论文阅读:适用于地球系统模式工作流的轻量并行Python工具
K. Paul, S. Mickelson, J. M. Dennis, H. Xu and D. Brown, “Light-weight parallel Python tools for earth system modeling workflows,” 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, 2015, pp. 1985-1994, doi: 10.1109/BigData.2015.7363979.
论文介绍用于制作 CMIP 6 数据集的两个轻量化并行 Python 工具:
- PyReshaper:将多个时间片 (time-slice) 数据转换为时间序列 (time-series) 数据
- PyAverager:计算时间序列数据的统计值
另外,本文开发工具的指导思想也值得借鉴。
论文
以下内容摘选自论文,并附加笔者个人理解,如有偏差,敬请谅解。
介绍
生成 CESM 模式的 CMIP 6 数据集需要处理 12 PB 的原始输出。 之前使用的串行处理工具无法处理如此庞大的数据,论文开发轻量级并行 Python 工具替换现有方案中的瓶颈软件 (bottleneck software)。
论文仅关注地球系统模式中的一个方面,即数据密集型问题。
本文涉及三类文件
时间片文件
time-slice files
地球系统模式通常会在积分过程中逐步输出文件。 例如 GRAPES MESO 3KM 的业务系统每积分一小时会输出二进制格式的原始文件。 地球系统模式一般输出更长时间间隔的 NetCDF 格式文件。
这类文件称为时间片文件 (time-slice files)。
但随着模式分辨率提升和输出的要素场增加,时间片文件方便进行诊断分析。
因为大多数后处理分析 (post-processing analyses) 仅使用少量的变量,但需要相对较长时间的序列。 执行诊断分析需要获取所有的时间片文件,会增加分析过程的耗时。
所以需要将时间片文件转换为时间序列文件。
时间序列文件
time-series files
每个文件只有一个变量,但包含长时间序列。 这样分析数据时仅需获取少量文件。
注:另两种处理方式
- 将每个时间点每个变量全部打散为单个的文件,类似 MICAPS
- 对时间片文件保存索引信息,使用额外工具向用户直接提供提取后的文件,类似 NWPC 数据平台
将时间片数据转换为时间序列数据非常耗时,CESM 耗费 15 个月生成 CMIP5 数据集。
气候态数据
climatology (ie, averaged) data
另一个挑战是从时间序列文件中计算气候统计值。 虽然这一步骤不是主要的瓶颈,但在某些高分辨率数据集上计算也需要花费 7 个小时。
设计思想
考虑到与现有工作流的兼容性,引入新工具必须是一个渐进的过程。
完全变革性的解决方案需要更长时间的开发,更长时间的用户培训,会影响用户使用。 所以,论文借鉴 Principle of Least Astonishment,仅针对工作流中的独立瓶颈脚本,开发轻量级并行 Python 工具替换这些脚本。
与变革性方案对比,有如下优势:
- 渐进式:大问题可以分解成若干小的“子问题”,可以针对这些子问题设计非常小的单独的软件解决方案。 如果将来证明解决方案不足,则可以轻松地以较小代价替换。
- 重大影响:解决方案可以针对现有解决方案中极有问题或表现不佳的部分,从而可以通过较小的增量变化来实现较大的效果。
- 快速部署:每个增量解决方案都可能足够小,可以非常快速地进行原型设计和产品化。
- 以用户为中心:如果有必要,可以将总体使用更改保持在最低水平。
- 维护最少:同样,与该方法的渐进性有关,解决方案足够小,可以由尽可能少的人轻松维护。我们的目标是维护仅占用单个开发人员的一小部分时间。
