论文阅读:收集监控分析超算中心的设施和系统数据
Collecting, Monitoring, and Analyzing Facility and Systems Data at the National Energy Research Scientific Computing Center
Elizabeth Bautista, Melissa Romanus, Thomas Davis, Cary Whitney, and Theodore Kubaska. 2019. Collecting, Monitoring, and Analyzing Facility and Systems Data at the National Energy Research Scientific Computing Center. In Proceedings of the 48th International Conference on Parallel Processing: Workshops (ICPP 2019). Association for Computing Machinery, New York, NY, USA, Article 10, 1–9. DOI: https://doi.org/10.1145/3339186.3339213
本文发表于 ICPP 2019 会议,介绍 NERSC 超算中心如何收集、监控、分析设施和系统的运行数据。
注:以下正文部分翻译自论文,并根据笔者个人理解有所删改整合
正文
需要在不影响业务的前提下,从异构和分布式的多种来源中以近实时的速度不间断地收集、存储和分析运行数据。 本文介绍用于超大规模运行数据收集的架构设计和实现,在 NERSC (National Energy Research Scientific Computing) 中被称为 OMNI (Operations Monitoring and Notification Infrastructure)。
利用 OMNI,设备和环境数据可以和机器指标、作业调度信息、网络错误和其他更多信息相关联。
介绍
挑战:
- 数据异构
- 数据量大
- 采集间隔不同
- 历史数据有用
需要集成式运行数据收集和分析基础设施:OMNI
OMNI 从多个来源检查流式时间序列数据:
- NERSC 的 HPC 系统
- 其他支撑计算基础设施
- 环境传感器
- 电力系统
- 更多其他信息
OMNI 构建在开源技术之上,例如使用 Elastic 工具栈,已保存两年运行数据共 125 TB。
设计
时间 (Time) 是运行数据的关键属性,因为计算环境可能在纳秒或微秒量级上变化。
时间序列运行数据示例:
- 环境 (例如温度,功率,湿度水平,微粒水平)
- 监控数据 (例如网速,延迟,丢包,利用率或监控文件系统的磁盘写入速度,I/O,CRC 错误)
- 事件数据 (例如系统日志,终端日志,硬件错误事件,电源事件,特别是有开始和结束时间的任何事件)
汇报频率取决于如下因素:
- 传感器或机器的个别属性
- 数据大小
- 是否需要连续监控
- 分析需要多快
某些系统默认不报告数据,必须由系统管理员进行检测。
OMNI 核心系统需求
可扩展 Scalability
数据收集基础设施必须支持:
- 增加新数据源
- 动态扩展以响应新需求
高可用 High-Availability
7x24 环境,随时可用。
可维护 Maintainability
系统维护人员必须能够在不影响来自各种来源数据流的情况下对系统的各个部分应用滚动补丁 (rolling patches)、升级 (upgrades)、热硬件交换 (warm hardware swaps) 等。
可使用 Usability
向不同用户提供,必须支持对数据的快速和便捷访问,用于分析,可视化和监控。
终身数据保留政策 Lifetime Data Retention Policy
必须以永久保存为目标来收集数据。
实现细节
OMNI 集群在设施中独立于其他任何系统,是通电后第一个可用的系统,也是断电前最后一个关停的系统。
OMNI 使用开源软件,按需硬件和虚拟化技术实现。
- 开源软件:避免供应商锁定,降低成本
- 虚拟机和容器:充分利用硬件,按需配置应用,降低硬件维护成本,允许配置高可用
选用技术
- 虚拟化:oVirt 和 Rancher
- 近实时数据检索和存储:Elastic Stack (Elasticsearch + Logstash + Kibana)
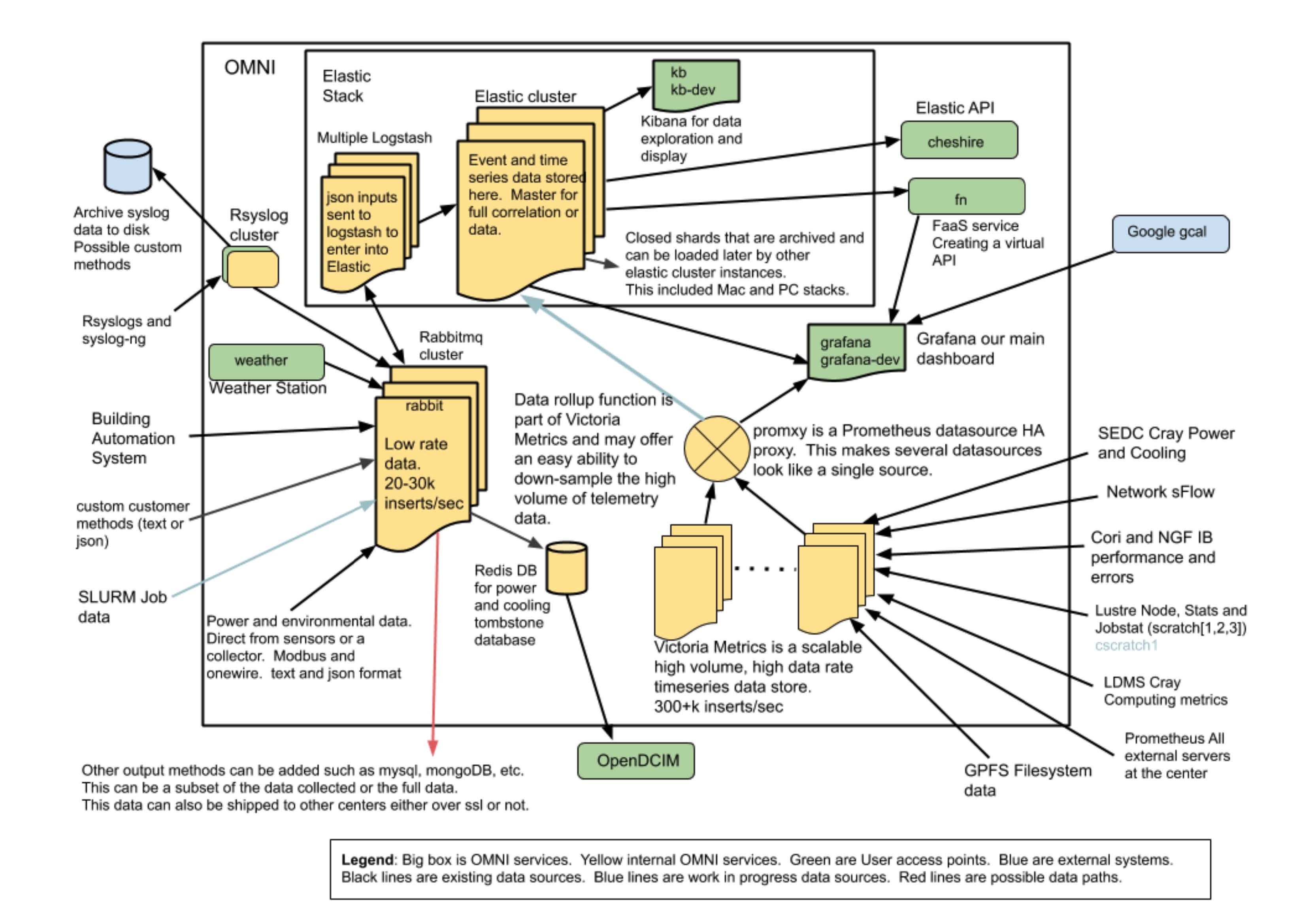
OMNI 集成运行数据收集和分析架构及数据源,图片来自论文
数据源
- 外部系统和传感器
- 继电器
- 水塔
- 关于空气和气候的天气和大气数据
- 从设施角度,包括建筑管理系统 (BACnet、Modbus),例如冷却水、空气处理单元、微粒计数器、机架门的温度和地震传感器,以及在断路器面板、配电单元 (PDU) 和不间断电源 (UPS) 的读数
- HPC 系统,包括
- Cray Power Management Database (PMDB)
- System Environment Data Collections (SEDC)
- Slurm 作业调度器中的作业信息
- Lustre 并行文件系统数据
- Areis 高速网络数据
- 突发缓冲区 (burst buffer, Cori)
- 其他网络信息,来自 sFlow, SNMP 和 InfiniBand 数据
- syslog 数据
收集的所有数据都将时间同步到本地层,即网络时间协议 (NTP) 服务器。
消息队列
使用 RabbitMQ,两种方式传输:
- 直接发送,如果格式合适
- 使用 collected 收集,使用 Logstash 解析,然后传入 RabbitMQ
不使用 Kafka 的原因:设计系统时 API 变化频繁。
存储
JSON 格式数据从 RabbitMQ 发送给 Logstash,再传给 ElasticSearch。
使用 RabbitMQ + Logstash + Elasticsearch 方式,OMNI 每秒处理 25,000 条消息。 未来计划使用 Victoria Metrics 将每秒消息量提高到 300,000 条。
可视化面板:Kibana
高可用:RabbitMQ 集群和 Elasticsearch 集群自带,数据存储多级策略 (hot and cold)
经验
集中数据在分析、关联、业务决策、容量规划、设施规划等方面具有潜力。
理念差异
运行数据,不只是环境数据
收集大量异构数据才能看到运行数据的真正潜力
多少和什么数据?
收集所有数据并永远保存,而不是收集特定数据只用于回答特定问题。 具有丰富历史时间线的综合数据集可以为洞察创造新的机会。
如果某个数据在任何地方被收集并从中获得洞察力,那么它应该存储在 OMNI 中。
将数据放置在一个集中位置的目的是使所有数据组能够一起分析、相互关联并一起用于回答复杂的问题。
谁来进行分析和关联?
团队经常被质疑:您从您的收集中获得了哪些新见解? 作者认为,系统管理员的专长在于获取数据集、数据存储和可用性,而不是转为数据科学家。 团队提供文档、教程介绍如何访问、检索、分析和可视化这些数据。
增长和可扩展性
使用开源软件节省成本。 今天,付费产品中有一些功能很不错,但作者希望它们最终会作为另一个开源产品来解决。 目前,团队不会改变他们继续使用开源产品并保持灵活性以解决未来遇到的问题的决定。
总结
未来扩展:
- 存储从 SATA 换为 NVME (non-volatile memory express)
- 使用 Prometheus 替换 collected
- 使用 Kubernetes 管理容器
- 将吞吐量增加到 100k/second 或更多,可能绕过 RabbitMQ 并直接将数据流发送到 Victoria Metrics。 这个极快的时间序列数据库对于长期存储来说效率更高,并且可以直接从 Prometheus 中摄取数据。
增加新数据源,例如 Lightweight Distributed Metric Service (LDMS) 数据。
OMNI 作用:
- NERSC 管理层:为月度报告提供数据
- 运行团队:提供实时数据用于日常决策
- 研究小组:提供新视野,如何提高性能、使用率,获取相关信息
参考文献
[13] Victoria 2019. Victoria. (2019). Retrieved June 6, 2019 from https://victoriametrics.com/
讨论
文中提到对监控系统的几个需求:
可扩展:架构便于添加新监控对象,监控系统本身支持动态扩容。
高可用:任何时候都必须可用。
可维护:方便团队维护开发。
注:当前我们将整个监控系统通过工程项目交给公司实现,而公司使用我们完全没有能力维护的 Java 技术栈,这种模式不可持续。 当然笔者负主要责任,技术把控不过关。
可使用:运行数据必须支持用户访问,能为用户的研发工作带来收益。 仅在运维团队内部使用数据无法充分发挥数据价值,也不能给研发人员带来全新的洞见。 文中方式值得借鉴,编写文档、教程,提供 API 接口,帮助用户使用运行数据。
永久保存:运行数据必须长久保存。只有长时间序列的数据才能持续发挥价值。
运行数据最本质的特征就是 时间,运行数据分析也就是 时间序列数据分析。 文中更多涉及对硬件环境和操作系统层面的数据进行监控,给出的示例也都来自硬件监控所带来的效益。
笔者仅从事应用系统维护,也就是数值天气预报业务系统的运维。 从最近流传的风声来看,后续依然很难接触到系统和硬件层面的运行数据。 不过随着业务系统逐步引入云计算技术,NWP 运维岗位可能会转变为要求更高的 SRE 工程师,需要更多涉及系统底层架构的开发和维护。
笔者开发过的两个项目与本文类似:
- HPC 用户级监控:收集磁盘信息和队列空闲节点,使用 Prometheus 保存时间序列数据,使用 Grafana 时间可视化。 参考 nwpc-oper/nwpc-hpc-exporter 项目。
- 业务系统消息平台:业务系统主动发送产品消息,使用 RabbitMQ / Kafka 作为消息中间件,使用 ElasticSearch 保存数据。 参考技术报告《基于消息通讯的数值预报业务系统运行监视和分析技术研发》。
随着气象大数据云平台 (CMADaaS) 逐渐在业务系统构建中占据核心地位,系统工程师也会面临对发展方向的抉择:是加入还是加入? 全新的平台会带来新的机遇与挑战,就看能否适应环境的变化。
参考
论文:
https://dl.acm.org/doi/10.1145/3339186.3339213
相关文章: