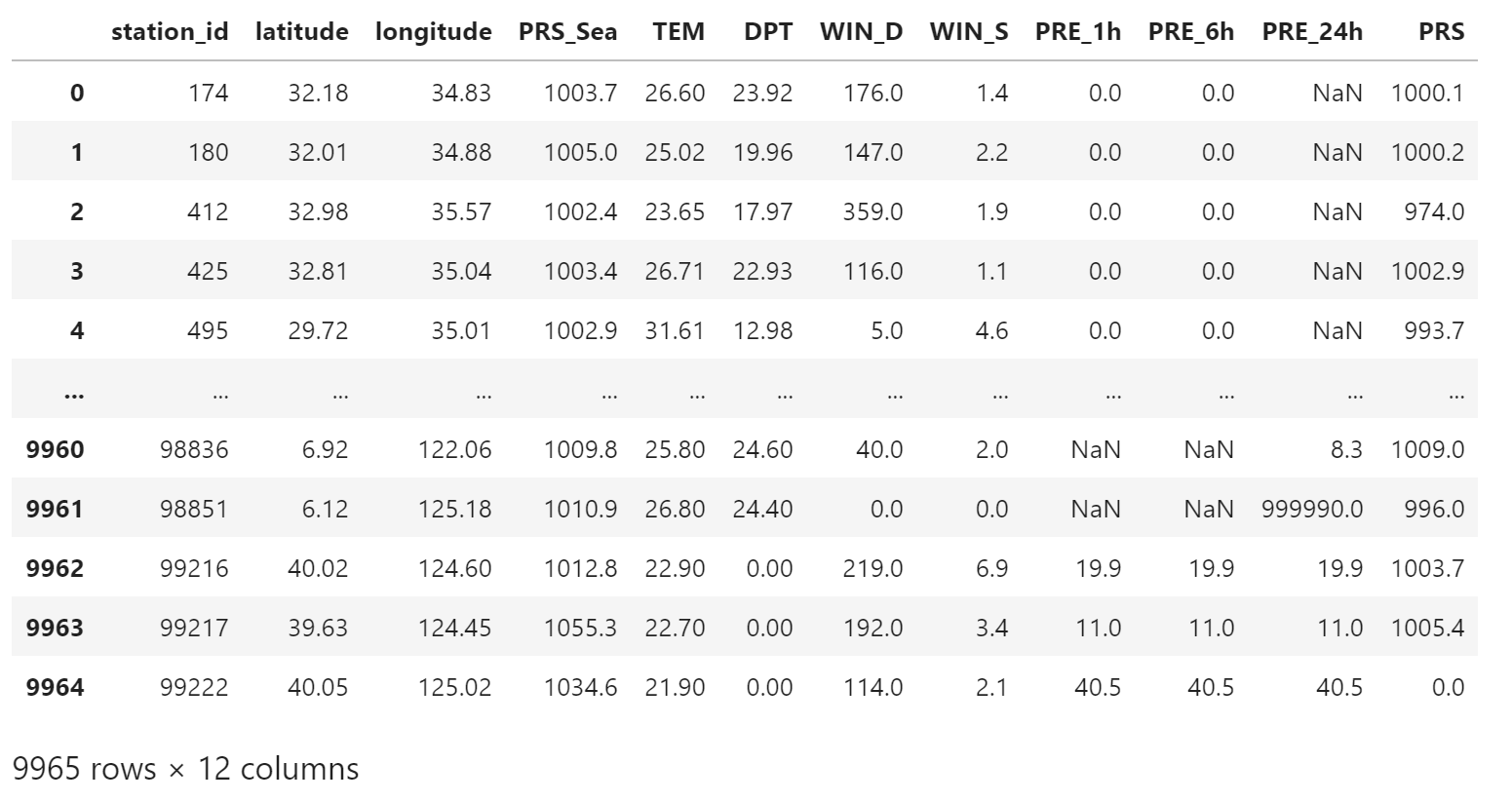
提取需要的列,重命名,并删掉有缺失值的行
obs_table = df[["latitude", "longitude", "PRE_24h", "station_id"]]
obs_table = obs_table.rename(columns={"PRE_24h": "rain_24"})
obs_table = obs_table.dropna()
obs_table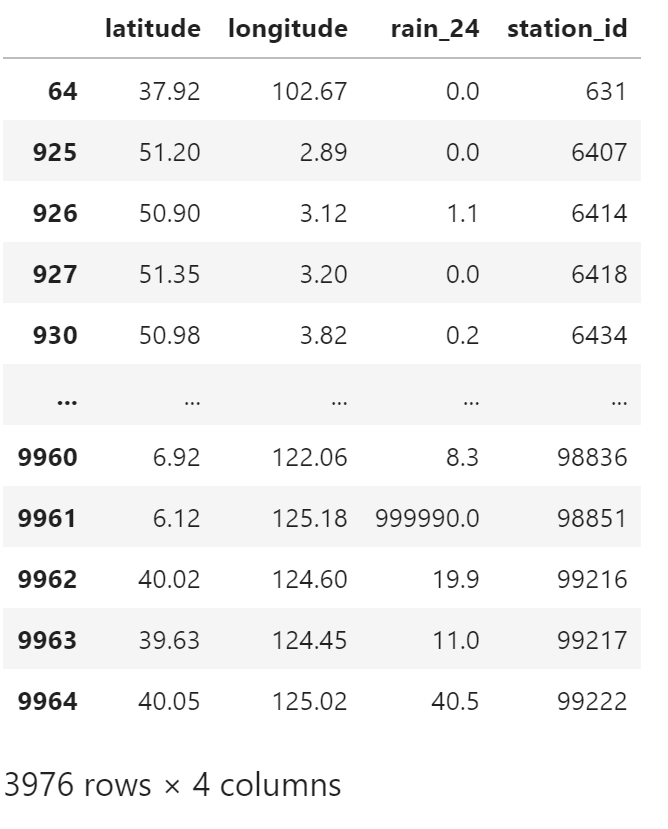
因数据中有其它异常值,需要再次过滤
obs_table = obs_table[obs_table["rain_24"] < 99999.0]
obs_table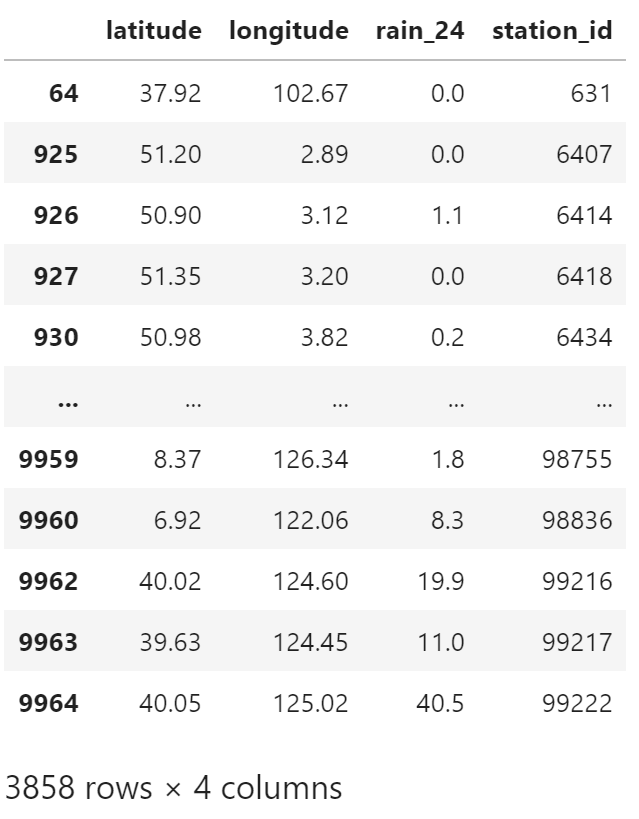
陆地掩码文件
掩码文件路径
mask_file_path = "/base/run_grapes/landmask.grib"载入掩码场
mask_field = load_field_from_file(
mask_file_path,
)
mask_field.attrs["long_name"] = "landmask"按区域范围绘制
mask_field.sel(
latitude=slice(20, 55),
longitude=slice(70, 145)
).plot(
figsize=(10, 5)
)
plt.show()
预报数据
下图说明预报场与观测场之间的关系,本文仅检验 00 点的 24 小时累积降水。
为了与 00 点对齐,12 时次第一个检验的时效是 036,036 的 24 小时降水由 036 - 012 计算得出。
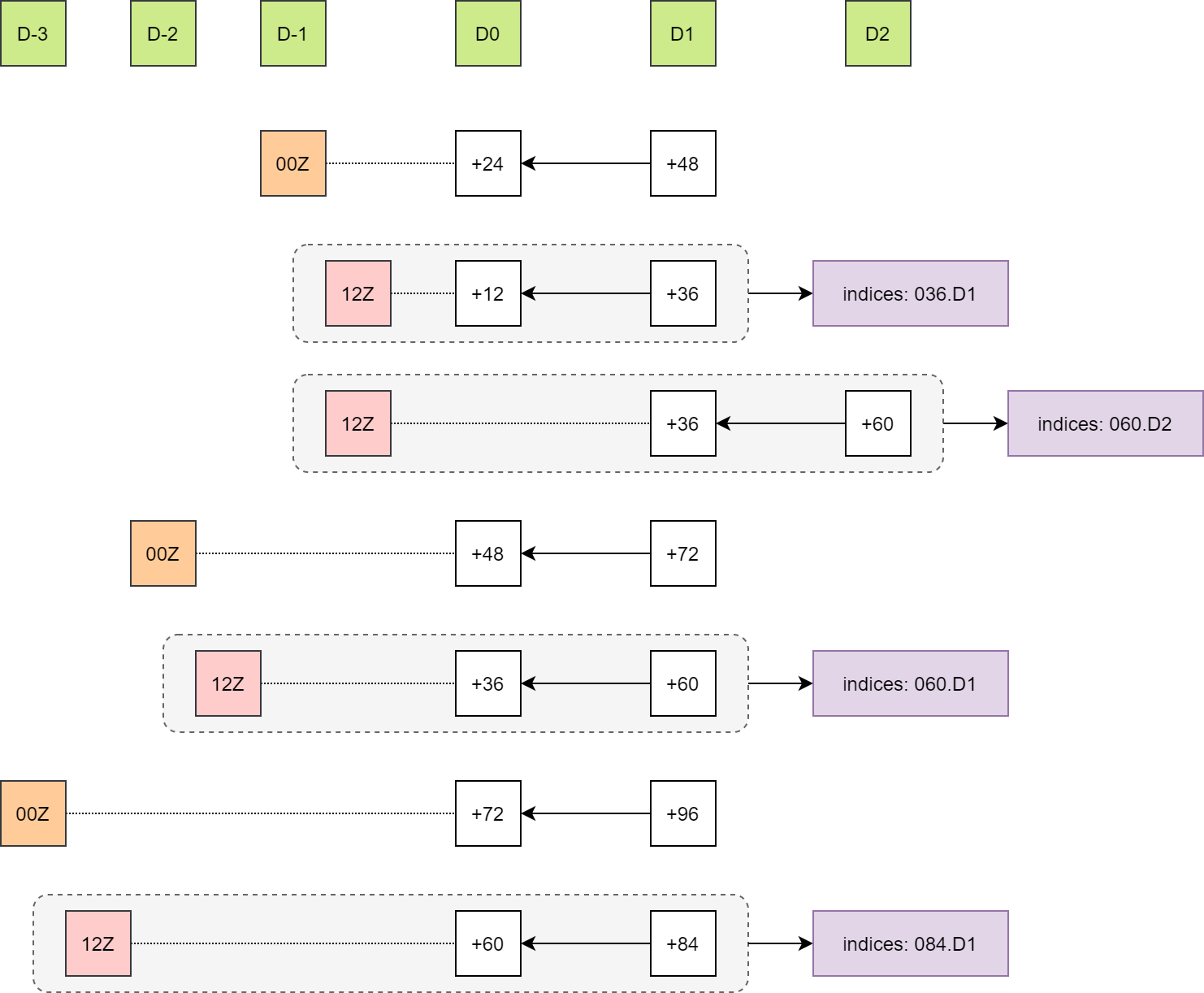
对于 current_date 时刻 current_forecast_hour 时效预报所对应的起报时间
step_start_time = current_date - current_forecast_hour
step_start_timeTimestamp('2020-07-30 12:00:00')
即 036 时效是 2020-08-01 00 时次对应的起报时次是 2020-07-30 12 时次
加载 036 时效数据
forecast_036_path = pathlib.Path(
forecast_root,
f"rain{int(current_forecast_hour / pd.Timedelta(hours=1)):03d}.grapes.{step_start_time.strftime('%Y%m%d%H')}"
)
forecast_036_pathPosixPath('/g2/nwp_vfy/operation/EC/rain036.grapes.2020073012')
!grib_ls {forecast_036_path}/g2/nwp_vfy/operation/EC/rain036.grapes.2020073012
edition centre typeOfLevel level dataDate stepRange shortName packingType gridType
1 kwbc surface 0 20200730 36 tp grid_simple regular_ll
1 of 1 messages in /g2/nwp_vfy/operation/EC/rain036.grapes.2020073012
