2022年第一季度工作总结
上季度工作总结中的豪情没能延续到第一季度,只剩下“雄关漫道真如铁”,而没有了“而今迈步从头越”。
部门两个科之间的分裂愈演愈烈,在部门领导人选上的分歧又看起来不可调和,整个部门弥漫在一种前途未卜的气氛中。 无论是处室内部的沟通理解还是中心对处室的信任都没能看到鼓舞人心的变化,有一种滑向恶性循环的趋势。 从非官方渠道了解的信息可以明显看到,运行团队的核心诉求和中心对处室的要求存在一定错位,我认为核心原因不在于对相关工作的不了解,也不在于沟通不到位,而是我们确实没有一项核心技术在手。 过往的工作成绩中没有一项成果可以强有力地支撑中心的研发工作,导致中心对运行团队存在质疑,认为我们只是在做业务运维工作,也只能做业务运维工作,很难去支持团队核心诉求。 当然这只是我个人的不负责任分析,部门和团队工作不属于这篇工作总结的内容。
至于我个人的问题就更突出了。 我依然没能克服自己专注度不够的问题,频繁切换工作方向,没能找到可以持续深入研究的一项工作内容。 不是将精力分散到没有产出的各类任务中,就是在纠结自己究竟该进行哪项工作。 工作计划绝对不能太多,要主次分明,明确自己的主攻方向,并持续开展研发工作,遇到困难不要退缩,要有自己能趟出一条路的坚定信念。 另外,在单位内部风云变幻的特殊时期,更要保持对自己的信心,无论对过去的工作成绩、现在的工作任务和未来的工作方向,都不要因为这样或那样的质疑而轻易否定自己。 不管中心对部门有何观感,自己的路还需要自己走下去,未来的方向也必须靠自己去探索。
计划完成情况
第一季度再次证明我做的计划没有任何计划性可言,绝大部分任务连看都没看,少部分有所进展的工作也没有连贯性,缺乏完整而连续的规划,仅完成了 1-2 项工作。
- 青年基金课题
- 🚧 完善示例,对比运行效率
- ❌ 技术文档
- ❌ 并行计算技术
- 模式要素库
- 调研:✔️ cfgrib 索引,❌ FDB 索引
- ❌ 元数据
- 🚧 本地文件索引
- 🚧 索引读取接口原型
- 产品制作融入天擎
- 🚧 数据准备工作
- ❌ 部署绘图算法
- ❌ 流程测试
- 后处理系统流程
- ❌ 优化运行脚本,统一编码风格
- ❌ 通用框架
- 数据准备工具库 reki
- ❌ 文档
- ❌ 测试用例
- 🚧 完善 CMADaaS 数据检索库 nuwe-cmadaas-python,设计多重配置文件,实现常用检索功能
- 🚧 GRIB 2 数据索引,❌ 与模式要素库结合
- ❌ 更多数据处理操作
- 工作流软件 takler
- ✔️ 重启 takler 开发
- 🚧 Python 实现
- 🚧 简单顺序流程
- 绘图封装工具库 sokort
- ✔️ 替换 WMC 绘图
- ❌ Singularity 镜像
- 数据检查工具 nwpc-data-client
- ❌ 并发检测拷贝,串行修改数据进度
- 绘图包 meda
- ❌ 设计绘图 API 接口
- ❌ 支持中国分区域图片
- ❌ 绘制部分业务系统图形
工作
业务系统
冬奥保障
第一季度最重要的工作就是 2022 北京冬奥会保障服务,部门承担数值天气预报业务系统的值班值守任务。 中心要求值班员在包含春节假期在内的特殊保障时期必须值班值守,也就是夜间值班需要待在单位大院内。 虽然不需要像以往特殊保障时期那样夜间必须待在值班室,但这也是我参加工作以来参与的最长时间的特殊保障值班任务了。 这项任务直接促使科级部门在 3 月对值班值守方案、系统升级办法展开热烈而充分的讨论,逐步形成共识,将在第二季度形成正式发布的文件。
冬奥保障期间我对系统进行两次大规模升级:
CMA-TYM 使用 CMA-GFS 模式面驱动
1 月份 NCEP GFS 资料缺失时 CMA-TYM 切换 CMA-GFS 等压面驱动发现模式积分无法运行。 经研发部门紧急开发,将背景场替换为 CMA-GFS 模式面。 使用模式面数据的流程需要跳过部分模块,并且需要替换初始化和模式积分模块使用的可执行程序。 因此,我使用采用标识文件的方式在 ecFlow 中模拟分支流程。
详情请参看《CEMC笔记:CMA-TYM中使用CMA-GFS模式面数据驱动的流程改造》
CMA-MESO 1KM 加密输出
冬奥保障期间中心响应 NMC 需求,紧急加密 CMA-MESO 1KM 输出,并增加额外变量层次,制作相应产品。 加密输出时效范围是 3 - 9 小时逐 10 分钟。
紧急任务往往没有足够的时间去雕琢实施细节,大多采用最容易实现的方案,当然也就没法应对各类异常情况。 所有加密输出的产品制作任务使用一个触发器,10 小时数据生成后同时提交所有加密输出产品任务。 批量任务定义使用如下代码所示的方法定义时间变量:
for hour in range(3, 10):
for minute in range(0, 60, 10):
if hour == 9 and minute > 0:
continue
# ...skip...
CMA-MESO 1KM 产品后处理系统新增任务的 ecFlow 截图如下所示:
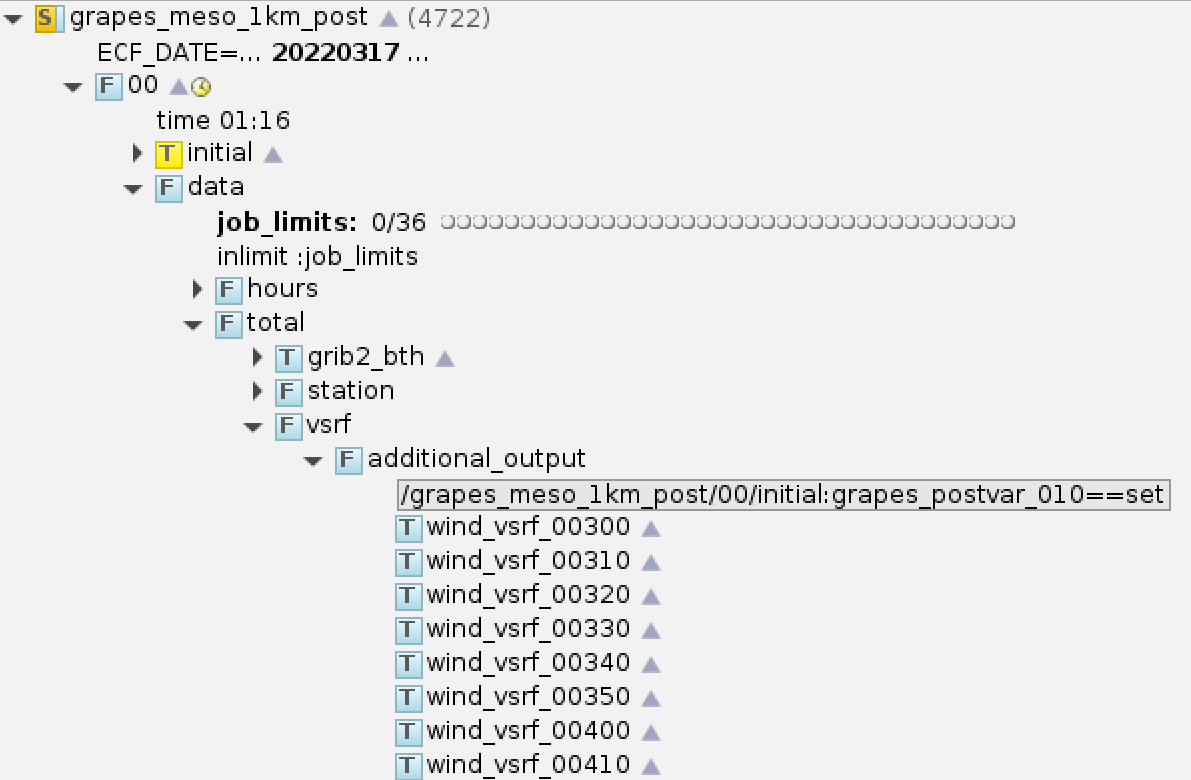
CMA-MESO 1KM 加密输出产品 ecFlow 任务示意图
MESO 站点绘图
CMA-MESO 绘制站点图片的任务使用单一脚本 (All.csh) 绘制所有图片,单个时次绘图耗时 1 小时左右。
如果文件系统 IO 速度有波动,任务执行时间可能会增加到 2 - 3 个小时。
第一季度对这个脚本进行拆分,为每个站点都单独配置一个任务,并发绘图,将站点绘图耗时从 1 小时降低到 10 分钟以内。
这是用计算资源换取运行效率的典型方案,使用大量串行节点 CPU 核心并发执行绘图任务,来降低总体任务运行时间。
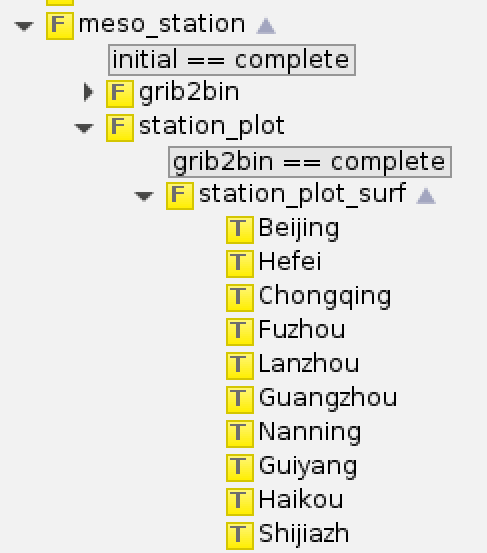
CMA-MESO 后处理系统站点绘图 ecFlow 任务示意图
拆分脚本并不复杂,站点绘图脚本运行慢的问题也不是最近突然出现的,可我直到现在才最终完成这项早就该做的工作。 我往往不愿意动 ecFlow 任务脚本中的子脚本,尽量简化自己的工作量。 可是一旦子脚本没人维护,就一定会成为未来的瓶颈。 未来应该更明确自己的职责,认真对待已发现的故障和故障隐患点,持续优化业务系统运行流程相关的所有组件。
WMC 绘图使用 sokort
第一季度将 sokort 应用在 WMC 网站相关的两个绘图系统 swfdp 和 globalchartos 中。 这是我负责的产品后处理系统中最后两个使用 sokort 的系统,为后续迁移到 CMADaaS 做准备。 自此,sokort 的开发已阶段性结束,集成绘图脚本的方案不会进行大规模调整。
当前中心在产品方面的改革尚未落地,不清楚未来会有何种变化,因此第二季度暂缓产品后处理系统流程构建方面的相关工作。 如果产品改革最终落地,可以考虑就以下方面开展合作研发:
- 适用于产品后处理的通用运行框架
- 基于 Python 的绘图工具包
- 模式要素库
项目
信息化工程
第一季度继续缓慢推进信息化工程项目的建设。 协助 NMIC 开始构建模式数据集,正在调整 CMADaaS 中模式业务数据的目录结构。 根据与 NMIC 的沟通交流,调整了去年底绘制的产品后处理系统融入方案示意图,如下所示:
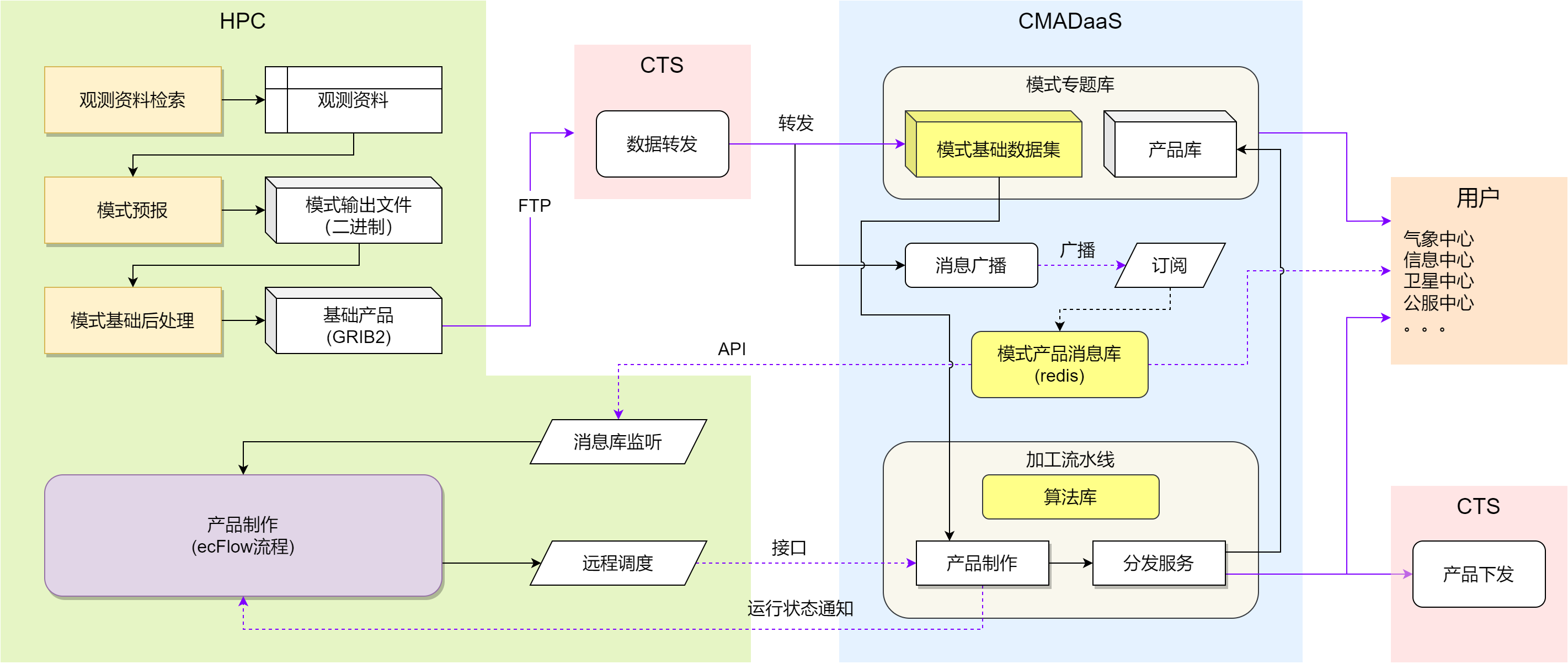
数值预报业务系统产品制作任务融入天擎方案
第一季度的进展未达到预期目标,没能在 CMADaaS 的加工流水线上部署一个算法。 原因在于我不善于处理跨部门之间的合作,也没能有效监督工程项目承建方的工作进度。 更深层次原因在于我认为当前信息化融入的工作方向和合作方式存在一些疑虑,我很难找到参与的兴趣。 也许随着项目逐步推进,我就能发现可以开展研发工作的地方,也许能找到 CMADaaS 与支撑模式研发工作的结合点。 不管怎样发展,我始终应该警惕在工程项目方面对部门存在的质疑,明确当前项目的边界,积极推动信息化工程项目的建设,协调基础设施环境准备工作,更主动地敦促承建方开展工作。
下一季度将继续完善 CMDaaS 中的模式基础数据集,将 sokort 镜像部署到 CMADaaS 新版容器环境中,与 NMIC 对接产品消息机制,并最终在加工流水线上实现一个绘图任务从数据检查、图形绘制到文件分发的完整流程。
分布式调度
在分布式调度项目方面,第一季度没有开发新的算法,也没尝试新的用例,仅对两个用例重新开展批量测试。 开发生成批量试验任务脚本和统计作业运行时间的小功能,收集了运行时长,但没对结果分析。
详情请参阅以下文章:
工具
数据准备工具 reki
整理中心内部能获取到的 GRIB 2 要素表,形成 CEMC 版本的要素表格 reki.format.grib.config.CEMC_PARAM_TABLE,reki 库的 GRIB load_ 系列函数已支持该表格。
研究 cfgrib 的索引机制,参看《GRIB笔记:cfgrib索引机制解析v1》。
仿照 ECMWF 开放数据中的索引文件尝试创建 json 行记录形式的索引文件,并测试索引文件对要素访问的影响。 初步测试结果显示索引文件对于从本地 GRIB2 文件抽取要素场没有加速效果,而对于在 NAS 等网络文件系统保存的 GRIB2 文件有明显的加速。
另外也测试了不同压缩方法下读取 GRIB 2 文件要素场的加载速度,参见《不同打包方式下GRIB2文件加载速度对比:简单打包与JPEG压缩》。
最近半年 reki 库没有新增核心功能,我所能想到的功能大多已经开发,更多开发目标则需要调研用户的需求。 所以最近半年的目标中都有编写文档的任务,可惜我都没有完成。 未来应该积极主动推广我开发的包含 reki 在内的各个工具库,编写文档和使用示例,以便了解用户需求,从而开展针对性开发。 当不明确下一步发展计划时,完善文档总不会白费功夫。
资料检索库 nuwe-cmadaas-python
修改内置的数据集配置为 YAML 格式文件,并将之前项目外部的逐小时站点观测资料的测试代码集成到项目的测试代码中。
单位正在将业务系统中观测资料检索接口从 CIMISS 兼容接口升级为 CMADaaS 的新版 MUSIC 接口,旧版和新版检索程序均通过工程项目使用 Fortran 开发。 Python 版本的检索程序或工具库依然有一定的需求,也是我开发 nuwe-cmadaas-python 库的最初想法,即为单位内部的 Python 项目提供封装 MUSIC 接口的观测资料检索工具库。 但因为我一贯不善于跨部门之间的沟通,又缺乏咨询工具库需求的主动性,再加上检索程序之前不是由部门负责维护的,所以一直缺少明确的开发目标。 从最近接口迁移的工作推进情况来看,未来检索程序的维护工作可能会由运行团队负责,这样就能考虑是否统筹开发不同编程语言的检索工具库。
我觉得类似资料检索这样功能单一的工具库不应该通过工程项目来开发,而是应该单位内部自行开发,哪怕专门设立一个内部课题也可以。 从之前一些工程项目的经验来看,通过工程项目开发的工具库后期往往找不到持续的维护者。 这也许并不是工程项目本身的问题,而是因为这些工具库本来就没人愿意开发,所以才会包给第三方去实现。 单位内部维护检索工具库的承接团队必须考虑是否熟悉 Fortran 语言。 如果最终决定由运行团队负责后续维护,那么有同事愿意维护当前程序是最好的情况,否则我会建议团队抛弃当前工程项目开发的 Fortran 程序,改用 Python 或其它编译类编程语言(C++,GOLANG)重新实现。
虽然工作的延续性很重要,但果断放弃也同样重要,没必要为过去的不恰当决定而买单。
工作流工具 takler
第一季度终于着手重启工作流工具项目,经过一番不连贯的思考,决定重启 takler 项目,编程语言依然使用 Python,参考 airflow, perfect, cylc 等 Python 实现的工作流项目。 重新编写 takler 代码的进展比较缓慢,仅实现了用于表示业务系统的树形结构和基本的状态变化机制,尚未完全覆盖 takler 项目在 2014 年的开发内容。
工作流软件是我一参加工作就想要涉及开发的工具,直到现在我参加工作已快 10 年,依然没有任何成果。 当前运维团队缺少核心技术,而工作流软件正是业务系统运行的核心组件之一。 无论后续是否继续强调核心组件的自主可控,无论未来中心是否会看重工具软件的开发工作,我都认为工作流工具是非常值得投入的长远发展方向。 即便重复造轮子很难达到 ecFlow 的高度,但有针对性开发的工作流软件还是能有一席之地。
第二季度会将 takler 项目作为最重要的开发工作,逐步制定开发规划,争取在第二季度末能用 takler 跑完一个完整的模式积分试验流程。
Slurm 工具 slurm-client-go
为了监控分布式调度项目批量提交的作业是否运行结束,第一季度在 slurm-clinet-go 命令行程序中添加作业监控子命令 watch。
但监控的任务结束时 (从 squeue 命令输出中消失时),子命令运行结束。
下一步计划集成作业提交功能,提供从提交到监控结束的命令行工具,可以尝试替代当前试验脚本中的 shell 代码。
数据处理库 mofis
本想仿照 ECMWF 的 FDB 开发 C++ 版本的模式要素库 (Model Field Storage),用于支撑产品制作任务,但第一季度仅在 mofis 中试验了一个最简单的数据处理任务,即从分时效 GRIB2 文件中抽取要素生成多个单要素的时间序列文件 (grib2-bth)。
关于模式要素库,我还需要仔细地思考如何与当前成果整合:
- 如何将团队现有的数据平台成果应用到业务系统流程中?
- 如何存储要素场?如何设计要素的元数据信息?如何实现查找功能?
- 如何部署整个数据平台?
- 是否需要使用 C++ 重新开发一套要素库?
同时也要回答为什么要引入要素库的问题:
- 当前基于本地文件的产品制作流程有什么问题?
- 要素库能为产品制作带来什么样的效益?
- 要素库需要怎样改变产品制作流程?
最后还要考虑对研发的支撑作用:
- 数据平台能否推广到研发应用?
- 未来该如何管理业务和科研数据?
第二季度应该思考上述问题,不能再没有目标地编写没有用处的代码,区分实验性质开发和业务目的开发,让数据平台能成为运行团队的一项核心技术。
思考
第一季度没有撰写新的论文笔记,只完善去年底的一篇笔记:
新闻稿笔记 1 篇已写完:
2 篇还没写完:
《视界:Aviso - ECMWF的数据可用性通知服务》
第二季度应该加快看论文的效率,提高撰写笔记的频率,用国内外同行的研究成果来指导自己的工作。
总结
第一季度运行团队始终面临一个质疑:
到底能拿出什么东西让中心相信团队不只是在做业务系统运维工作?
第一季度继续纠结个人(和团队)的未来在何方,却仍没有开展充分的思考(,沟通和讨论)。 过往的成绩让中心觉得运行团队只是在做运维工作,也只能做运维工作。 当前的状态来自过去长时间的积累,在没有外力推动的情况下,不可能一天两天就能达到新的状态。 没有必要因为对过去工作的各种质疑而陷入苦恼,想清楚当下和未来该做什么才是最重要的事情。 历史问题就交给历史去评述,不应该成为面向未来的包袱。 无论作为参与者还是旁观者,从历史经验吸取教训,避免重走老路就可以了。 当前没有谁能给团队指出一条康庄大道路,所以未来的路还得靠自己走下去。
至于我自己的问题就更明显了,没有找到明确的方向,缺乏在某方向持续研究的毅力,导致没有能拿得出手的成果。 方向太多没有专精是个问题,但对于看到的某个方向却不展开详细的调研和深入的思考则更是一个大问题。 单纯靠想并不能得出有说服力的结论,也不能想出明确的发展路线。 必须对国内外同领域的相关工作开展调研,综合分析,并与单位现状和未来相结合,进行深入地思考,才能得出能经得起时间考验的发展方向,才能有底气说服团队和中心押宝该方向。 这是我第二季度必须要做的一件事,对于当前想到的几个方向都开展调研,拿出有理有据的调研报告。
对于中心对团队的质疑,还是放到一边吧。既然没有有说服力的成果,就要立正挨打,接受批评建议。
下一步工作计划
核心任务
- 工作流
- 目标:在 HPC-PI 上运行模式积分完整流程
- 开发:根据进度逐步开发各个组件和功能
主要任务
- 模式要素库
- 调研:继续调研 FDB 库,团队内部开展讨论,明确数据平台部分工作内容和技术路线
- 分布式调度
- 试验:在更多测试用例上延续第一季度的批量试验,分析批量试验数据
- 总结:撰写技术报告
- 应用:争取在新的服务保障系统中得到应用(难度较大)
- 运维技术
- 产品消息库:构建 Redis 产品消息库,前期对接 NWPC 消息,后期对接 CMADaaS 消息
工具开发
- reki
- 文档:为当前已开发功能撰写文档,给出多平台下可用的测试用例 (Windows 桌面,Linux 服务器,HPC PI)
- 推广:了解中心使用 Python 开发的各类项目,通过多种途径在中心内部推广
- sokort
- 封装:提供 PI 上可用的预安装环境,提供 PI 上面向用户的使用说明
- 平台:更新 JupyterHub 环境,提供最新版本 sokort 工具
- meda
- 调研:调研业界主流 Python 气象绘图包,撰写调研报告
- 开发:继续仿制业务图形,争取确定 API 接口风格
- mofis
- 随意发挥
展望
写了 2 星期还没写完,4 月份都过去一半了,也就没什么可以展望的了。
不要因质疑而失去信心,不要因画饼而迷失方向。相信明天会更好吧。