- 分层:可以在其他增量解决方案之上构建更复杂的任务和解决方案。
新产品
原有脚本基于命令行工具 NCO (NetCDF Operators) 开发。 论文使用 Python 重新开发工具,新库如下图所示,基于通用软件包开发。
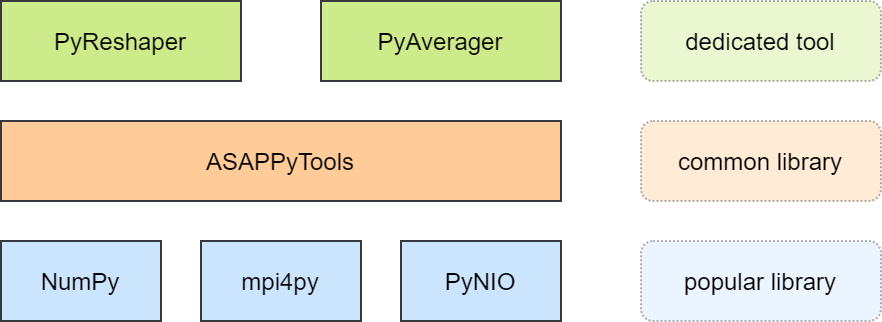
选择 Python 的理由
Python 适合快速原型开发,有强大和持续增长的科学计算开发社区,同时 Python 是非常高层的语言。
注:强大的科学计算开发社区意味着有通用的科学计算库,使用通用工具开发的新工具更方便用户使用和集成。
Python 脚本可以无缝集成进现有由脚本驱动的 CESM 工作流中
注:Shell 也是脚本语言,工作流中运行 Shell 和 Python 脚本没有本质的区别,当然也便于集成
Python 代码非常容易扩展,或与未来代码共享,以提供新的解决方案
注:可能是因为 Python 脚本通常就是源代码,只有提供源代码才有可能让用户进一步集成应用
Python 脚本 (使用 mpi4py 包) 非常容易并行化,并与 CESM 使用的现有 MPI 批处理环境集成
使用最少依赖的 Python 脚本,可以非常容易移植到其他超算系统中
注:底层兼容性问题已被基础科学计算包解决,Python 脚本仅需要关注业务逻辑。 如果仅提供编译后的可执行程序,那么工作流就没有任何可移植性。
测试方法和数据集
将 NCO 串行脚本生成的数据作为标准数据集。
首先验证 Python 工具生成的数据是否正确,然后再对比性能。
性能指标如下:
- duration:工具运行并生成正确结果的总体时间
- throughput:所有输入数据大小 / 运行时间
注意:计算节点和共享文件系统都有 I/O 吞吐量限制
PyReshaper
PyReshaper 用于将时间片数据转为时间序列数据,数据转换操作的示意图如下所示。
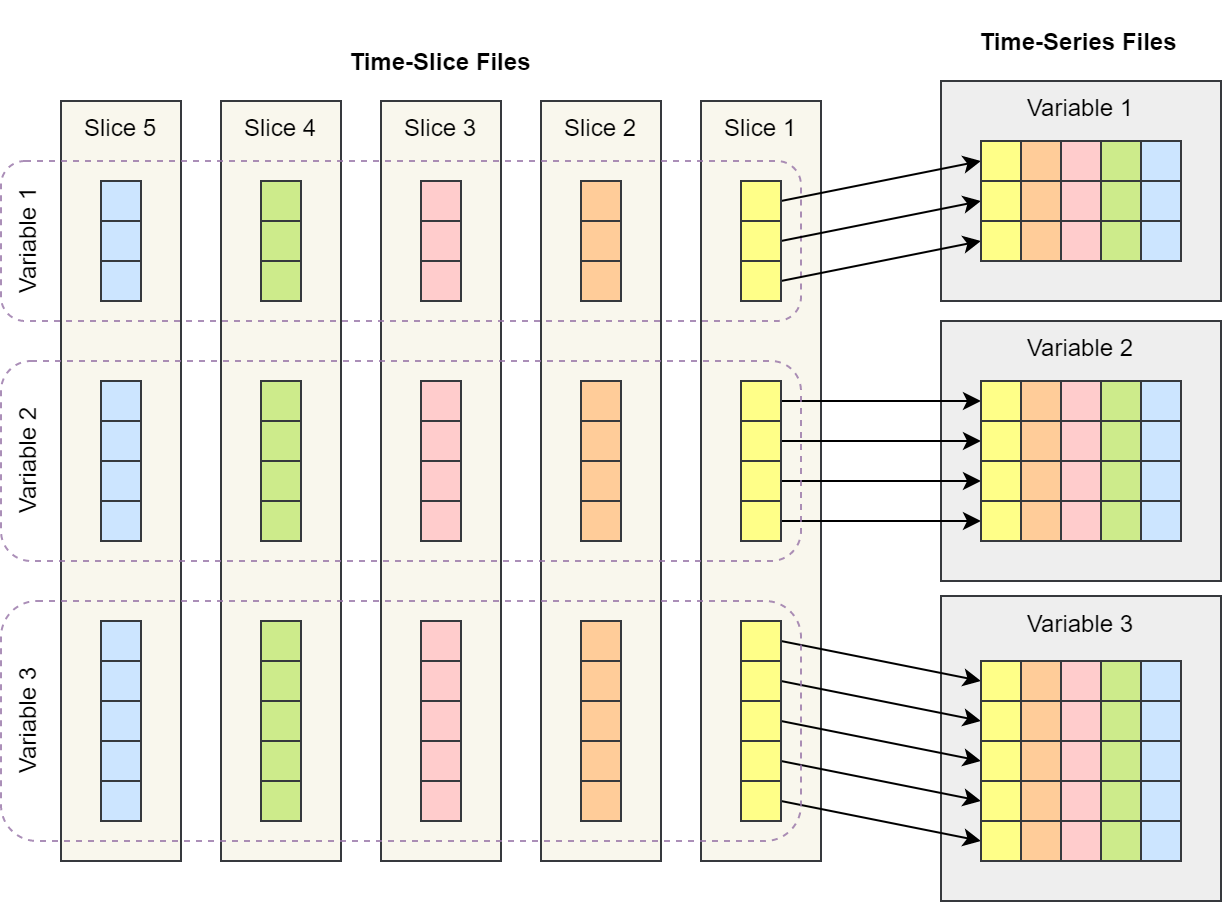
时间片数据转为时间序列数据示意图,根据论文图片重新绘制
技术方法
用两种方式实现上述方法
任务并行
task parallelization
任务并行算法中,每个进程 (rank) 负责输出一个变量的时间序列文件。
每个进程需要打开和读取所有时间片文件,但仅输出一个文件。
这是最简单的并行实现方式,相当于在每个 MPI 进程中执行独立的串行操作,进程之间不需要消息通讯。
缺点就是进程数受变量总数限制,超过变量总数的 MPI 进程不会被分配任务。
PyReshaper 使用该方法实现。
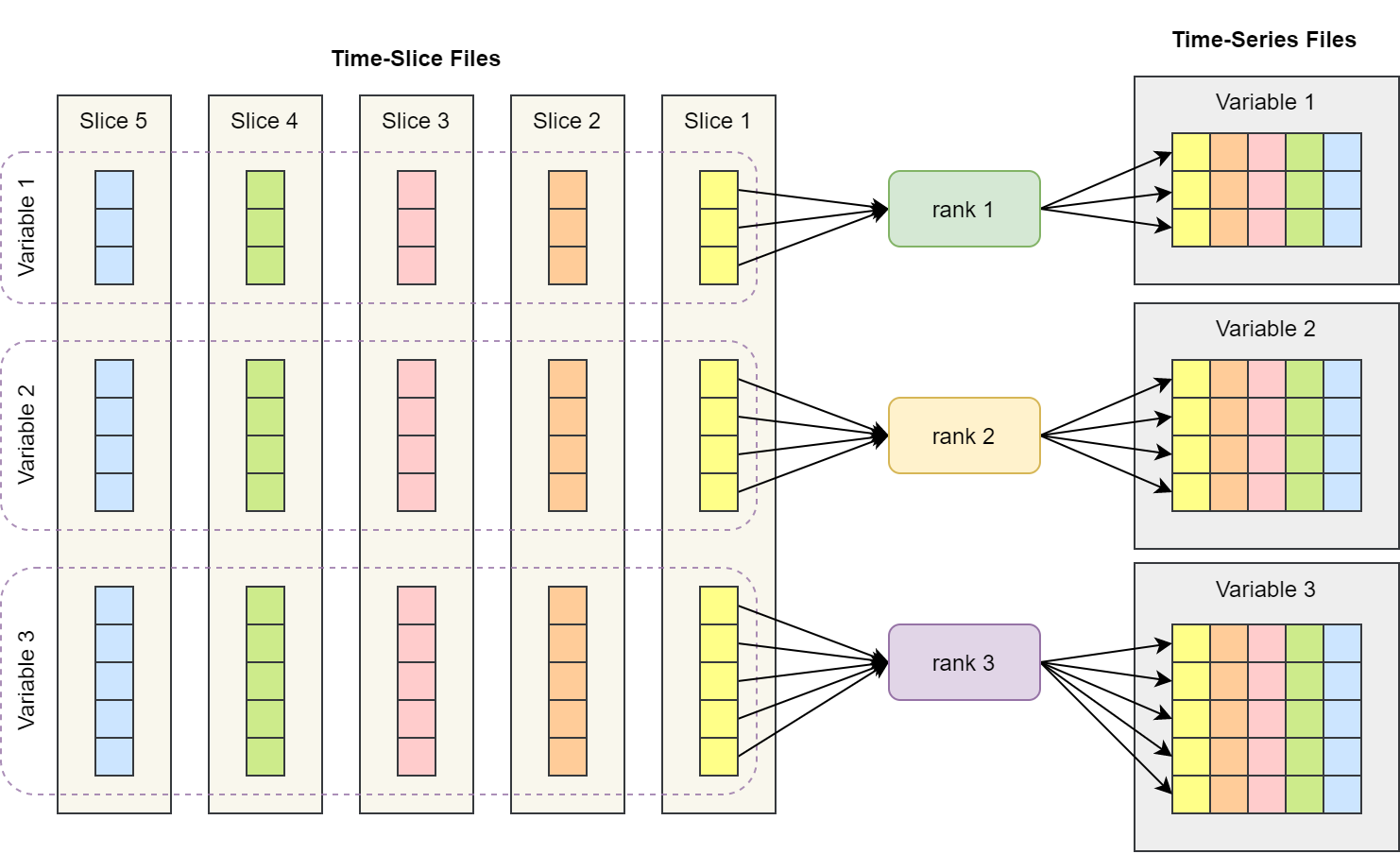
时间片转时间序列数据任务并行示意图,根据论文图片重新绘制
数据并行
data parallelization
数据并行算法将时间序列变量任务分配给多个进程,这些进程将会同时同步写入一个时间序列文件。
缺点是更复杂,更难有效实现。
论文中使用 Fortran 语言编写的 NcReshaper 实现该方法,该库基于 PIO (Parallel I/O Library) 和 MPI 实现。
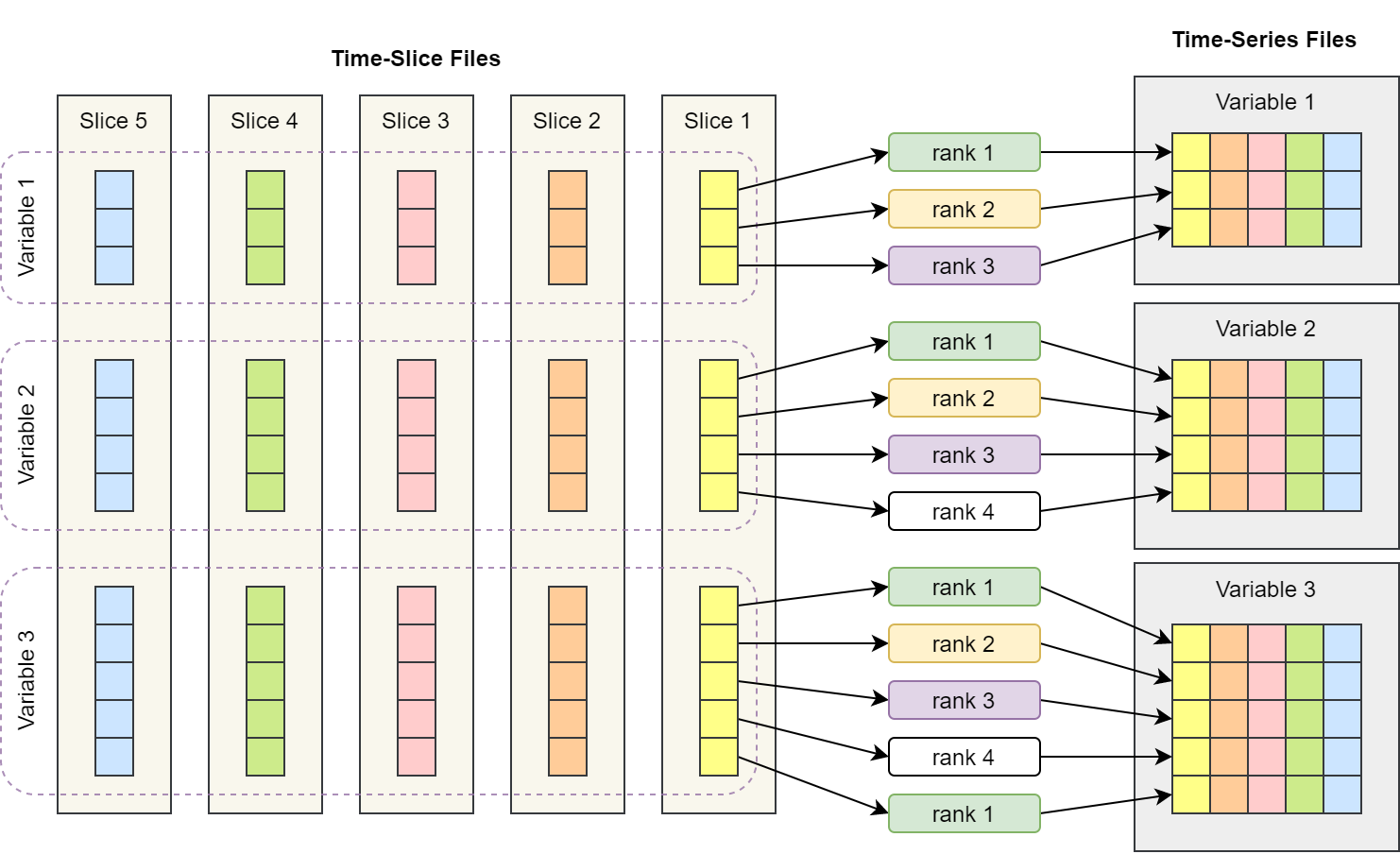
时间片转时间序列数据数据并行示意图,根据论文图片重新绘制
结果
并行方法占用 16 个 CPU 核心,每个节点 4 个。
多种方法 duration 和 throughput 对比
注意:纵坐标是对数坐标。
其中:
- NC3:NetCDF3
- NC4:NetCDF4
- NC4-CL1:NetCDF4 compressed (compression level 1)
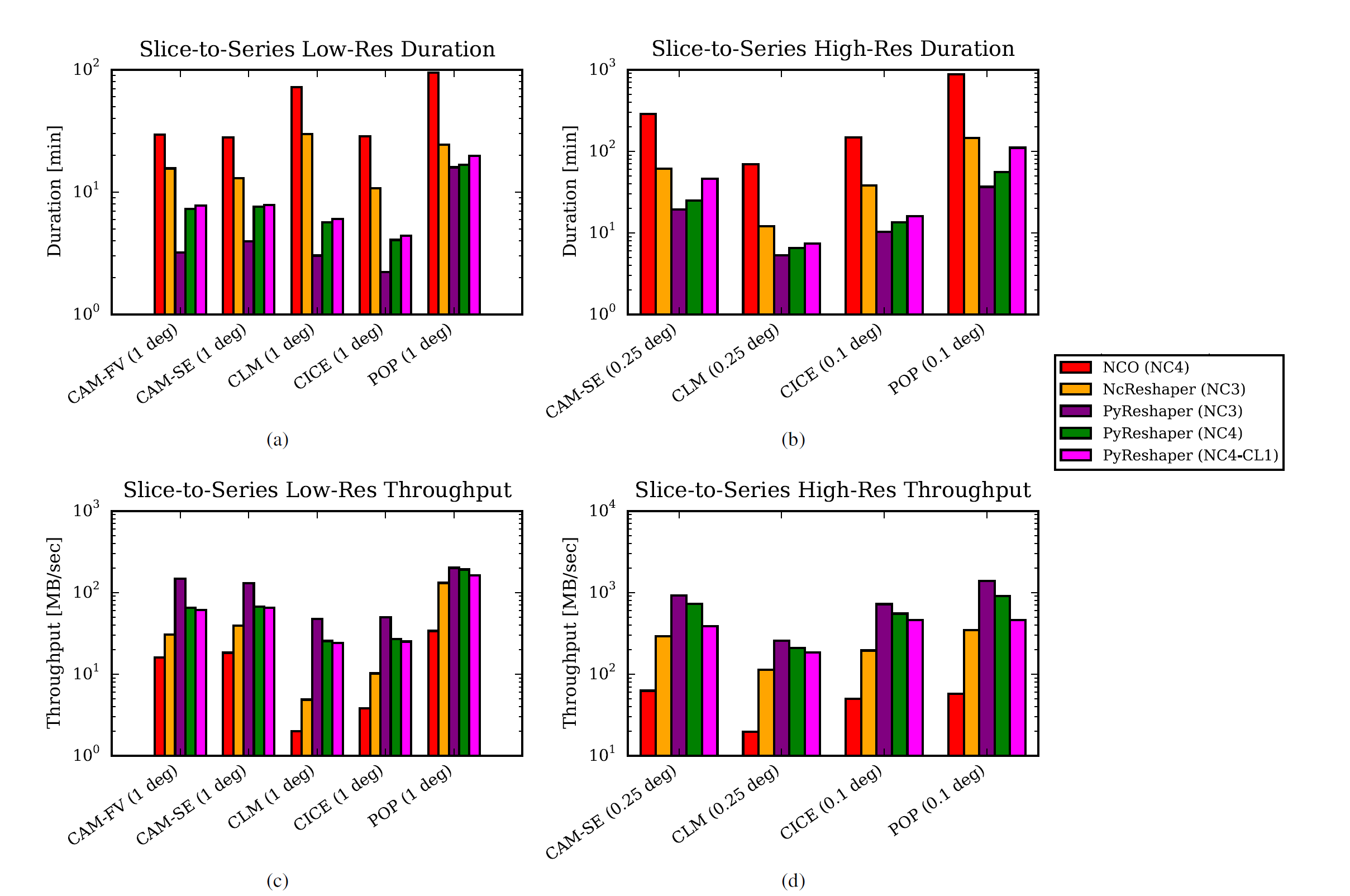
图片来自论文
结果显示,对大多数试验,使用任务并行的 PyReshaper 比使用数据并行的 NcReshaper 效率更高。
PyReshaper 可扩展性
PyReshaper 的扩展性受变量数限制
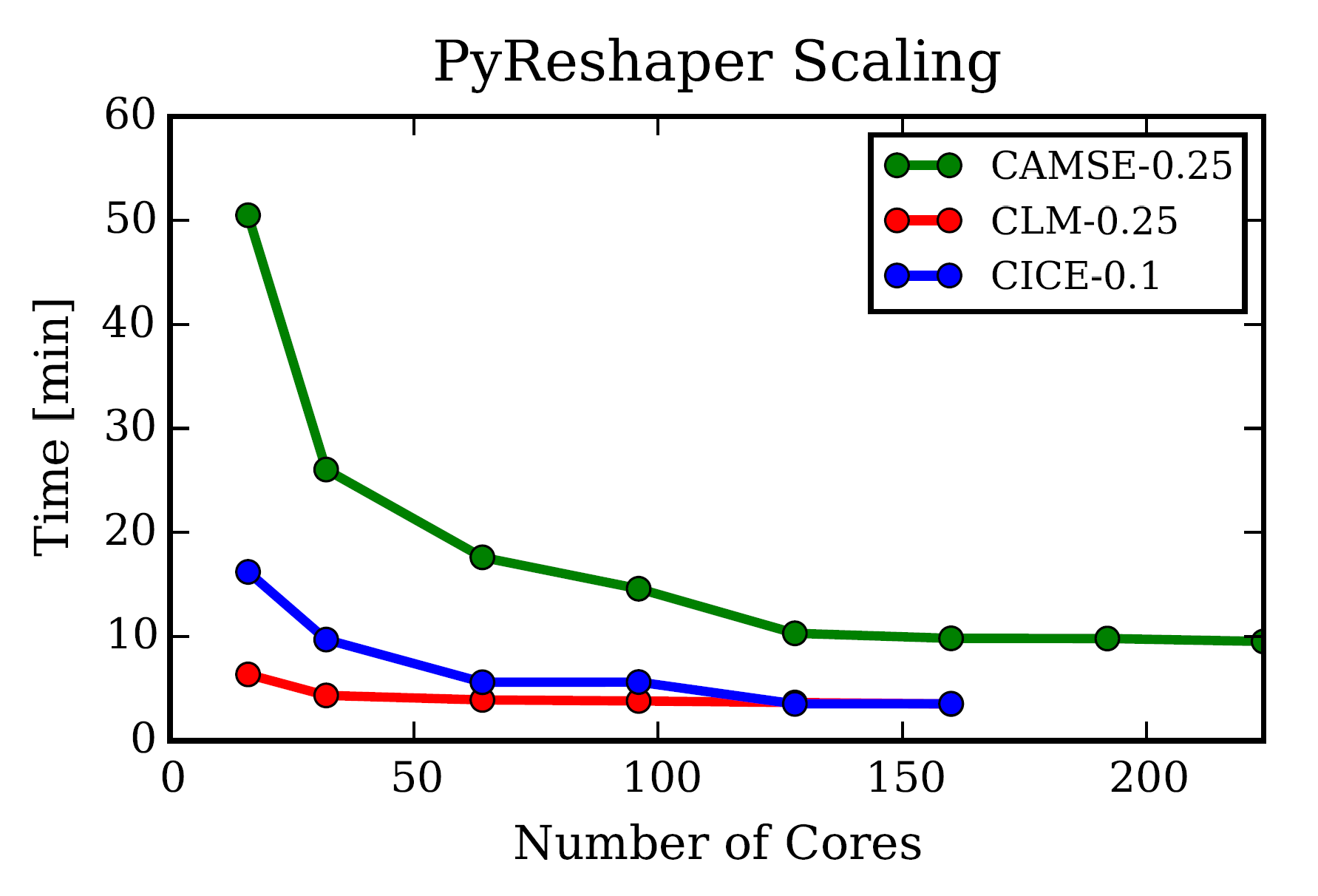
图片来自论文
PyAverager
气候模拟数据分析通常包括两个阶段:
- 计算气候平均值,I/O 密集型计算
- 执行诊断包,生成大量图片,不是主要瓶颈
从时间序列数据计算气候均值的步骤:
- 从时间序列数据中提取变量
- 计算均值
- 将均值结果添加到最终的文件中
技术方法
PyAverager 使用 mpi4py 和 PyNIO 实现任务并行算法
PyAverager 将 MPI 任务分组,称为 sub-communicator。 每组接收需要计算的变量列表,并同时计算统计值。 每组中有一个专用进程用于输出气候态文件。 所有其他 MPI 任务一次读取一个时间序列变量,并累加到统计缓存中。 统计缓存被发送到一个 MPI 进程,顺序生成气候态文件。
通常情况下,气候统计包含多种类型的统计。 下图是仅有一种统计类型的算法示意图
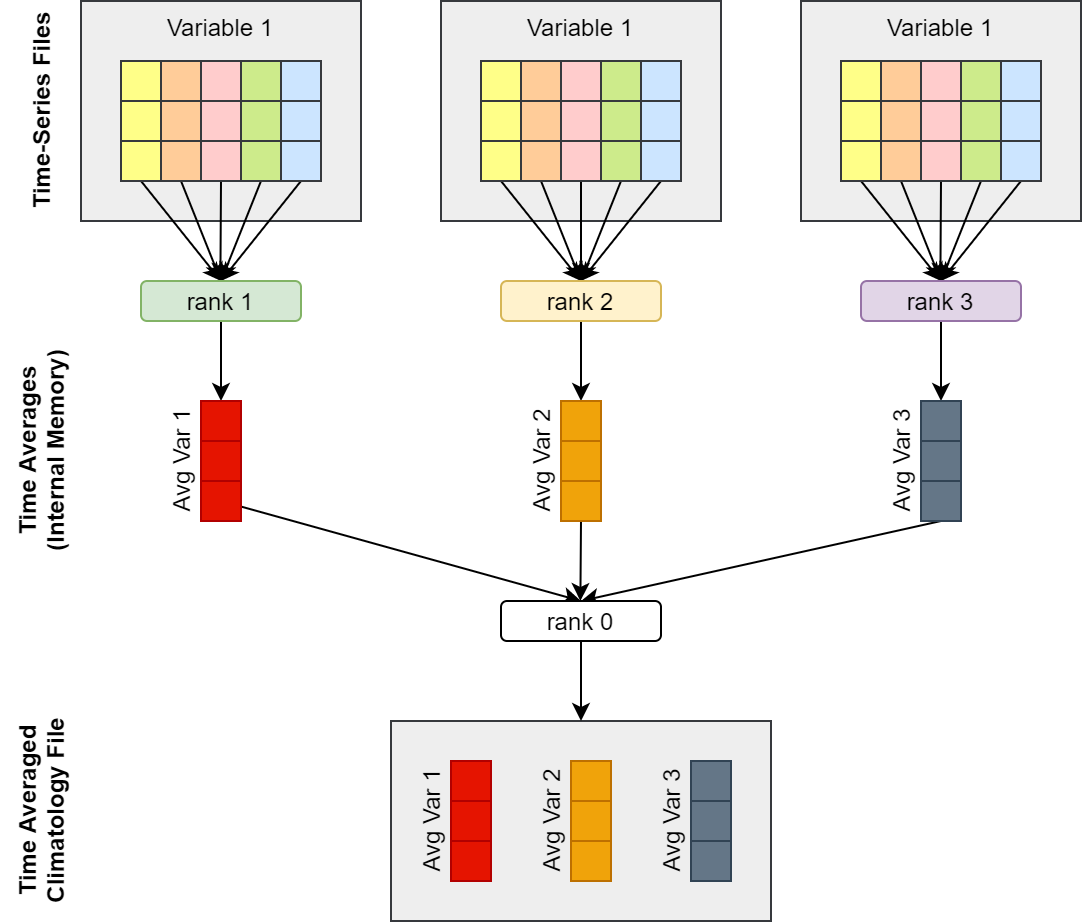
时间序列数据计算气候态均值算法示意图,根据论文图片重新绘制
结果
运行环境:
低分辨率
- NCO:1 个专用节点
- SWIFT:4 核/节点,4 节点,共 16 个核
- PyAverager:8 核/节点,20 节点,共 160 个核,Geyser 队列
高分辨率
- NCO:GPGPU 和 BigMem 队列
- SWIFT:4 核/节点,4 节点,共 16 个核 POP 0.1 度时间片数据使用 1 核/节点,4 节点,共 4 个核,BigMem 队列
- PyAverager:8 核/节点,20 节点,共 160 个核 POP 0.1 度时间片数据使用 Geyser 队列
多种方法 duration 和 throughput 对比
PyAverager 在时间序列数据上优于串行 NCO 方法,在时间片数据上与串行 NCO 相当或略优。
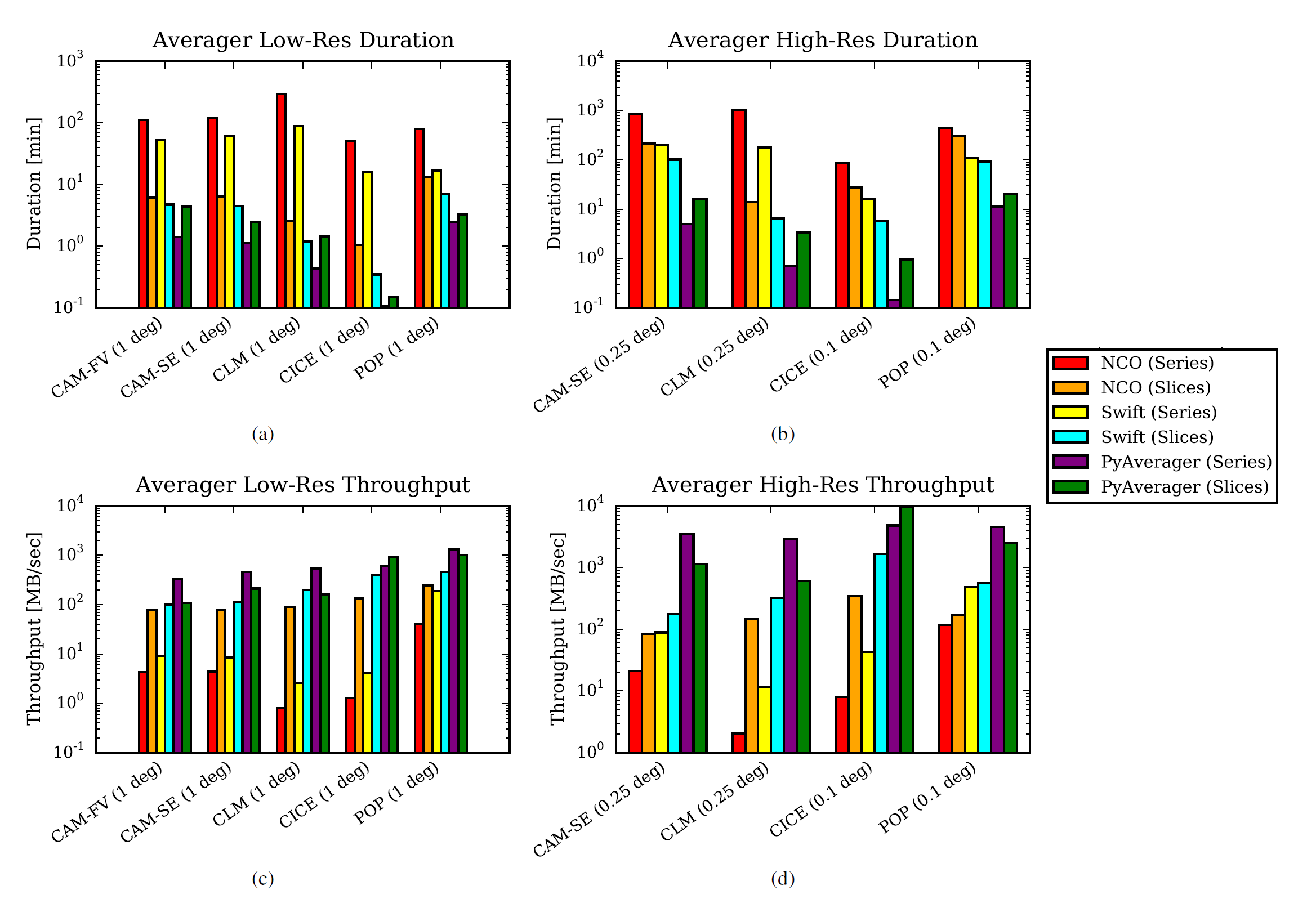
图片来自论文
PyAverager 可扩展性
使用 CAM-SE 0.25 数据集
读写操作耗时差不多。 超过 128 核心 (8 核/节点,16 节点) 后,运行时间几乎没有变化,受 I/O 性能影响。 后续版本会研究如何提高性能。
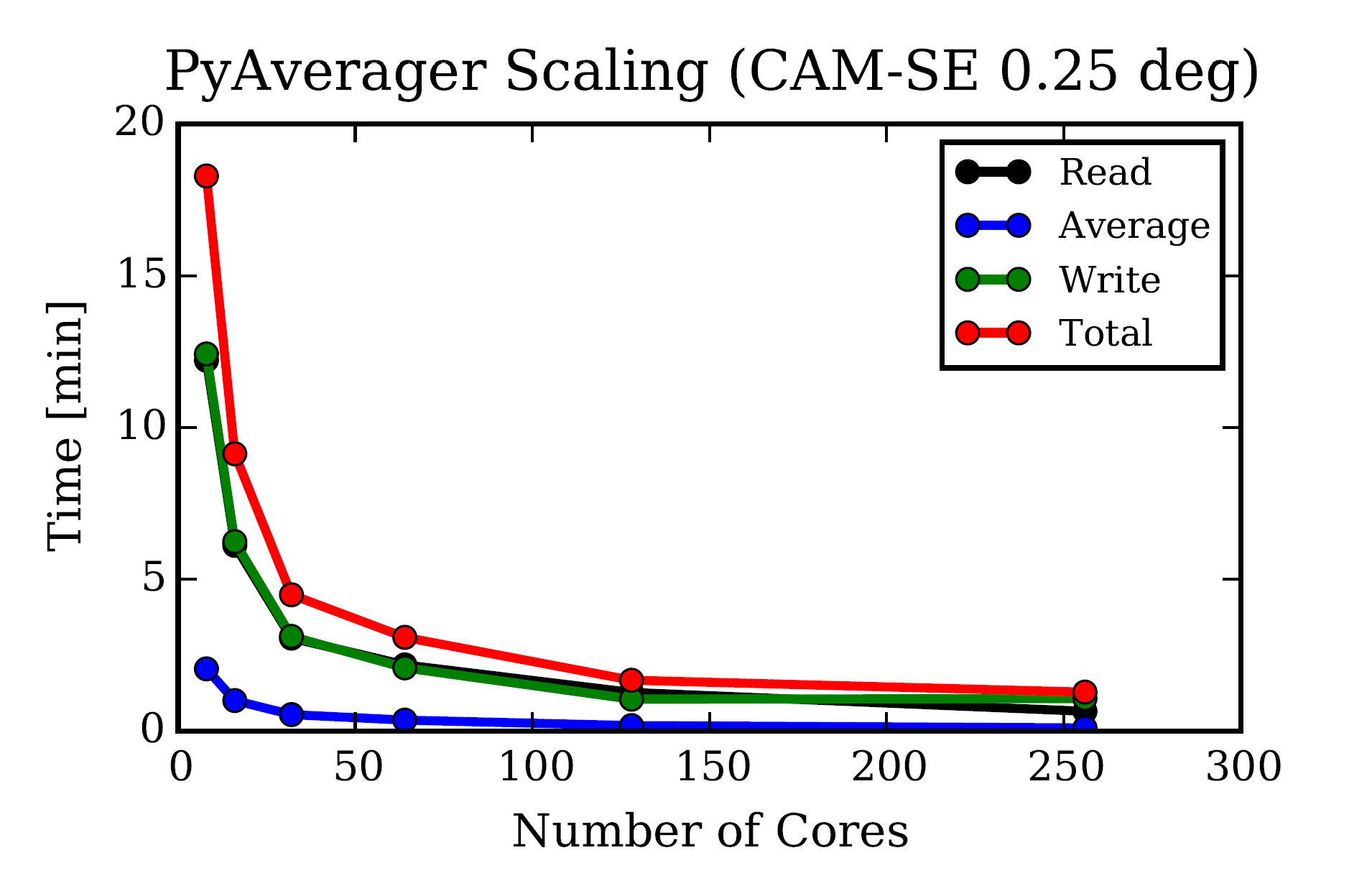
图片来自论文
相关工作
注:论文于 2015 年发表,不代表适合 5 年后的 2020 年。
ParCAT
Parallel Climate Analysis Toolkit
注:没找到源代码
使用 C 和 Parallel NetCDF,实现任务和并行算法,提供命令行工具。
但 C 语言不如 Python 方便扩展。
UV-CDAT
Ultrascale Visualization Climate Data Analysis Tools
使用 ParCAT,提供分析大规模气候数据集的全面工具集,包括并行可视化和后处理计算。
太庞大,难以安装和集成,需要重新培训用户
TECA
Parallel Toolkit for Extreme Climate Analysis
https://github.com/LBL-EESA/TECA
并行工具,专注提供特定的操作集合以从大规模气候数据中识别极端事件
正在开发,没有公开发布。
注:项目已开源
NCO
NetCDF Operators
一组可执行工具,对 NetCDF 数据执行单一原子操作。
NCO 通过 MPI 和 OpenMP 提供并行支持,但仅面向计算密集型程序和不是 I/O 密集型程序。
原子操作的设计导致会串联使用不同的 NCO 操作,通常需要使用磁盘文件系统保存中间结果。
CDO
Climate Data Operators
https://code.mpimet.mpg.de/projects/cdo/
类似 NCO,但提供基于管道的并行方式,可以在执行多个原子操作时将中间结果保存在内存中。
但将 PyReshaper 和 PyAverager 执行的操作用链式方式实现时,通常不能最小化数据在磁盘或内存中的移动。
Pagoda
注:没找到源码
模仿 NCO,基于 Globa Arrays,PNetCDF 和 MPI 实现并行。
与 NCO 有一样的问题,需要三步才能完成计算时间序列值的均值。
SWIFT
http://swift-lang.org/main/index.php
两篇参考文件中使用 SWIFT 脚本语言实现并行分析气候数据
[33] M. Woitaszek, J. M. Dennis, and T. Sines, “Parallel high-resoution climate data analysis using swift,” in 4th Workshop on Many-Task Computing on Grids and Supercomputers (MTAGS), Seattle, WA, November 2011.
[34] S. Mickelson, R. Jacob, M. Wilde, and D. Brown, “How to use the task-parallel omwg/amwg diagnostic packages,” http://www.cesm.ucar.edu/events/ws.2012/Presentations/Plenary/parallel.pdf.
注:以下内容摘自官方网站
Swift 是一种面向数据流的粗粒度脚本语言,支持数据集类型和映射,数据集迭代,条件分支和过程组合。
结论
两个库只用几天就完成原型设计,仅用几个月就完成实现和部署。 这两个库可以替换现有的脚本,并使用同样的批处理 MPI 框架,可以无缝对接现有 CESM 工作流。 基于轻量级并行的 Python 实现可以很方便进行扩展。
两个工具对于 CESM 工作流中的目标瓶颈问题,都有显著的性能提升。 PyShaper 提升 13 倍,PyAverager 提升 400 倍。
讨论
以下均为笔者个人理解,如有偏差,敬请谅解。
笔者之前一直觉得 并行编程 是一门很高深的学问,实际上这一种很严重的错觉。
虽然并行程序往往都非常复杂,但并不是所有并行算法都如同数值天气预报模式系统一样需要专业的领域知识,复杂的程序设计和大量的编程训练。
论文中两个工具使用的算法实际上都是同一种类型:任务并行,即将串行执行的任务同时运行,每个任务之间相互没有通讯。
这是一种最简单的并行实现方式,但却能带来巨大的效率提升。
论文中的工具都使用 mpi4py 实现并行计算,但实际上现代编程语言和工具库已提供更多的方法进一步简化并行程序开发。
协程是一种轻量级的并行工具,笔者在如下文章中使用 Go 语言提供 goroutine 实现多协程编程:
《使用Bulk API向ElasticSearch发送数据》
多线程工具已成为是现代编程语言的标配,笔者在如下文章中使用 C++ 内置库实现多线程编程:
批量数据处理任务使用 Python 的 Dask 库能很容易实现并行算法,笔者在如下文章中使用 Dask 库实现并行编程:
论文中开发工具的指导原则也非常值得借鉴:
- 开发小工具,便于单人维护
- 必须有足够的理由才能引入新工具到现有系统中,因为所有新工具都需要额外的培训和维护成本
- 针对工作流中的单一瓶颈开发新工具解决,对现有工作流的影响降到最低,尽量保持用户接口的稳定
- 先验证是否可以得到一致的结果,再对比执行效率