1 of 1 total messages in 1 files
field_036 = load_field_from_file(
forecast_036_path
)加载 current_forecast_hour - 24 时效的数据,用于计算 24 小时累计降水
start_forecast_hour = current_forecast_hour - pd.Timedelta(hours=24)
forecast_012_path = pathlib.Path(
forecast_root,
f"rain{int(start_forecast_hour / pd.Timedelta(hours=1)):03d}.grapes.{step_start_time.strftime('%Y%m%d%H')}"
)
forecast_012_pathPosixPath('/g2/nwp_vfy/operation/EC/rain012.grapes.2020073012')
field_012 = load_field_from_file(
forecast_012_path
)计算降水
field_rain = field_036 - field_012
field_rain
使用掩码处理
field_rain = field_rain.where(
mask_field == 1
)
field_rain.sel(
latitude=slice(20, 55),
longitude=slice(70, 145)
).plot(
figsize=(15, 8),
)
plt.show()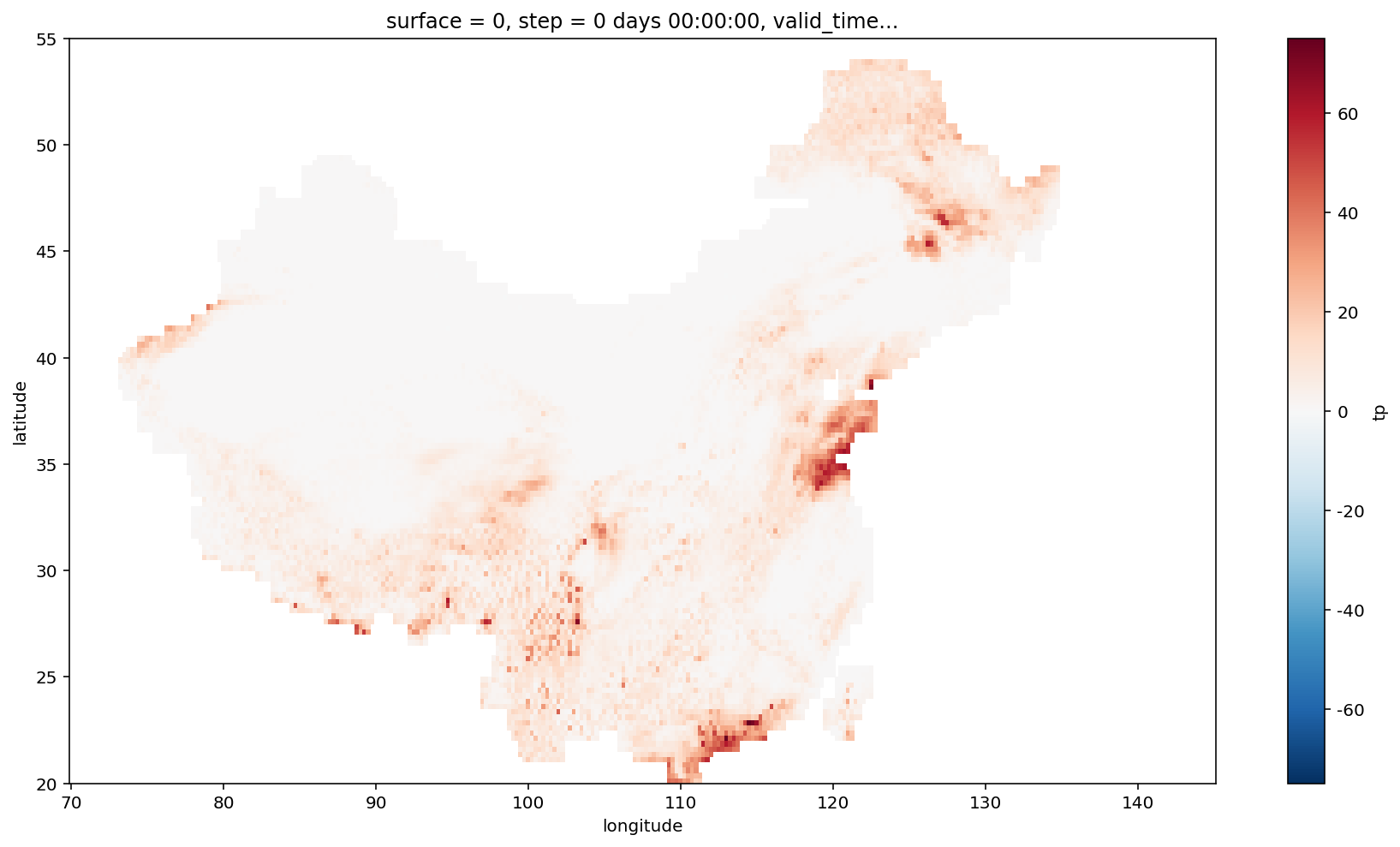
处理
提取 domain 区域范围内的站点观测数据
geo_obs_table = gpd.GeoDataFrame(
obs_table,
geometry=gpd.points_from_xy(
obs_table.longitude,
obs_table.latitude
)
)
polygen = Polygon([
(70, 20),
(70, 55),
(145, 55),
(145, 20),
])
area_rain_obs = geo_obs_table[geo_obs_table.intersects(polygen)].copy()
area_rain_obs
获取预报场中站点的最近邻点
def get_forecast(row):
value = field_rain.sel(
longitude=row["longitude"],
latitude=row["latitude"],
method="nearest"
).item()
return value
area_rain_obs["forecast"] = area_rain_obs.apply(
get_forecast,
axis="columns"
)
area_rain_obs
因为使用掩码过滤预报场,所以站点的最近邻点可能是缺失值
df_area = area_rain_obs.dropna()
df_area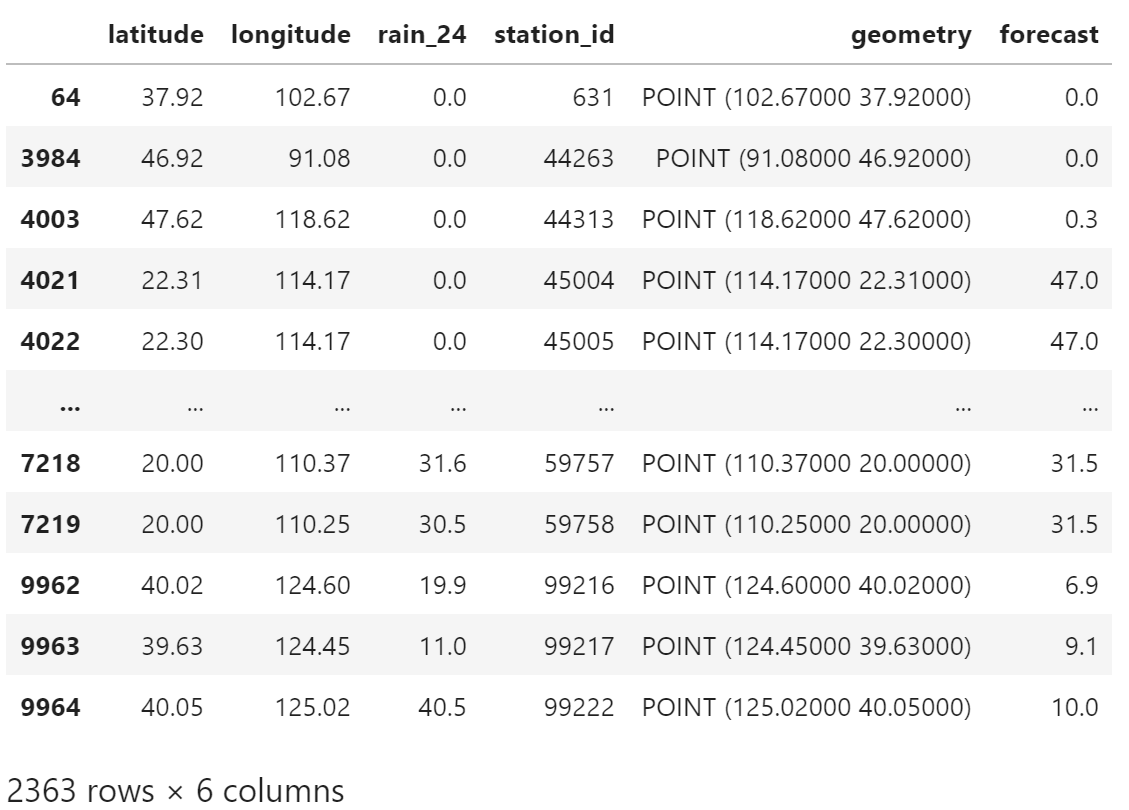
计算列联表
对于列联表,Meteva 的文档 有无预报检验 - 数值型检验指标 给出很好的说明。
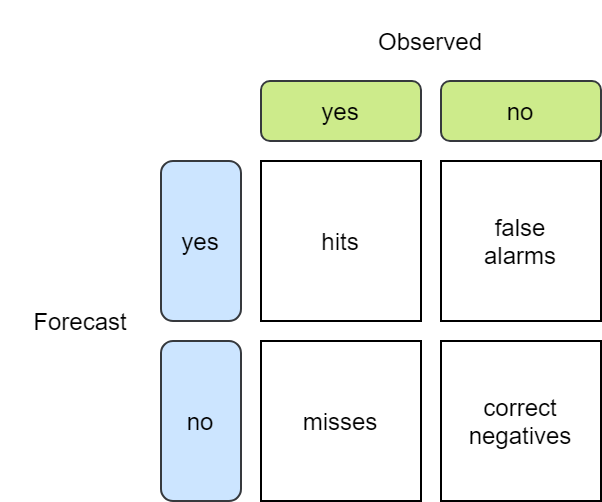
给定观测、预报和阈值,计算列联表四个元素的值
def calculate_matrix(obs, forecast, threshold):
hits = 0
false_alarms = 0
misses = 0
correct_negatives = 0
if forecast >= threshold and obs >= threshold:
hits = 1
elif forecast >= threshold and 0 <= obs <= threshold:
false_alarms = 1
elif 0 <= forecast <= threshold and obs >= threshold:
misses = 1
elif 0 <= forecast <= threshold and 0 <= obs <= threshold:
correct_negatives = 1
return (hits, false_alarms, misses, correct_negatives)计算 0.1 mm 阈值的列联表
threshold = 0.1
matrix_values_0p1 = [
calculate_matrix(
obs,
forecast,
threshold=threshold,
)
for (
obs,
forecast
)
in zip(
df_area["rain_24"],
df_area["forecast"]
)
]
matrix = np.array(matrix_values_0p1)
matrixarray([[0, 0, 0, 1],
[0, 0, 0, 1],
[0, 1, 0, 0],
...,
[1, 0, 0, 0],
[1, 0, 0, 0],
[1, 0, 0, 0]])
matrix.sum(axis=0)array([1108, 962, 24, 267])
计算所有阈值的列联表
rows = []
for threshold in thresholds:
matrix_values_0p1 = [
calculate_matrix(
obs,
forecast,
threshold=threshold,
)
for (
obs,
forecast
)
in zip(
df_area["rain_24"],
df_area["forecast"]
)
]
matrix = np.array(matrix_values_0p1)
row = matrix.sum(axis=0)
rows.append(row)df_matrix = pd.DataFrame(
rows,
columns=[
"hits",
"false_alarms",
"misses",
"correct_negatives",
],
)
df_matrix["threshold"] = thresholds计算结果
df_matrix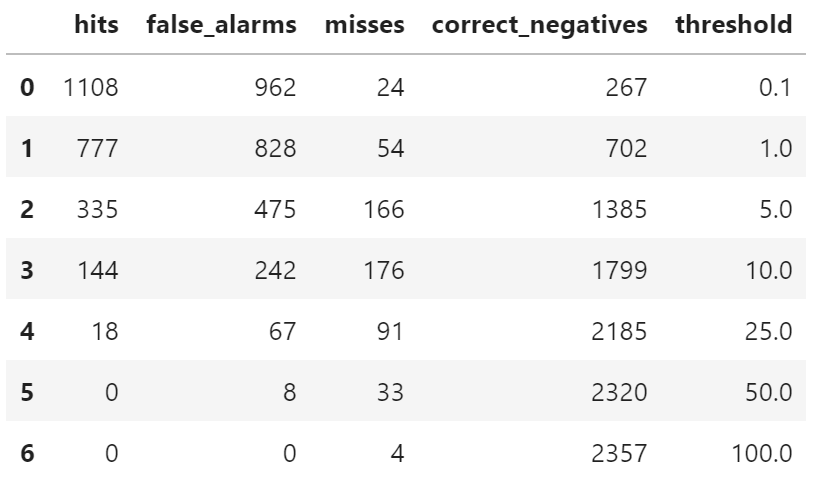
统计样本个数
df_matrix[["hits", "false_alarms", "misses", "correct_negatives"]].sum(axis="columns")0 2361
1 2361
2 2361
3 2361
4 2361
5 2361
6 2361
dtype: int64
与 df_area 的行数 (2363) 不一致,因为 df_area 中有两行观测数据小于 0,在计算中被忽略。
注:笔者不清楚为什么会有负数出现。
df_area[df_area["forecast"] < 0.0]
Meteva 计算列联表
数据:观测 + 预报
使用 meteva.method.contingency_table_yesorno() 计算多个阈值的列联表
Mateva 返回的列联表如下图所示:
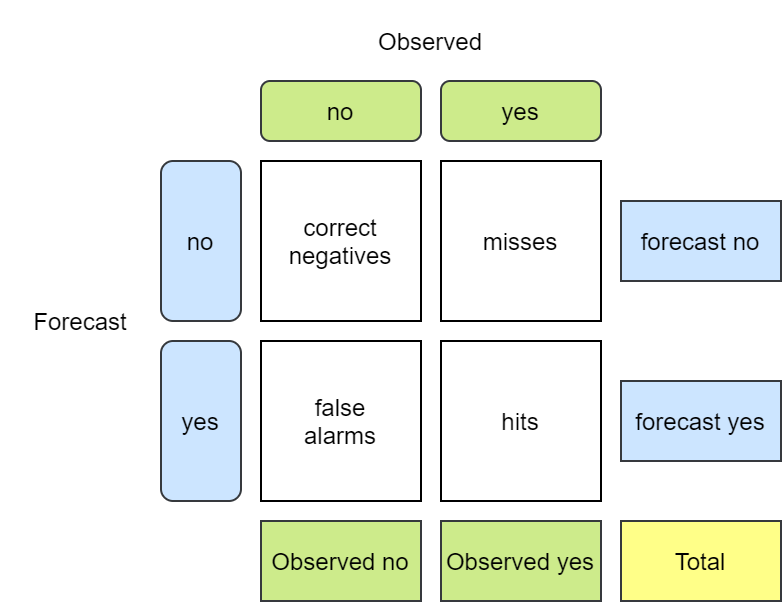
import meteva.method as mem
hfmcs = mem.contingency_table_yesorno(
ob=df_area.rain_24.values,
fo=df_area.forecast.values,
grade_list=thresholds
)
hfmcsarray([[[ 269, 24, 293],
[ 962, 1108, 2070],
[1231, 1132, 2363]],
[[ 704, 54, 758],
[ 828, 777, 1605],
[1532, 831, 2363]],
[[1387, 166, 1553],
[ 475, 335, 810],
[1862, 501, 2363]],
[[1801, 176, 1977],
[ 242, 144, 386],
[2043, 320, 2363]],
[[2187, 91, 2278],
[ 67, 18, 85],
[2254, 109, 2363]],
[[2322, 33, 2355],
[ 8, 0, 8],
[2330, 33, 2363]],
[[2359, 4, 2363],
[ 0, 0, 0],
[2359, 4, 2363]]])
对比 df_matrix 的结果,可以发现,hfmcs 中所有的 correct negatives 都少 2。
这是因为有两个站点计算的降水量是负值,在 calculate_matrix() 函数中被过滤掉。
如果统计有负值的数据,则结果会与 Meteva 保持一致。
参考
https://www.cawcr.gov.au/projects/verification/
模式检验系列文章