一种封装CMADaaS MUSIC Python接口的方法
本文介绍如何封装 CMADaaS MUSIC 的 Python SDK,提供更高层的数据检索 API 接口,将尽可能多的数据检索接口整合到少量的 Python 函数中。
背景
前期工作
我在 2019 年写过一篇文章《改造CIMISS MUSIC接口的Python SDK》,文中指出当时该 SDK 存在的两个问题:不支持 Python 3;密码明文传输。
最近才发现在 2020 年的更新版本中,MUSIC Python SDK 已完全解决这两个问题:发布支持 Python 3 的版本,并将密码替换为由一系列字符串计算得到的 MD5 值。 所以非常有必要对之前随意下的结论进行反思和纠正,尤其是对于频繁更新的软件库而言。
本文介绍我最近正在进行的一些尝试,对 2019 年改造的 MUSIC SDK 库进行重新设计,提供更高层的数据检索 API 接口,将尽可能多的数据检索接口整合到少量的 Python 函数中。
该项目还在开发当中,仅针对感兴趣的资料,目标也不是覆盖全部检索接口。 另外,因账户权限问题,缺乏部分资料的访问权限,无法测试部分接口。
MUSIC 接口简介
CMADaaS 的 MUSIC 接口设计符合 2019 年 3 月发布的由 NMIC 制定的《气象数据服务接口规范(征求意见稿)》。
来自上述接口规范文件中的几个接口定义示例:
| 接口 | 用途 | 类型 |
|---|---|---|
getSurfEleByTime | 指定时间的地面资料检索接口 | 站点资料读取接口 |
getUparEleInRectByTimeAndVertical | 指定时间、垂直探测意义、经纬度范围的高空资料检索接口 | 站点资料读取接口 |
getTyphByTimeRangeAndTyphGids | 指定时间段、台风编号(国际)的检索台风资料接口 | 站点资料读取接口 |
getNafpEleGridByTimeAndLevelAndValidtime | 指定时间、预报层次、预报时效的单场单要素检索接口 | 数值格点资料解析接口 |
getNafpEleAtPointByTimeAndLevelAndValidtimeRange | 指定时间范围、预报层次、预报时段、经纬度的时间序列检索接口 | 数值格点资料解析接口 |
getRadaFileByTimeRange | 指定时间段的雷达资料检索接口 | 文件类资料读取接口 |
getSateFileByTime | 指定时间的卫星资料文件检索接口 | 文件类资料读取接口 |
getNafpFileByElementAndTime | 指定时间、预报要素的数值预报文件读取检索接口 | 文件类资料读取接口 |
接口定义由 3 部分组成:
- 接口名称
- 接口参数
- 返回码与数据格式
这里我主要关注数据检索接口的命名规则:
{接口功能}{资料类型}{数据内容}{主要条件}
上述接口示例可以拆解成 4 个部分,如下图所示:
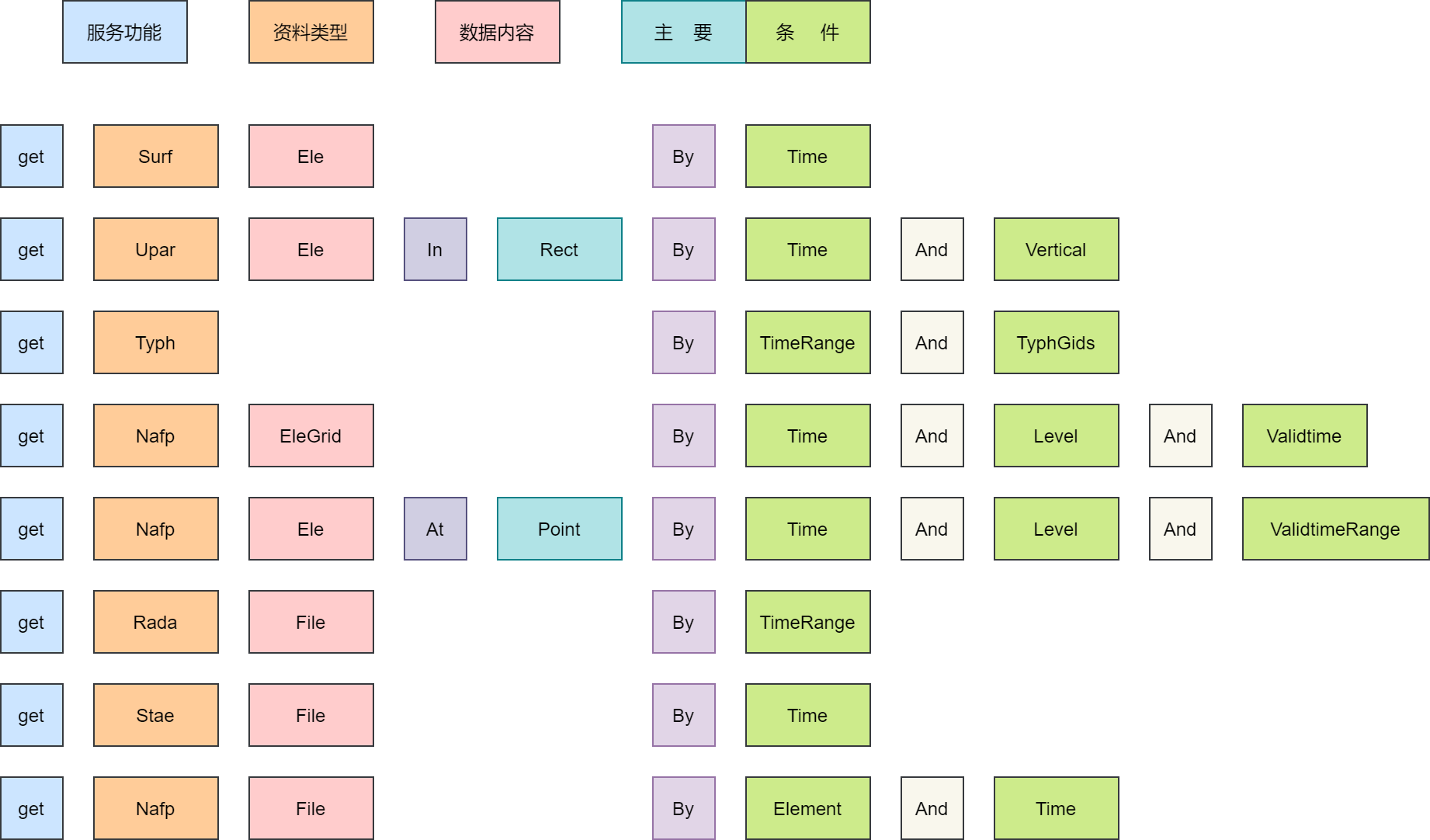
CMADaaS MUSIC 接口可以拆解为 4 个部分:服务功能,资料类型,数据内容和主要条件。
服务功能
服务功能字段取值:
get:检索stat:统计
资料类型
资料类型字段取值(参考行业标准 QX/T 102-2009 “气象资料分类与编码”):
Surf:地面资料Upar:高空资料Ocen:海洋资料Radi:辐射资料Agme:农气资料Cawn:大气成分Nafp:数值预报Disa:灾害资料Rada:雷达资料Sate:卫星资料Sevp:服务产品Othe:其他
数据内容
数据内容字段取值(部分):
Ele:要素File:文件
注:笔者另外还遇见
EleGrid的数据内容字段,获取格点要素场。
主要条件
主要条件:{By|In|Of}{参数名},多个以 And 连接。
注:笔者目前只遇到
By和In,另外还有At。
相关项目
NMC 已开源一系列用于诊断分析的 Python 项目,其中有两个项目内置对 CMADaaS 的支持:
- 气象数据读写及访问程序库 nmcdev/nmc_met_io
- 全流程检验程序库 nmcdev/meteva
注:下面示例使用 2021.4.20 从 GITHUB 中拉取的项目代码,不排除未来接口有变动。
nmc_met_io
nmc_met_io 使用返回 JSON 格式数据的接口,从 CMADaaS 中检索数据,并保存到 pd.DataFrame 和 xr.Dataset 中。
例如下面的代码检索 2021 年 4 月 19 日 00:00 时刻 54511 站的温度值:
>>> from nmc_met_io.retrieve_cmadaas import cmadaas_obs_by_time_and_id
>>> data = cmadaas_obs_by_time_and_id(
... "20210419000000",
... elements="Station_Id_C,Datetime,TEM",
... sta_ids="54511"
... )
>>> data
Station_Id_C Datetime TEM
0 54511 2021-04-19 16
elements 参数中设定的要素名称列表构成返回结果中的列。
meteva
meteva 同样使用返回 JSON 格式数据的接口,并使用 pandas 和 xarray 的数据结构。
检索和上面示例一样的数据:
>>> import pandas as pd
>>> from meteva import base as mb
>>> mb.io.set_io_config("~/.config/.nmcdev/config.ini")
>>> data = mb.io.read_stadata_from_cmadaas(
... dataCode="SURF_CHN_MUL_HOR_N",
... element="TEM",
... time=pd.to_datetime("2021-04-19 00:00"),
... station=pd.DataFrame({
... "id": [54511]
... })
... )
>>> data
level time dtime ... lon lat SURF_CHN_MUL_HOR_N
0 0 2021-04-19 00:00:00 0 ... 116.466698 39.799999 16.0
[1 rows x 7 columns]
与 nmc_met_io 不同的是,meteva 返回值针对站点数据进行一定的包装 (sta_data() 函数),返回结果包含更多维度信息。
上述两个库设计的检索 API 接口有诸多相似之处:
- 使用方便理解的函数封装 MUSIC 数据检索接口,将诸如
getSurfEleByTimeAndStaID等略显复杂的检索接口隐藏在 API 内部 - 通过带默认值的函数参数设置检索条件,而不是如 MUSIC Python SDK 中一样放到
dict结构中 - 使用 Python 生态系统中的常见科学库表示返回结果,例如使用 pandas 表示表格数据,使用 xarray 表示格点数据
- 隐藏配置信息,将账户、密码、服务器信息等配置项目放在统一路径的配置文件中,函数会直接从默认路径中读取配置信息
nuwe-cmadaas-python
另外可以对比下我开发的 nuwe-cmadaas-python 库中检索数据的 API 接口,与 MUSIC Python SDK 原生接口基本保持一致。
from nuwe_cmadaas.music import CMADaaSClient
client_config_path = "path/to/client/config/file"
user = "user name"
password = "user password"
server_id = "server id"
interface_id = "getSurfEleByTimeRange"
params = {
"dataCode": "SURF_CHN_MUL_HOR",
"elements": "Station_Id_d,Lat,Lon,Alti,Day,Hour,PRS_Sea,TEM,"
"DPT,WIN_D_INST,WIN_S_INST,PRE_1h,PRE_6h,PRE_24h,PRS",
"timeRange": "[20190817000000,20190817020000)",
"orderby": "Station_ID_d:ASC",
"limitCnt": "10",
}
client = CMADaaSClient(
user=user,
password=password,
config_file=client_config_path
)
result = client.callAPI_to_array2D(interface_id, params)
返回结果是自定义类 Array2D,其中 data 成员变量是 numpy 数组。
设计
下面介绍封装 CMADaaS MUSIC Python SDK 的设计方案,以提供更高层的数据检索 API 接口。
封装原则
封装 API 的核心目标:使用单一 API 提供尽可能多的检索手段
封装原则:
- 检索条件由参数指定,为参数设计默认值,不同参数组合对应不同的检索接口
- 使用常见的数据结构,尽量避免自行设计新对象
- 返回 pandas 和 xarray 对象
- 隐藏账户密码等配置信息,但允许用户手动指定
- 用尽可能少的函数实现需要的检索接口
接口设计
参考 nmc_met_io 和 meteva 项目中的接口设计。
整合检索接口,函数参数支持多种类型,对应不同的检索接口。
大部分参数都使用 None 作为默认值。
以检索站点数据的函数接口为例进行说明:
def retrieve_obs_station(
data_code: str = "SURF_CHN_MUL_HOR",
elements: str = None,
time: typing.Union[pd.Interval, pd.Timestamp, typing.List, pd.Timedelta] = None,
station: typing.Union[str, typing.List, typing.Tuple] = None,
region=None,
station_level: typing.Union[str, typing.List[str]] = None,
order: str = "Station_ID_d:asc",
count: int = None,
config_file: typing.Union[str, Path] = None,
**kwargs,
) -> pd.DataFrame:
pass
返回值是 pd.DataFrame 对象
其中 data_code 是资料代码,检索条件如下:
time: 时间筛选条件,支持单个时间,时间列表,时间段和时间间隔- 时间对象:
pd.Timestamp类型,单个时间点,对应接口的 times 参数 - 时间列表:
typing.List[pd.Timestamp]类型,多个时间列表,对应接口的 times 参数 - 时间段:
pd.Interval类型,起止时间,定义区间端点是否闭合,对应接口的 timeRange 参数 - 时间间隔:
pd.Timedelta类型,用于获取地面资料最新时次 (getSurfLatestTime),忽略其余筛选条件
- 时间对象:
station: 站点筛选条件,支持字符串,列表和元组- 字符串:单个站点
- 列表:多个站点
- 元组:站点范围,二元组,第一个元素是起止站号 (
minStaId),第二个元素是终止站号 (maxStaId)
region: 区域筛选条件- 经纬度范围 (
rect) - 流域 (
basin) - 地区 (
region)
- 经纬度范围 (
station_level: 台站级别011: 国家基准气候站012: 基本气象站013: 一般气象站
order: 排序字段count: 最大返回记录数,对应接口的 limitCnt 参数config_file: 配置文件路径kwargs: 其他需要传递给 MUSIC 接口的参数,例如:eleValueRanges: 要素值范围hourSeparate: 小时取整条件minSeparate: 分钟取整条件
检索格点要素场的接口有类似的参数:
def retrieve_obs_grid(
data_code: str,
parameter: str = None,
time: typing.Union[pd.Interval, pd.Timestamp, typing.List, pd.Timedelta] = None,
station: typing.Union[str, typing.List, typing.Tuple] = None,
region=None,
station_level: typing.Union[str, typing.List[str]] = None,
order: str = None,
count: int = None,
config_file: typing.Union[str, Path] = None,
**kwargs,
) -> xr.DataArray:
pass
返回值是 xr.DataArray 对象,唯一区别是使用 parameter 代替 element 参数
下载站点观测文件的接口也类似:
def download_obs_file(
data_code: str,
elements: str = None,
time: typing.Union[pd.Interval, pd.Timestamp, typing.List, pd.Timedelta] = None,
station: typing.Union[str, typing.List, typing.Tuple] = None,
region=None,
station_level: typing.Union[str, typing.List[str]] = None,
order: str = None,
count: int = None,
output_dir: str = "./",
interface_data_type ="Surf",
config_file: typing.Union[str, Path] = None,
**kwargs,
):
pass
对比上面接口增加两个参数:
output_dir:输出目录,默认为当前目录interface_data_type:数据类型,默认为地面观测数据 (Surf),为增强扩展性而添加的内部参数,一般无需用户设置。
实现
下面介绍实现上述接口设计所使用的一些关键技术。
动态类型参数
利用 Python 动态类型的特性,让参数支持不同的数据类型,提供不同的检索条件。
以时间条件 time 为例说明,时间条件可以有三种设置方式,使用不同的数据结构表示:
- 时间点或时间点列表
- 时间段
- 时间间隔
使用 Python 的 isinstance() 函数结合 typing 模块判断参数类型,进行相应处理。
if isinstance(time, pd.Interval):
# 时间段
interface_config["time"] = "TimeRange"
pass
elif isinstance(time, pd.Timestamp):
# 时间点
interface_config["time"] = "Time"
pass
elif isinstance(time, typing.List):
# 时间列表
interface_config["time"] = "Time"
pass
elif isinstance(time, pd.Timedelta):
# 时间间隔,用于获取最新时次
interface_config["name"] = "getSurfLatestTime"
pass
拼接检索接口
根据设置的检索条件动态拼接检索接口。
interface_config 变量保存接口名称各项组成部分
name:接口前缀region:区域条件time:时间条件station:站点条件
interface_config = {
"name": "getSurfEle",
"region": None,
"time": None,
"station": None,
}
上一节代码已显示如何在判断参数类型时配置接口的 time 部分,其余部分也类似。
所有参数都解析后,生成检索接口。
name 直接作为前缀
interface_id = interface_config["name"]
设置 region 时,添加 In + region 值
region_part = interface_config["region"]
if region_part is not None:
interface_id += "In" + region_part
用 And 合并 time 和 station 名称,在前面加上 By
condition_part = "And".join(filter(None, [
interface_config["time"],
interface_config["station"]
]))
if "level" in interface_config and interface_config["level"] is not None:
condition_part = "And".join([condition_part, interface_config["level"]])
if len(condition_part) > 0:
interface_id += "By" + condition_part
部分自动生成的名称需要调整,使用单独的函数进行修改:
def _fix_interface_id(interface_id: str) -> str:
mapper = {
"getSurfEleByTimeRangeAndStaIdRange": "getSurfEleByTimeRangeAndStaIDRange"
}
return mapper.get(interface_id, interface_id)
形成最终的接口名称 interface_id。
返回值
MUSIC Python SDK 使用自定义的返回结果,用于装载 Protobuf 对象。 nuwe-cmadaas-python 项目底层沿用原 SDK 的数据接口,例如:
Array2D:表格数据GridArray2D:格点数据FileInfo:文件信息FilesInfo:文件信息列表GridVector2D:二维矢量格点数据
同时该项目为部分数据接口添加两个用于数据转换的函数:
to_pandas():转换为 pandas 数据to_xarray():转换为 xarray 数据
对于 Array2D 数据,将其转换为 pd.DataFrame:
def to_pandas(self) -> pd.DataFrame:
df = pd.DataFrame(self.data, columns=self.element_names)
return df
对于 GridArray2D 数据,将其转换为 xr.DataArray:
def to_xarray(self) -> xr.DataArray:
coords = {}
if len(self.lats) > 0:
lats = self.lats
else:
lats = np.linspace(
self.start_lat, self.end_lat, self.lat_count,
endpoint=True
)
if len(self.lons) > 0:
lons = self.lats
else:
lons = np.linspace(
self.start_lon, self.end_lon, self.lon_count,
endpoint=True
)
coords["latitude"] = xr.Variable(
"latitude",
lats,
attrs={
"units": "degrees_north",
"standard_name": "latitude",
"long_name": "latitude"
},
)
coords["longitude"] = xr.Variable(
"longitude",
lons,
attrs={
"units": "degrees_east",
"standard_name": "longitude",
"long_name": "longitude"
}
)
dims = ("latitude", "longitude")
field = xr.DataArray(
self.data,
dims=dims,
coords=coords,
attrs={
"units": self.units,
},
name=self.user_element_name,
)
return field
配置文件
仿照 nmc_met_io 库,将配置文件放在固定的路径中,默认情况下使用接口时无需额外指定配置文件。
在用户配置目录 ($USER/.config) 中创建 nwpc-data/config.yaml 配置文件,设置账号、密码等相关信息。
cmadaas:
auth:
user: user name
password: user password
server:
music_server: music server ip
music_port: music server port
music_connTimeout: 3 # connection time out, seconds
music_readTimeout: 3000 # read time out, seconds
music_ServiceId: music service id
函数内部会从多个来源加载配置文件:
- 已指定配置文件路径,则使用该文件
- 已设置
NWPC_OPER_CONFIG环境变量,则使用该变量值作为路径 - 否则将
$USER/.config/nwpc-data/config.yaml作为路径
def _get_cmadaas_config_path(file_path: typing.Optional[str] = None):
if file_path is None:
if "NWPC_OPER_CONFIG" in os.environ:
return os.environ["NWPC_OPER_CONFIG"]
path = pathlib.Path(pathlib.Path.home(), ".config/nwpc-oper/config.yaml")
return path
else:
return file_path
对原有接口的重新实现
根据 Python SDK 中的 protobuf 生成文件反推 protobuf 定义文件,生成新的 protobuf 生成文件。 仿照原有接口重新实现,将 Python 2 修改为 Python 3,将 pycurl 库替换为 windows 下更容易安装的 requests 库。
已在《改造CIMISS MUSIC接口的Python SDK》文章中详细描述,本文不再重复。
应用
接口示例
getSurfEleByTimeAndStaID
按时间、站号检索地面数据要素
与上面示例相同,检索 2021 年 4 月 19 日 00:00 时刻 54511 站的温度值:
>>> import pandas as pd
>>> from nuwe_cmadaas.obs import retrieve_obs_station
>>> table = retrieve_obs_station(
... "SURF_CHN_MUL_HOR",
... time=pd.to_datetime("2021-04-19 00:00:00"),
... elements="Station_Id_C,Datetime,TEM",
... station="54511",
... )
>>> table
Station_Id_C Datetime TEM
0 54511 2021-04-19 00:00:00 16
getUparEleByTimeRangeAndStaIDAndVerticalAndPress
按时间段、站号、垂直探测意义、气压层检索数据要素
from nuwe_cmadaas.obs import retrieve_obs_upper_air
retrieve_obs_upper_air(
"UPAR_GLB_MUL_FTM",
time=pd.Interval(
pd.to_datetime("2021-01-01 00:00:00"),
pd.to_datetime("2021-01-02 00:00:00"),
closed="left"
),
station=54511,
level_type=("vertical", "pl"),
level=(4096, 670),
)
getNafpEleAtPointByTimeAndLevelAndValidtimeRange
按起报时间、预报层次、预报时段、经纬度检索预报要素插值
from nuwe_cmadaas.model import retrieve_model_point
retrieve_model_point(
"NAFP_ECMF_C1D_GLB_FOR",
parameter="TEM",
start_time=pd.to_datetime("2021-01-01 00:00:00"),
forecast_time=("0h", "24h"),
level_type=1,
level=0,
point=[(9.93, 116.28), (44.57, 129.6)]
)
getNafpEleGridInRectByTimeAndLevelAndValidtime
按经纬范围、起报时间、预报层次、预报时效检索预报要素场
from nuwe_cmadaas.model import retrieve_model_grid
retrieve_model_grid(
"NAFP_ECMF_C1D_GLB_FOR",
parameter="TEM",
start_time=pd.to_datetime("2021-01-01 00:00:00"),
forecast_time="24h",
level_type=1,
level=0,
region={
"type": "rect",
"start_longitude": 70,
"end_longitude": 140,
"start_latitude": 55,
"end_latitude": 15,
}
)
getNafpFileByElementAndTimeAndLevelAndValidtime
按预报要素、起报时间、预报层次、预报时效检索数值预报文件
from nuwe_cmadaas.model import download_model_file
download_model_file(
"NAFP_FOR_FTM_GER_GLB",
parameter="TEM",
start_time=pd.to_datetime("2021-01-01 00:00:00"),
forecast_time="12h",
level_type="100",
level=850,
output_dir="./"
)
总结
前几年我不能理解为什么会将 MUSIC 接口设计得如此复杂,经过最近半个月的研究,才发现内在的逻辑性,也能感觉到设计人员的良苦用心,为了保证所有编程语言都使用几乎相同的接口而设计了一套合理可行的接口规范。 正如在“前期工作”中提到的,对于持续更新的工具库,一定不能随意下结论,要紧跟最新版本并时刻进行反思和纠正。 说不定自行二次开发的功能已在新版本中有更好更强大的替代品。
本文尝试利用 Python 语言动态类型的特征,将尽可能多的检索接口整合到单一 API 函数中,并使用常用的 Python 科学工具库 Pandas 和 Xarray 对检索结果进行包装,期望能在现有的多种工具库基础上提供另外一种使用 MUSIC 接口的方式。
目前本文项目正在开发中,暂时仅作为个人兴趣项目,没有应用场景。
一碗冷水
最后用刚看到的新一期技术雷达对本文这种 封装已有 API 提供新 API 的方式泼一碗 冷水。 想要保证项目有持久的生命力,就得有明确的目标,也需要保持频繁的更新。
以下内容来自由 ThoughtWorks, Inc. 出品的 Technology Radar Vol. 24
https://assets.thoughtworks.com/assets/technology-radar-vol-24-cn.pdf
自研基础设施即代码(IaC)产品
暂缓
那些由公司或社区所支持的(至少在业界引起关注的)产品,正在不断发展。 但有时组织会倾向于在现有的外部产品之上,构建框架或抽象,来满足组织内非常特定的需求,并认为这种适配会比其现有的外部产品具备更多好处。 我们发现一些组织试图基于现有外部产品,创建自研基础设施即代码(IaC)产品。 他们低估了根据其需求不断演进这些自研解决方案而所需投入的工作量。 很快他们就会意识到,所基于的外部产品的原始版本要比他们自己的产品好得多。 在有些情况下,构建在外部产品之上的抽象,甚至削弱了外部产品的原始功能。 虽然目睹过组织自研产品的一些成功案例,但是我们仍然建议要审慎地考虑这种方式。 因为这会带来不可忽视的工作量,并且需要确立长期的产品愿景,才能达到预期的结果。
参考
perillaroc/nuwe-cmadaas-python
NMC 开源 Python 库:
之前写的两篇文章:
