GRIB笔记:cfgrib索引机制解析v1
cfgrib 是由 ECMWF 开发的 GRIB 格式 Python 工具库,基于 ecCodes 库实现 GRIB 格式文件的编解码。
cfgrib 目前版本正在开发 v2 版索引,经测试发现 v2 版本索引实现存在一定问题,可以生成但无法被 cfgrib 读取。 本文以 v0.9.9.1 版本为例介绍 cfgrib 索引版本 1,git 提交 hash 为 af3f96c1。
索引简介
在默认参数配置下,cfgrib 会检查 GRIB 2 文件是否有索引文件存在,如果有则直接使用该文件,如果没有,则会在 GRIB 2 文件目录中生成一个索引文件。
下面代码会为 gmf.gra.2022021700006.grb2 文件在当前目录生成索引文件 gmf.gra.2022021700006.grb2.02ccc.idx,文件名中 02ccc 是 cfgrib 自动生成的 hash 编码。
import xarray as xr
data_path = "./gmf.gra.2022021700006.grb2"
ds = xr.open_dataset(
data_path,
engine="cfgrib",
backend_kwargs={
"filter_by_keys": {
"shortName": "t",
"typeOfLevel": "isobaricInhPa",
},
}
)
第二次运行上述代码时,cfgrib 会自动加载索引文件信息,加快要素查找速度。
对比两次运行 xr.open_dataset 的时间,使用索引可以极大提高查找要素场的效率。
| 索引 | 时间 (s) |
|---|---|
| 创建 | 4.2 (创建索引 2.8秒) |
| 使用 | 2.0 |
索引结构
索引文件是 pickle 二进制格式,持久化 cfgrib.FileIndex 对象。
FileIndex 对象包括:
filestream:GRIB 消息的迭代对象,保存 GRIB 文件路径index_keys:索引需要的 GRIB key 键名列表offsets:列表,每个元素是两个元素的元组,[(key tuple, id list), ..., ...]。- key tuple:元组,个数与 index_keys 相同,每个值是 index_keys 中 GRIB key 键对应的值
- id list:列表,GRIB 消息偏移字节数
header_values:动态计算的属性,字典形式,保存每个index_keys中 GRIB key 可能的取值范围(列表形式)filter_by_keys:筛选条件,创建索引文件时不使用该字段
创建索引
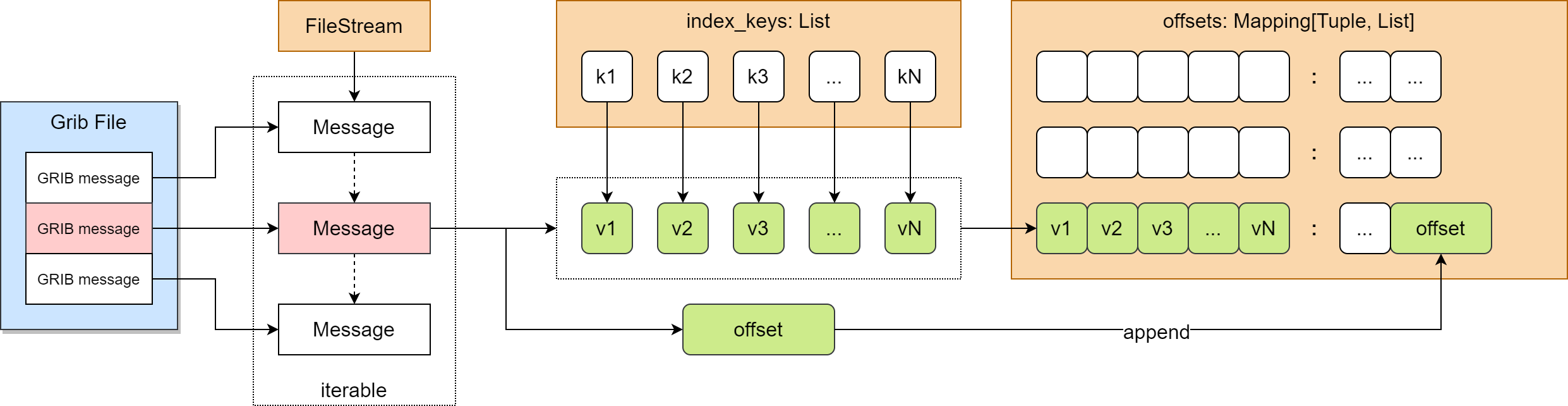
cfgrib 创建 GRIB 2 文件索引对象 FileIndex 示意图
上图是 cfgrib 创建 GRIB 2 文件索引对象 FileIndex 的示意图,主要说明 FileIndex.from_filestream 方法如何生成 FileIndex 中的 offsets 。
Grib File 是文件系统中保存的 GRIB 2 文件,包含三个 GRIB 2 消息。
from_filestream 接收两个参数 filestream 和 index_keys。
FileStream 顺序访问 Grib File 中的每个 GRIB 消息,返回 Message 对象。
对于每个消息 Message,按照 index_keys 中列出的键名依次获取对应的键值,然后获取 GRIB 消息在文件中的偏移字节数 offset。
将所有键值组成一个元组,作为 offsets 字典的键名,将 offset 追加到键名对应的列表值中。
在创建 FileIndex 对象时,会将 offsets 字典转为元素为 (key, value) 的列表形式。
创建索引对象 FileIndex 后,FileIndex.from_indexpath_or_filestream() 方法会使用 pickle.dump 将其序列化为二进制文件。
自动生成的索引文件名中序号值来自 index_keys 的 md5 值前 5 位:
hash = hashlib.md5(repr(index_keys).encode("utf-8")).hexdigest()
indexpath = indexpath.format(path=filestream.path, hash=hash, short_hash=hash[:5])
由此可以看到 cfgrib 索引方式的一个问题:如果索引 key 有变化,就需要重新创建新的索引文件。
使用索引
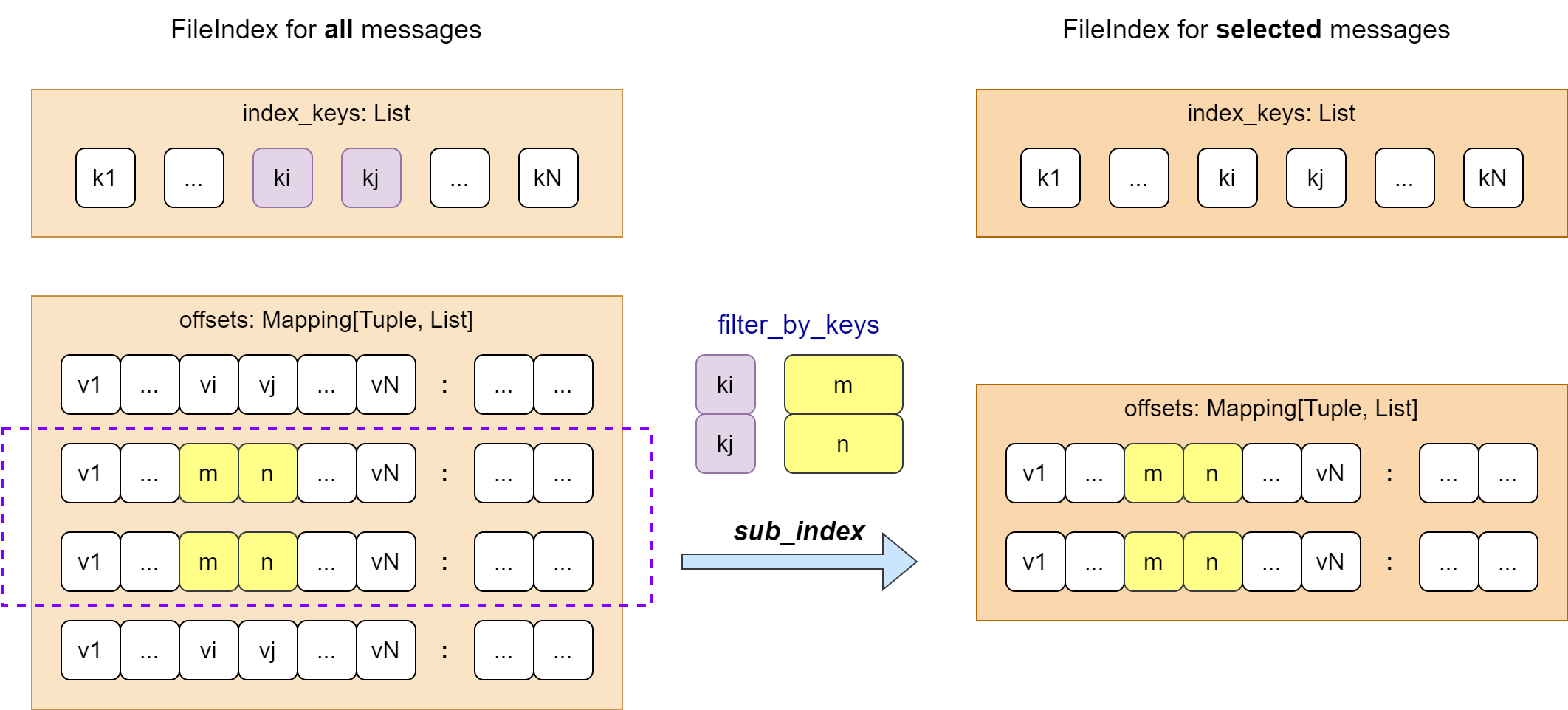
cfgrib 使用 GRIB 2 索引文件示意图
cfgrib 内部基于索引信息来实现要素集构建、要素场筛选等功能。 所以 cfgrib 在读取 GRIB 2 数据时会首先检测索引是否存在:
- 已有索引,直接载入索引;
- 没有索引,按照上一节方法生成索引,并保存为文件。
可以通过设置跳过索引文件保存步骤,但无法跳过索引生成步骤。
筛选要素场时,cfgrib 首先通过 FileIndex.subindex 方法从原始索引对象中生成新的索引对象。
根据 filter_by_keys 设置的筛选条件 (ki=m, kj=n) 对比 offsets 中每条记录,仅当满足条件的记录放到新的索引中。
cfgrib 会使用新索引对象生成相应的数据集对象 xr.Dataset。
根据上述分析,xr.open_dataset() 函数使用 cfgrib 加载 GRIB 2 文件的过程如下图所示:
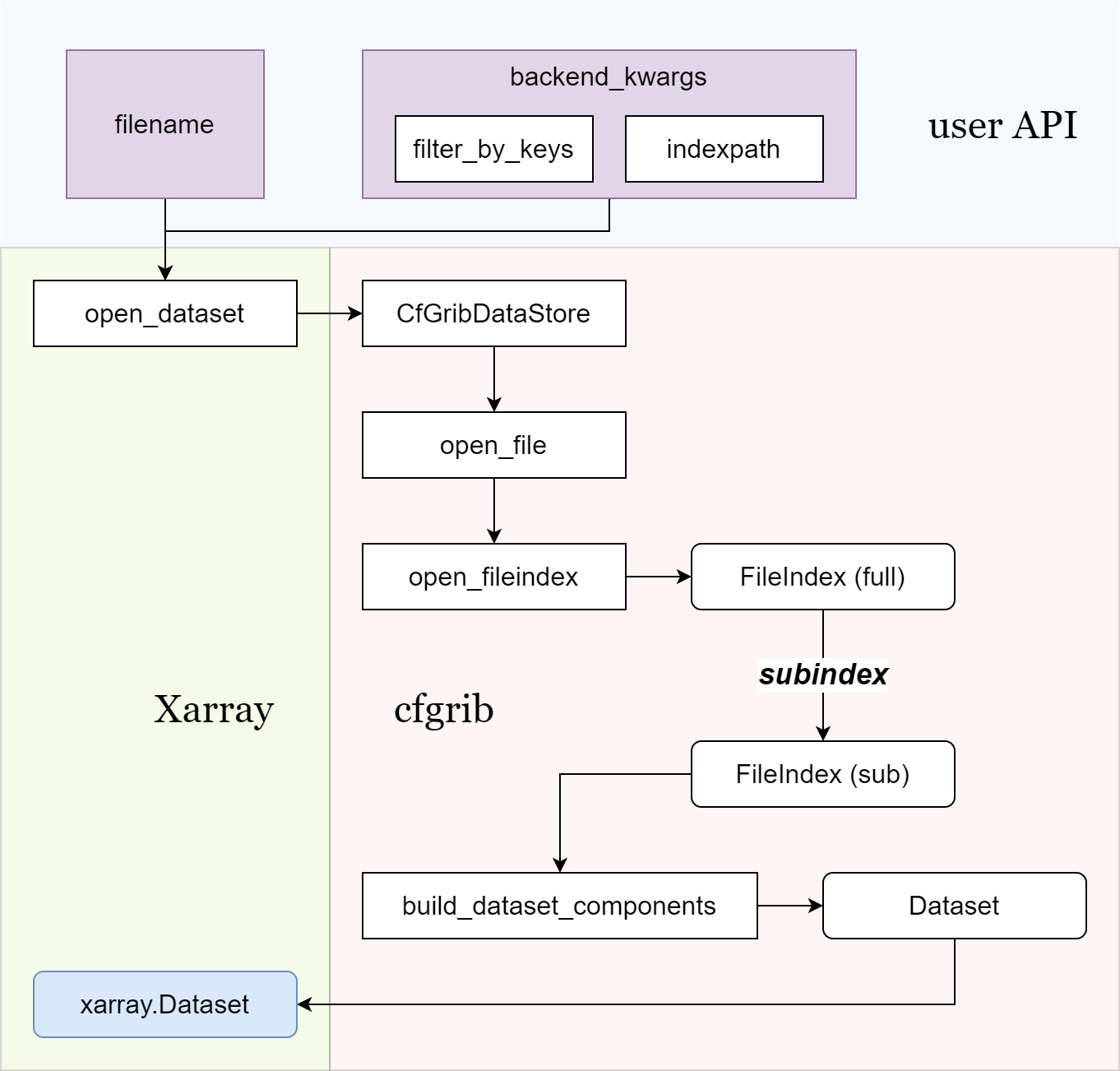
xarray 使用 cfgrib 加载 GRIB 2 格式数据示意图
总结
cfgrib 核心思想之一是使用索引管理 GRIB 2 数据的键值对形式元数据。
优点:
- 元信息规范:保持与 ecCodes 一致的元信息表示方法
- 数据集:对整个文件做索引方便以数据集方式描述数据文件
- 筛选:使用索引可以快速实现要素场筛选和定位
问题:
- 效率:第一次生成索引文件时效率不高,需要读取整个文件中所有要素场的元信息
- 兼容性:对于 ecCodes 不支持 shortName 的变量需要额外提供其他 GRIB key
cfgrib 对于 GRIB 格式的索引设计非常有代表性,值得借鉴。
参考
cfgrib 相关文章:
