Cloud-WS 2021:数据工具库CliMetLab
本文正文部分来自 ECMWF 于 2021 年 2 月召开的 Virtual workshop: Weather and climate in the cloud (Cloud-WS 2021) 中的如下演讲:
Enabling machine learning for weather and climate data in the cloud
A Python package to support AI/ML activities in climate and meteorology
by Baudouin Raoult
at Cloud-WS 2021
CliMetLib:一个用于支持气候和气象学中的 AI/ML 研究的 Python 包
正文
注:笔者对演讲幻灯片中部分内容有修改和调整
概述
Jupyter Notebook
Jupyter Notebooks 中通常可以看到大量与 AI/ML 方法无关的代码:
- 获取数据
- 网络访问:wget,curl
- 解压:unzip,untar
- 解码数据
- GRIB
- NetCDF
- CSV
- …
- 修改绘图属性,使图像更好看
而与 AI/ML 相关的代码通常很少。
为什么选择 Python ?
当前已有大量 Python 工具库
社区软件包(基础库):
- Numpy:线性代数
- Pandas:统计
- Matplotlib:绘图
机器学习框架
- Keras
- Tensorflow
- PyTorch
- Scikit-learn
社区软件包(数据处理):
- NetCDF
- xarray
- cfgrib
ECMWF 软件包:
- ecCodes,odc,pybufr:GRIB,BUFR,ODB
- Magics:绘图
- webapi,cdsapi:数据获取
简介
使接口尽可能简化,让科学家可以专注 ML 算法
加载 ERA5 数据集中的 2m 温度数据
import climetlab as cml
# 加载数据
era5_data = cml.load_dataset(
"era5-temperature",
domain="France",
period=1980
)
# 绘图
cml.plot_map(
era5_data["1980-06-09 18:00"]
)
加载 NOAA 飓风数据集,选择特定数据,并绘图
import climetlab as cml
data = cml.load_dataset(
"hurricane-database",
"atlantic"
)
# 数据结构
irma = data.to_pandas(
name="irma",
year=2017
)
# 绘图
cml.plot_map(irma)
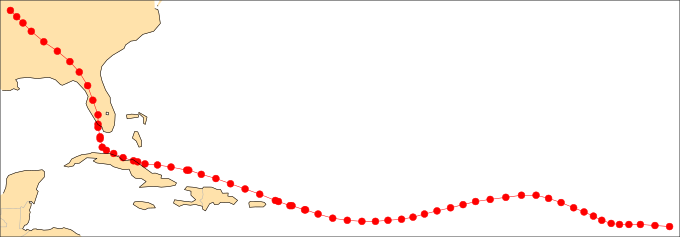
自动绘图,无需额外设置
目标
面向 Jupyter Notebooks。 Jupyter Notebook 的使用者越来越多,使用范围也越来越广。 ECMWF 也正在使用 JupyterLab。
旨在最小化样板代码 (boilerplate code)。
提供无缝数据访问和绘图
与主流科学 Python 软件包完全兼容
允许用户专注于科学问题,而不是编程
数据
数据生态系统
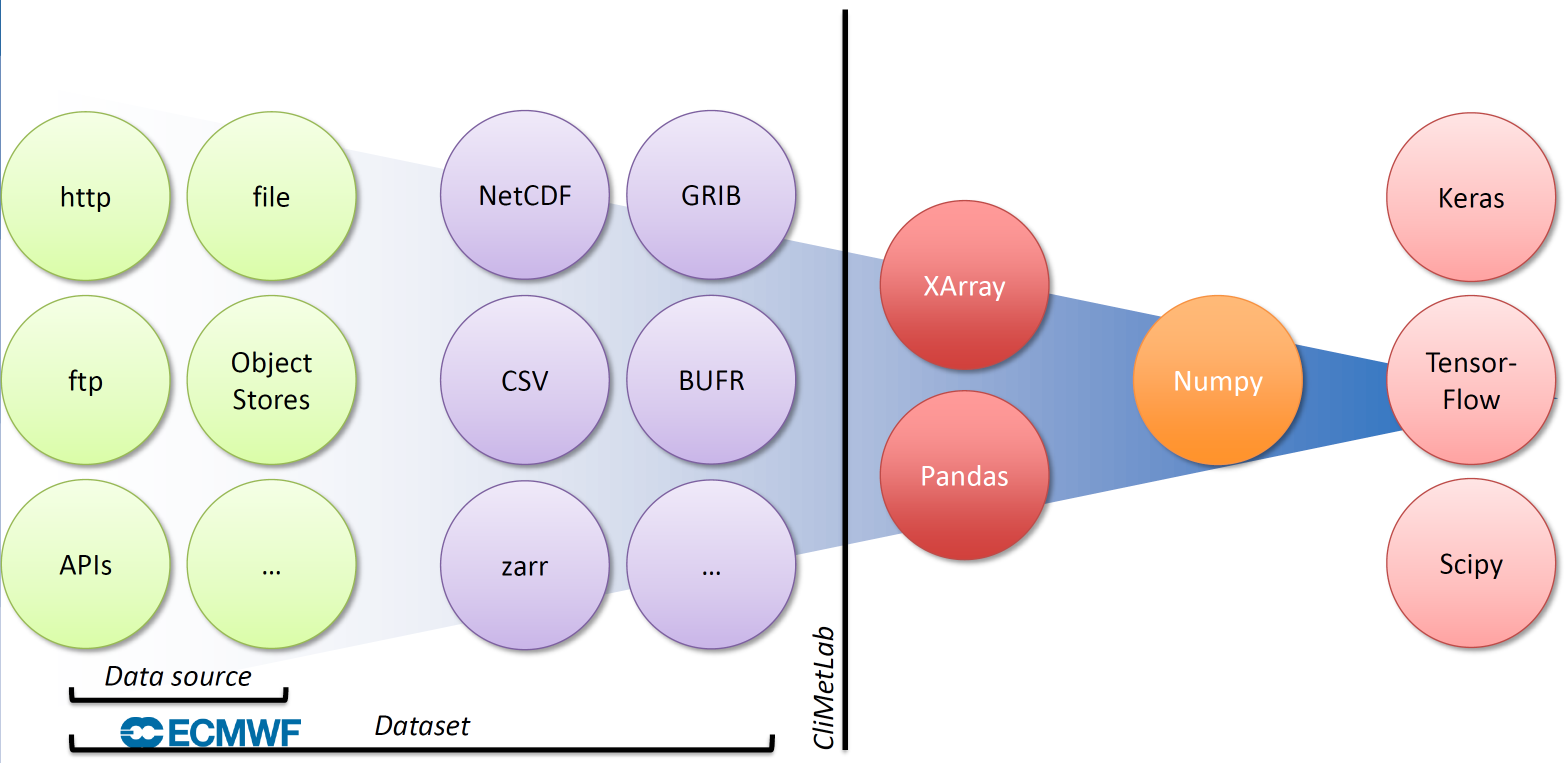 图片来自幻灯片
图片来自幻灯片
图片展示 CliMetLib 库在数据生态系统中的位置
绿色是数据源 (Data source),来源包括:
- HTTP
- 本地文件
- FTP
- 对象存储
- APIs
- …
绿色和紫色构成数据集 (Dataset),包含
- 如何获取数据,即数据源
- 数据格式
- NetCDF
- GRIB
- CSV
- BUFR
- zarr
- …
右侧是 Xarray 和 Pandas,提供设计良好的 API 接口,基于 Numpy 实现。
数据可以提供给机器学习库
- Keras
- TensorFlow
- PyTorch
- Scikit-learn
元数据
数据集除了包含数据源外,还包含 数据集元数据 (Dataset metadata):
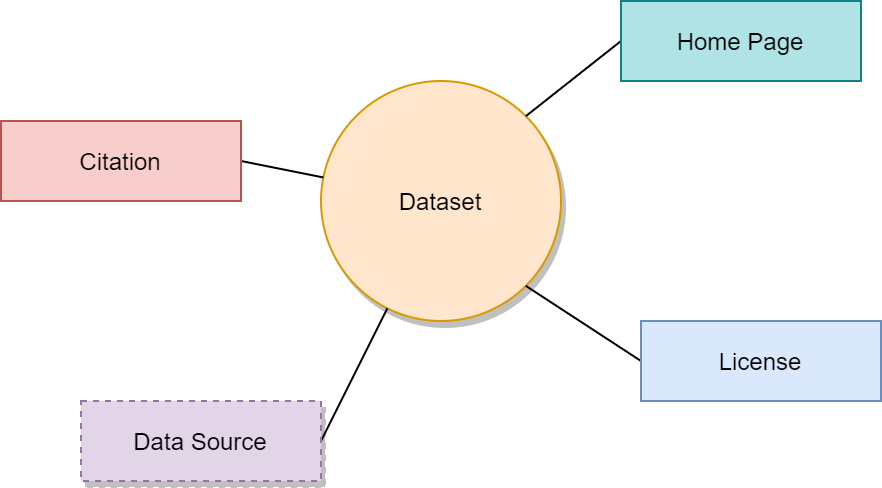
- 数据源 Data source
- 主页 Home page
- 引文 Citation
- 协议 Licence
数据源
- 本地文件
- URL
- ecmwf-webapi,访问 MARS 归档
- cdsapi,访问 Copernicus Climate Data Store
- zarr/s3fs (开发中)
- …
数据集
目前主要是概念证明
- WeatherBench
- Meteonet
- S2S AI/ML Competition (Upcoming, ECMWF/WMO)
- NOOA’s hurrican database
- 用户的数据集
- ….
目标:包含全部天气学/气候学领域的 AI/ML 参考数据集
功能
互通性
Interoperability
与 Python 科学库互通非常简单:
- 加载某个数据集
- 转换为相应的数据对象(xarray,pandas,numpy)
- 为 ML 库准备训练集和测试集
ds = cml.load_dataset("some-dataset")
xa = ds.to_xarray()
df = ds.to_pandas()
ar = ds.to_numpy()
(x_train, y_train), (x_test, y_test) = ds.load_data()
绘图
自动绘制二维地图
数据集知道如何最好地绘图
支持 GRIB,NetCDF,Xarray,Pandas 等
 图片来自幻灯片
图片来自幻灯片
函数
借用 Numpy,Pandas,Keras 等库中的广泛使用的方法名,方便用户使用。
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
ds = cml.load_dataset("high-low")
(x_train, y_train), (x_test, y_test) = ds.load_data()
插件结构
方便添加新内容
- 数据源
- 数据集
- 绘图样式
- 数据格式
示例
加载 Python 库
加载 CliMetLab 和 Tensorflow
import climetlab as cml
from tensorflow.keras.layers import (
Input,
Dense,
Flatten
)
from tensorflow.keras.models import Sequential
数据
加载带标签的数据集:High-Low 数据集
highlow = cml.load_dataset("high-low")
绘制数据集
for field, label in highlow.fields():
cml.plot_map(
field,
width=256,
title=highlow.title(label)
)
示例图形,每种标签各选择一个示例
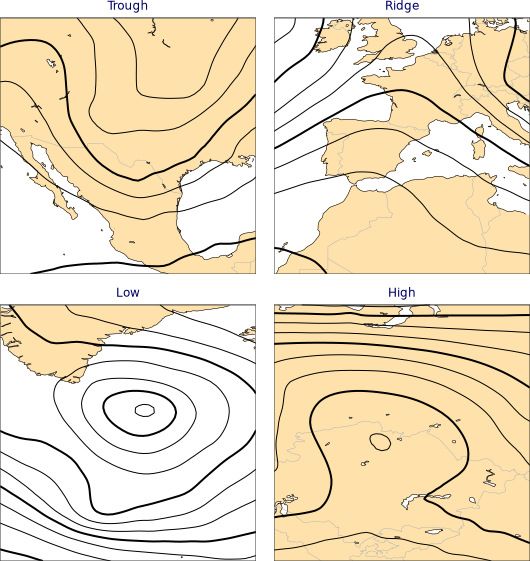
数据集中的每个条目由要素场和标签组成
field, label = highlow.fields()[0]
field 是 GRIB 要素场,包含 21x21 二维数组
field
GribField(z,500,19930408,1200,0,0)
label 是类别标签
label
(1.0, 0.0, 0.0, 0.0)
分割数据集
使用 load_data() 将数据集分为训练集和验证集
fields 参数用于保留带元数据的原始数据
(
(x_train, y_train, f_train),
(x_test, y_test, f_test)
) = highlow.load_data(
test_size=0.3,
fields=True
)
x_train 和 y_train 是用于机器学习库的 Numpy 数组,f_train 是 GribFiled 数组。
训练集有 25 个数据
x_train.shape, y_train.shape, len(f_train)
((25, 21, 21), (25, 4), 25)
测试集有 12 个数据
x_test.shape, y_test.shape, len(f_test)
((12, 21, 21), (12, 4), 12)
构建模型
创建三层模型
model = Sequential()
model.add(
Input(shape=x_train[0].shape)
)
model.add(
Flatten()
)
model.add(
Dense(
64,
activation="sigmoid"
)
)
model.add(
Dense(
4,
activation="softmax"
)
)
使用下面的代码可以打印模型结构
from tensorflow.keras.utils import plot_model
plot_model(
model,
to_file='model.png',
show_shapes=True,
dpi=200
)
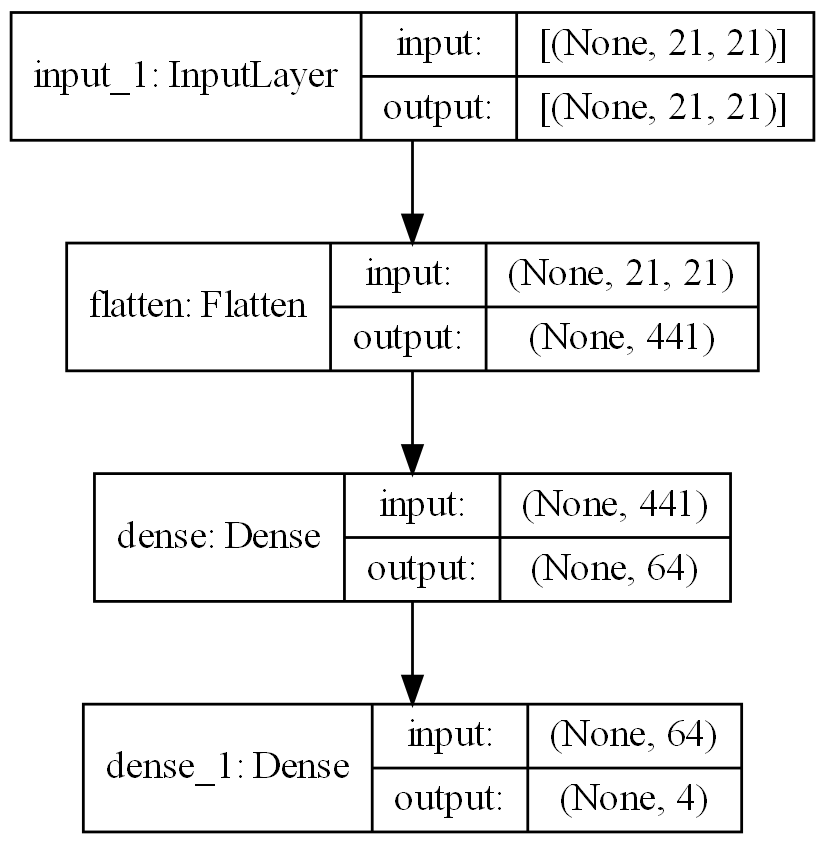
编译
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"]
)
训练
model.fit(
x_train,
y_train,
epochs=100,
)
model.evaluate(
x_test,
y_test
)
[0.4204963743686676, 0.9166666865348816]
使用模型
预测标签
predicted = model.predict(x_test)
predicted.argmax(axis=1)
array([2, 2, 2, 2, 0, 3, 2, 2, 3, 0, 0, 1])
实际标签
y_test.argmax(axis=1)
array([2, 2, 2, 2, 0, 3, 2, 2, 3, 0, 1, 1])
注意:倒数第二个数据预测出错
绘制最后 4 个数据
for p, f, y in list(zip(predicted, f_test, y_test))[-4:]:
cml.plot_map(
f,
width=256,
title=f"{highlow.title(p)} with label {highlow.title(y)}"
)
合并的绘图结果如下所示,左下样本预测分类与实际标签不符
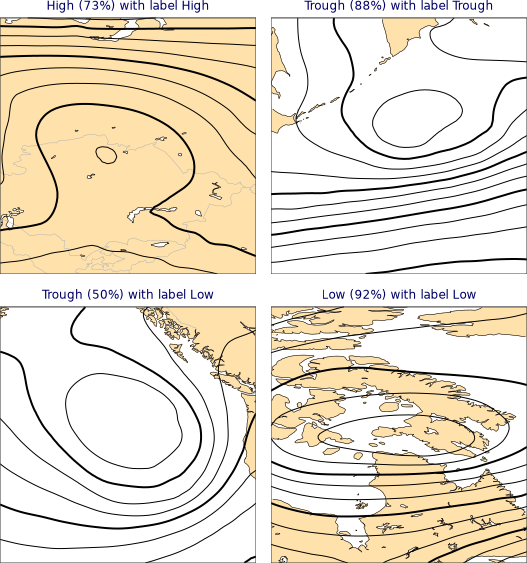
合并代码
from tensorflow.keras.layers import Input, Dense, Flatten
from tensorflow.keras.models import Sequential
import climetlab as cml
highlow = cml.load_dataset("high-low")
(
(x_train, y_train, f_train),
(x_test, y_test, f_test)
) = highlow.load_data(
test_size=0.3,
fields=True
)
model = Sequential()
model.add(Input(shape=x_train[0].shape))
model.add(Flatten())
model.add(Dense(64, activation="sigmoid"))
model.add(Dense(4, activation="softmax"))
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"])
model.fit(
x_train,
y_train,
epochs=100,
verbose=0
)
model.evaluate(x_test, y_test)
可以看到,仅需使用少量代码加载数据,其余大量代码都与 ML 模型相关。
总结
- 无需 MARS 检索
- 无需 GRIB 解码
- 无需转换为 Numpy
- 只需关注 AI/ML 模型
开放开发
利用 GitHub 开源社区进行开发
- GitHub
- Read the Docs
- CI/CD
开始使用
安装,支持 Mac/Linux/Windows,仅支持 Python 3
pip3 install climetlab
文档
https://climetlab.readthedocs.io
当前处于 Beta 版本
- API 会变更
- 欢迎反馈
- 欢迎提供有用的数据集
讨论
虽然处于早期开发阶段,CliMetLab 仍然可以作为基础支撑工具的典型代表,专注于数据访问、绘图等各类机器学习任务需要的通用功能。
其中数据集 (dataset) 的概念非常值得借鉴。 通过集成多种数据源,利用常用的 Python 科学工具库,提供开箱即用的数据,可以直接应用到机器学习库中。 内置的数据集和简便易用的加载函数让用户可以专注于机器学习算法本身,而不是将大量时间花费在数据准备和处理等过程中。 这也是类似笔者这样的研发支撑人员最容易切入的方向。
气象领域的其他工具库中也可以看到类似的思想。
nmcdev 开发的天气学诊断分析工具 (Meteorological Diagnostic Tools, MetDig) 依赖多个基础工具库:
- nmc_met_io 是气象数据读写及访问程序库,提供数据访问接口
- nmc_met_graphics 提供气象数据绘图功能
- nmc_met_base 是气象应用开发基本程序库,提供关于气象科学计算的基础功能函数
最终形成 nmc_met_map 天气学诊断分析工具库。
ESMValGroup 开发的气候诊断工具包 ESMValTool 也分成两个库:
- ESMValCore 提供包括数据预处理在内的基础功能
- ESMValTool 提供各种诊断方法
领域专家仅需利用现有的接口开发新的诊断方法,而无需单独开发数据处理功能。
同样也需要看到,开发类似 CliMetLab 的基础工具库会面诸多挑战:
功能需求。只有了解用户的需求,才能开发可用的基础工具库。多沟通,才能更好地获得需求。
参考已有工具库提供的数据处理功能,开发新的实现,是一种可行的方法。 对于基础库开发者来说,实际编写机器学习程序也是一种了解需求的途径。
HPC 部署。为单位开发的工具库不可避免地需要面对如何在 CMA-PI 上部署的问题。 考虑到 HPC 无法在线安装 Python 包,安装的 Python 环境也几乎不会更新,基础库开发者就会面临如下的抉择:是否仅使用 HPC 已安装的 Python 库?
一个可供参考的例子是去年下半年上线的某个观测资料检索系统,使用 MUSIC V2.0 版本的 Python 接口检索从 CMADAAS 检索观测资料数据。 接口需要单独安装 Protobuf 等依赖库,导致该系统仅能在单一账户下运行,无法简单迁移到其他账户。
数据源。数据工具库的关键在于能否让用户更容易使用数据,这就涉及到工具支持的数据源种类。 部门一直缺乏广泛使用的数据获取工具,没有类似 ECMWF 的 MARS 或 CDS 一样的数据接口。
虽然 CMA 已有 CIMISS/CMADAAS 等数据平台并提供多种语言的接口,基础库开发者依然可以对接口进行二次封装。 nmc_met_io 在这方面的工作非常值得学习,提供从 MICPAS、CIMISS/CMADAAS、GHCND、AWS、CaiYunAPP 等多个平台获取数据的方法。 era5cli 的方式也值得借鉴,将 API 封装为方便易用的命令行工具。NWPC 使用的观测资料检索程序也采用类似的方法将 MUSIC 接口封装为可执行程序。
应用范围。数据工具推广应用的前提条件是支持的数据源可以被广泛获取。 而笔者工作中使用的数据几乎都无法公开访问,这可能也是开源社区中很少听到 CMA 声音的一个原因。 (笔者目测 nmcdev 已成为开源领域的先行者)
笔者会持续关注 CliMetLab 库的开发进展。
参考
Virtual workshop: Weather and climate in the cloud
Enabling Machine Learning for weather and climate data in the cloud
幻灯片:https://events.ecmwf.int/event/211/contributions/1876/attachments/972/1700/Cloud-WS_Raoult.pdf
视频:https://vimeo.com/509944026
相关文章