论文阅读:探索数据分析工具 DataPrep.EDA
DataPrep.EDA: Task-Centric Exploratory Data Analysis for Statistical Modeling in Python
Peng J, Wu W, Lockhart B, et al. DataPrep. EDA: Task-Centric Exploratory Data Analysis for Statistical Modeling in Python[C] //Proceedings of the 2021 International Conference on Management of Data. 2021: 2271-2280.
本文介绍用于探索性数据分析 (EDA) 的 Python 库 DataPrep.EDA。 我很少进行探索性数据分析,阅读这篇文章主要用来借鉴数据处理/分析库的设计思想和实现方式。
正文
设计理念
对于统计模型,探索性数据分析通常分解为多个任务,本文关注如下三种:
- 理解单个变量 (univariate analysis)
- 理解两个随机变量之间的关系 (bivariate analysis)
- 了解缺失值的影响 (missing value analysis)
DataPrep.EDA 使用以任务为中心的方法,实现三个设计目标:
- 方便使用:每个 EDA 任务对应一个函数调用,类似调用单个函数就可以绘制一张图片 (
xarray.DataArray.plot)。 根据数据内容自动进行分析和绘图。 - 交互速度:避免无关计算,使用Dask加速,可以用于交互分析
- 方便定制:提供通用参数和并在结果中显示指南
三个库的对比
| Pandas + Plotting | Pandas-profiling | DataPrep.EDA | |
|---|---|---|---|
| 方便使用 | ❌ | ✔️ | ✔️ |
| 交互速度 | ✔️ | ❌ | ✔️ |
| 方便定制 | ✔️ | ❌ | ✔️ |
以任务为中心
统计模型的通用 EDA 任务
本文定义 5 个通用 EDA 任务
概览 (Overview):基本统计指标,简单图形
相关分析 (Correlation Analysis):相关矩阵
缺失值分析 (Missing Value Analysis):图形
单变量分析 (Univariate Analysis):指标,图形 (箱线图,Q-Q 图)
双变量分析 (Bivariate Analysis):图形 (散点图,hexbin 图)
未来会实现的任务:时间序列分析,多变量分析
