2020年第三季度工作总结
随着全年最重要的任务 业务系统升级 于第二季度完成,我在最近三个月有充足的时间做自己感兴趣的工作,开始进入对转型的探索期中。 不过,转型不是想一想就能实现的,尤其是像我这样全凭自己探索方向,缺乏足够的指导,连最终的目标都没有确定,就更不用说能否成功了。
在总结第二季度工作时,我已列出第三季度的计划。 虽然我确实是按照计划开展了后续工作,但却没能实现所有的目标。
系统建设
业务系统没有大规模的升级更新,但因为运行环境和产品需求,进行了一些维护级更新。
FTP 切换
因服务器下线等问题,调整 FTP 上传,将 GRIB 2 产品发送给 CTS。 最终目标是不再直接向外单位用户发送产品,而是将产品全部传输至信息中心,再由信息中心进行分发。
这种方式会极大降低运维成本,也符合预报司最新的数据管理规定。 但增加的中间环节会导致与最终用户脱离,我们无法明确知道产品到底是哪些用户在用。 之前就已有类似的情况发生,最终用户并不知道数据的流转方式,缺数据时用户的第一反应很可能是产品没有正常生成。 不过,我们部门更关注如何保证产品成功发送,对于提供服务的时效性并不是关注的重点。
产品分发管理一直是业务系统中欠缺,但又不是必须的功能。 我曾经做过一部分工作,但发现想要将分发管理与实际分发相结合,需要重构产品分发流程,在现有系统框架下很难实现,就不再继续这方面的工作。 后续会将产品制作全部放到气象大数据平台中,也许可以重新开展产品分发方面的工作。
新产品
GRAPES TYM 后处理增加为 NMC 制作的台风动画 GIF 产品。
我认为针对单一特殊需求而在业务系统中增加新任务不是最佳实践,业务系统应该保持稳定。 不过,我们暂时没有其他手段能实时制作产品,也许气象大数据云平台能提供合适的工具。
气象大数据云平台培训
参加了 7 月 30 日信息中心关于气象大数据云平台的在线培训。 因为没有可用账户,缺乏使用经验,所以收获有限,具体讨论参见:
另外在为基于加工流水线的产品后处理项目准备文字材料时,翻译了 ECMWF 之前的一篇报道
运维
应当从工作中提炼科学问题,不能仅停留在工具开发层面。 第三季度,我没能从运维工作中总结出新的科学问题,也就是说没能设计出与运维相关的新的算法。
这是一件值得警惕的事情,不能为了开发而开发,应该将开发工具当成验证算法的一种方式。 我应该更关注工具背后所使用的算法,研究已有算法是否有改进空间,研究运维需求是否能衍生出新的算法。
最近看到国家气象信息中心发布第一批和第二批 创新团队骨干成员遴选公告,其中部分岗位职责正好与数值预报模式系统业务系统相关,可以作为提炼科学问题的参考。 比如:
- 模式运行流程调度技术(自主的流程调度原型系统)
- 气象数值模式特征分析
- 流水线调度和算法集成技术研发(云平台加工流水线与HPC并行计算的调度协同)
- 数据全生命周期监控技术研发
- 业务配置与控制技术研发
- 智能化运维技术研究
- 业务报表及评估分析
- 告警通知机制及可视化技术研发
下阶段可以参照上述岗位及相应的职责要求,思考后续应该如何开展工作。
值班网站
在全科同志的共同推动下,值班系统的报警质量已有显著的提升。
8 月份 HW 行动期间,旧版值班系统网段被封,无法继续使用。 尝试使用新版值班网站记录值班日志,可以满足日常维护记录的需求。 计划最晚于明年汛期之前正式切换,替代旧版值班系统。
ecFlow
为统计每天运行的作业数量,使用 ecFlow API 开发获取任务节点数的脚本,详情参看:
业务高峰时段,ecFlow UI 界面经常出现无法获取服务运行状态的情况。 为了寻找原因,在信息中心的支持下,将 ecFlow 脚本输出目录切换到 SSD 盘,基本解决界面卡住的现象。 详情请查看:
下阶段可以考虑研究将业务系统使用的 ecFlow 从 v4 版本切换到 v5 版本的可行性,研究切换对业务系统本身和相关运维系统的影响。 当然这不是迫切的任务,我们对业务系统底层的非兼容性更新一直保持谨慎的态度。
消息平台
二季度工作总结中提到,现代化专项消息平台是第三季度的工作重点。 本季度,主要完成以下任务
新消息
封装 ecflow_client 命令,每次调用会发送一条 ecflow-client 类型消息。
下面是一条实际的消息记录:
{
"app": "nwpc-message-client",
"type": "ecflow-client",
"time": "2020-09-29T07:01:13.936647058Z",
"data": {
"args": [
"modelvar_036"
],
"command": "event",
"ecf_date": "20200929",
"ecf_host": "login_b06",
"ecf_name": "/check_grapes_meso_3km/03/initial",
"ecf_port": "31071",
"ecf_rid": "203564",
"ecf_tryno": "1",
"envs": null
}
}
已在业务系统中进行评估,实时发送消息,包括:
- 辅助系统 service_checker
- 辅助系统 system_checker
- 业务系统 globalchartos
目前仅将 ecflow 消息数据存储到 ES 库中,下一阶段计划对数据进行分析,验证该消息数据是否能在一定程度上代替 ecFlow 日志。
分析
针对产品消息数据,使用自助法计算 95% 置信区间,作为产品生成的标准时间。 保存的标准时间如下所示:
{
"app" : "nwpc-message-tool",
"type" : "prduction-standard-time",
"time" : "2020-08-25T11:29:00.991260",
"data" : {
"system" : "grapes_meso_3km",
"stream" : "oper",
"type" : "grib2",
"name" : "orig",
"start_hours" : [
{
"start_hour" : "00",
"times" : [
{
"forecast_hour" : 0,
"upper_duration" : "P0DT4H54M48S",
"lower_duration" : "P0DT4H33M49S"
},
{
"forecast_hour" : 1,
"upper_duration" : "P0DT5H0M34S",
"lower_duration" : "P0DT4H38M33S"
}
]
},
{
"start_hour" : "03",
"times" : [
{
"forecast_hour" : 0,
"upper_duration" : "P0DT3H28M1S",
"lower_duration" : "P0DT3H12M40S"
},
{
"forecast_hour" : 1,
"upper_duration" : "P0DT3H32M4S",
"lower_duration" : "P0DT3H16M35S"
}
]
}
]
}
}
为了加快计算效率,使用 Dask 加速不同时效标准时间的批量计算。
标准时间计算算法没有对离群点进行特殊处理,计算得到的部分时间与整体趋势不一致,有待进一步优化。
可视化
参考 NMC 关键产品监控网页,基于 Vue.js 开发消息平台的可视化面板。
使用 Vuetify 制作如下页面:
各系统逐时效产品生成时间
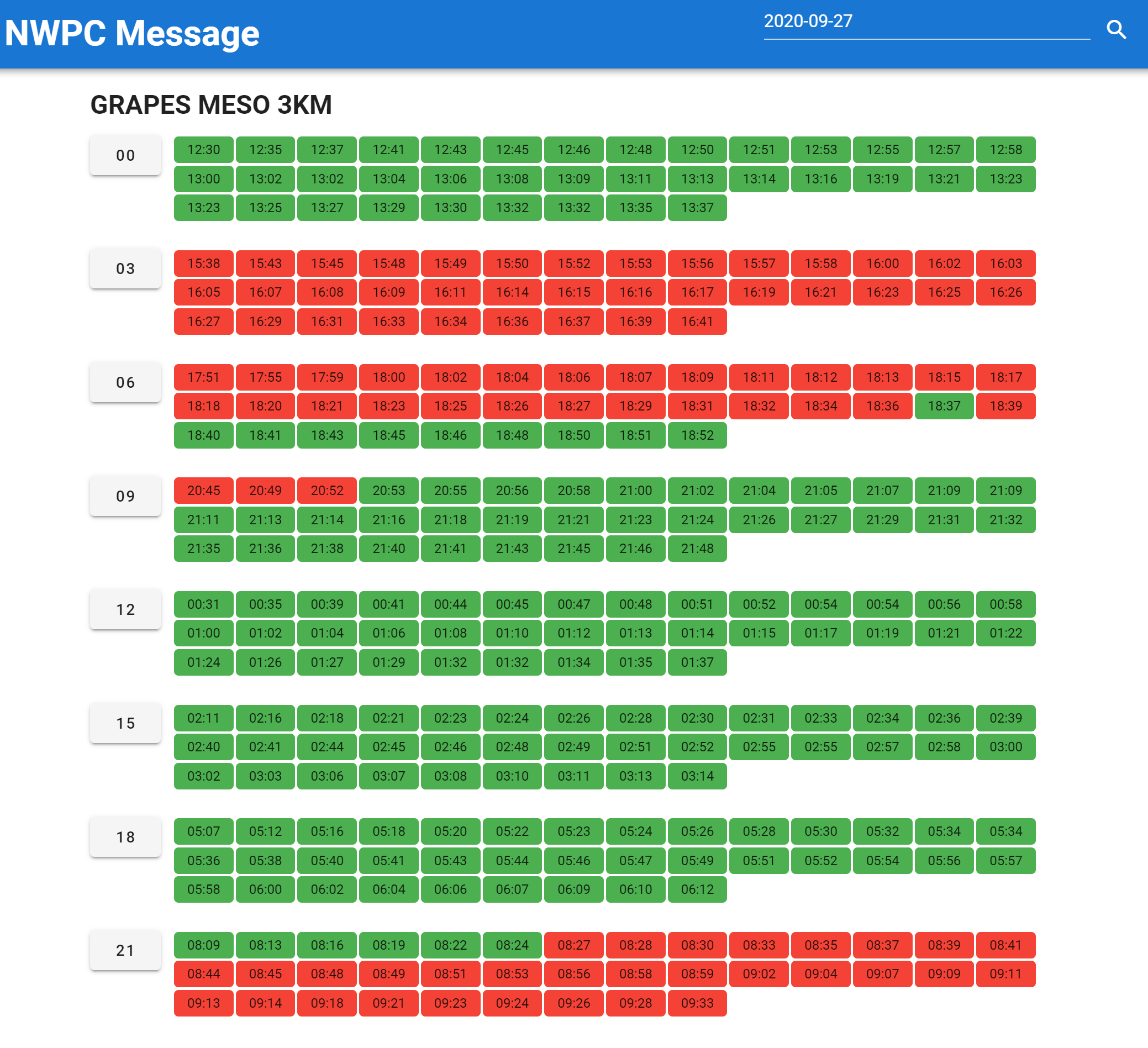
使用 Bokeh 绘制下面两类图形:
单个时次多时效产品生成时间
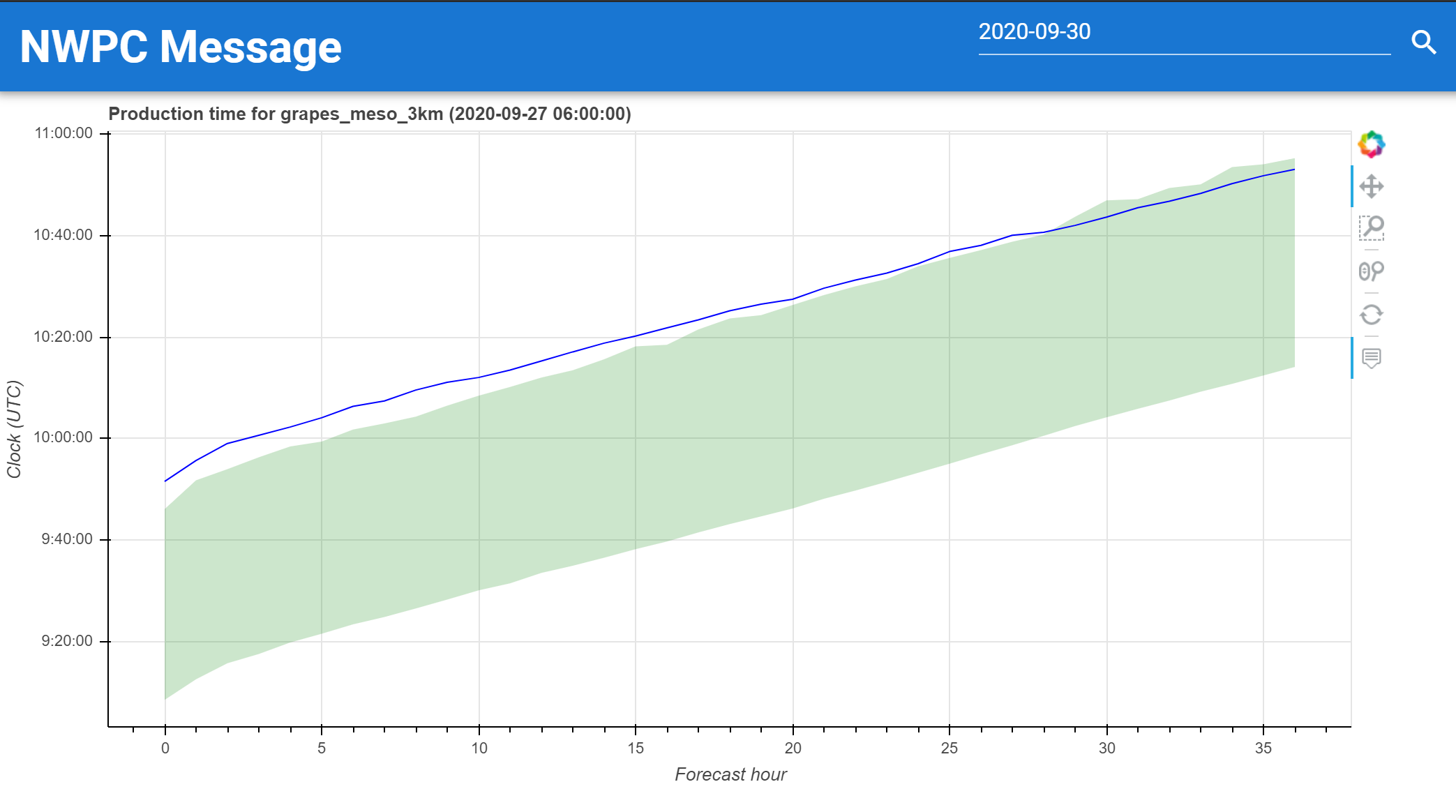
单个时效多时次生成时间
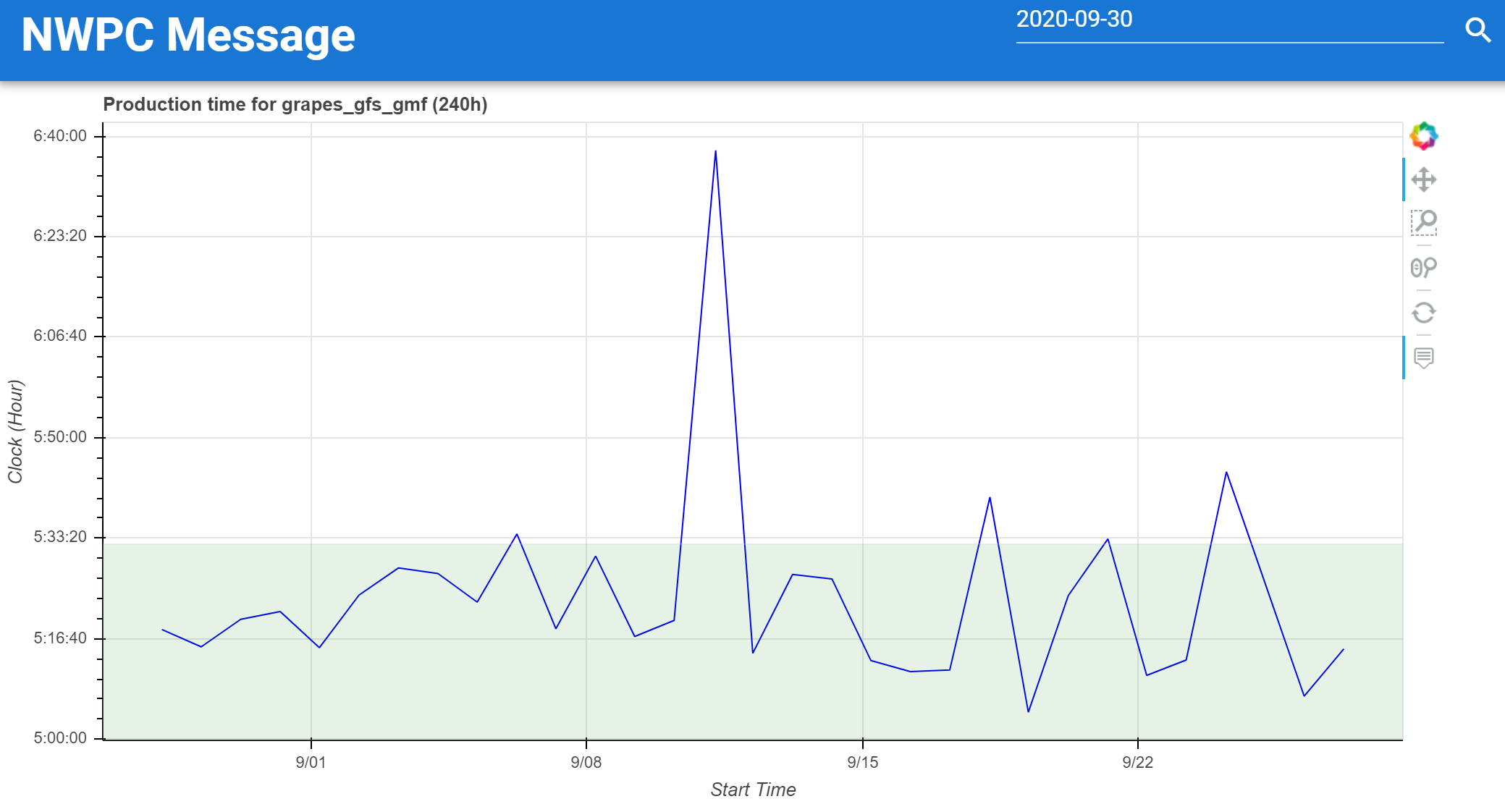
可视化面板还需进一步优化和开发。
另外,在数据量不大的情况下,从 ElasticSearch 库检索数据已出现连接超时的问题,下一阶段要研究如何优化 ES 库存储。
数据
原计划继续开发数据工具 nwpc-oper/nwpc-data,实际第三季度仅增加少量数据的配置文件,没有功能上的更新。
下一阶段将再次进行本应在第三季度进行的开发工作,即提高批量数据的处理效率。 同时应该将该工具从仅支持 GRIB 2 扩展到支持更多种类的数据类型,让该工具成为原始数据与算法库之间桥梁。 参考 ECMWF 开发的 climetlab。
另外还尝试使用 cdo 工具进行转码,详情参见:
尝试使用 xarray 合并 GRIB 2 要素场,详情参见:
诊断工具
随着海洋工程一期项目完成业务验收,我也不再从事桌面端诊断工具相关工作。 实际上,从去年下半年以来,我就不再参与桌面程序的开发工作,并于今年转为开发基于 Jupyter Notebook 的在线版诊断工具。
诊断工具工作最核心的问题在于,多年来没能拿出可以使用的工具。 第三季度,我在绘图工具方面的封装工作已确保能提供实现一种简易功能的“诊断”工具。
绘图工具
将业务绘图工具 nwpc-oper/nwpc-graphics 封装到基于 Docker 构建的 JupyterHub 中,可以为不同用户提供相对独立的 Jupyter 环境。 详情参看如下文章:
下一阶段,应该考虑增加更多的功能,并在单位内推广使用。比如挂载共用目录提供代码示例,集成模式运行分析工具等等。 不过,因为我们的工具往往面向 HPC 和命令行开发,增加面向 Jupyter Notebook 的新功能并不容易。 也许有人用起来以后才会带来额外的需求。
检验工具研究
第三季度耗时最多的工作就是研究检验工具源码。
8 月和 9 月的大部分时间,都在研究中心内部正在开发的工具及 NMC 开源的 Meteva 两个项目的源代码,并学习检验基本知识。 代码是否是最好的老师还有待商榷,但看源代码,尤其是专注于特定功能的源代码,确实能有效地掌握相关算法。 感谢开发检验工具的老师提供方便易用的工具。
只看不写,相当于没看。因此,我在学习过程中使用 nwpc-data 等库实现部分检验指标的计算,并与参考程序计算的结果进行比较,验证计算结果是否正确。 详情请参看如下文章:
数据处理
等压面要素场
地面要素场
下一阶段将继续检验工具的源码研究,尝试实现更多的检验指标算法,并尝试为中心开发的工具库贡献自己的力量。
其他工作
第三季度最重要的其他工作就是海洋工程的项目验收。
工程项目
持续两年的海洋工程一期项目终于完成业务验收工作,至于项目效果如何还需要时间还进一步验证。 后续虽然也有部分工程项目与我相关,但我不再承担联系人职责,可以更专注于科研和开发工作。
HPC
完成 CMA-PI 用户目录迁移,从 /g3 切换到 /g11。 同时将之前安装的 Anaconda 3 环境也做了相应的迁移,详情请查看如下文章:
学习
第三季度继续进行机器学习方面的学习,同时也开始学习 R 语言。 希望对以后的工作有所帮助。
总结
从 Github 代码提交量来看,第三季度的代码开发量有显著的下降。 不能提炼到工具项目中的代码都不是可以复用的代码,写得再多也没有意义。 这也是第三季度工作的最显著的特征,我花了大量时间做了一些没有推广价值的工作,写了一些无法复用的代码,没有形成应有的工作成果。
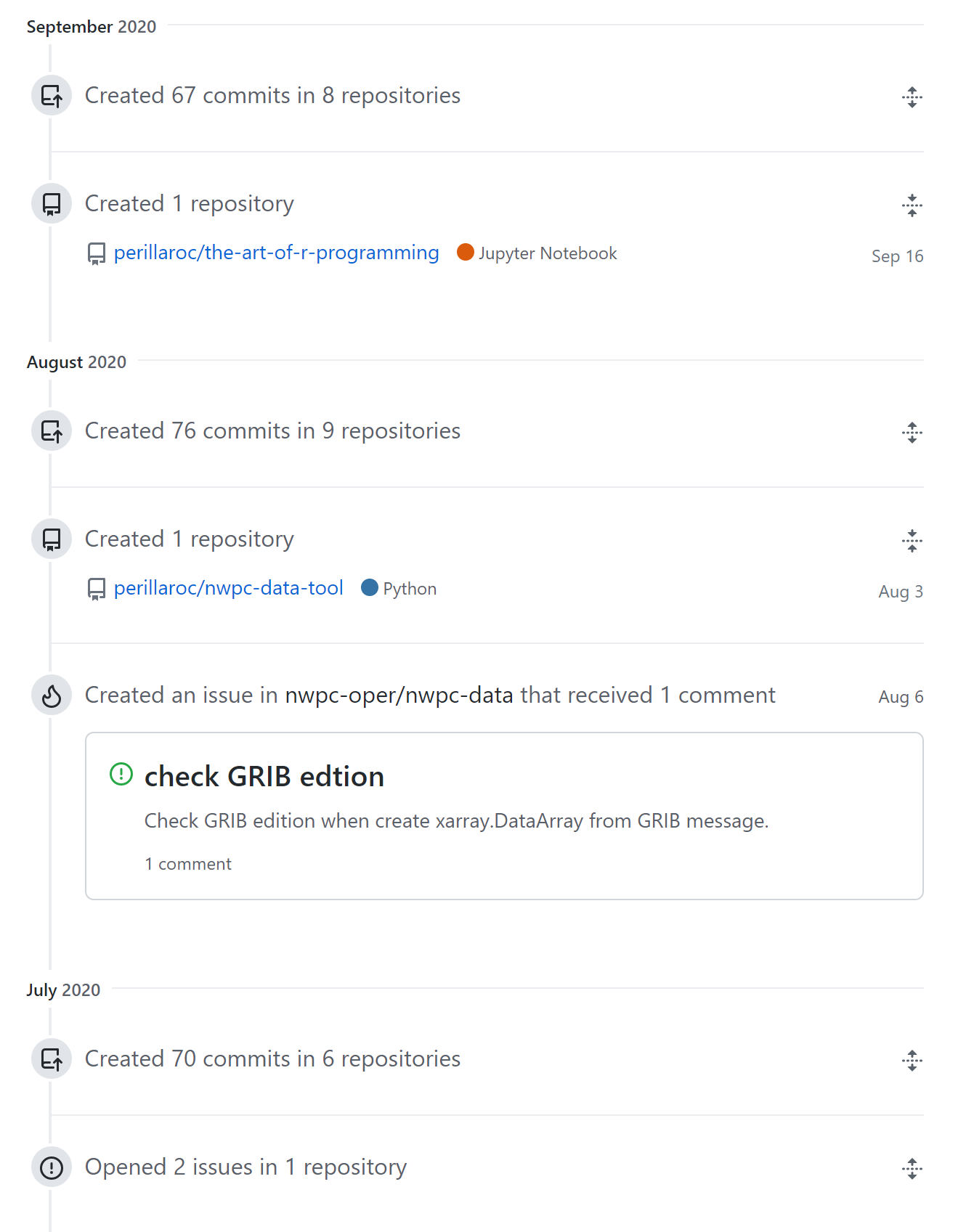
上半年开发的运维相关工具也完全搁置一旁,没能进一步更新完善。
看了一些机器学习方面的资料,却没有动手实践,导致学习的效果大打折扣。 本计划第二季度、第三季度就开始的机器学习实战计划也完全没有开展。 下一阶段确实应该提高工作和学习效率,开启新的机器学习项目。哪怕只用少量的数据,也要实现某篇文章中的机器学习算法。
我需要反思下近三个月的时间安排策略。 是否在某些任务中耗费太多时间,却没有产出任何成果; 是否在运维工具上投入更多的精力,将早已想做的功能尽快实现; 是否更深入地介入到数据平台的开发方面,尽快提供方便使用的用户接口。
好在即将迎来十一长假,希望我能给自己留出足够的时间思考下一阶段的计划。
下一阶段计划
第四季度工作的重点在于做好工作总结。 今年一直想写关于消息平台和工作流日志分析的两份技术文档,前期仅准备了少部分材料。 第四季度必须抓紧时间在完善功能的同时开始写技术文档。
另外,消息平台和诊断工具依旧是工作的重心。
继续开发消息平台的可视化面板,完成现代化专项任务书中的所有考核目标。
完善数据工具 nwpc-data,增加对其他数据类型的支持,并研究如何基于 Dask 提供实现对大批量数据的分布式处理。 力争将该工具打造成数据与算法之间的桥梁(这只是一个长远目标)。
争取向中心提供封装业务绘图库的 JupyterHub 工具,避免多年来一直无法提供诊断工具的情况继续延续。 继续学习检验工具源码。
使用实际的数据实现一个小规模的机器学习算法,并修改模式运行时间预测的机器学习模型,提高预测的准确性。
花了一天时间终于完成这篇总结,希望第四季度能让 2020 年有个完美的收尾。
