获取Slurm作业运行时间
上一篇文章《使用Jinja2批量生成Slurm作业脚本》介绍如何批量编写作业脚本。 批量提交作业的目的是统计作业运行耗时,本文介绍如何使用 Python 通过执行 sacct 命令批量获取 Slurm 作业的运行时间。
方法
Slurm 的 sacct 命令可以获取作业相关运行数据。
默认参数 sacct 命令输出如下所示,仅给出基本信息:
sacct
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
38407636 reki normal acct4 32 COMPLETED 0:0
38407636.ba+ batch acct4 32 COMPLETED 0:0
38407636.0 python acct4 32 COMPLETED 0:0
38407637 reki normal acct4 32 COMPLETED 0:0
38407637.ba+ batch acct4 32 COMPLETED 0:0
38407637.0 python acct4 32 COMPLETED 0:0
启用扩展参数的 sacct 命令显示时间信息:
sacct -l --job 38407636
JobID JobIDRaw JobName Partition MaxVMSize MaxVMSizeNode MaxVMSizeTask AveVMSize MaxRSS MaxRSSNode MaxRSSTask AveRSS MaxPages MaxPagesNode MaxPagesTask AvePages MinCPU MinCPUNode MinCPUTask AveCPU NTasks AllocCPUS Elapsed State ExitCode AveCPUFreq ReqCPUFreqMin ReqCPUFreqMax ReqCPUFreqGov ReqMem ConsumedEnergy MaxDiskRead MaxDiskReadNode MaxDiskReadTask AveDiskRead MaxDiskWrite MaxDiskWriteNode MaxDiskWriteTask AveDiskWrite AllocGRES ReqGRES ReqTRES AllocTRES TRESUsageInAve TRESUsageInMax TRESUsageInMaxNode TRESUsageInMaxTask TRESUsageInMin TRESUsageInMinNode TRESUsageInMinTask TRESUsageInTot TRESUsageOutMax TRESUsageOutMaxNode TRESUsageOutMaxTask TRESUsageOutAve TRESUsageOutTot
------------ ------------ ---------- ---------- ---------- -------------- -------------- ---------- ---------- ---------- ---------- ---------- -------- ------------ -------------- ---------- ---------- ---------- ---------- ---------- -------- ---------- ---------- ---------- -------- ---------- ------------- ------------- ------------- ---------- -------------- ------------ --------------- --------------- -------------- ------------ ---------------- ---------------- -------------- ------------ ------------ ---------- ---------- -------------- -------------- ------------------ ------------------ -------------- ------------------ ------------------ -------------- --------------- ------------------- ------------------- --------------- ---------------
38407636 38407636 reki normal 32 00:02:18 COMPLETED 0:0 Unknown Unknown Unknown 5Gc 0 billing=3+ billing=3+
38407636.ba+ 38407636.ba+ batch 1 32 00:02:18 COMPLETED 0:0 0 0 0 0 5Gc 0 cpu=32,me+ energy=0 energy=0
38407636.0 38407636.0 python 0 cmac1418 2 0 0 cmac1418 2 0 29 cmac1418 2 0 00:00:45 cmac1418 2 00:00:01 32 32 00:02:11 COMPLETED 0:0 0 Unknown Unknown Unknown 5Gc 0 2189.00M cmac1418 2 68.41M 0.01M cmac1418 2 0.00M cpu=32,me+ cpu=00:00:01,+ cpu=00:00:45,+ cpu=cmac1418,ener+ cpu=2,fs/disk=2,m+ cpu=00:00:45,+ cpu=cmac1418,ener+ cpu=2,fs/disk=2,m+ cpu=00:00:45,+ fs/disk=8218 fs/disk=cmac1418 fs/disk=2 fs/disk=256 fs/disk=8218
Elapsed 列是运行时间,该作业有三个条目:
38407636:作业号38407636.ba+:通过 sbatch 提交的 shell 脚本38407636.0:Shell 脚本中通过 srun 运行并行 Python 脚本
前两个条目运行时间相同 (00:02:18),可以看成整个作业脚本的耗时。 第三个条目运行时间稍小 (00:02:11),是并行 Python 脚本的运行时间。 差异主要来自运行 Python 脚本前需要加载 Anaconda Python 环境。
sacct 默认输出的表格形式适合在终端中的人机交互,但不方便使用程序自动解析。
使用 -P 参数可以将输出改为使用 | 分割,适合按照 CSV 格式文件解析。
输入数据
批量运行的作业脚本将输出写入到同一个文件夹中,文件名是 task_01.{job_id}.out,其中 job_id 是 Slurm 作业号。
使用 pathlib.Path.glob 函数获取所有以 .out 结尾的日志文件:
output_path = Path("/some/path")
task_output_list = sorted(output_path.glob("*.out"))
task_output_list
[PosixPath('/some/path/test_01.38407636.out'),
PosixPath('/some/path/test_02.38407637.out'),
...skip...
]
单个任务运行时间
首先获取单个任务的运行时间。
提取第一个测试脚本的作业号:
task_output = task_output_list[0]
job_id = task_output.stem.split(".")[-1]
job_id
38407636
调用 sacct 命令并捕获命令输出
slurm_command = subprocess.run(["sacct", "-l", "-P", "--job", job_id], stdout=subprocess.PIPE)
使用 pandas 解析命令输出为表格,将 Elapsed 列转为 pandas.Timedleta 对象:
slurm_df = pd.read_table(
io.StringIO(slurm_command.stdout.decode("utf-8")),
sep="|",
)
slurm_df["Elapsed"] = slurm_df["Elapsed"].map(lambda x: pd.to_timedelta(x))
slurm_df

Elapsed 列是运行时间:
slurm_df["Elapsed"]
0 0 days 00:02:18
1 0 days 00:02:18
2 0 days 00:02:11
Name: Elapsed, dtype: timedelta64[ns]
作业总体运行时间,即作业号 38407636 对应的行:
slurm_df[slurm_df["JobID"] == job_id]["Elapsed"].iloc[0]
Timedelta('0 days 00:02:18')
示例
将上述过程整理为函数:
def get_job_duration(job_id):
slurm_command = subprocess.run(["sacct", "-l", "-P", "--job", job_id], stdout=subprocess.PIPE)
slurm_df = pd.read_table(
io.StringIO(slurm_command.stdout.decode("utf-8")),
sep="|",
)
slurm_df["Elapsed"] = slurm_df["Elapsed"].map(lambda x: pd.to_timedelta(x))
total_duration = slurm_df[slurm_df["JobID"] == job_id]["Elapsed"].iloc[0]
python_duration = slurm_df[slurm_df["JobID"] == f"{job_id}.0"]["Elapsed"].iloc[0]
return {
"total": total_duration,
"python": python_duration,
}
同时该示例也在输出日志文件中打印主运行函数的运行时长,例如 38407636 作业:
[cal_run_time] function run time: 0 days 00:01:13.846254
上述时间比 Slurm 给出的运行时长更少,主要是因为在 HPC 分布式存储环境中, Python 脚本 import 阶段读取大量小文件耗时比单机环境下增长更明显。
将提取主函数运行时长的过程封装成函数:
def get_main_duration(file_path):
duration = None
with open(file_path, "r") as f:
lines = f.readlines()
for line in lines:
line = line.strip()
if line.startswith("[cal_run_time] function run time: "):
token = line[len("[cal_run_time] function run time: "):].strip()
duration = pd.to_timedelta(token)
break
if duration is not None:
duration = duration.ceil('S')
return duration
duration = get_main_duration(task_output)
print(duration)
0 days 00:01:14
以上两种时间提取方法合并为一个函数中:
def get_duration(file_path: Path):
job_id = file_path.stem.split(".")[-1]
job_duration = get_job_duration(job_id)
main_duration = get_main_duration(file_path)
return {
**job_duration,
"main": main_duration,
}
批量获取所有作业的运行时长,得到运行时长表格:
records = []
for task_output in tqdm(task_output_list):
record = get_duration(task_output)
records.append(record)
df = pd.DataFrame(records)
df = df.applymap(lambda x: x.seconds)
df
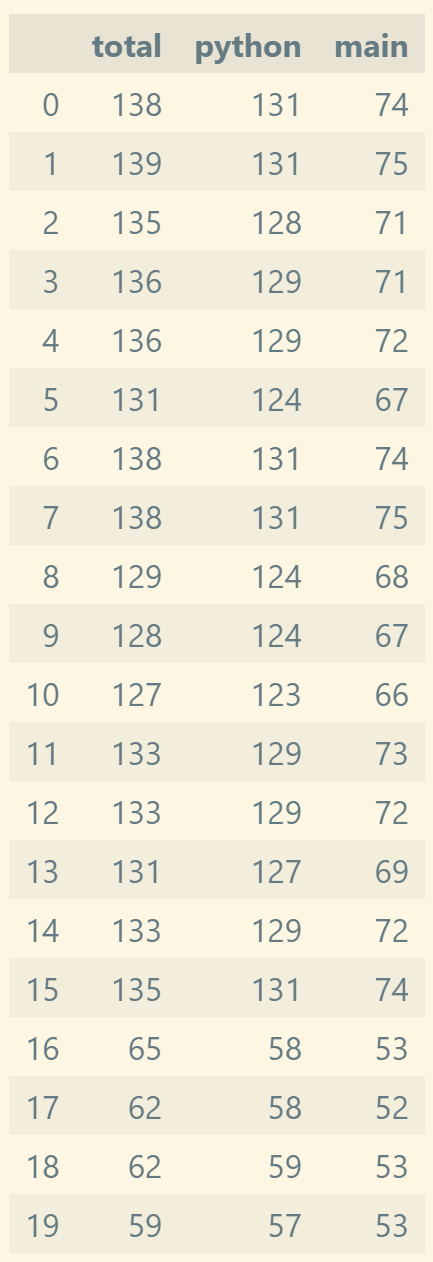
其中:
- total:作业运行时长
- python:并行 Python 脚本运行时长
- main:主代码段运行时长