2020年工作总结
本文是为下周二 (12月15日) 年度工作汇报准备的 PPT,后续可能会有改动
大家好,下面我汇报下 2020 年的工作。
概述

我的汇报主要包含六个部分。
数据处理技术

首先介绍数据处理技术,今年研究数据处理技术的主要目标有两点:
- 提供方便使用的数据访问工具
- 研究分布式数据处理技术
数据访问工具库

https://github.com/nwpc-oper/nwpc-data
今年为 GRAPES 系列模式开发 GRIB 2 数据访问 Python 工具库 nwpc-data,提供查找数据文件和检索要素场的便捷方法,属于 GetPy 软件包的一部分。
左边是数据文件路径查找的代码,支持 HPC 和二级存储。
右边是加载 GRIB2 要素场的代码,基于 eccodes-python 库实现。
分布式数据处理技术
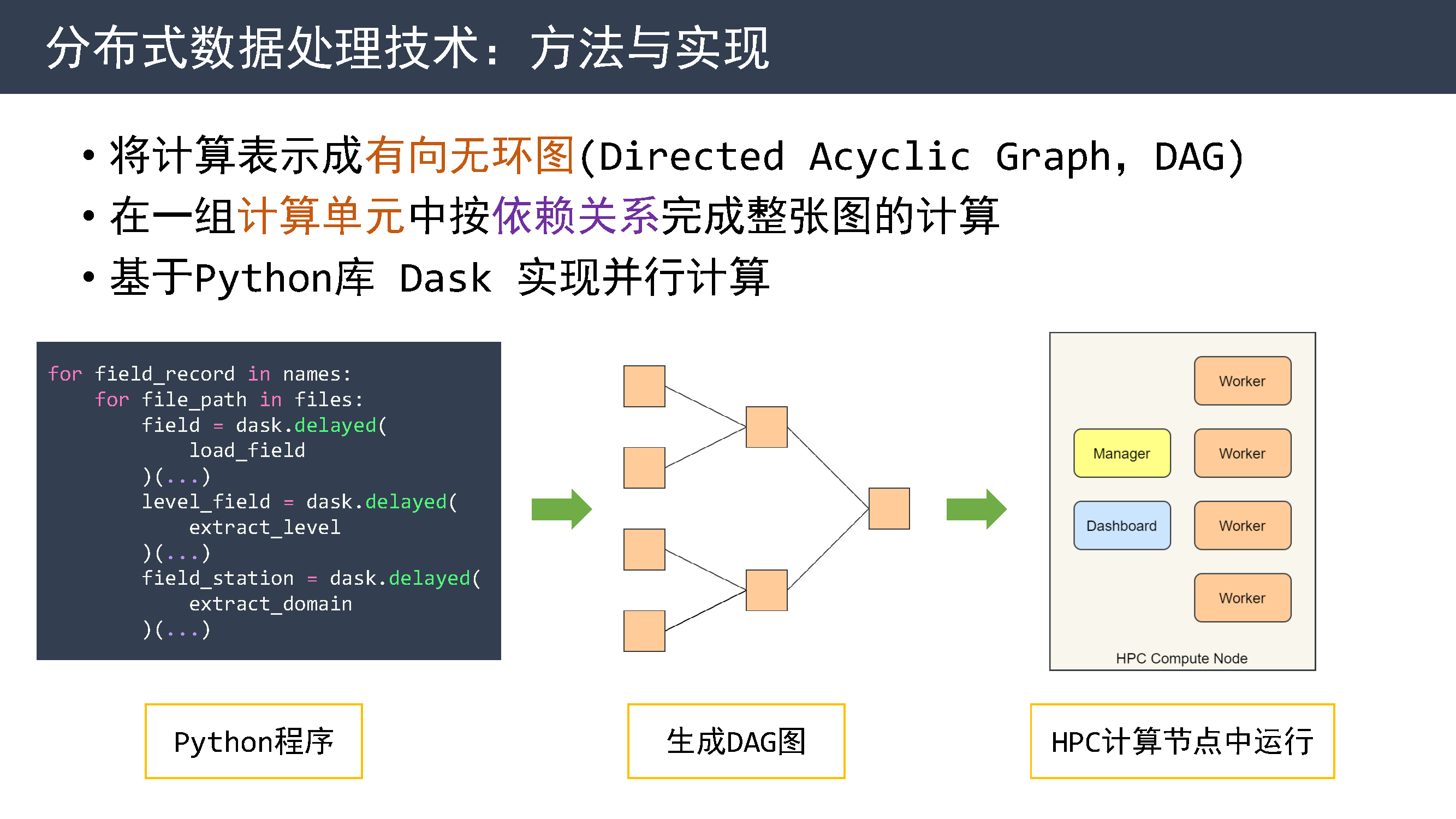
为了提高数据处理效率,今年我研究了一种实现分布式数据处理的方法。
该方法将计算表示成 有向无环图,在一组计算单元中按依赖关系完成整张图的计算。 目前我使用 Dask 库实现并行计算功能。
我使用该方法进行了三项试验
试验 1:批量绘图
https://github.com/nwpc-oper/nwpc-graphics
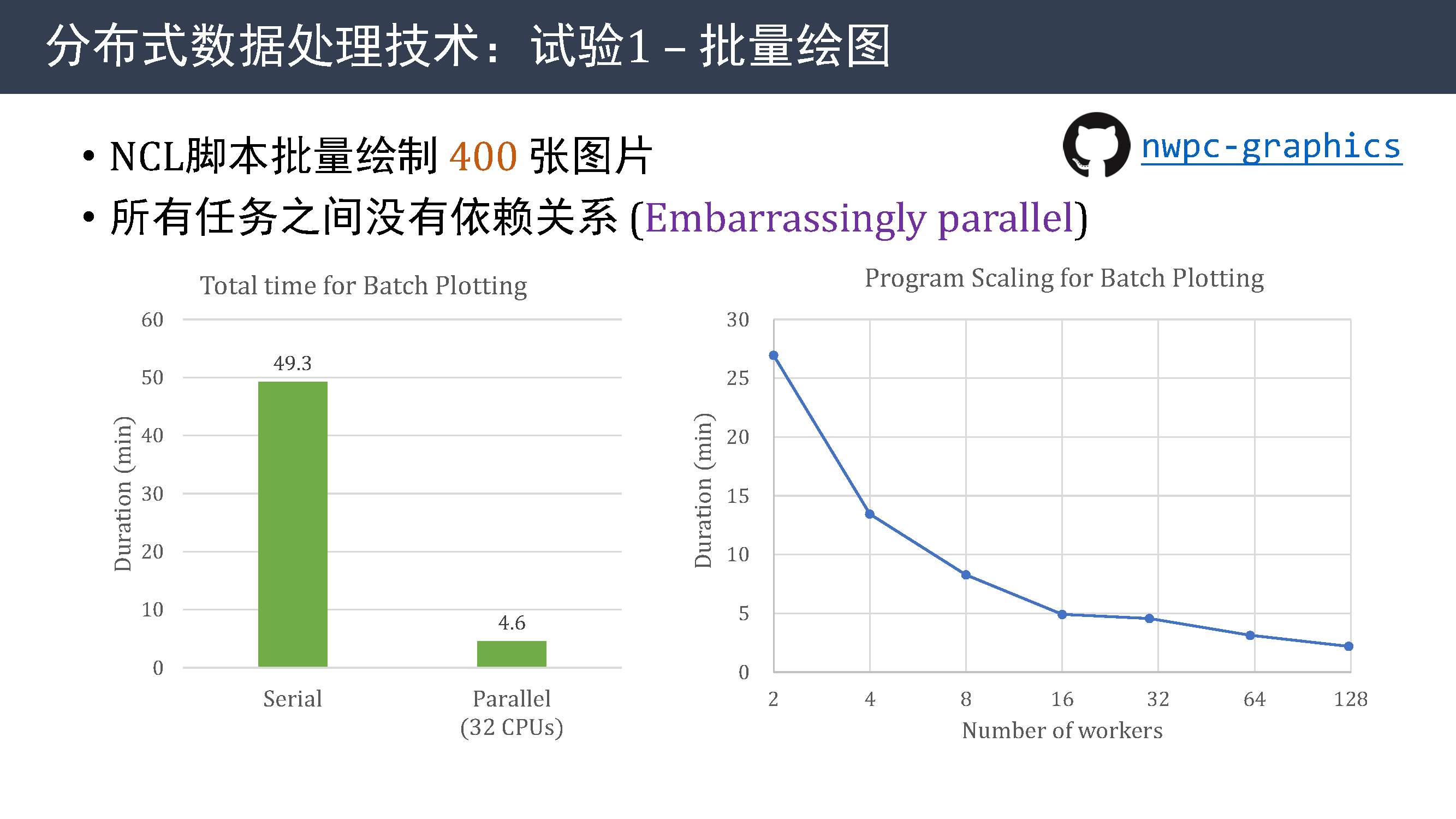
首先使用该方法实现批量图片绘制。
这是一种最简单的分布式数据处理过程,所有任务之间没有依赖关系。
使用分布式数据处理技术,可以将 NCL 脚本批量绘制 400 张图片的时间从串行的 50 分钟减少到 5 分钟以内,将运行时间减少一个数量级。
右图展示了该方法的扩展性能,可以看到,增加 CPU 核心数可以有效缩短批量绘图的时间。
试验2:提取站点数据
https://github.com/perillaroc/nwpc-data-tool
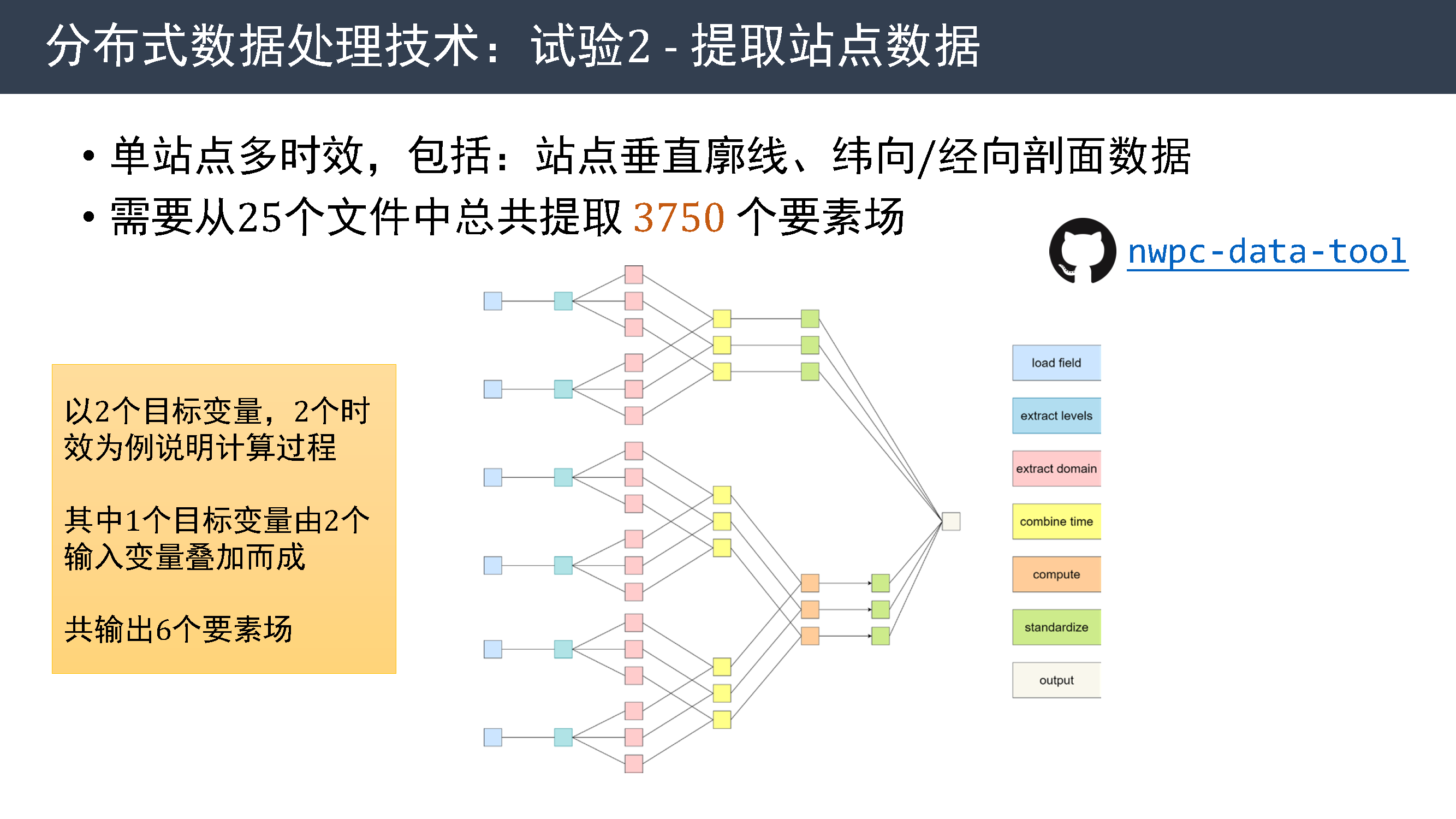
一个更复杂的例子是从多时效文件中提取站点数据,包括站点垂直廓线数据和经向、纬向剖面数据。 在这个试验中,需要从 25 个文件中总共提取 3750 个要素场。
这张图是计算过程的示意图,仅以 2 个目标变量,2 个时效为例说明,其中 1 个目标变量由 2 个输入变量叠加而成,共输出 6 个要素场。
整个过程包括从文件中提取要素场,抽取需要的层次,提取不同区域的数据,按时间轴合并,按需完成计算,并对数据进行标准化等多个步骤。
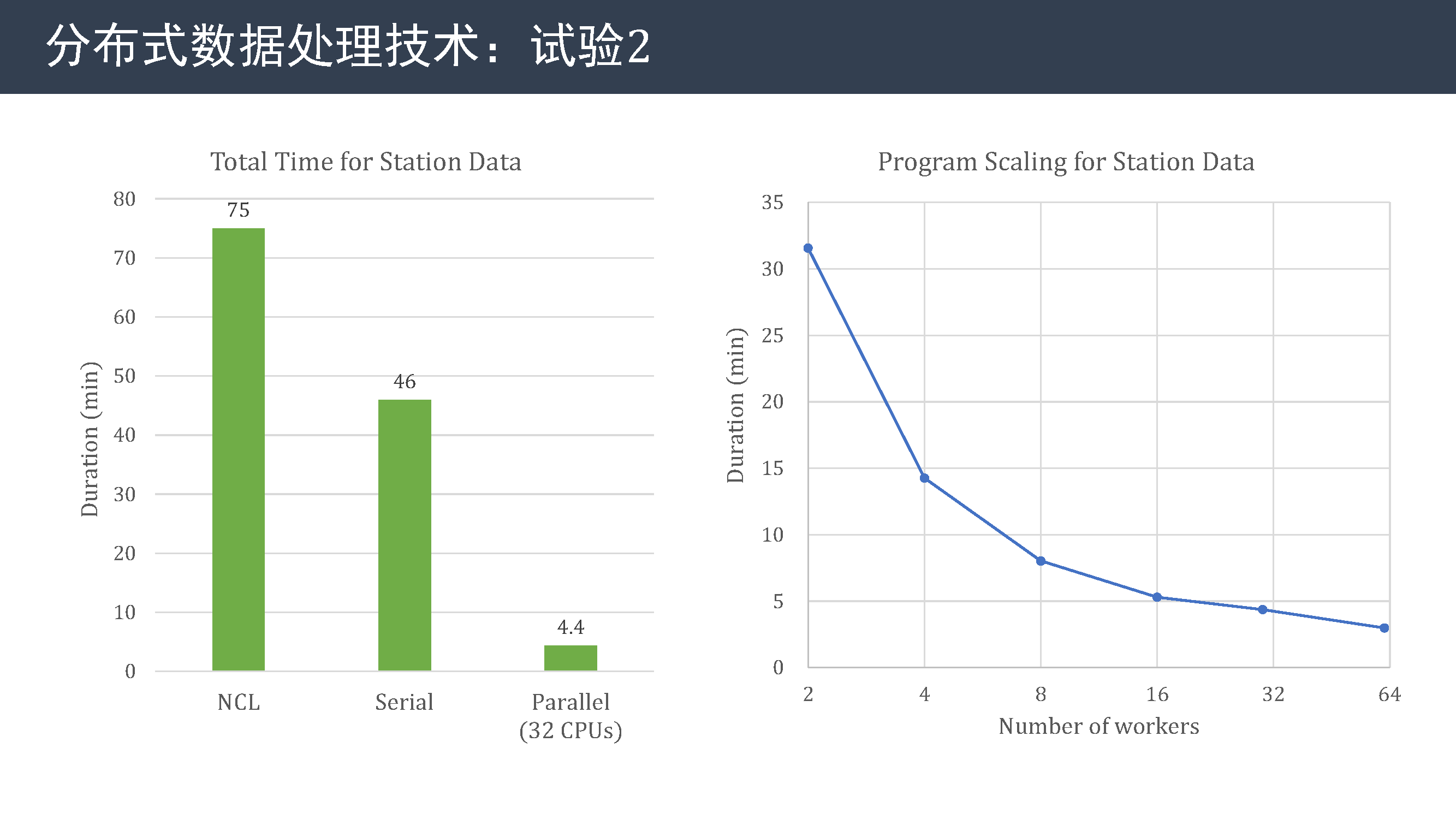
左图是对比三种方法的运行时间,可以看到并行版本仅需要 4.4 分钟,比串行版本低一个数量级,也远远低于 NCL 脚本需要的 75 分钟。
右图展示了方法的扩展性,可以看到当增加到 2 个节点时,效率提升不够显著,说明该方法还有进一步优化的空间。
试验 3:计算统计指标
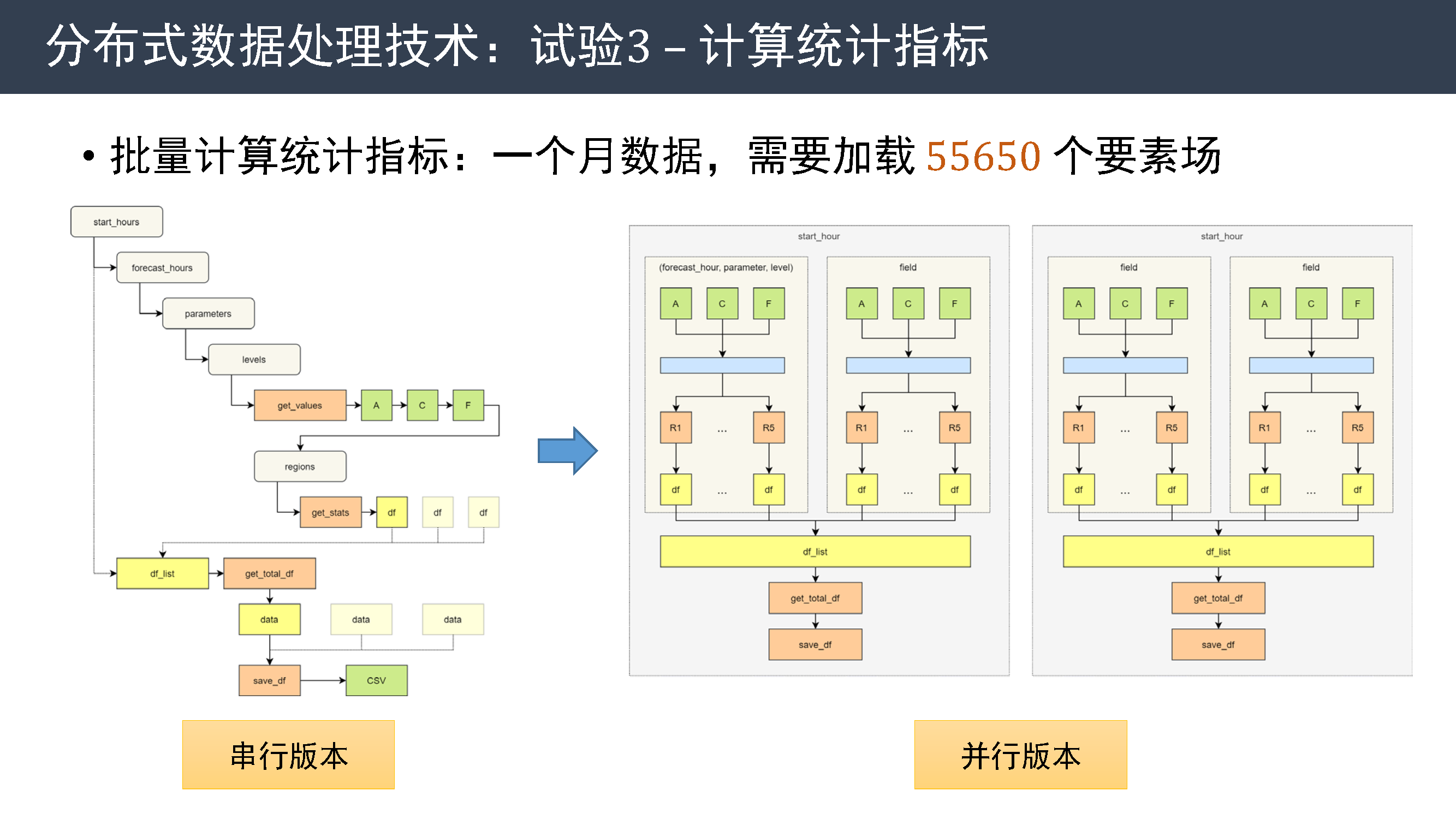
最后一个示例是批量计算统计指标。在试验中要计算一个月的数据,需要加载 5 万多个要素场。
左图是串行版本,需要计算不同时次、不同时效、不同变量、不同层次、不同区域的指标。 右图是并行版本,其中每一层都可以并发执行。
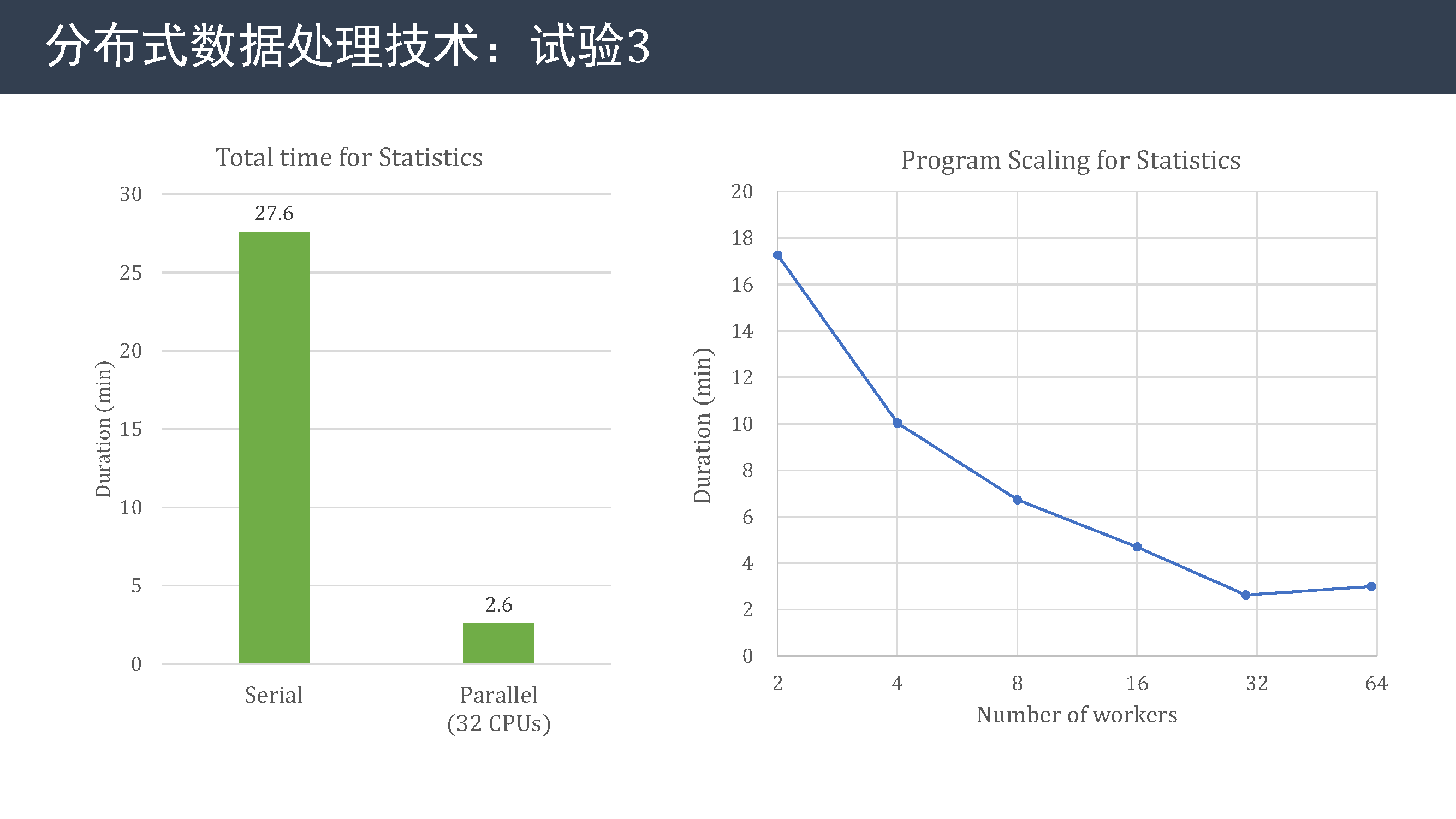
从试验结果可以看到,并行方法耗时比串行方法低一个数量级。 右图展示了方法的扩展性,可以看到,在 1 个节点 32 CPU 以内,执行效率逐步提高。 但 2 个节点耗时比 1 个节点还高,说明各个计算单元间的通信占比较高,限制了算法的可扩展性。
以上试验均表明这种分布式数据处理方法可以有效提高部分数据处理任务的运行效率。
运维技术
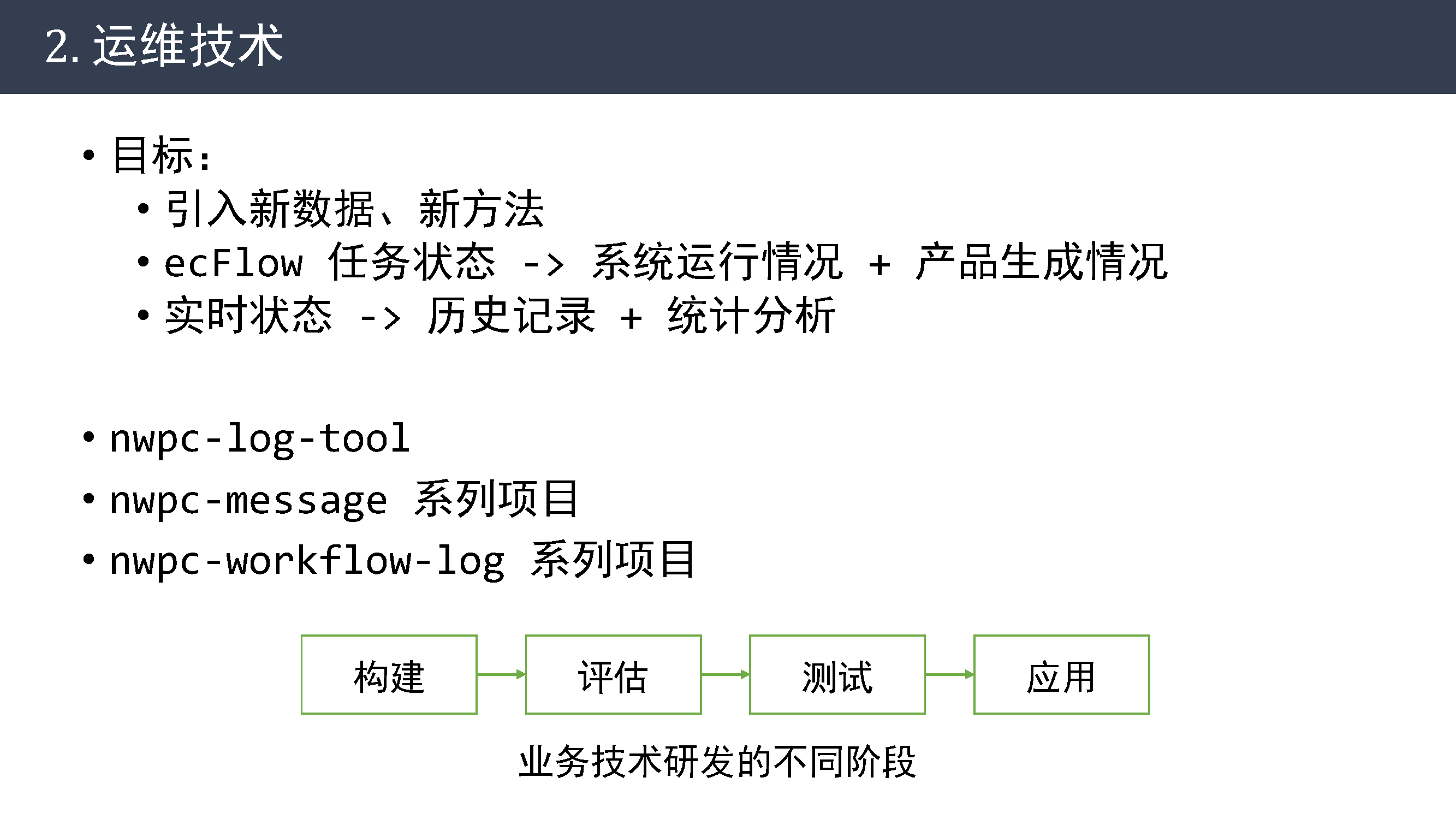
今年在运维技术方面的目标是
- 引入新数据和新方法
- 从只展示 ecFlow 任务运行状态扩展到展示更通用适用面更广的系统运行情况和产品生成情况
- 同时在监控实时状态的基础上,将关注目标扩展到历史记录上,对历史记录进行统计分析。
模式积分时长预测算法
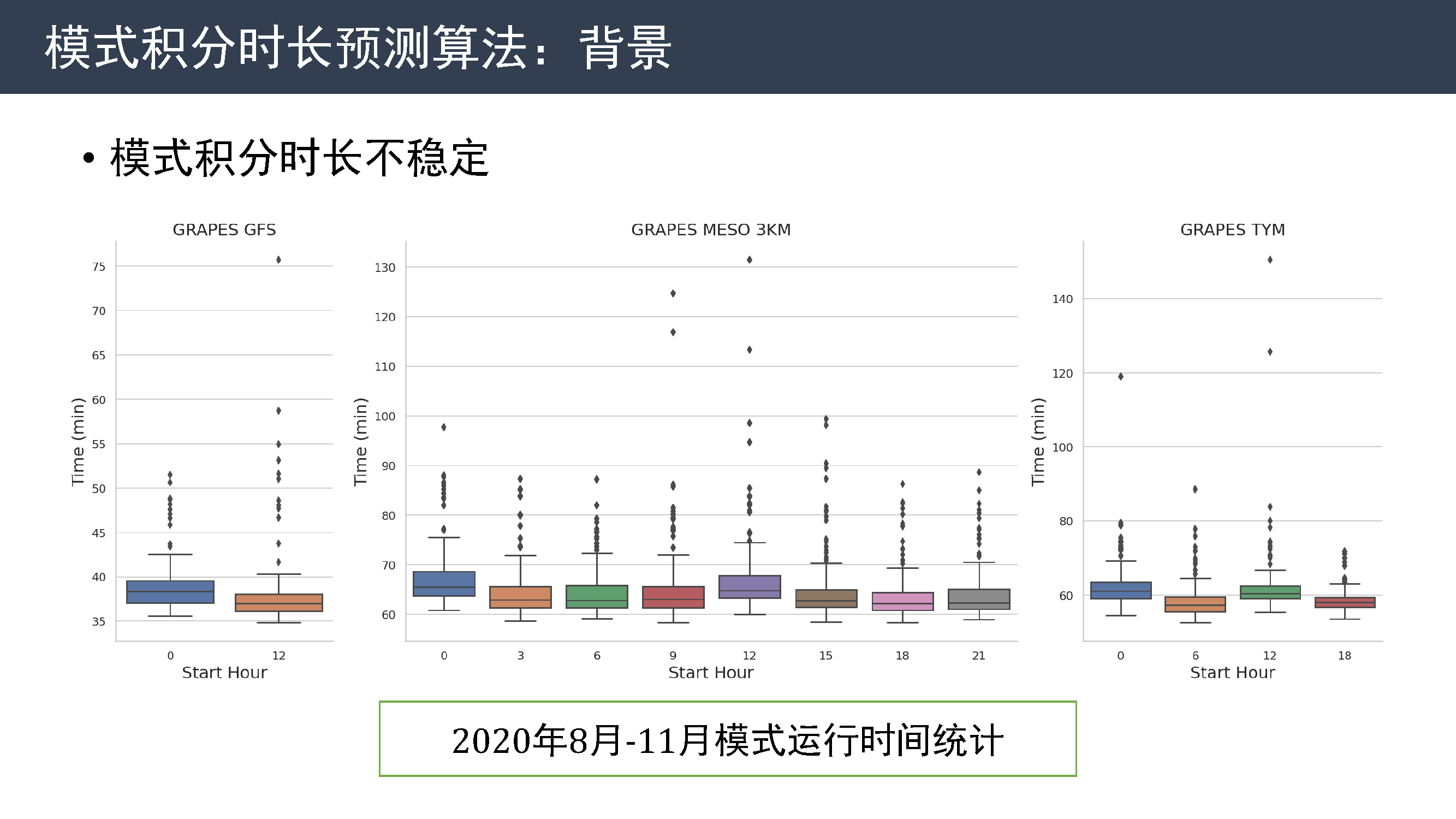
今年对模式积分运行时长的历史数据进行分析,发现模式积分时长不够稳定。 这是 2020 年 8 到 11 月三个模式各个时次积分时长的箱线图,可以看到几乎每个时次都有部分样本积分时间过长。
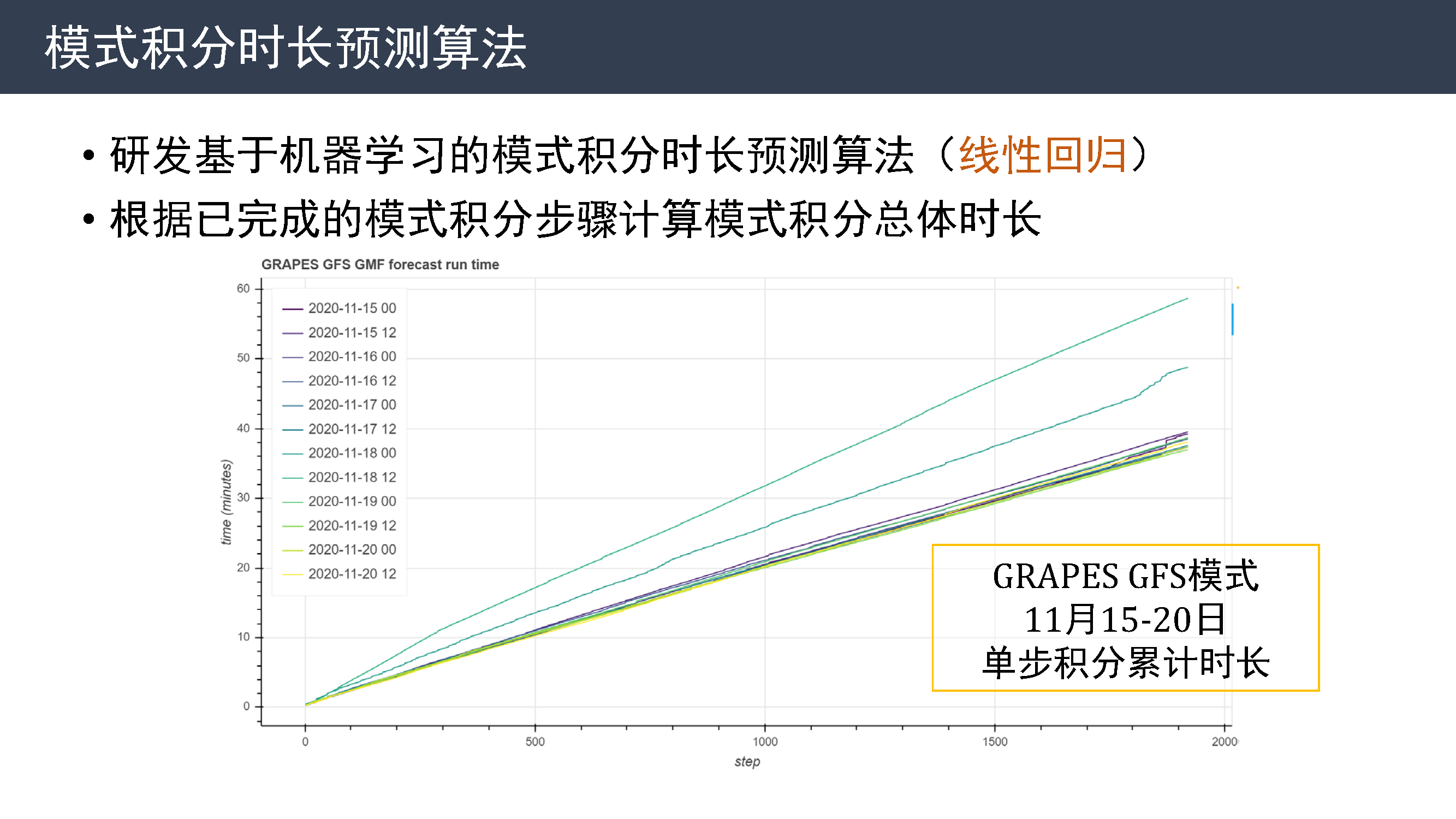
从模式单步积分累计时长线条图中可以看到,模式积分累积时间近似于线性增长,积分异常时次的曲线斜率明显大于积分正常的时次。
因此今年研发了基于线性回归的模式积分时长预测算法,根据已完成的步骤计算模式积分的总体耗时。
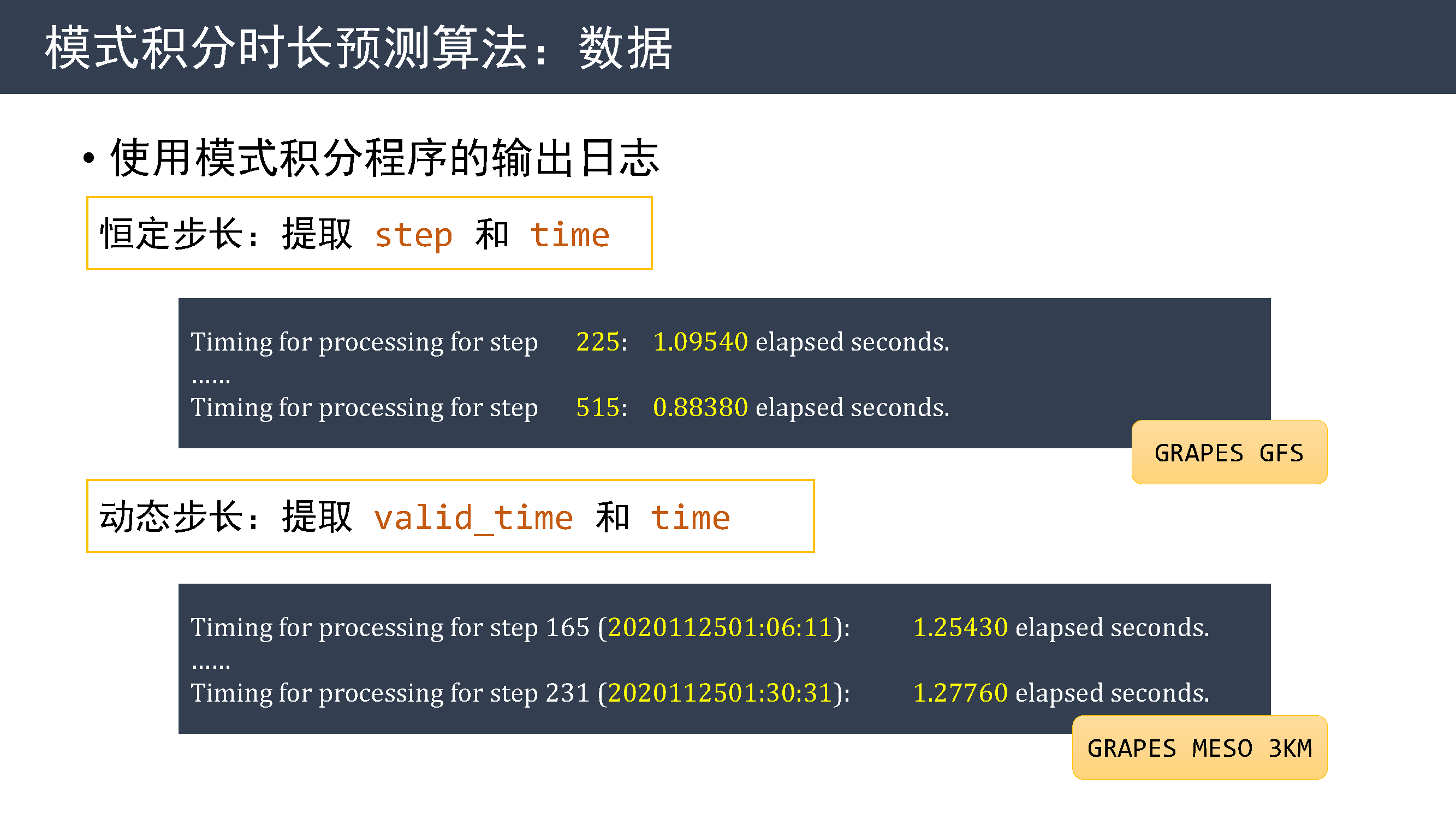
该算法使用模式积分程序的输出日志作为输入数据。
对于恒定步长的模式,提取积分步数和单步耗时。
对于动态步长的模式,提取积分步骤对应的时刻和单步耗时。
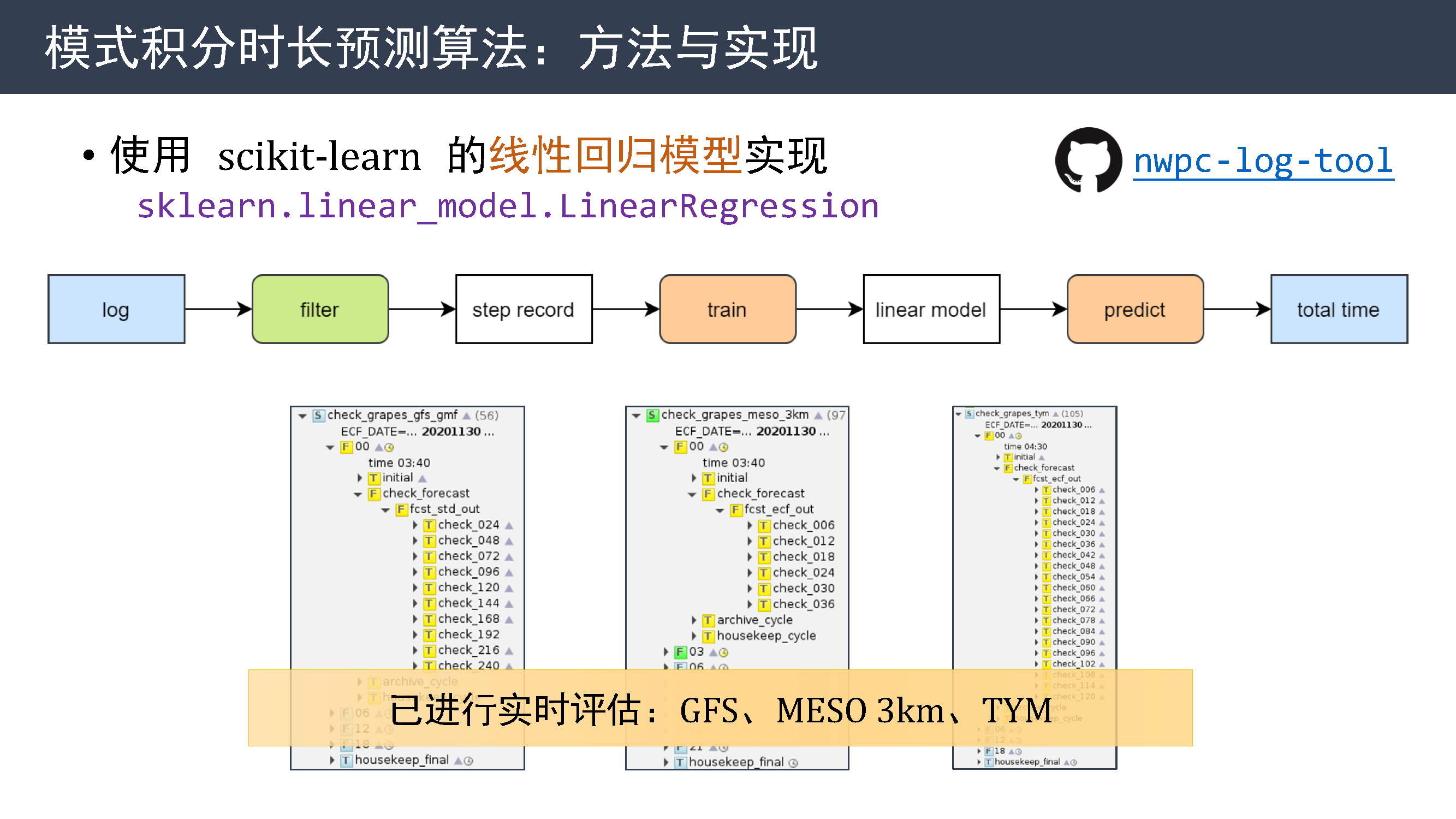
目前我使用 scikit-learn 的线性回归模型实现该算法,通过正则表达式提取需要的信息,训练模型,预测积分总体耗时。 已在 GFS、MESO 3KM 和 TYM 系统上进行实时评估。
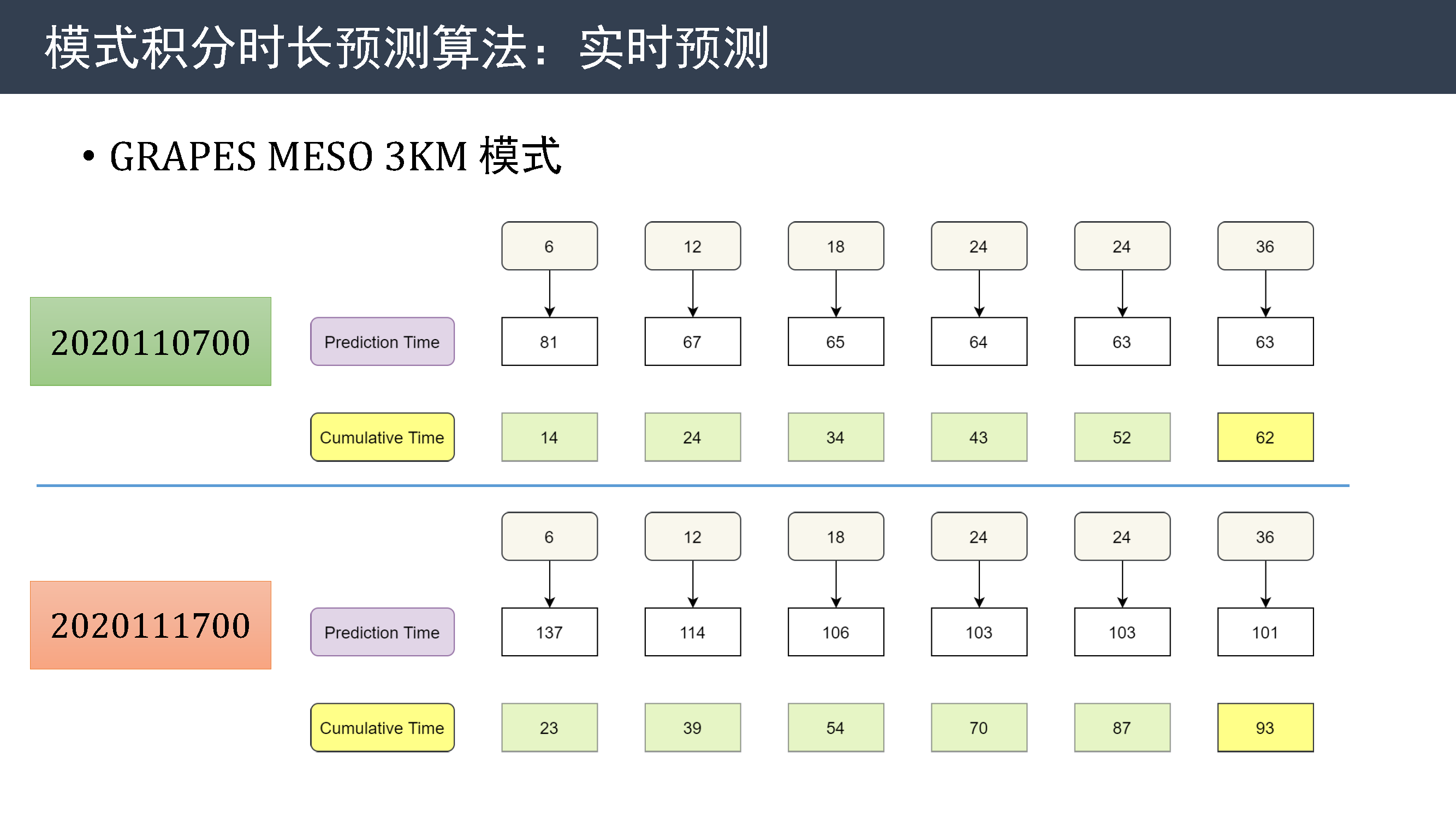
这是 MESO 3KM 模式的一个实时预测示例,上面的时次积分耗时正常,下面的时次积分运行超时。
第一行是运行预测程序时对应的时效,紫色行表示预测的最终时间,黄色行表示运行预测算法时当前积分累计时间。
从结果可以看到,正常积分时,从第 12 小时开始,算法预测的结果与最终时间相差不多。 而异常积分时,虽然偏差较大,但也能暗示积分很可能已处于超时状态。
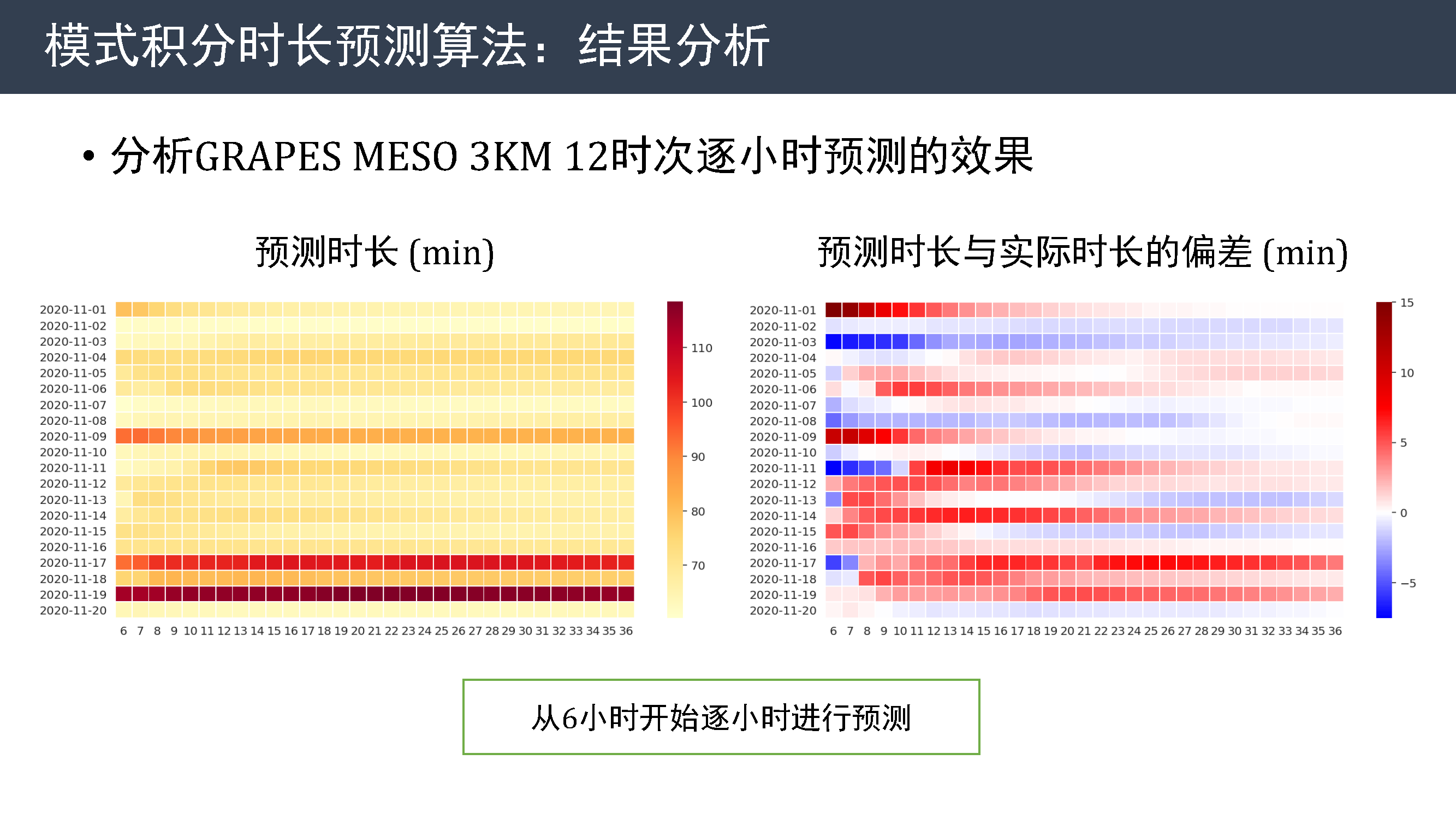
同时,我也对预测效果进行进一步分析。 这是 MESO 3KM 12 时次从 6 小时开始逐小时预测的效果图。
虽然前面时效偏差较大,但从左图中可以明显看到,积分时间超时的时次通常在整个预测序列中都有较大的预测时长,所以该算法能有效在积分前期就发现积分时长的异常情况。
NWPC 消息平台

在消息平台方面,今年全面引入表示特定事件的新数据。 由业务系统主动发送与业务系统相关的事件消息,方便驱动后续应用,面向明年会进入业务流程中的大数据云平台。
目前支持的事件包括:
- 产品生成
- 产品上传
- 任务运行状态变化
同时该项工作已申请 2020 年气象中心现代化专项项目《基于消息通讯的数值预报业务系统运行监视和分析技术研发》。

在去年基础上,今年新增向 NMC 统一监控平台实时发送 MESO 3KM 和 10 KM 两个模式的 GRIB 2 产品消息。
GRAPES 相关产品消息已集成到气象中心关键业务信息监视平台中,在产品生成超时的情况下会发送报警短信。

另外,今年也设计一套更符合业务系统需求的事件消息。
目前包括两种消息:
一种是产品上传消息,已在多个系统中进行实时测试;
另一种是任务状态变化消息,目前仅在两个非核心系统中进行评估,计划明年加入到部分业务系统中。
新设计的事件消息也是现代化专项《运行研发技术》中的第一项研究内容。
标准时间统计算法
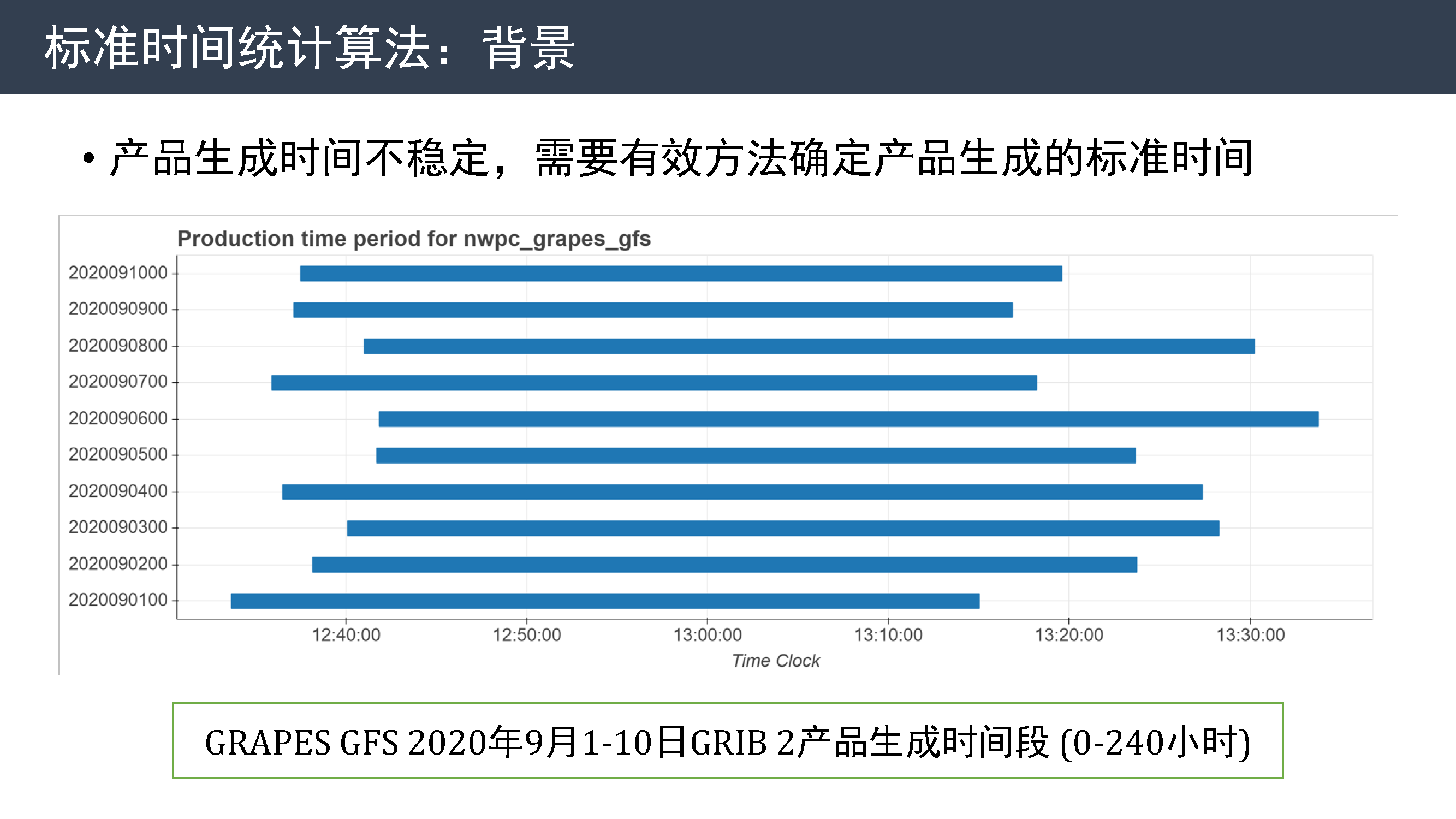
有了新的数据,就可以对业务系统的运行情况进行进一步分析。 这张图展示了 GFS 模式在 9 月前 10 天 GRIB 2 产品的生成时间段,可以看到产品生成时间不稳定,需要有效方法确定产品生成的标准时间。

https://github.com/nwpc-oper/nwpc-message-tool
因此,今年我设计了两种计算标准时间的方法:
第一种使用自助法计算 95% 置信区间,作为标准时间的上下界,并使用 Dask 并行来加速计算过程。
第二种计算截尾平均值,使用分位数在 10 - 90% 之间的数据计算平均值和标准差,平均值 +/- 2 倍标准差作为上下界。 因为不需要重采样,所以第二种方法可以瞬间完成计算。
这两种方法也是现代化专项《运行技术研发》中的第二项研究内容。

https://github.com/nwpc-oper/nwpc-message-web
同时我还基于标准时间,开发了在线可视化面板,可以逐时效查看产品的生成时间,超过标准时间的时效会用红色标出,支持实时数据和历史数据。
在线可视化面板也是现代化专项《运行技术研发》中的第三项研究内容。
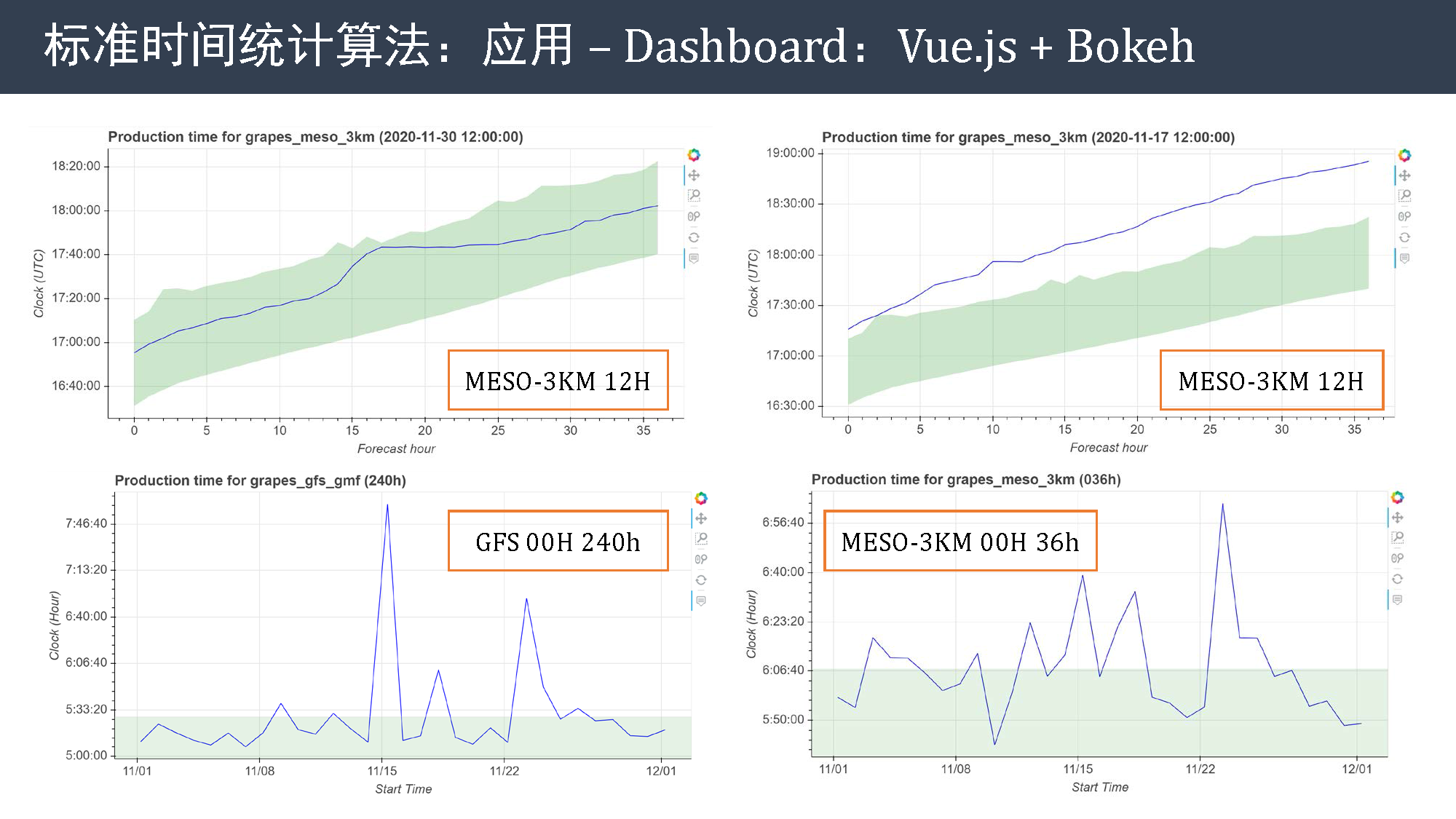
另外该可视化面板还支持对历史数据的统计显示。
上面两张图是 MESO 3KM 模式 12 时次全时效产品生成时间的折线图,蓝色线是产品实际生成时间,绿色区域表示标准时间的上下界。 可以看到正常情况下,蓝线始终在绿色区域内,但右图显示的异常时次中,蓝线都在绿色区域外部。
下面两张图是单个时效的历史生成时间图,可以很明显看到模式产品的生成时间不够稳定。
运行状态分析算法
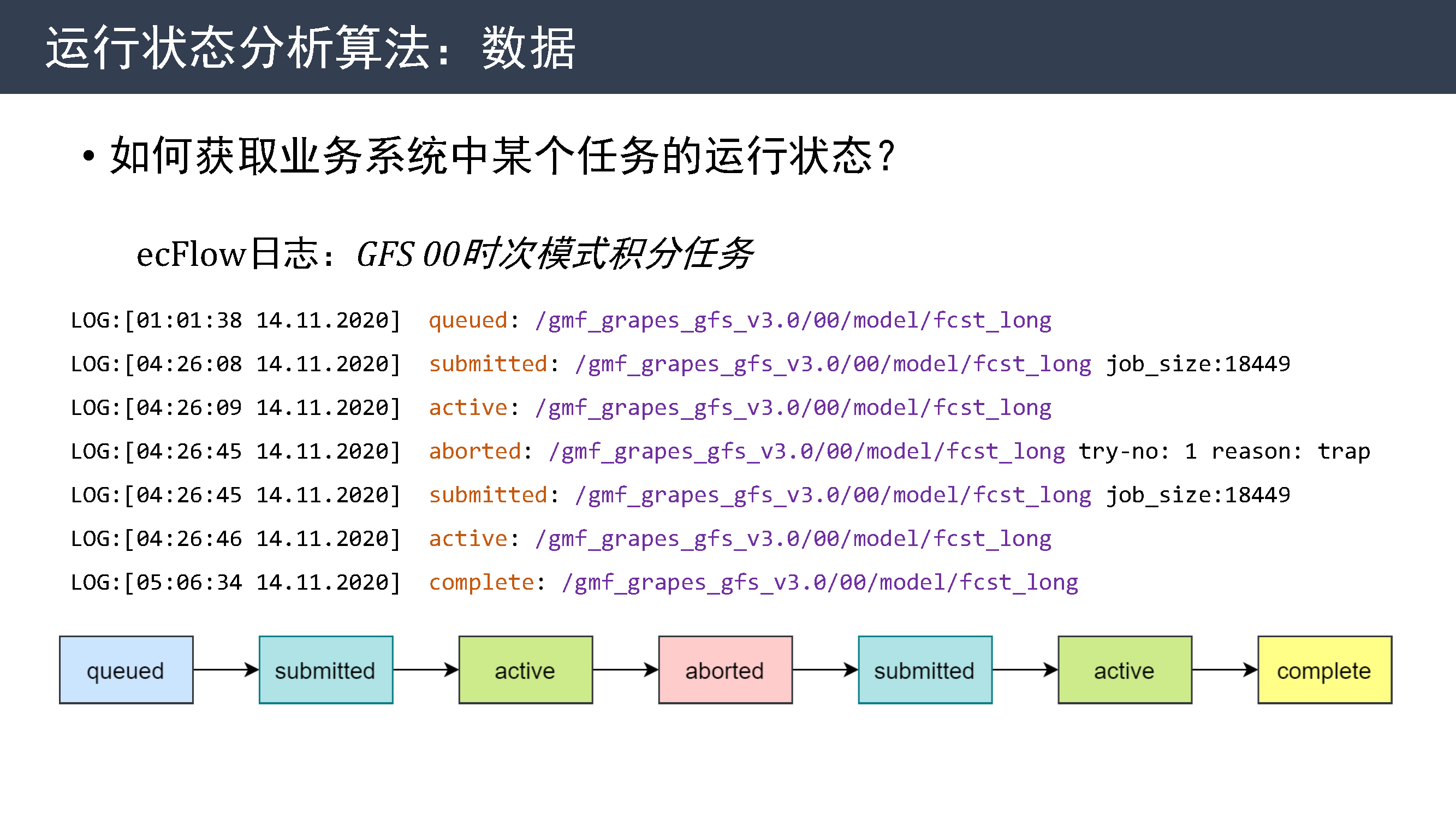
今年对之前收集到的历史数据也进行了分析。 需要首先解决的问题就是如何获取业务系统中某个任务的运行状态。
在 ecFlow 日志中保存了这样的记录,每条记录可以当成任务运行状态的变化数据,需要对这些序列数据进行分析。
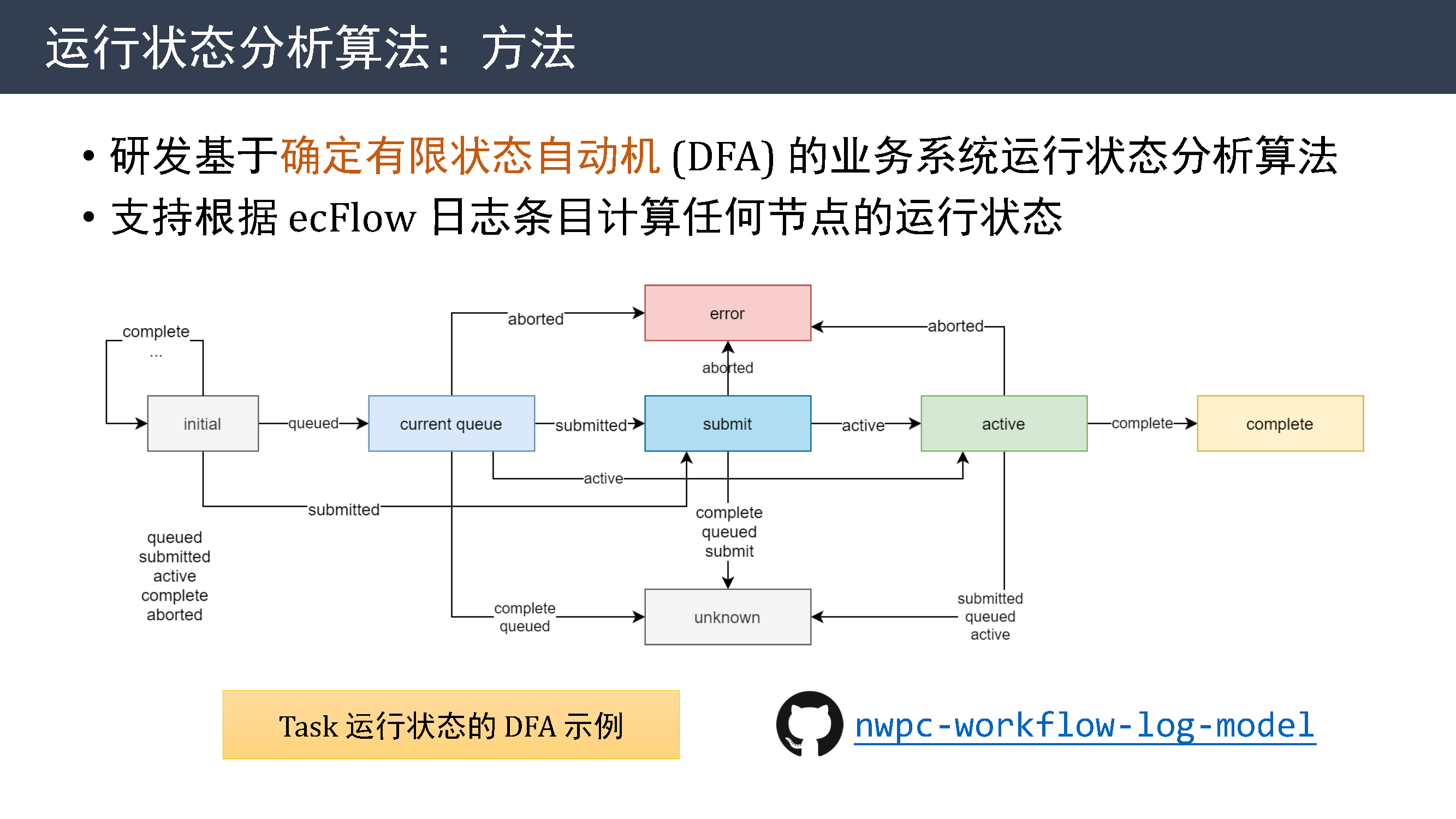
https://github.com/nwpc-oper/nwpc-workflow-log-model
今年研发基于确定有限状态自动机 (DFA) 的业务系统运行状态分析算法,支持根据 ecFlow 日志条目计算任何节点的运行状态。
这张图是针对任务节点计算运行状态的 DFA 示例,我们最需要是那些能到达完成状态的数据序列,而其他序列会被忽略。
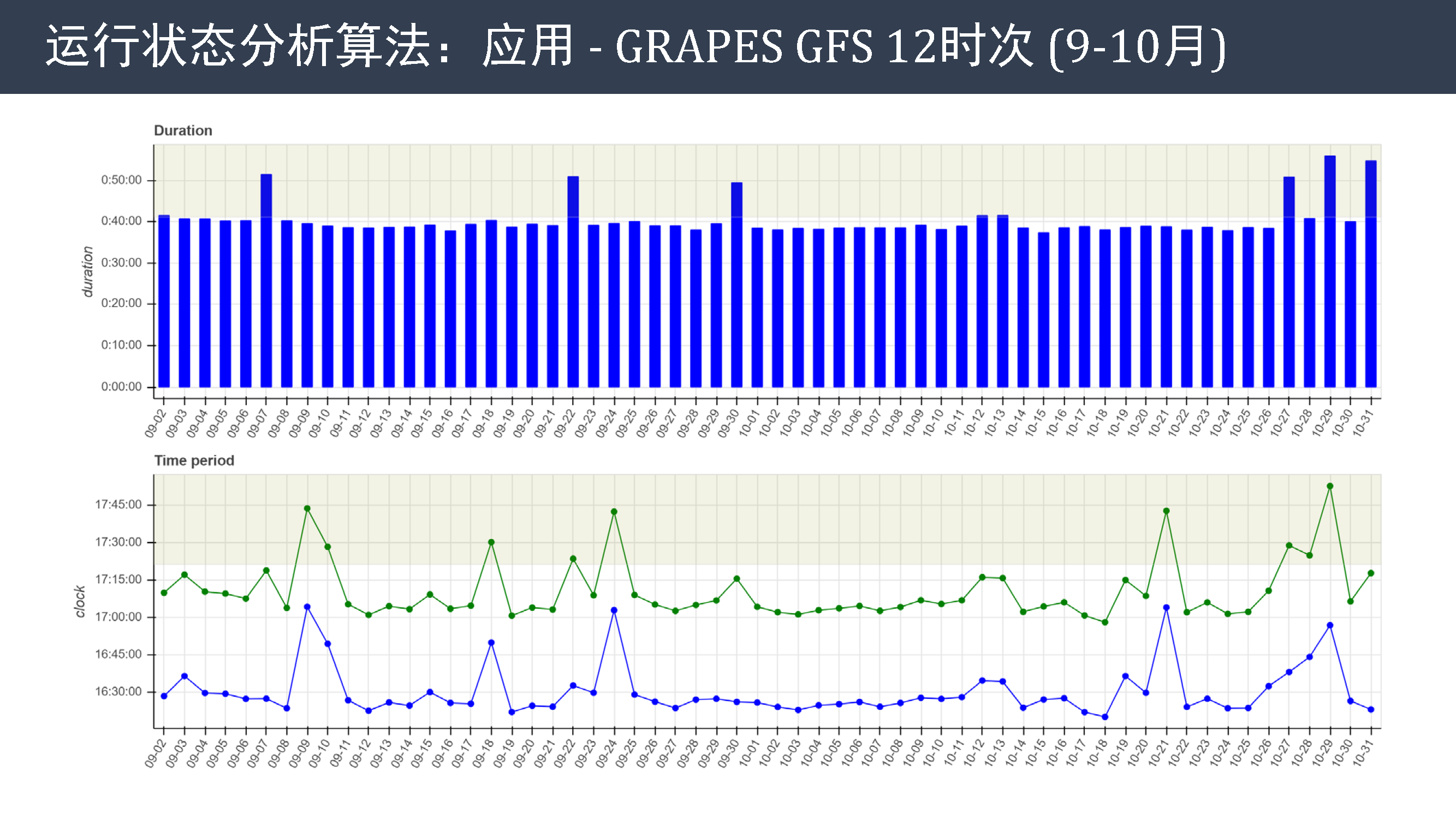
根据这一算法,我统计了 GFS 模式 12 时的模式积分任务在 9、10 两个月的运行时间和起止时刻。 可以看到,部分时次运行时长偏长,部分时次启动时间偏晚,但启动时间和运行时长之间没有明显的相关性。
值班网站

今年还完成了海洋工程一期项目中值班网站的验收。
核心开发思想是将业务系统运行状态以更直观的方式展现。
在运行科所有同事的共同推动下,新版值班网站已具备业务应用能力,将于明年 1 月 1 日正式启用。
诊断分析技术

在诊断分析技术方面,今年的目标是:
- 提供方便使用的在线分析工具
- 研究分布式调度技术
在线分析工具

https://github.com/nwpc-oper/nwpc-graphics
今年开始研究如何使用 Jupyter Notebook 来提供在线分析工具,并开发了一个小项目来用于验证。
封装业务系统的绘图脚本,提供方便使用的 Python 接口。 仅需编写少量代码,就能得到一个可交互的绘图工具界面。
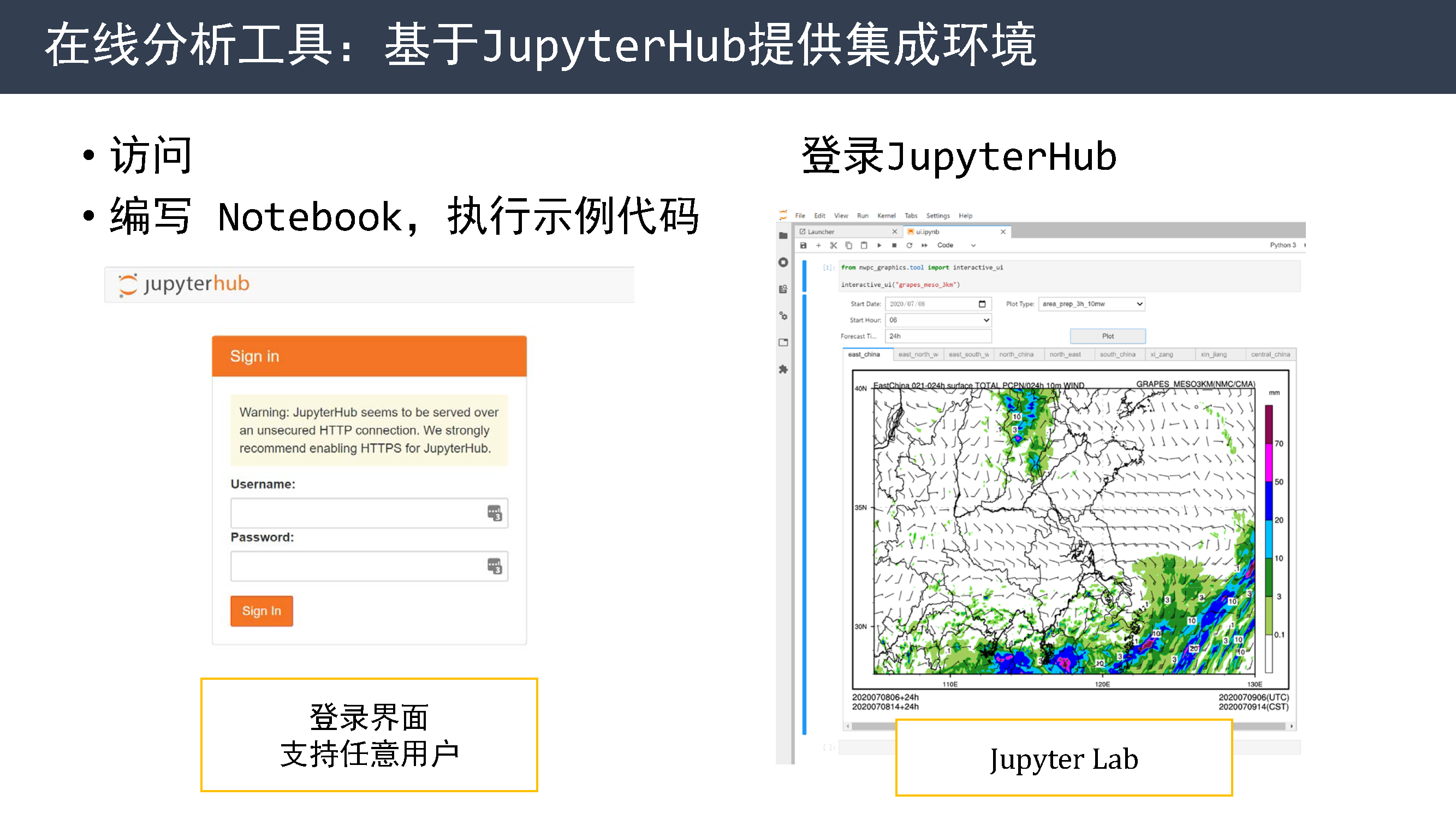
同时还研究如何基于 JupyterHub 提供集成开发环境,使用 Docker 搭建一个测试服务,支持任意用户登录。 大家如果感兴趣可以访问这个网址,编写 Notebook 执行示例代码。
基于分布式调度的绘图技术研究
https://github.com/perillaroc/ploto
https://github.com/perillaroc/ploto-gidat
https://github.com/perillaroc/ploto-esmvaltool
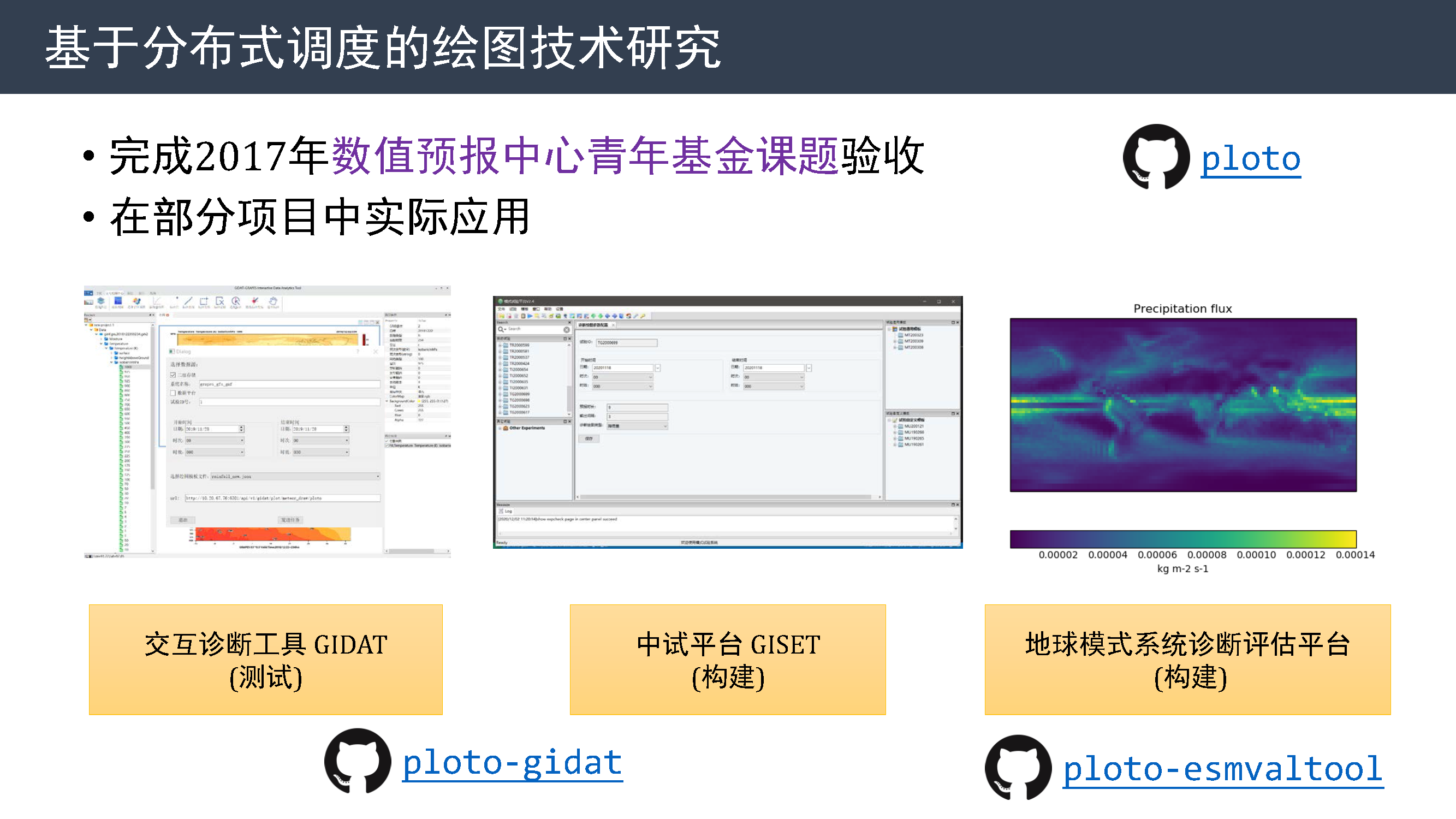
在基于分布式调度的绘图技术研究方面,今年完成 2017 年数值预报中心青年基金课题项目的验收,并在部分项目中实际应用,包括:
- 在交互诊断工具 GIDAT 项目中实际测试
- 对接中试平台 GISET,预计明年开始实际测试
- 在地球模式系统诊断评估平台中对接新的诊断工具包
地球模式系统诊断评估项目

在地球模式系统诊断评估项目中,今年完成平台的架构设计,支持 CMIP6 数据,支持多种诊断方法。 计划明年完成诊断方法的集成。
系统建设

系统建设方面的工作主要有三项。
业务系统建设
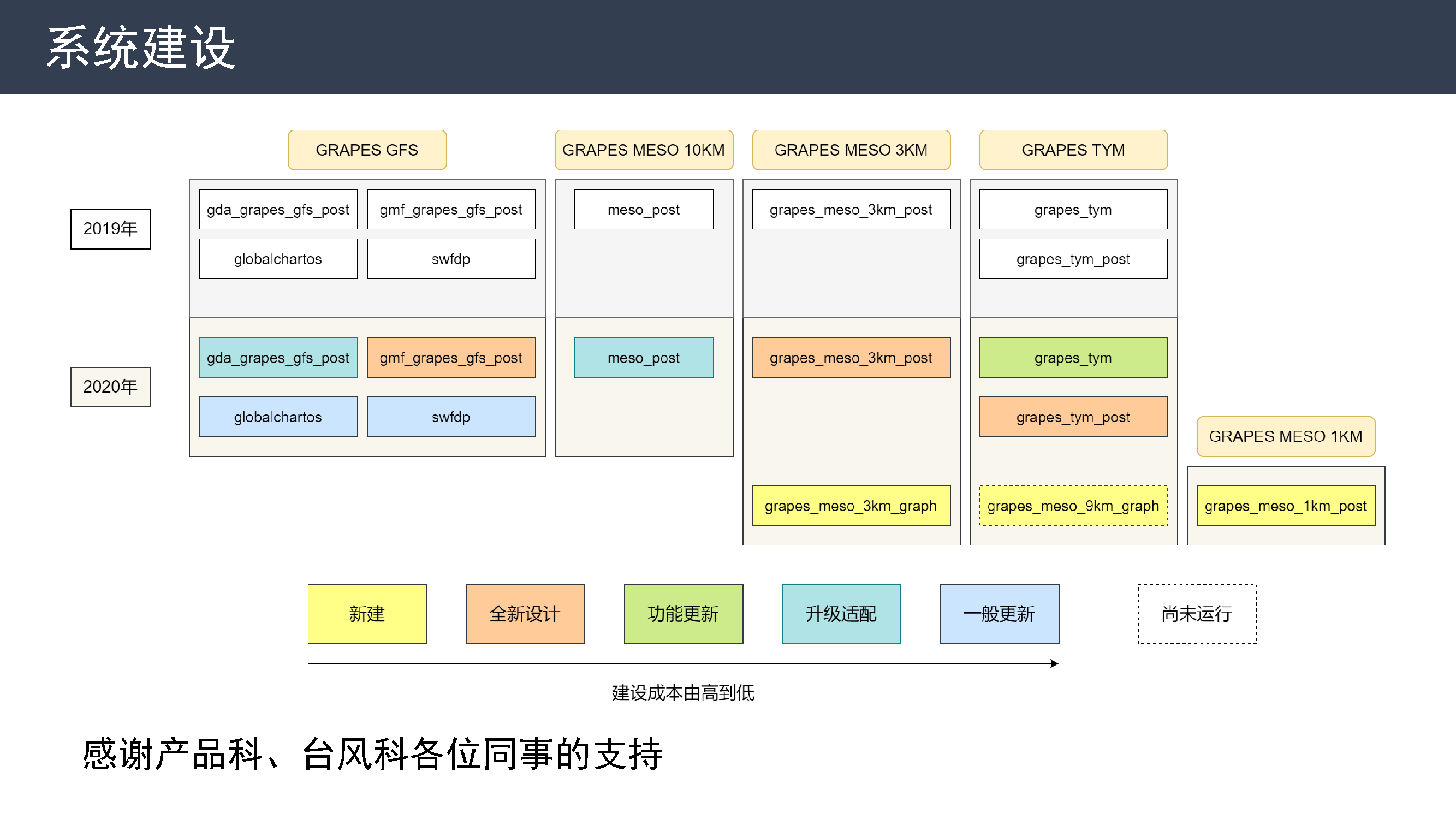
我负责维护的系统由 2019 年的 8 个增加到 2020 年的 11 个,包括 3 个新建系统,3 个重新设计的系统和 5 个有不同更新规模的系统。
感谢产品科、台风科各位同事的支持,让我能非常高效地完成系统升级和更新工作。
服务监控系统
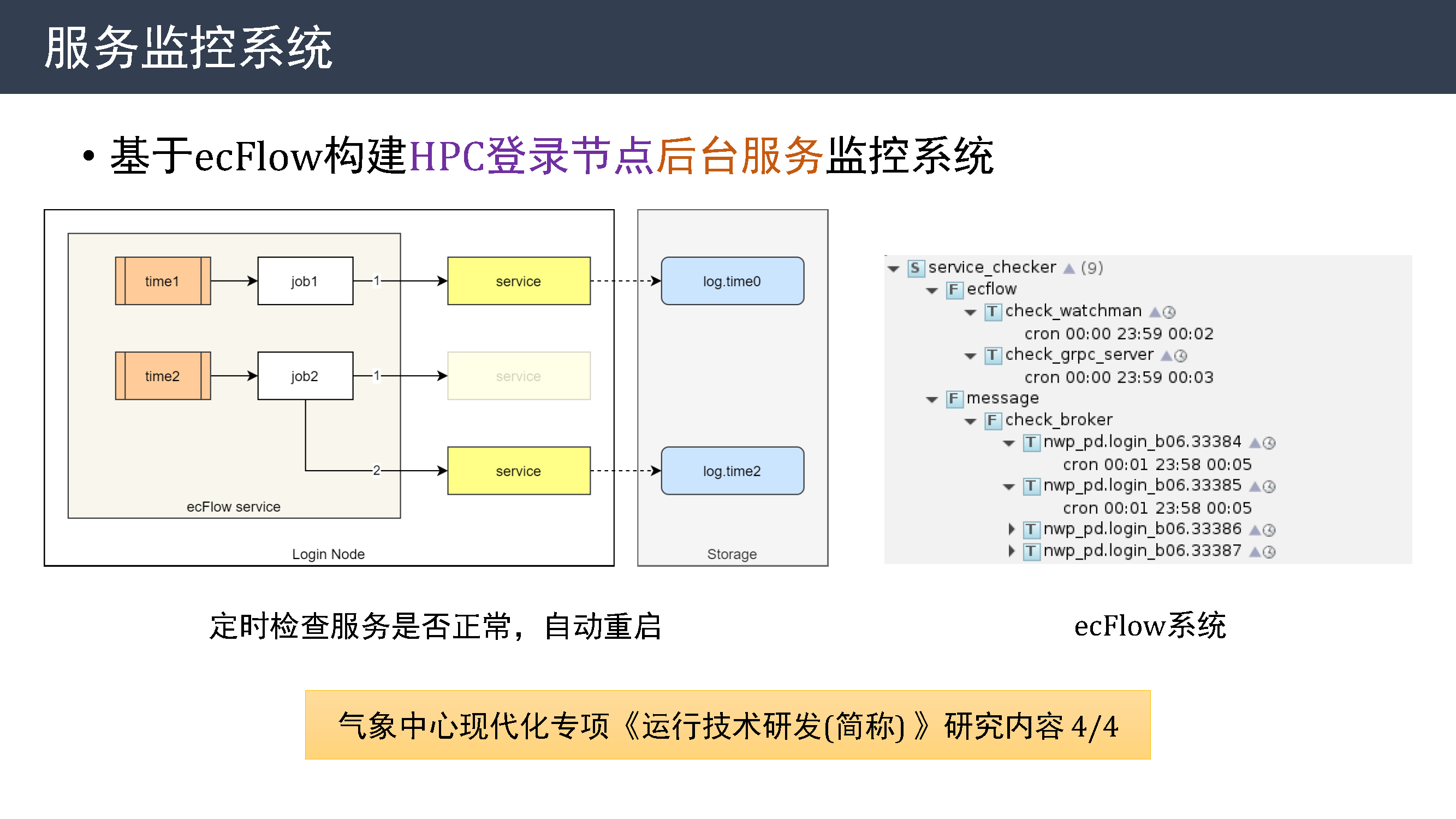
前面介绍的部分运维技术依赖在 HPC 登录节点上运行的服务程序,为了保障服务程序能稳定运行,今年基于 ecFlow 构建 HPC 登录节点后台服务监控系统。 定时检查服务是否正常,在检测到异常时会自动重启服务。
监控系统也是现代化专项《运行技术研发》中的最后一项研究内容。
NMC 台风数据库检索
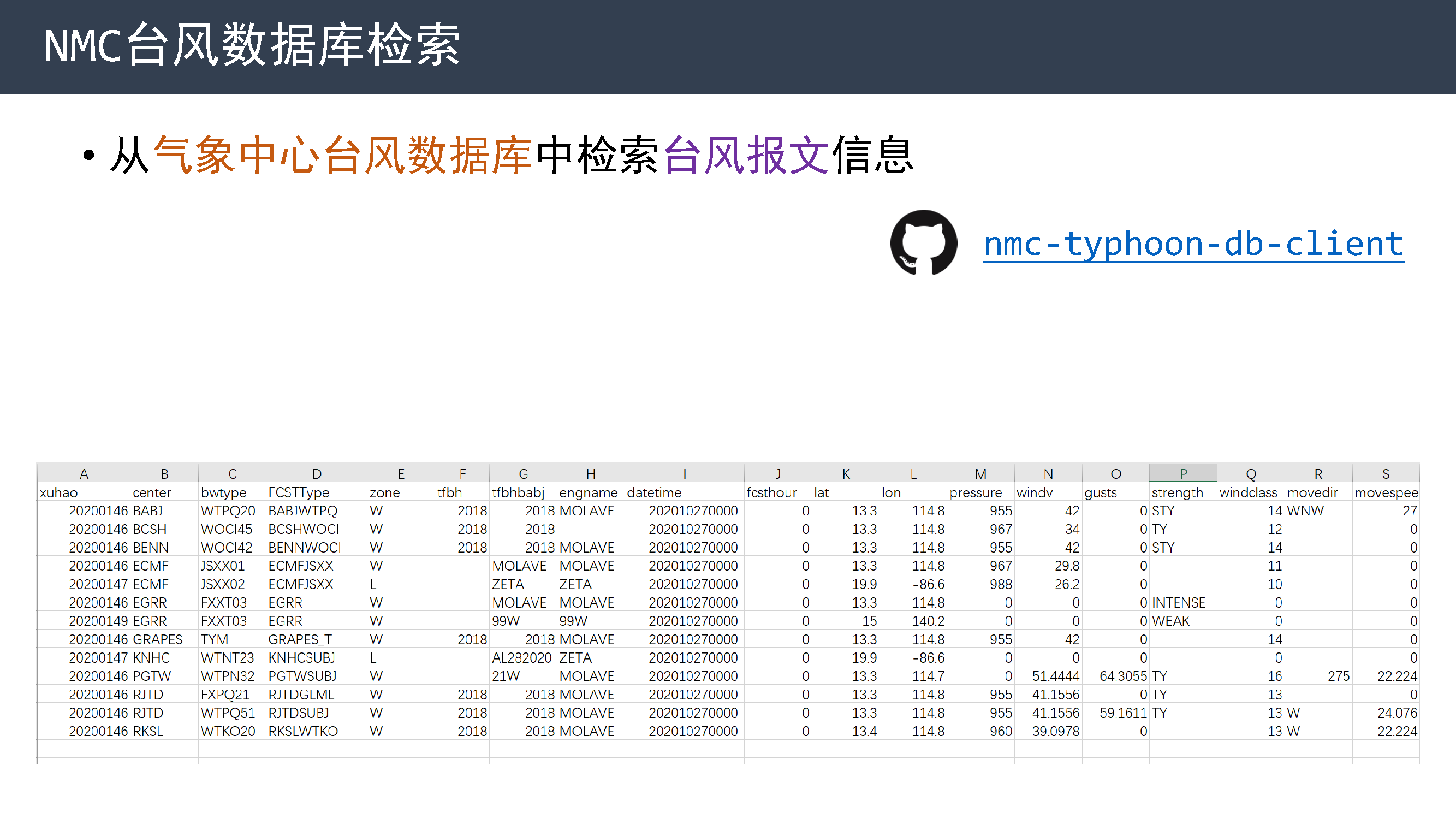
https://github.com/nwpc-oper/nmc-typhoon-db-client
在台风科老师的指导下,今年还开发 NMC 台风数据库检索工具,从气象中心台风数据库中检索台风报文信息。
其他工作
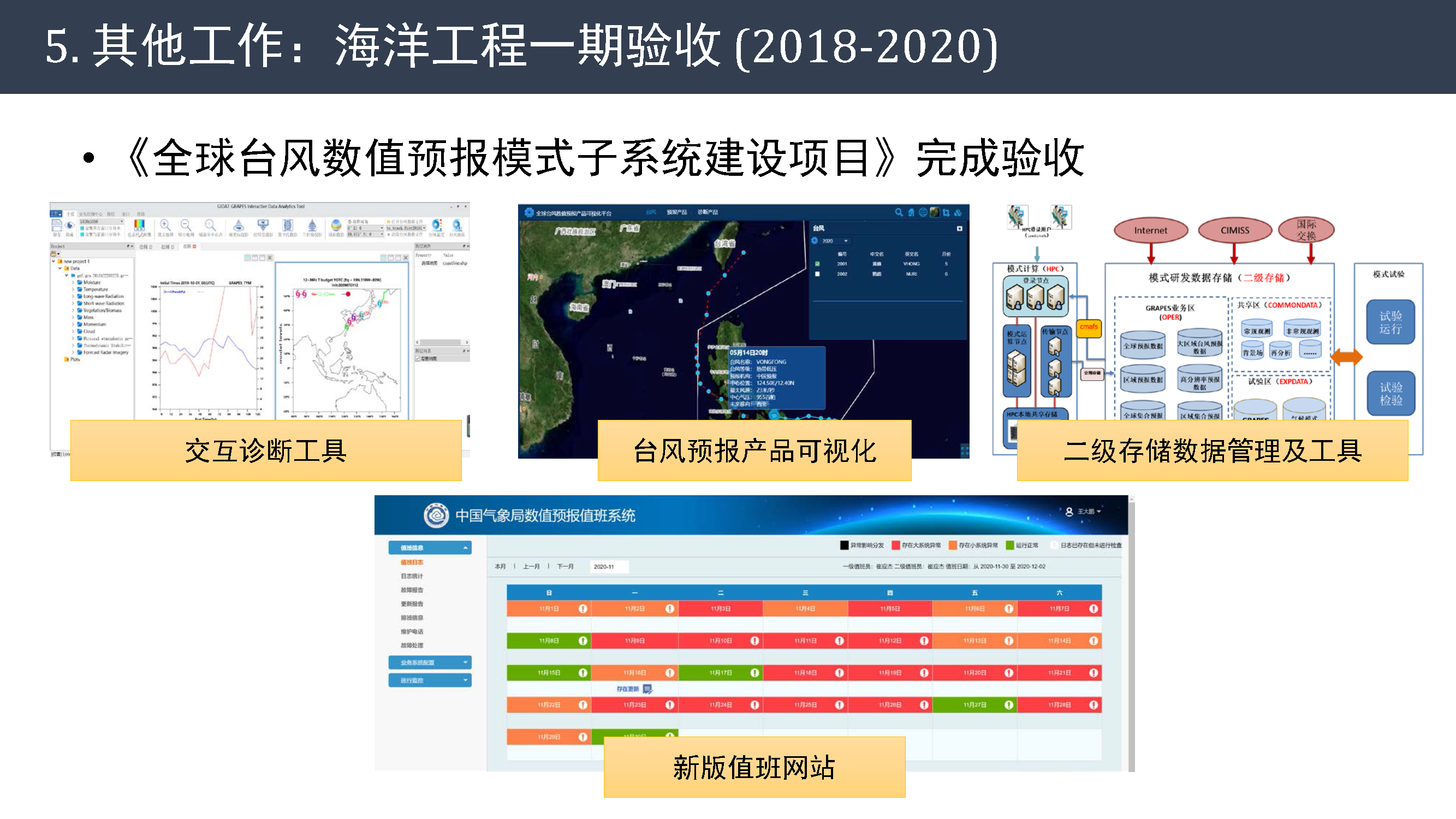
今年还完成海洋工程一期《全球台风数值预报模式子系统建设项目》的验收工作,该项目提供交互诊断工具、台风预报产品可视化、二级存储数据管理及工具和新版值班网站等多项成果。
下一步工作计划

明年计划继续
- 研究数据处理和诊断分析相关技术;
- 完善 NWPC 消息平台,完成现代化专项验收
- 进一步加强对历史数据的统计分析
开源
最后再做个倡议。以上绝大部分工作我都已经在 Github 上开源,大家感兴趣可以访问下面这个网址。 强烈推荐大家也一同加入到开源的大家庭中。
结语

感谢大家一年来对我工作的帮助与支持,谢谢大家!
