视界:在EuroHPC ACROSS项目中推进高性能数据管理
声明
本文正文内容翻译自 ECMWF 官方网站 2021 年 10 月 13 日发布的文章《Advancing high-performance data management in the EuroHPC ACROSS project》,由 Emanuele Danovaro 撰写,版权归原作者所有。 翻译底稿来自 Google 翻译。
正文
Bonn 和 Bologna 开业的消息在 EuroHPC ACROSS 项目合作伙伴中引起了极大的热情,期待与 ECMWF 更紧密地合作,开发对未来数值天气预报至关重要的高性能、低功耗和可扩展的计算机架构。

ECMWF 在意大利博洛尼亚开设的新数据中心将启用 Atos BullSequana 超级计算机系统,为合作提供更多机会。图片来自原文。
ACROSS 项目于 2021 年 3 月启动,将运行三年。 它旨在开发一个高性能计算、大数据和人工智能的融合平台,提供有效机制来轻松描述和管理复杂的工作流。 能源效率将发挥关键作用,大量使用专用硬件加速器、高频系统监控和应用智能作业调度机制。 该平台将由 Links 基金会 (IT)、Atos (FR)、IT4I (CZ)、Inria (FR) 和 Cini (IT) 共同设计,并将利用 EuroHPC 计算资源,即 CINECA Leonardo 和 Lumi pre-exascale supercomputers 和 IT4I Karolina petascale machine。
该平台将通过三个用例进行验证:
- 第一个用例旨在通过设计一个基于机器学习的系统来探索参数化设计空间,从而提高航空涡轮机的推进效率
- 第二个用例将面临大规模水文气象和气候工作流中的数据管理问题,解决 cloud-resolving 全球尺度数值天气预报 (NWP) 和高效后处理技术
- 第三个用例将侧重于开发用于模拟大规模 CO2 storage 场景的系统
ECMWF 与马克斯普朗克研究所 (MPI)(德国汉堡)、Deltares (NL) 和 Neuropublic (GR) 等领域专家合作,领导 ACROSS 合作伙伴开发水文气象和气候用例。
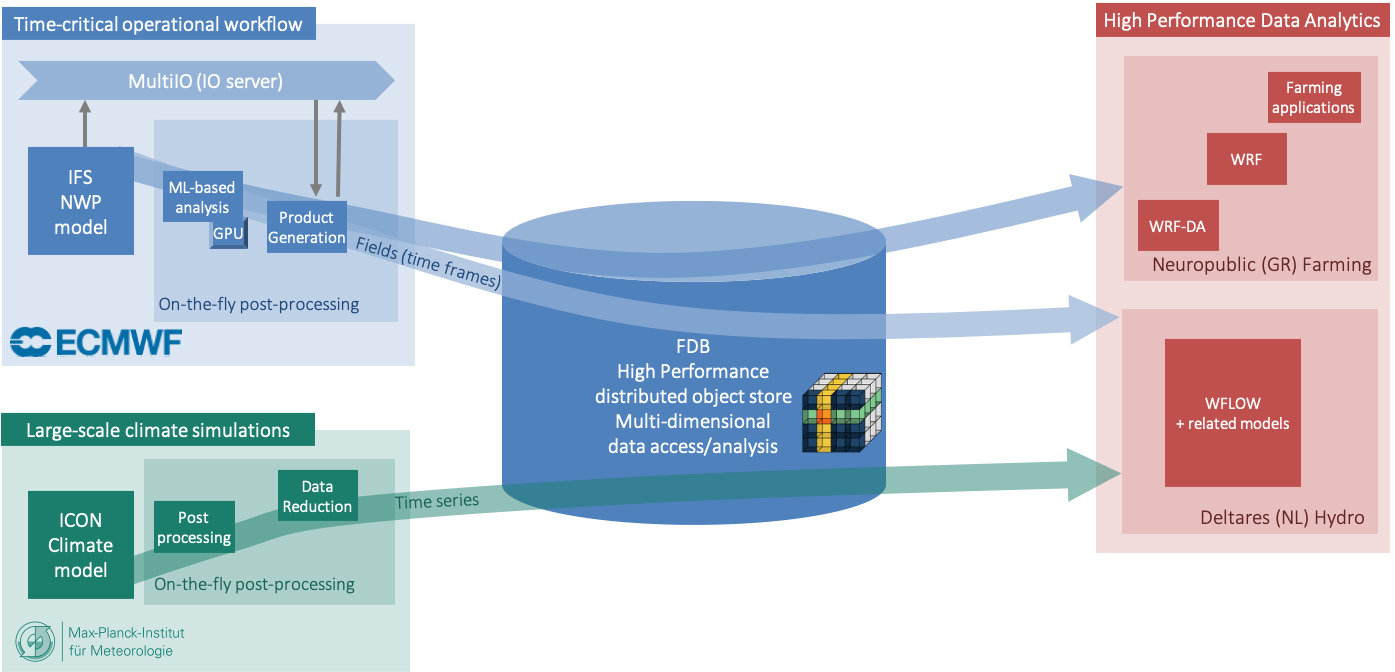
EuroHPC ACROSS 项目正在开发的水文气象和气候用例示意图。图片来源:EuroHPC ACROSS 项目。
我们的目标是通过多个并发就地 (in-place) 数据后处理应用程序 (例如产品生成、机器学习推理) 和对下游应用程序的低延迟支持 (例如区域降尺度、水文模拟),来进行全球 5 公里分辨率模拟。 就地后处理对于减轻 IO 系统的压力和将工作流扩展到超高分辨率至关重要。 在 ECMWF 当前的操作系统中,IFS 生成并存储在 Fields Database (FDB) 中的大约 70% 数据在产品生成的时间关键 (time-critical) 窗口期间被回读。 这会导致文件系统争用并导致数值模型变慢。
我们计划通过采用作为 MAESTRO 项目 一部分开发的 MultIO 软件栈来实现就地后处理,我们将通过试验 GPU 加速后处理来有效利用异构计算资源。 这将通过减少不必要的数据移动来改善端到端的运行时间。
全球尺度 NWP 模型生成的数据将被存储并提供给工作流中的下游应用程序。 ECMWF 将使用 FDB 来解决这个问题。 FDB 是一个领域特定对象存储,它根据语义元数据有效地存储和索引 NWP 输出。
虽然 FDB 的不同版本已经在业务中使用了几十年,但高分辨率预报 (5 公里或更高分辨率) 生成数据的数量和速度的增加以及硬件环境中异构性的增加需要对其进一步改进。 ECMWF 致力于改进 FDB 以充分利用 EuroHPC 计算资源上可用的多层数据存储,可能提供 non-volatile memory express (NVMe),SSD 和传统并行文件系统的组合。
ACROSS 基础设施将为大规模测试此类新技术提供宝贵的机会,并将支持 ECMWF 战略。 此外,ECMWF 在博洛尼亚的新数据中心和 CINECA Leonardo pre-exascale 超级计算机将并排在新的博洛尼亚 Technopole 中。 我们真的很期待受益于这种密切关系将为 ACROSS 和 Destination Earth 带来的协同效应,这将利用 Leonardo 作为主要计算资源之一。
ACROSS 项目内的创新不仅限于气象领域;通过与 MPI 和 DKRZ 合作,我们正在为在 ICON 数值模式中使用 FDB 做出贡献,该模型被 MPI 用于气候模拟。 这种共同努力将为气象和气候界之间更密切的合作以及在复杂的 ACROSS 工作流中不同模型之间更简单的数据交换铺平道路。 虽然我们一直与 MPI 和 DKRZ 保持着良好的合作,但我们希望新的 Bonn 基地将为更密切的合作和协作提供更多的机会。
讨论
本文给出了产品后处理方面可行的发展方向,即就地后处理并使用硬件加速 (GPU 等)。 结合 ACROSS 项目官网在 Weather, Climate, Hydrological and Farming 用例方面给出目标能更清晰地看到技术开发人员可以选择的研究方向:
- 通过利用硬件加速和数据流/对象存储技术来展示百亿级可扩展性,改进现有的全球数值天气预报、后处理和数据分发业务系统
- 通过集成使用领域特定对象存储的数据分发实现气候模拟的低延迟开发
- 开发和演示用户定义的原位 (in-situ) 数据处理环境。该系统将在数 PB 的气象和气候归档和数据流上实现 HPDA,以启用数据分析工作流,从而提高对数据的洞察力
总结一下,就是要研究如何能快速进行海量数据分析:
- 数据管理:领域特定的对象存储技术 (FDB)
- 数据处理;硬件加速的高效数据处理技术 (GPU)
- 访问策略:进行原位数据处理以减少数据移动 (MultIO 软件栈)
上述三项与我们正在开发的模式数据管理平台工作息息相关,也是我个人非常感兴趣的技术方向。
数据管理方面,我们目前的产品制作系统仅能对接本地数据文件,任务脚本与 GRIB 2 文件名紧耦合,非常不利于扩展。 数据平台虽然对 GRIB 2 文件的元数据进行索引,但尚未应用到实时业务系统中。 我们的业务系统流程正在经历从 HPC 向 HPC + Cloud 的转变,未来产品制作任务需要对接多种环境下的多种数据源。 我们可以延续在数据平台方面的工作,研发面向多层次硬件存储设备的对象存储技术,面向业务系统和科研用户对数据存储进行抽象,类似 ECMWF 的 MARS 库和 FDB 库。 用户无需关心数据保存在 HPC 的分布式存储中,还是保存在 NAS 二级存储,还是保存在 CMADaaS 提供的各项存储基础组件中,通过一个接口,数据平台后台服务会将需要的数据传递给用户。 当然这是一项长期的任务,在元数据、索引存储、数据存储、检索接口等多个方面都需要开展研发工作,也需要根据可用的基础设施环境来逐渐调整技术方案。
数据处理方面,我们仅有一个并行任务,即对模式原始输出生成的 MODELVAR 二进制文件进行计算诊断量并生成 GRIB 2 文件。 我正在使用 Dask 尝试现有后处理任务进行并行化改造,在 HPC 并行计算节点中执行后处理任务。 这篇文章中提到的使用 GPU 实现的高效数据处理技术也许是一个不错的研究方向。
访问策略方面,模式直接输出到内存文件系统中不是我所在部门的工作方向,不过我们可以参与其中,提供索引存储方案等组件。 甚至我们可以在模式保留输出文件的情况下,将后处理系统转码生成的 GRIB 2 文件加载到内存数据库中,提供后续产品制作任务使用。 重在开展研发工作,提前储备前沿技术,等待应用时机。
总之,需要时刻关注领域内发展方向,积极将新技术新方法引入到业务系统和研发工作中,努力做出创新性工作成果。
参考
原文:Advancing high-performance data management in the EuroHPC ACROSS project