论文阅读:面向天气和气候数据的可扩展对象存储
A Scalable Object Store for Meteorological and Climate Data
Simon D. Smart, Tiago Quintino, and Baudouin Raoult. 2017. A Scalable Object Store for Meteorological and Climate Data. In Proceedings of the Platform for Advanced Scientific Computing Conference (PASC ‘17). Association for Computing Machinery, New York, NY, USA, Article 13, 1–8. DOI:https://doi.org/10.1145/3093172.3093238
本文介绍由 ECMWF 开发的 Fields Database (FDB) 第 5 版。
以下内容根据笔者个人理解整理,如有偏差敬请谅解
正文
数值天气预报与气候模拟处于 High Performance Computing (HPC) 与 Big Data / High Performance Data Analytics (HDPA) 社区的交叉点。 数据量快速增长给数据处理管道带来了重大的可扩展性挑战,数据在各个阶段之间的移动是其中最重要的因素之一。
在 ECMWF,HPC 设施内的气象数据存储在索引数据存储 (indexed data store) 中,以便根据明确定义的气象元数据 (meteorological metadata) 模式进行检索。
存储索引数据,使用元数据检索
介绍
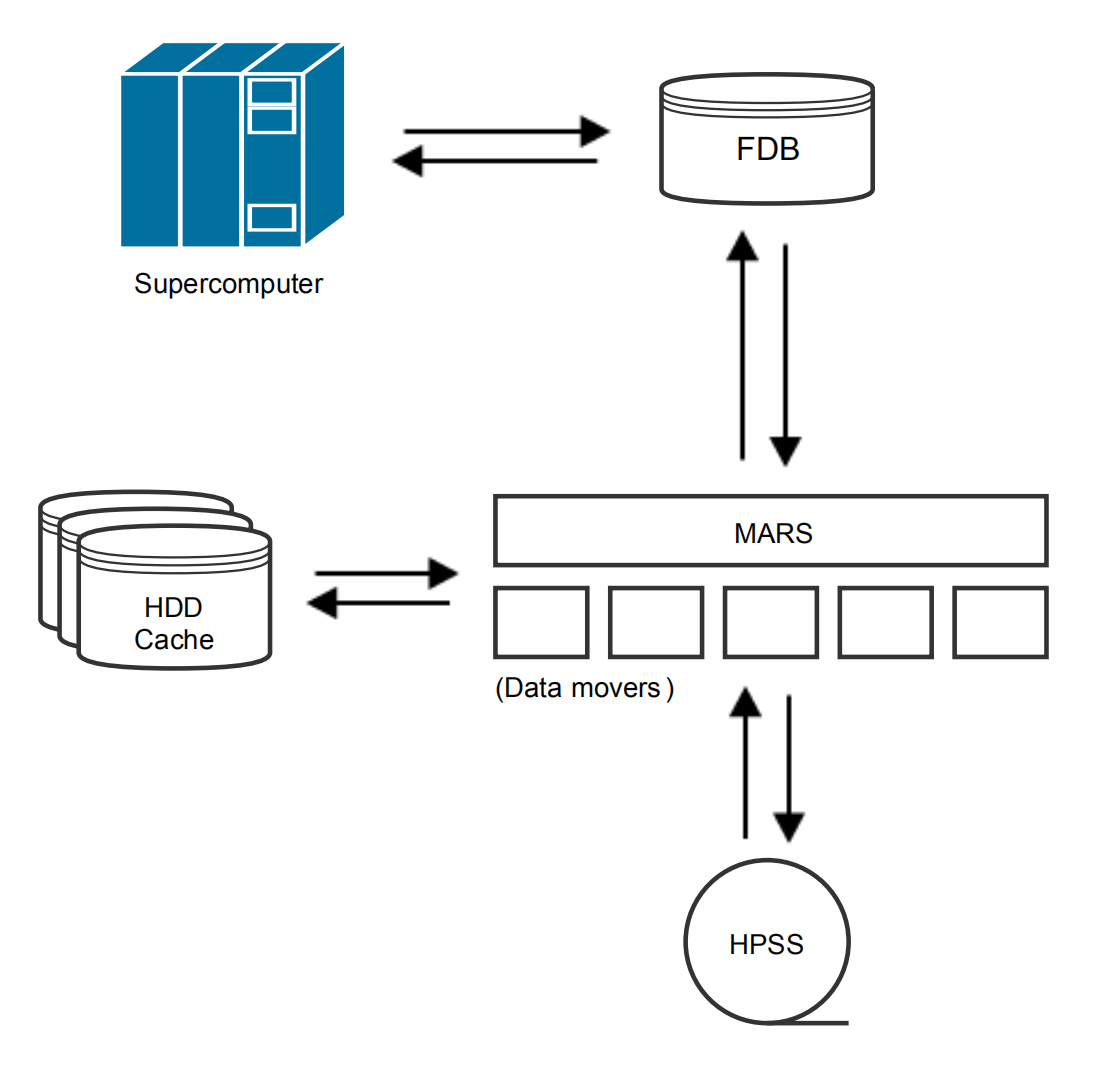
图 1 ECMWF 的高性能数据基础设施概览,图片来自论文
FDB 是一个软件库,也是一个内部提供的服务,用作天气预报软件堆栈的一部分。 在使用中,FDB 作为气象数据字节流的领域特定对象存储 (domain-specific object store) 运行,因此 ECMWF 的 IFS 的输出 (GRIB 数据) 被写入 FDB,被各种后处理和存档任务从其中检索。 FDB 还作为应用程序控制的分层存储管理器中的最高层运行。
在实践中,业务天气预报的价值在生成后会迅速衰减(被后来的预测所取代)。 FDB 的存在是当数据具有广泛用途因而经常被访问时使它们快速、廉价地可用。
使用元数据的键值对特性
挑战:
- 数据量增加:分辨率,多样性
- 硬件制约:I/O 速度跟不上计算能力
- 数据管理:多样性也带来元数据管理和索引的负担
- 技术发展:新硬件应用
FDB 是 MARS 基础设施中的热对象存储 (hot object store) 或附加“热”层 (additional “hot” layer)。
数据存储和管理方法
系统地标记和跟踪与所有生成的气象数据相关联的元数据有助于管理数据。
FDB 针对 GRIB 数据实现索引数据存储,尚未有同行实现。
硬件并行的实现方式:
- 根据定义的模式交错来自多个节点的数据
- 任务并行跨一组 I/O 服务器节点写入数据
- 两者的组合
POSIX 文件系统不利于多个写入者同时写入不冲突的数据。 一个明显的方向是放松 POSIX 语义限制,转向对象存储。
当前很多系统提供对象存储,使用多种格式的哈希表。 为什么要自己开发对象存储库?
- 这些系统都依赖分布式商业硬件,而不是 HPC
- ECMWF 的数据访问要求,特别是涉及枚举范围请求,需要更广泛的索引,对于这些通用对象存储方法,需要外部索引服务
- 当前面向 HPC 开发的项目离在业务中心应用还有很远距离
本文的 FDB 在现有并行文件系统之上提供对象语义,以实现在现有硬件上运行的现有软件的平滑过渡。 后续替代技术可用时再考虑重建后端。
FDB4
业务 FDB 是多生产者、多消费者系统的存储层。
GRIB 数据需要索引,读元数据时需要花费大量时间解压缩和解码。
FDB 4 基于以下索引方案构建:
- 每个数据库是整体元数据空间的细分,索引是写入要素场的简单列表
- 要素写入时,条目新增或更新到这个列表中
- 并行执行时,MPI 用于同步对该文件的写入访问,每个给定的数据库中同时仅能有一个写入 MPI 作业
FDB 4 的问题:
- 重写必须保证大小相同
- 非事务,出错需要全部重新索引,业务上重做可以保证,但不适合研发工作流
- 没有与 MARS 共享组件
FDB5 设计与实现
读写行为:每个写入进程都会生成许多具有强相关元数据的要素场,并且只有在模式向外部工作流控制器发出已到达某些检查点 (例如在给定迭代完成后) 的信号时才会触发读取尝试。
写独立。每个写入者写入自己的数据和索引信息,不参考其它进程。 仅当写入过程结束且数据被刷新时,数据才会被一次添加到全局命名空间中。 一条记录被追加到全局 Table Of Contents,是唯一需要同步的操作,可以通过 POSIX 文件系统的 append 操作实现,不需要 MPI 或其它同步、锁机制。
不可变。写入到数据库中的数据不可修改(immutable),数据库是一次写入,多次读取。 修改数据时,只修改元数据信息,新的要素场单独保存,而不修改旧的要素场。
前后端边界。FDB 在前端元数据管理控制和后端数据存储之间勾画清晰的边界,便于适配未来科技领域的发展。
分层索引
使用元数据的键值对区分每个要素场,平均 10 个。 索引结构的设计考虑元数据空间的稀疏性。
键分为三组:
数据库 (database):高层信息,数据生成时间 + 总体数据流(业务系统名)
- 业务:数量固定,长期存在
- 研发:每个试验一个数据库
索引 (index):每个数据库的一系列索引信息,标识一组可能密集填充元数据空间的要素场
要素场 (field):存储的数据元素,GRIB 字节流
键与存储层的对应关系与具体使用的后端有关。 目前使用 POSIX 兼容文件系统存储数据和索引,后续会引入其他后端,并考虑通过网络联合多个 FDB 服务。
后端功能使用访问者模式 (vistor pattern) 实现。
逻辑功能的清晰分离:前端知道如何遍历元数据模式,后端知道如何遍历索引,以便从适当的位置回调特定的函数(用于读取、写入、列表等)。
POSIX(文件系统)后端
POSIX 后端利用 POSIX 兼容文件系统特性来防止冲突和写入文件,不需要锁机制。 ECMWF 目前使用分布式并行文件系统 Lustre。
结构
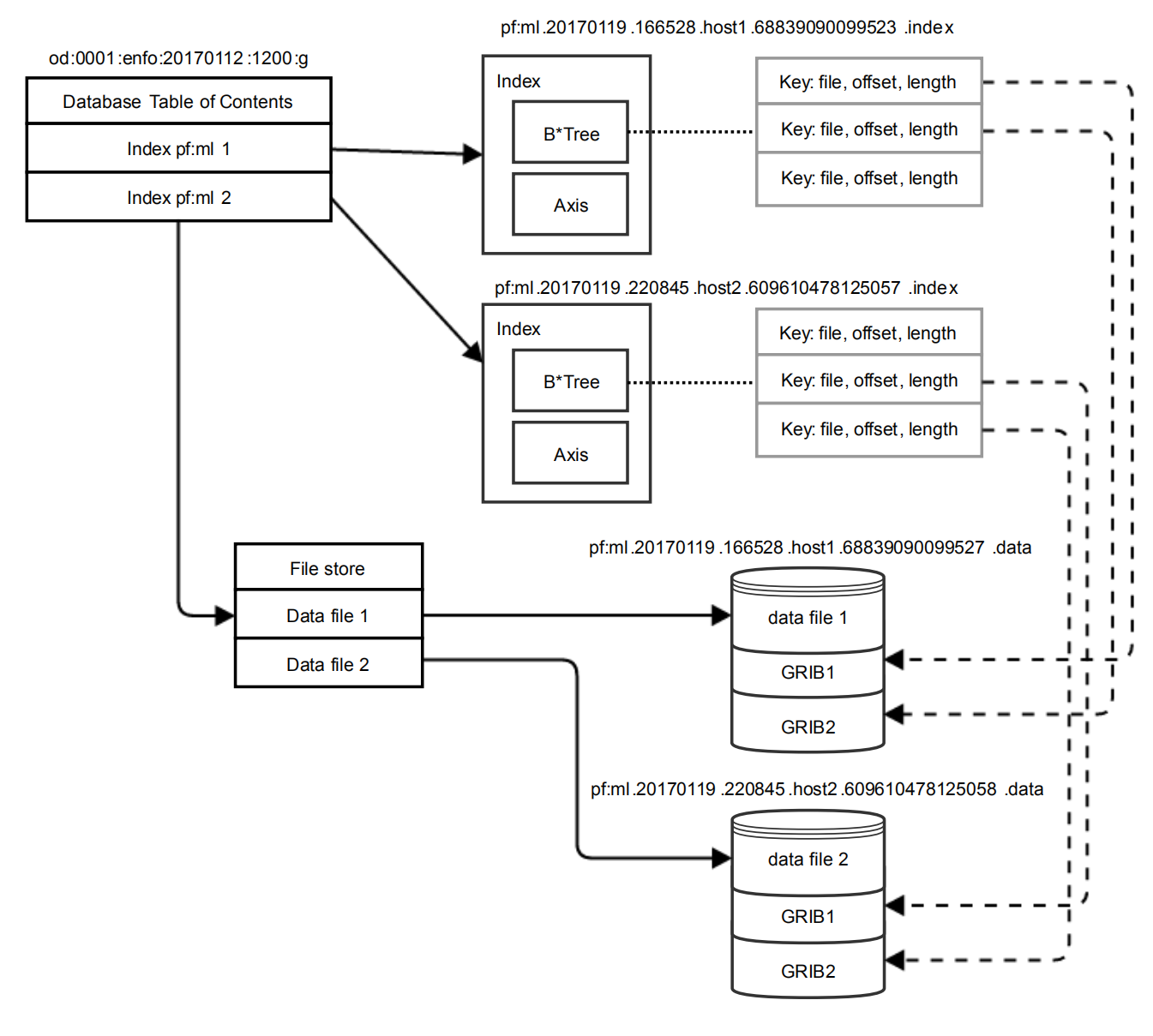
FDB5 数据库的概念层次结构,图片来自论文
使用目录结构保存数据库,路径由部分描述键决定,每个数据库完全独立。 创建时,全局模式 (global schema) 会被复制,这样模式变化仅影响新的数据库。
TOC (Table Of Content):数据库的主访问入口,包含索引文件的列表。
Axis object:每个索引文件一个,包含索引文件中占用元数据空间的最大范围。 针对每个 key 存储跨越的值范围,在执行查找时,检查 axis object 将排除大多数索引。
B*-tree:每个索引文件包含一个,保存从键到数据引用的映射。 数据引用由文件、偏移和长度组成。 GRIB 消息相互独立且自解释,GRIB 文件仅是 GRIB 消息的简单堆叠,所以直接使用现有文件而不进行复制,必要时可以重新索引。
索引文件生成:每个写入进程生成一个索引文件,每个数据文件唯一属于一个进程。 索引文件唯一命名,创建文件期间不需要在写入进程之间进行协调。
写入过程
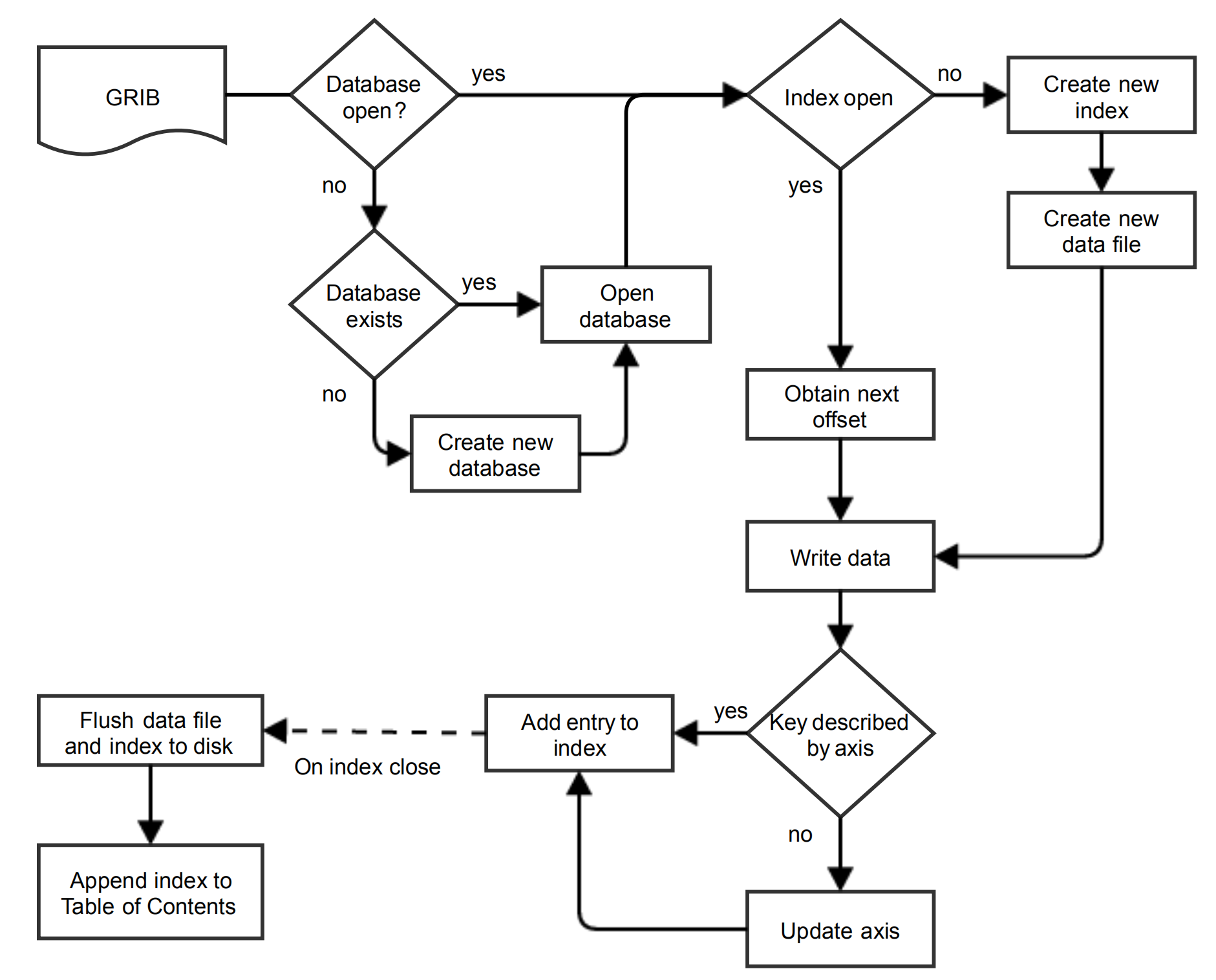
写入流程,图片来自论文
写入操作包括一系列 GRIB 消息和它们的元数据。
写入过程:
- 检查创建数据库 (database)
- 检查创建索引 (index)
- 写入数据文件,每个写入进程每个索引对应一个数据文件
- 检查 key 是否在 axis 范围内
- 增加 index 条目
- 全部索引完成时,将数据文件和索引写入到磁盘中
- 将索引添加到全局表格中 (Table of Contents)
仅在最后两步可能发生写入冲突,但这两步仅在整个索引文件生成后才进行,可以使用 POSIX 文件系统的同步机制实现。
读取过程
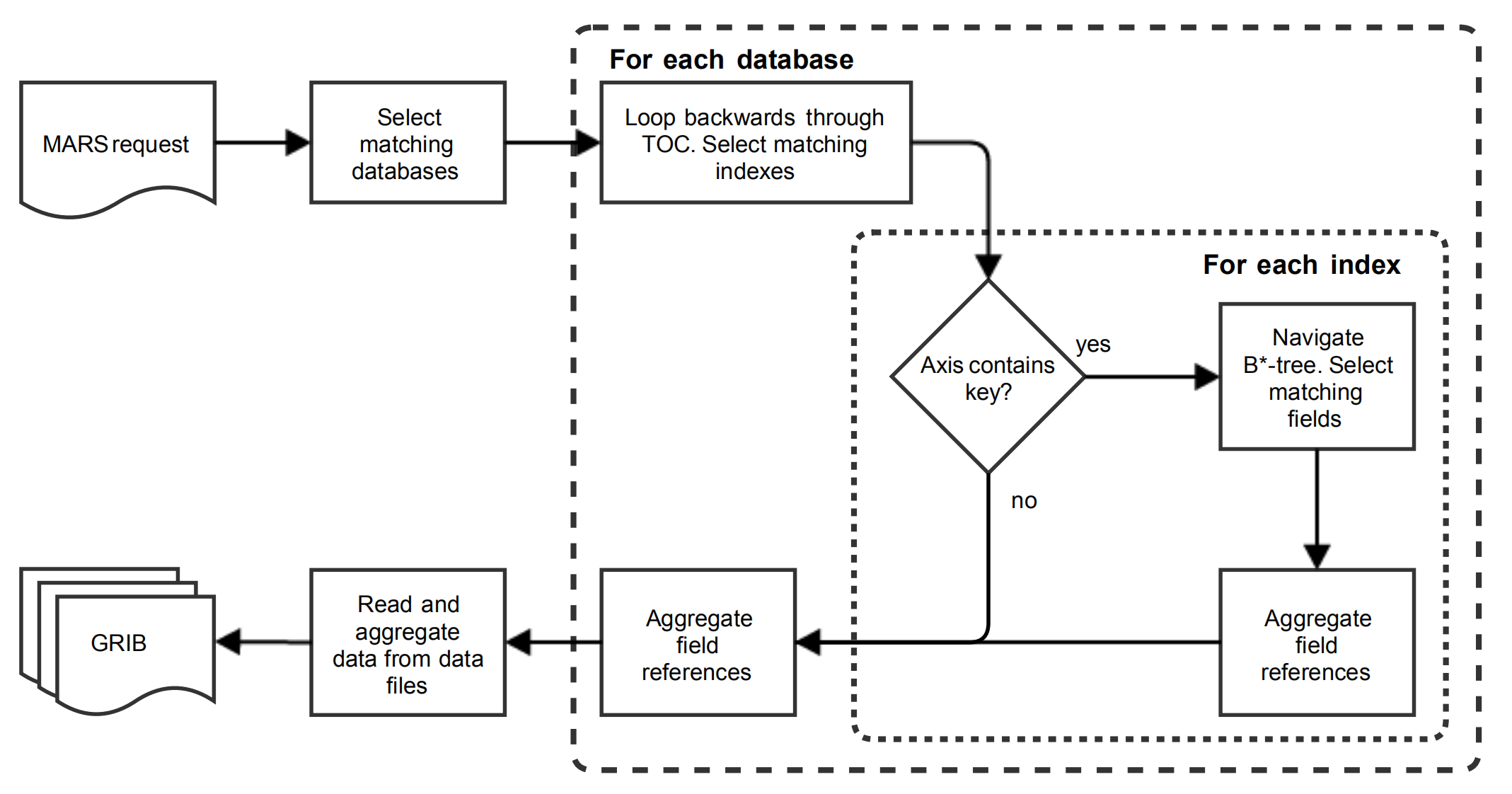
读取流程,图片来自论文
示例检索请求,检索多个要素,多个层次,多个时效
retrieve,
class = od,
type = pf,
stream = enfo,
expver = 0001,
levelist = 1/to/90,
param = t/u/v,
date = 20170112,
time = 1200,
step = 1/to/240/by/3,
number = 1,
target = "output.grib"
使用元数据查找:
- 读取请求被解析成一系列键
- 通过索引中的 axis 支持读取参数中的范围和通配符
- TOC 中条目反序存储,可以覆盖旧数据
读取策略:
- 查找索引:在每个符合条件的数据库中查找所有匹配的条目
- 集中取数据:汇总所有索引条目后,再获取数据(同步或异步)
- 缓存:最近访问的数据库和索引会缓存到内存中(操作系统实现 or 软件实现)
读取过程:
- 载入全部表格 (TOC)
- 检查每个索引 (index),检查 axis 是否包含 key
- 检查索引中条目是否满足筛选条件
- 汇总找到的要素索引并返回
- 所有数据库都完成检查后,读取数据文件
测试
性能不佳情景:
- 大量检索超出文件系统缓存
- 读请求的绝对开销大,不利于小数量检索
结论
- 写操作:事务,多进程写入
- 设计:前后端分离,支持未来引入新技术
- 实现:POSIX 后端,推迟写入索引直到数据完成输出
讨论
管理索引而不是重写数据:为 GRIB 2 文件建立索引开始,而不是将 GRIB 2 文件解码保存为其他形式
设计元信息:确定索引信息的内容 (字符串 vs 数字,ecCode vs 自建) 和存储格式 (本地文件 vs 数据库),满足业务和科研查询需求
对接本地文件:一步步实现,从本地文件开始,逐步过渡到远程文件
前后端分离:保持面向用户的前端 API 接口不变,后端支持使用不同的技术实现
参考
论文地址:https://doi.org/10.1145/3093172.3093238