对比 esmvalcore 中的数据处理操作步骤
以任务为中心的 API 设计
将 简单性 (simplicity) 和 一致性 (consistency) 作为 API 设计的原则
API 形式
plot_tasktype(df, col_list, config)
其中
tasktype:任务具体描述df:数据框col_list:列名称config:配置参数
设计三个函数支持上节的 5 个任务
plot:根据不同参数执行不同任务
plot(df):概览plot(df, col_1):单变量分析plot(df, col_1, col_2):双变量分析
plot_correlation:相关分析任务
plot_correlation(df):数据集的相关分析plot_correlation(df, col_1):col1 列与其他列的相关分析plot_correlation(df, col_1, col_2):col1 列与 col2 列的相关分析
plot_missing:缺失值分析
plot_missing(df):数据集缺失值分析plot_missing(df, col_1):移除 col1 列缺失值对其他列的影响plot_missing(df, col_1, col_2):移除 col1 列缺失值对 col2 列的影响
对于不同类型的数据列需要计算的指标和绘制的图形,DataPrep.EDA 根据现有论文和工具,预定义一系列映射规则。
系统架构
前端用户界面
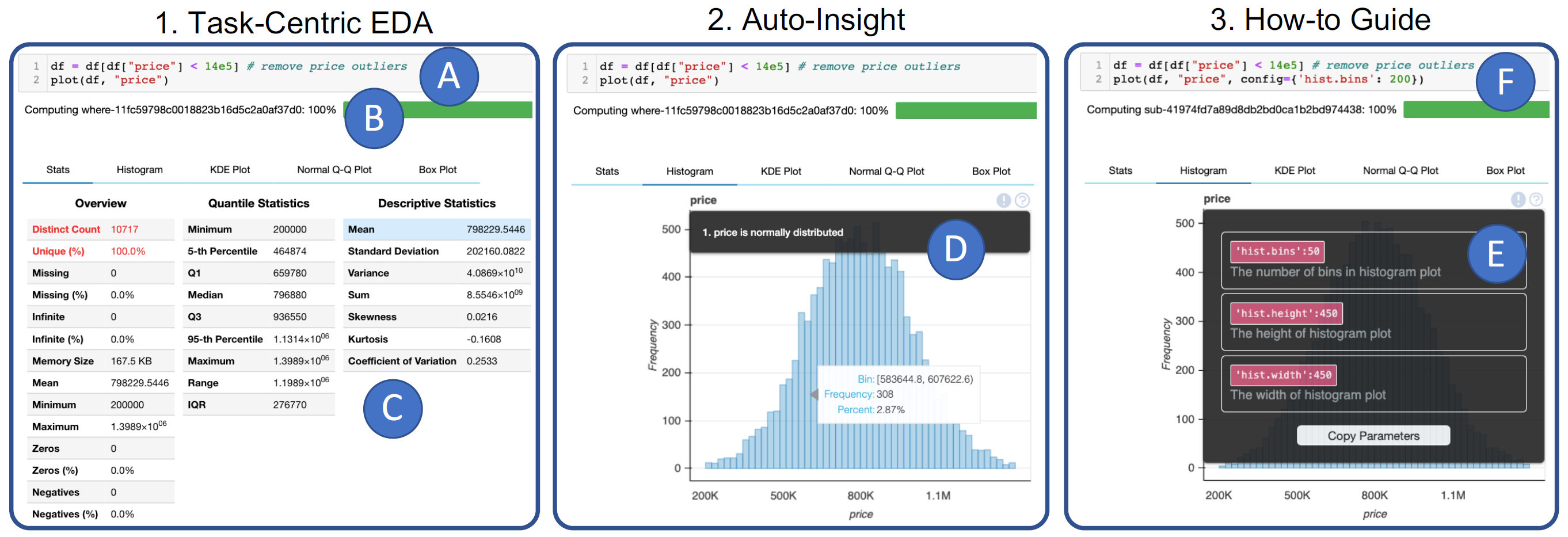
DataPrep.EDA 前端,图片来自论文
A:代码
B:计算执行进度 (Dask)
C:默认统计标签页
D:绘图结果,显示 insight
E:显示参数指南
F:设置参数 config
后端系统架构
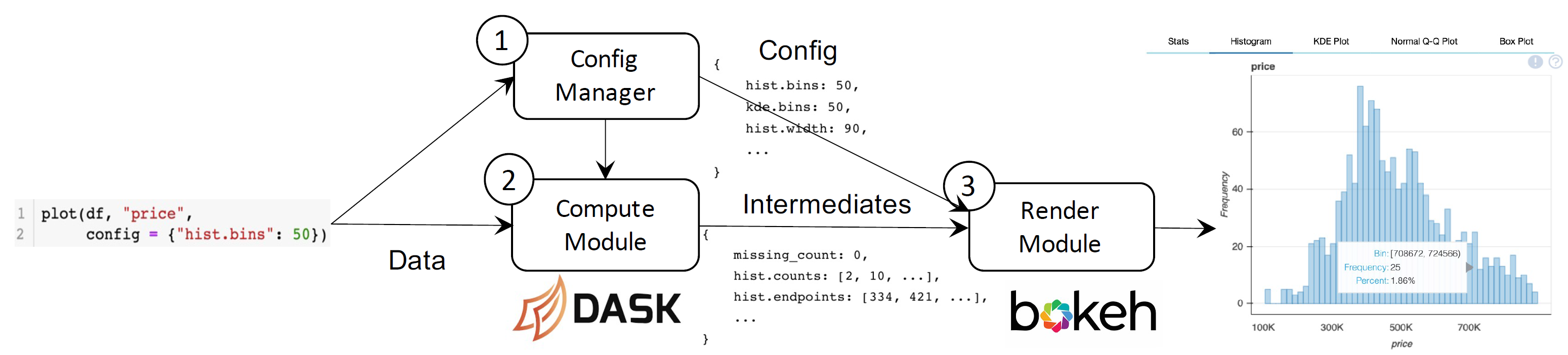
后端由三个组件构成:
- 配置管理器 Config Manager:设置所有可配置的参数,比如可视化类型、insight 阈值、可视化定制参数等
- 计算模块 Compute module:以
data和config为参数,生成用于可视化的intermediates,并计算 insights。 使用两种加速方法:共享结果;Dask 并行计算 - 渲染模块 Render module:将
intermediates转为数据可视化。使用 Bokeh 实现可视化,嵌入到自定义的 HTML/JS 布局。
计算与渲染分离的优点:
- 可以共享中间结果
- 用户可以获得中间结果
并行实现
为什么使用 Dask?
Dask 中计算是延迟的。首先创建计算图,优化计算图以减少计算量,最后才执行实际的计算
- 轻量级,单节点环境下也很快
- 可扩展到集群中
- 可以通过延迟评估优化多可视化需要的计算
性能优化
目标:将所有计算放入一个计算图中,让 Dask 移除重复计算。
方法:将所有计算改为延迟计算,最后才执行实际的计算
需要的几个问题:
无法构建 Dask 图:rechunk 无法合并到计算图中,DataPrep.EDA 预先计算 chunk size 信息,并传递给计算图
Dask 在小数据集上很慢:将计算分为 Dask Computation 和 Pandas Computation 两部分。 当前使用启发式决定两者边界,后续会研究自动分拆两个计算部分。
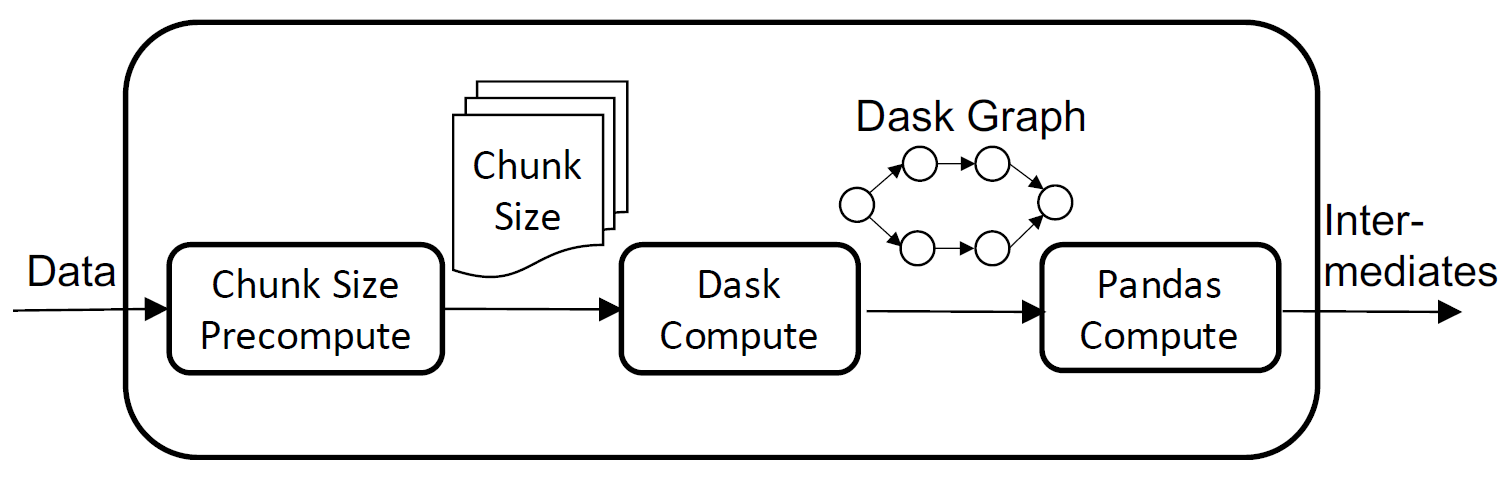
上图展示计算模块的数据处理管道,图片来自论文
对比试验
性能评估
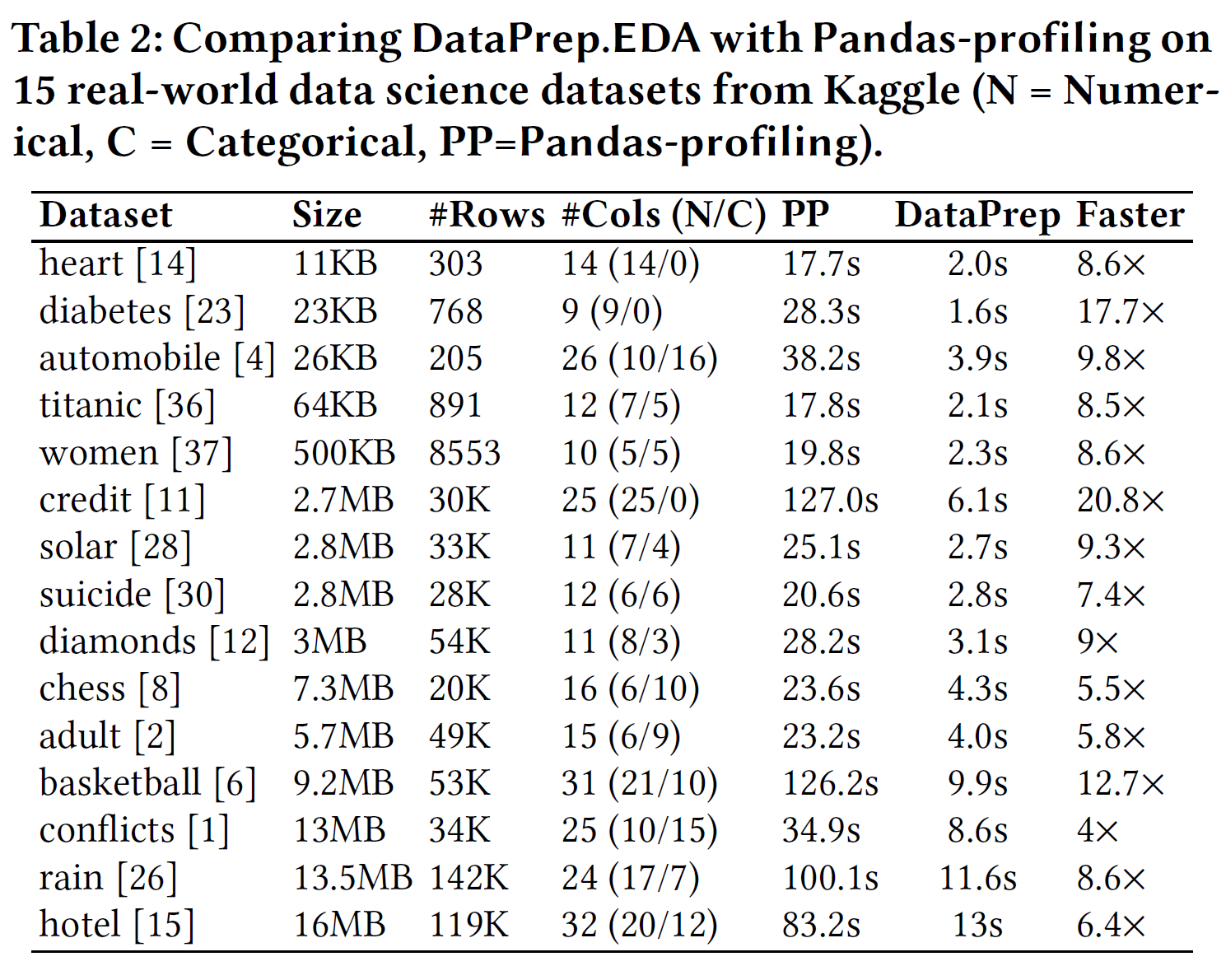
15 个数据集中的对比,图片来自论文
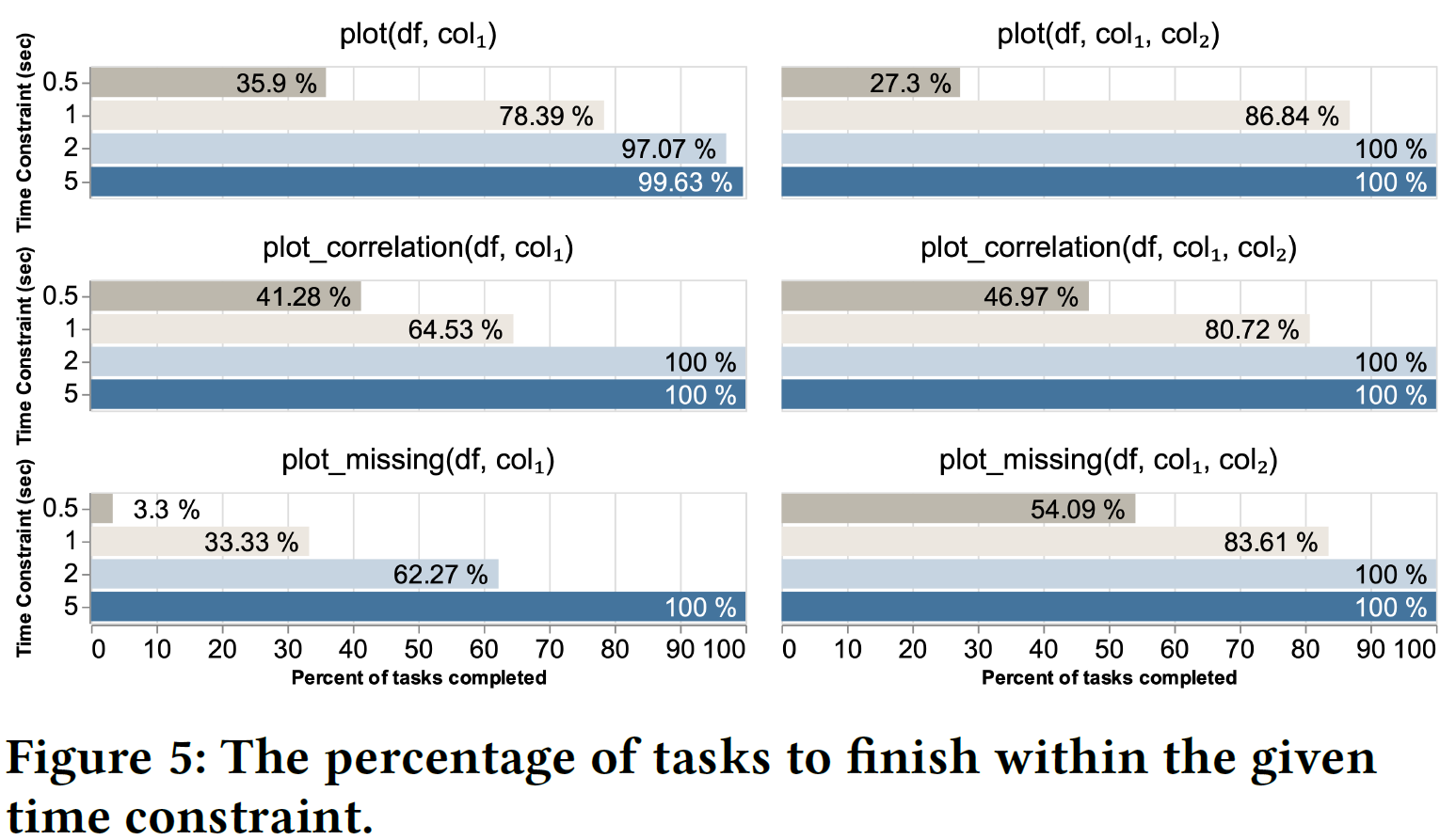
交互效率,图片来自论文
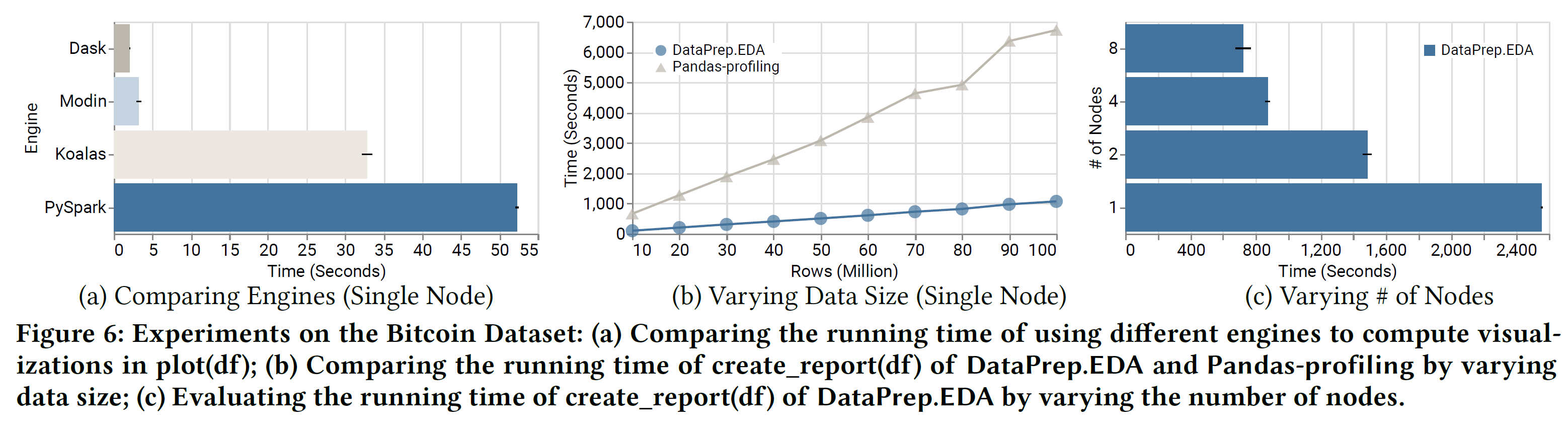
大数据集测试,图片来自论文,包括
- 不同并行库
- 数据大小
- 节点数
讨论
虽然 DataPrep.EDA 工具提供的探索性数据分析功能对我来说不常用,但该工具体现的设计思想和实现方式非常适合我正在开发的数据获取、数据分析、图形绘制等工具库。
开发工具库的目标
本文最值得借鉴的一点就是开发工具库的目标:
- 提供方便使用的 API 接口,用户可以用最少量的代码实现复杂的功能
- 提供可以用于交互分析的工具,提高数据处理效率
- 提供扩展接口和配置选项,用户可以定制工具中的各个组件
API 接口设计
本文采用以任务为中心的 API 接口设计,从用户实际需求出发,将 EDA 分解成几类基本任务,提供简单明了的函数接口。
所有函数均使用一致的参数选项,同时将复杂的配置隐藏在工具内部,用户仅在有需要时才在 config 参数设置配置选项。
架构设计
本文第三个值得借鉴的部分就是工具库的架构设计。 整个架构分为前后两端。
前端提供简化的 API 接口,面向 Jupyter Notebook 使用 HTML/JS 实现的面板,使用 Bokeh 实现数据可视化。
后端分成配置、计算和渲染三部分,共同完成数据分析操作。 计算部分使用 Dask 实现,并行处理部分隐藏在工具库内部实现,用户无需关注底层实现方式,仅需调用简单的 API 接口。
我正在开发的数据处理库也考虑提供基于 Dask 的分布式处理功能,可以参考 DataPrep.EDA 的实现方式,将并行部分隐藏在工具库内部,为一般用户提供简单的任务函数自动完成数据处理操作,同时也为深度用户提供更底层的操作函数。
参考
论文地址:
https://arxiv.org/abs/2104.00841
官方网站:
项目地址:
