学习R语言:列表
本文内容来自《R 语言编程艺术》(The Art of R Programming),有部分修改
列表在 R 中扮演着一个至关重要的角色,是数据框 (data.frame) 和面向对象编程的基础。
创建列表
列表属于“递归型” (recursive) 向量。
创建一个列表
j <- list(
name="Joe",
salary=55000,
union=T
)打印列表
print(j)$name
[1] "Joe"
$salary
[1] 55000
$union
[1] TRUE
R 语言中列表各组件的名称叫做 标签 (tags)。
标签是可选的,不指定标签会自动生成默认标签。
jalt <- list("Joe", 55000, T)
print(jalt)[[1]]
[1] "Joe"
[[2]]
[1] 55000
[[3]]
[1] TRUE
使用标签访问列表组件
print(j$name)[1] "Joe"
因为列表也是向量,所以可以使用 vector() 创建列表
z <- vector(mode="list")
z[["abc"]] <- 3
print(z)$abc
[1] 3
列表的常规操作
列表索引
有多种方式访问列表组件
print(j$salary)[1] 55000
print(j[["salary"]])[1] 55000
print(j[[2]])[1] 55000
上述三种方式返回列表 lst 中的组件 c,返回值是 c 的数据类型:
lst$clst[["c"]]lst[[i]],i 是 c 在 lst 中的数字编号
注意:使用双中括号返回组件本身
另外两种方式返回列表的子列表:
lst["c"]lst[1]
注意:使用单中括号返回子列表
print(j[1:2])$name
[1] "Joe"
$salary
[1] 55000
j2 <- j[2]
print(j2)$salary
[1] 55000
print(class(j2))[1] "list"
str(j2)List of 1
$ salary: num 55000
双中括号一次只能提取一个组件
下段代码
j[[1:2]]
会抛出错误
Error in j[[1:2]]: 下标出界
j2a <- j[[2]]
print(j2a)[1] 55000
print(class(j2a))[1] "numeric"
增加或删除列表元素
列表创建之后可以增加新的组件
z <- list(
a="abc",
b=12
)
print(z)$a
[1] "abc"
$b
[1] 12
增加组件 c
z$c <- "sailing"
print(z)$a
[1] "abc"
$b
[1] 12
$c
[1] "sailing"
可以使用索引增加组件
z[[4]] <- 28
z[5:7] <- c(FALSE, TRUE, TRUE)
print(z)$a
[1] "abc"
$b
[1] 12
$c
[1] "sailing"
[[4]]
[1] 28
[[5]]
[1] FALSE
[[6]]
[1] TRUE
[[7]]
[1] TRUE
删除列表元素可以直接将其设为 NULL
z$b <- NULL
print(z)$a
[1] "abc"
$c
[1] "sailing"
[[3]]
[1] 28
[[4]]
[1] FALSE
[[5]]
[1] TRUE
[[6]]
[1] TRUE
注意:删掉 z$b 后,之后元素的索引全部减 1
列表拼接
print(c(list("Joe", 55000, T), list(5)))[[1]]
[1] "Joe"
[[2]]
[1] 55000
[[3]]
[1] TRUE
[[4]]
[1] 5
获取列表长度
使用 length() 得到列表的组件个数,因为列表是向量
print(length(j))[1] 3
扩展案例:文本词汇索引
findwords() 函数用于找到文本文件中的所有单词,并标出各个单词的位置
findwords <- function(tf) {
txt <- scan(tf, "")
wl <- list()
for (i in 1:length(txt)) {
wrd <- txt[i]
wl[[wrd]] <- c(wl[[wrd]], i)
}
return(wl)
}scan() 函数用于读取文本文件
示例:
print(scan("testconcorda.txt", "")) [1] "the" "here" "means" "that" "the"
[6] "first" "item" "in" "this" "line"
[11] "of" "output" "is" "item" "in"
[16] "this" "case" "our" "output" "consists"
[21] "of" "only" "one" "line" "and"
[26] "one" "item" "so" "this" "is"
[31] "redundant" "but" "this" "notation" "helps"
[36] "to" "read" "voluminous" "output" "that"
[41] "consists" "of" "many" "items" "spread"
[46] "over" "many" "lines" "for" "example"
[51] "if" "there" "were" "two" "rows"
[56] "of" "output" "with" "six" "items"
[61] "per" "row" "the" "second" "row"
[66] "would" "be" "labeled"
测试 findwords() 函数
wl <- findwords("testconcorda.txt")
print(wl)$the
[1] 1 5 63
$here
[1] 2
$means
[1] 3
......
$labeled
[1] 68
访问列表元素和值
names() 函数获取列表元素的标签
print(names(j))[1] "name" "salary" "union"
使用 unlist() 函数获取列表的值
values <- unlist(j)
print(values) name salary union
"Joe" "55000" "TRUE"
实际上,unlist 返回值是一个向量,每个元素都被命名。
本例中返回的是字符串向量
print(class(values))[1] "character"
对于全数值的列表,返回的是数值向量
z <- list(
a=5,
b=12,
c=13
)
y <- unlist(z)
print(class(y))[1] "numeric"
如果既有数值又有字符串,返回值会转为最通用的类型
优先级排序:
NULL < raw < 逻辑类型 < 整型 < 实数类型 < 复数类型 < 列表 < 表达式
w <- list(
a=5,
b="xyz"
)
wu <- unlist(w)
print(class(wu))[1] "character"
print(wu) a b
"5" "xyz"
将元素名设为 NULL
names(wu) <- NULL
print(wu)[1] "5" "xyz"
也可以使用 unname() 去掉元素名
wun <- unname(y)
print(wun)[1] 5 12 13
在列表上使用 apply 系列函数
lapply() 和 sapply() 的使用
lapply() (list apply) 对列表中的每个组件执行给定函数,返回另一个列表
print(lapply(
list(1:3, 25:29),
median
))[[1]]
[1] 2
[[2]]
[1] 27
sapply() (simplified lapply) 可以返回矩阵或向量
print(sapply(
list(1:3, 25:29),
median
))[1] 2 27
扩展案例:文本词汇索引(续)
将 findwords() 函数的返回列表进行排序
alphawl() 将单词按字母顺序排序
alphawl <- function(wrdlst) {
nms <- names(wrdlst)
sn <- sort(nms)
return(wrdlst[sn])
}print(alphawl(wl))$and
[1] 25
$be
[1] 67
......
$with
[1] 58
$would
[1] 66
freqwl() 按词频排序
freqwl <- function(wrdlst) {
freqs <- sapply(wrdlst, length)
return(wrdlst[order(freqs)])
}order() 返回排序后向量在原向量中的索引
x <- c(12, 5, 13, 8)
print(order(x))[1] 2 4 1 3
print(freqwl(wl))$here
[1] 2
$means
[1] 3
......
$this
[1] 9 16 29 33
$of
[1] 11 21 42 56
$output
[1] 12 19 39 57
将词频在前 10% 的单词绘制成条形图
swl <- freqwl(wl)
nwords <- length(swl)
freqs9 <- sapply(swl[round(0.9*nwords):nwords], length)
barplot(freqs9)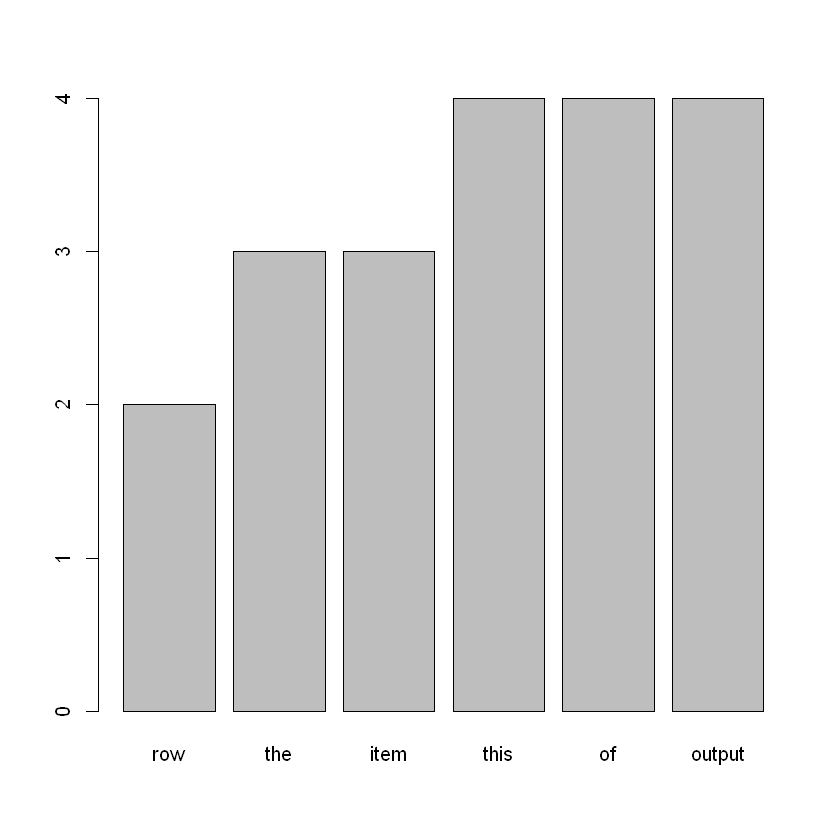
扩展案例:鲍鱼数据
寻找三种不同类别的鲍鱼分别有哪些
g <- c("M", "F", "F", "I", "M", "M", "F")
print(lapply(
c("M", "F", "I"),
function(gender) which(g==gender)
))[[1]]
[1] 1 5 6
[[2]]
[1] 2 3 7
[[3]]
[1] 4
注意:这里 lapply() 的第一个参数不是 g,g 出现在匿名函数中
递归型列表
列表的组件也可以是列表
b <- list(
u=5,
v=12
)
c <- list(
w=13
)
a <- list(b, c)
print(a)[[1]]
[[1]]$u
[1] 5
[[1]]$v
[1] 12
[[2]]
[[2]]$w
[1] 13
c() 有一个可选参数 recursive 决定在拼接列表时是否将列表“压平”,即把所有元素都提取出来,组合成一个向量
默认值为 FALSE,形成嵌套列表
print(c(list(
a=1,
b=2,
c=list(
d=5,
e=9
)
)))$a
[1] 1
$b
[1] 2
$c
$c$d
[1] 5
$c$e
[1] 9
设为 TRUE 时,c 组件中的元素 d 和 e 被取出,与 a 和 b 一同构成向量
print(c(list(
a=1,
b=2,
c=list(
d=5,
e=9
)
), recursive=T)) a b c.d c.e
1 2 5 9
参考
学习 R 语言系列文章:
《快速入门》
《向量》
《矩阵和数组》
本文的 Jupyter Notebook 代码请访问如下项目: