Meteva笔记:加载本地观测数据
Meteva 是由 nmc 开源的全流程检验程序库,提供了常用的各种气象预报检验评估的算法函数,气象检验分析的图片和表格型产品的制作函数,以及检验评估系统示例。
本文介绍如何将 NWPC 生成的站点观测文本文件接入到 Meteva 工具中。
站点数据格式
在 Meteva 中,使用 pandas.DataFrame 对象表示站点数据,类似 Excel 表格。
每个站点数据表格都必须包含如下所示的六个列,用于表示每行记录的元信息:
level:层次time:时间dtime:预报时效id:站点号lon:站点经度lat:站点纬度
其余列均为数据列,可以任意取名字。
准备
加载需要使用到的库
import pandas as pd
import numpy as np
import xarray as xr
import pathlibmeteva.base 提供 IO、数据处理和绘图函数,meteva.method 提供检验指标计算函数,meteva.product 提供集成的诊断函数。
import meteva.base as meb
import meteva.method as mem
import meteva.product as mpd
from nwpc_data.data_finder import find_local_file
from nwpc_data.grib.eccodes import load_field_from_fileGDS 数据
首先从 GDS 服务中加载观测资料
读取 IP 地址和端口号
gds_config_file = "/g1/u/wangdp/.config/.nmcdev/config.ini"
ip, port = meb.io.read_gds_ip_port(gds_config_file)读取观测资料
GDS 数据路径,读取 2020 年 9 月 19 日 08 时的全国地面站观测资料
时间
obs_date_utc = pd.Timestamp("2020-09-19 00:00:00")
obs_date_bj = obs_date_utc + pd.Timedelta(hours=8)路径
data_path = f"SURFACE/PLOT_NATIONAL_1H/{obs_date_bj.strftime('%Y%m%d%H')}0000.000"
data_path'SURFACE/PLOT_NATIONAL_1H/20200919080000.000'
打印 GDS 数据变量名称。 需要使用数字编号来实际提取数据
ele_dict = meb.print_gds_file_values_names(
data_path,
ip, port
)现在天气:1601
露点温度:801
测站高度:3
过去天气1:1603
测站级别:4
过去天气2:1605
降水_3小时:1005
降水_6小时:1007
平均风向_2分钟:209
海平面气压:401
平均风速_2分钟:211
变压_3小时:403
变压_24小时:405
水平能见度_人工:1207
温度:601
总云量:1401
低云量:1403
云底高度:1405
变温_24小时:607
下载温度数据,element_id=601
station_data = meb.read_stadata_from_gds(
ip, port,
data_path,
element_id=601,
show=True,
)
station_data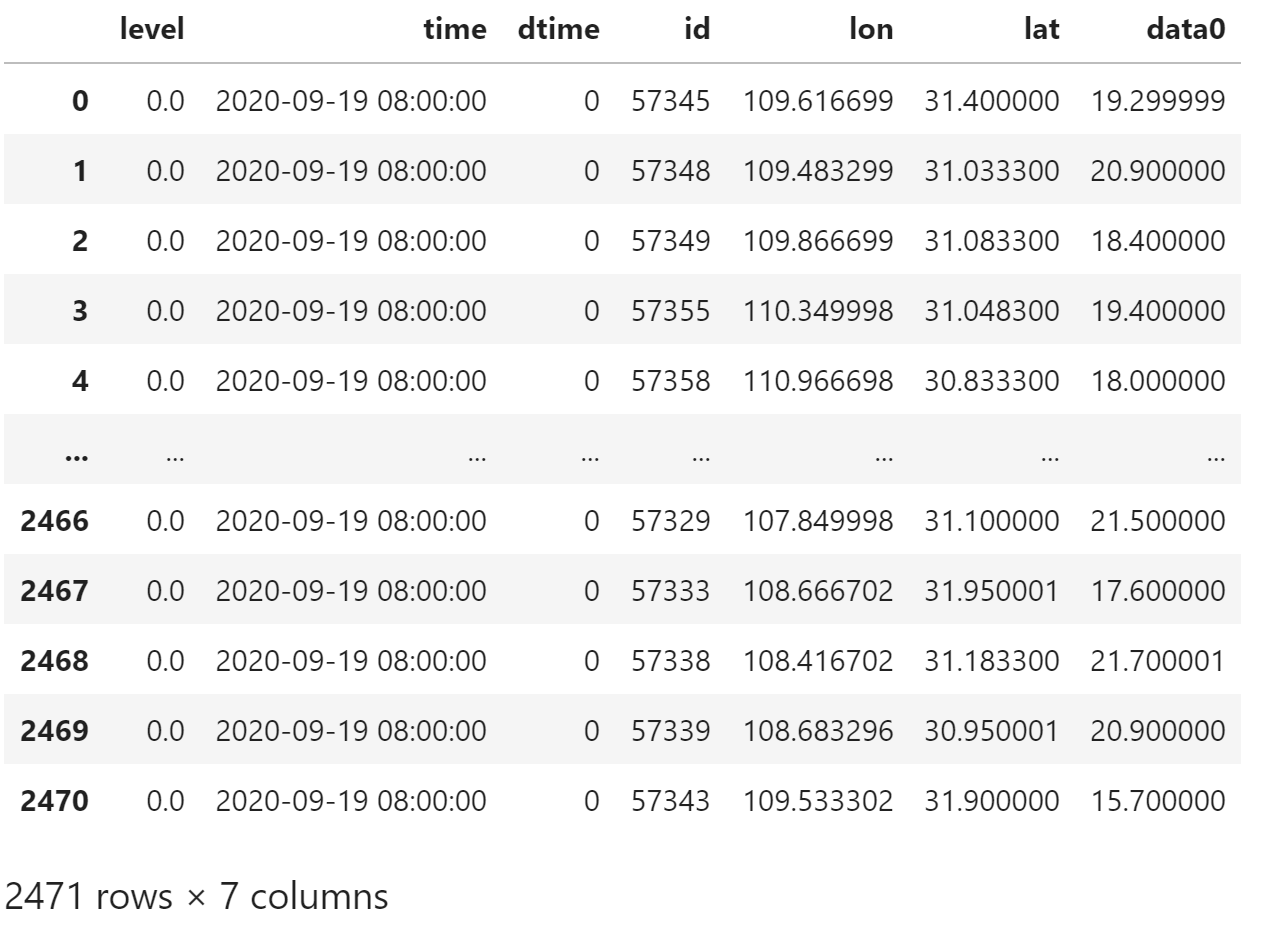
绘制站点图
将 station_data 中的数据列 data0 命名为 T
meb.set_stadata_names(station_data, ["T"])使用 meb.tool.plot_tools.scatter_sta 绘制站点图
meb.tool.plot_tools.scatter_sta(
station_data,
map_extend=[70, 140, 0, 55],
)
本地数据
本文使用 NWPC 制作的观测数据,每个时次一个文件。
原始观测数据来自从 CIMISS 检索的全球地面逐小时数据 (SURF_GLB_MUL_HOR)。
下面是一个时次的样例文件
2020091900 09909
174 32.18 34.83 1010.50 26.74 24.09 149.00 0.70 0.00 0.00 999999.00 1006.80
180 32.01 34.88 1011.60 27.59 23.38 178.00 1.40 0.00 0.00 999999.00 1006.90
412 32.98 35.57 1009.10 21.31 18.54 223.00 1.70 0.00 0.00 999999.00 980.30
425 32.81 35.04 1010.60 27.50 24.28 26.00 1.60 0.00 0.00 999999.00 1010.00
495 29.72 35.01 1008.60 30.52 13.25 342.00 7.10 0.00 0.00 999999.00 999.30
502 33.13 35.80 999999.00 24.66 3.66 291.00 4.60 0.00 0.00 999999.00 999999.00
503 33.02 35.57 999999.00 23.93 19.77 999999.00 999999.00 0.00 0.00 999999.00 999999.00
506 32.96 35.33 999999.00 24.58 8.96 999999.00 999999.00 0.00 0.00 999999.00 999999.00
507 32.98 35.09 999999.00 22.73 20.54 105.00 0.40 0.00 0.00 999999.00 999999.00
511 32.85 35.11 1011.10 24.75 23.05 229.00 0.10 0.00 0.00 999999.00 1009.90
第一行是时次和条目数。
第二行开始是每个站点的观测数据。包括以下 12 个字段(括号中是 CIMISS 的要素代码):
- 站号 (Station_Id_d)
- 纬度 (Lat)
- 经度 (Lon)
- 海平面气压 (PRS_Sea)
- 温度 (TEM)
- 露点温度 (DPT)
- 风向 (WIN_D)
- 风速 (WIN_S)
- 1小时降水 (PRE_1h)
- 6小时降水 (PRE_6h)
- 24小时降水 (PRE_24h)
- 气压 (PRS)
其中 999999.00 是缺测值
载入
观测资料文件目录
注意:NWPC 数据均使用世界时,所以对应上一节观测数据的时刻是 2020 年 9 月 19 日 00 时 (UTC)
obs_file_path = (
f"/g2/nwp_vfy/MUVOS/obs/station/GTS/"
f"{obs_date_utc.strftime('%Y%m')}/gts{obs_date_utc.strftime('%Y%m%d%H')}.txt"
)
obs_file_path'/g2/nwp_vfy/MUVOS/obs/station/GTS/202009/gts2020091900.txt'
使用 read_csv 读取观测数据,并跳过第一行。
处理缺失值,将 999999.0 替换为 np.nan
obs_file = open(obs_file_path, "r")
obs_file.readline()
df = pd.read_csv(
obs_file,
sep="\s+",
names=[
"station_id",
"latitude",
"longitude",
"PRS_Sea",
"TEM",
"DPT",
"WIN_D",
"WIN_S",
"PRE_1h",
"PRE_6h",
"PRE_24h",
"PRS",
]
)
obs_file.close()
df[df==999999.0] = np.nan
df.head()
处理
选择温度
temperature = df[["station_id", "latitude", "longitude", "TEM"]]
temperature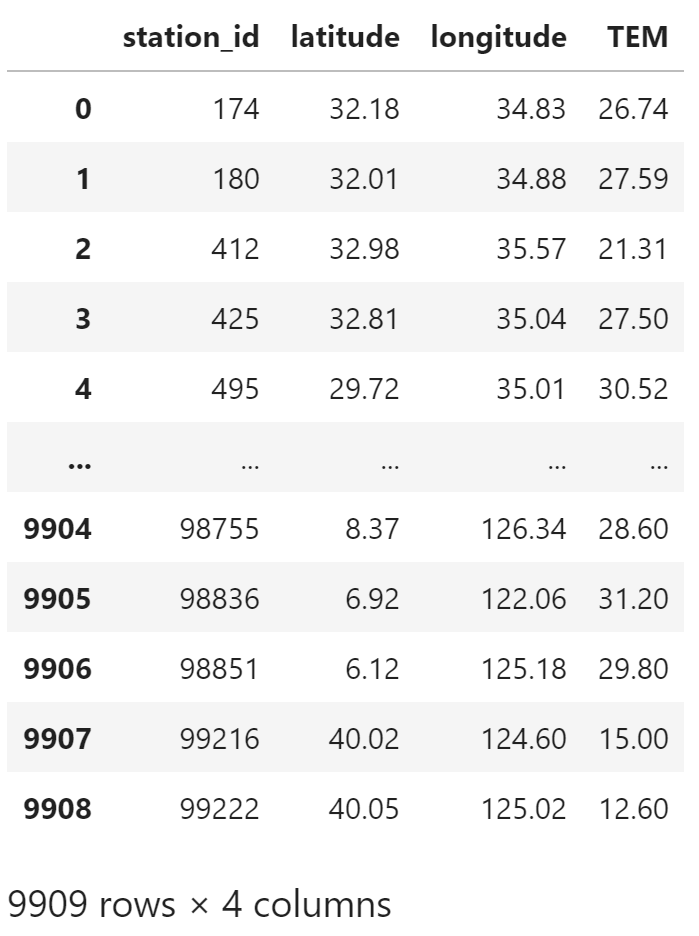
过滤缺失值,删掉缺失温度的条目
temperature = temperature[temperature["TEM"].notna()]
temperature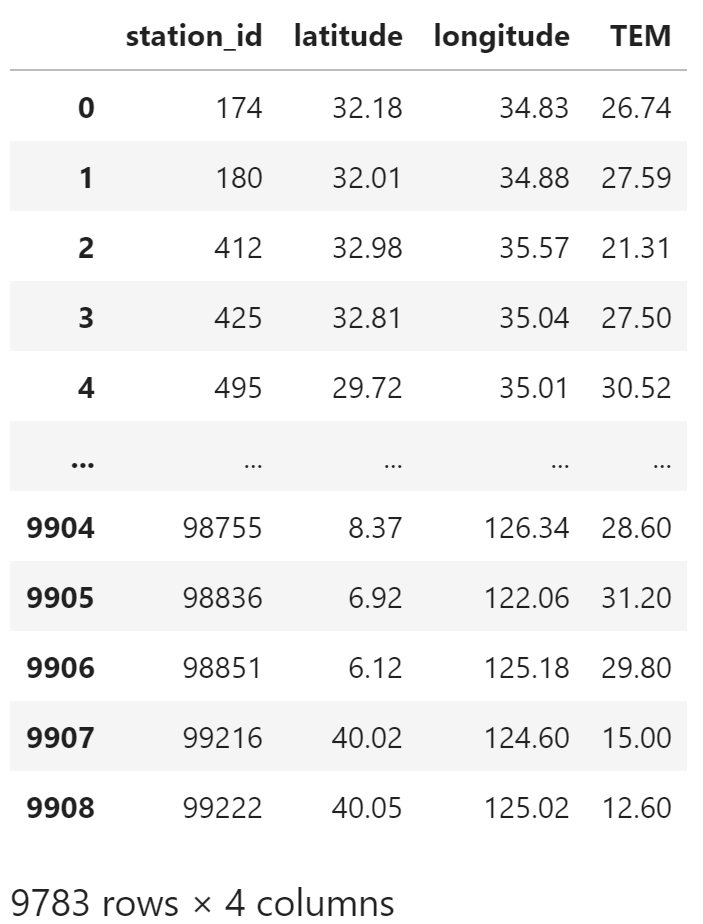
对于重复的站号,只取第一个值
temperature = temperature.drop_duplicates("station_id")
temperature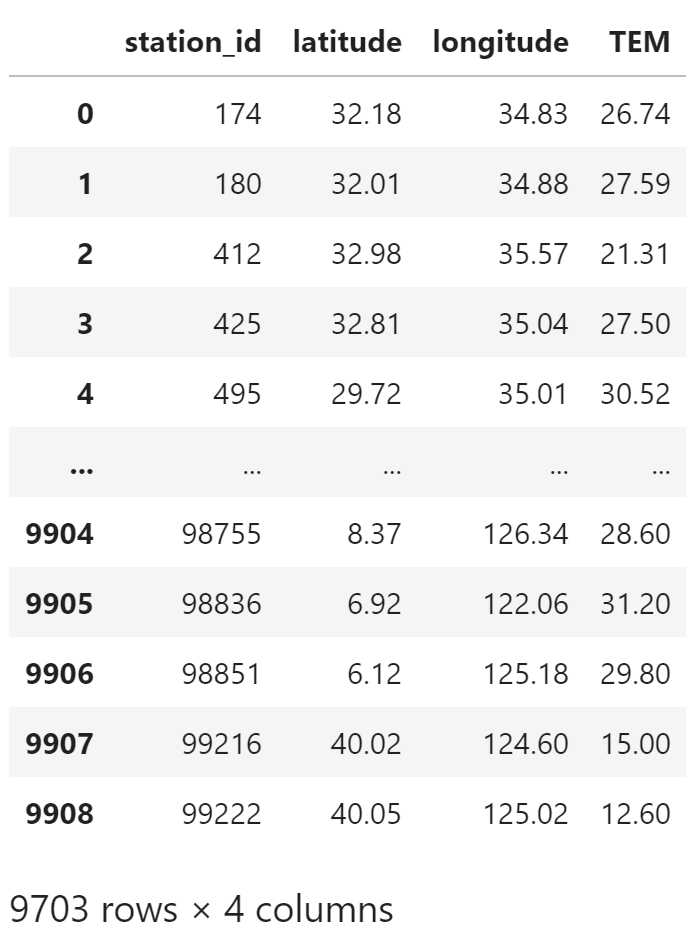
转换
将读取的表格数据转为 meb.sta_data() 函数返回的表格格式
使用 columns 参数设置列的对应关系
gts_data = meb.sta_data(
temperature,
columns=[
"id",
"lat",
"lon",
"TEM",
]
)
gts_data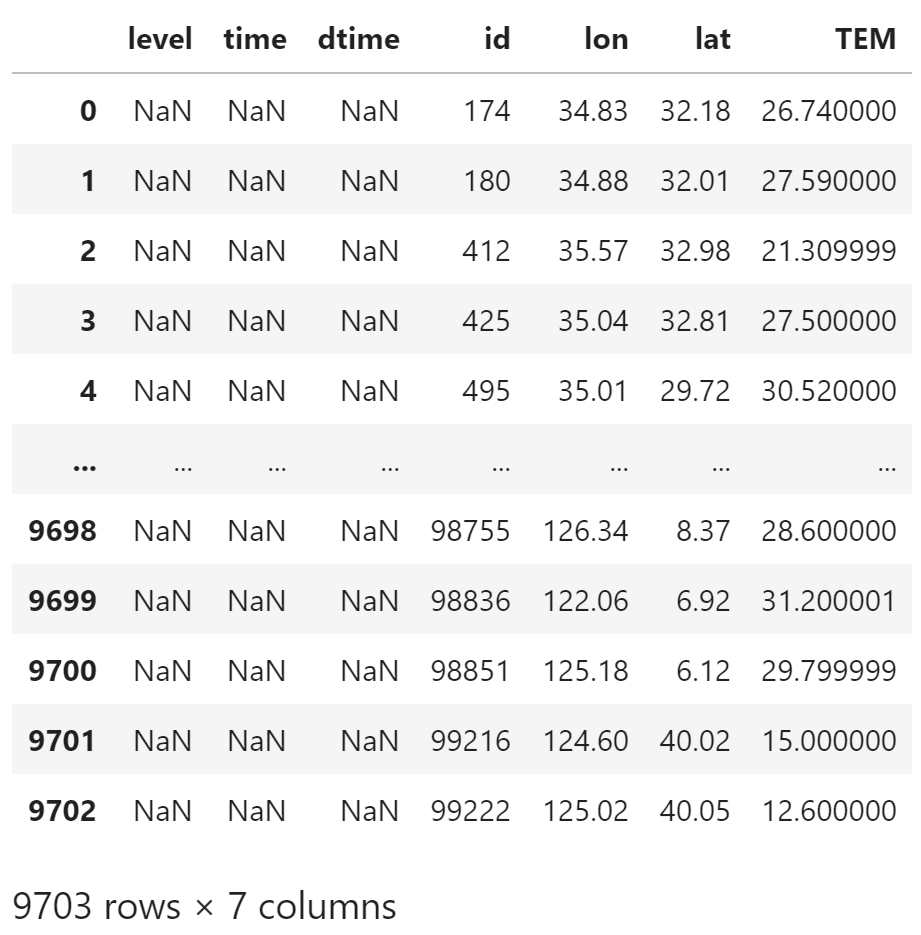
数据中没有 level,time 和 dtime 信息,这些列被填充为 NaN
绘制
绘制站点图前需要补充缺失的列。
gts_data.level = 0.0
gts_data.time = pd.Timestamp("2020-09-19")
gts_data.dtime = 0
gts_data.head()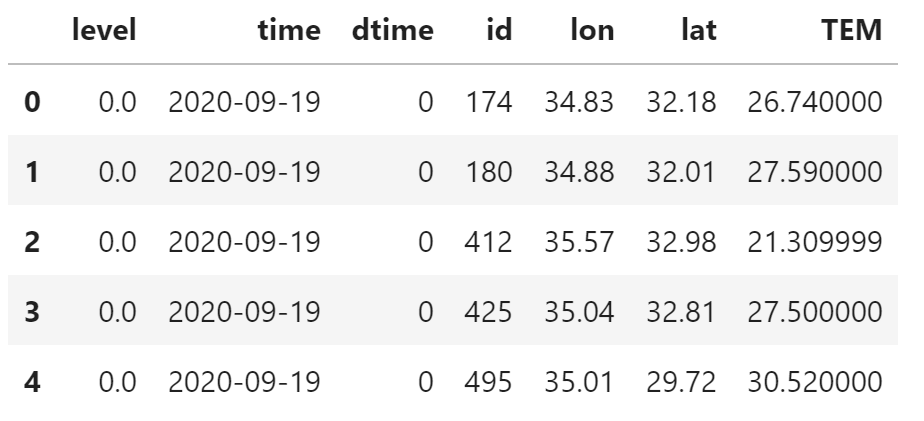
也可以使用 meb.set_stadata_coords() 函数设置数据时空坐标
meb.set_stadata_coords(
gts_data,
level=0.0,
time=pd.Timestamp("2020-09-19 08:00"),
dtime=0,
)
gts_data.head()
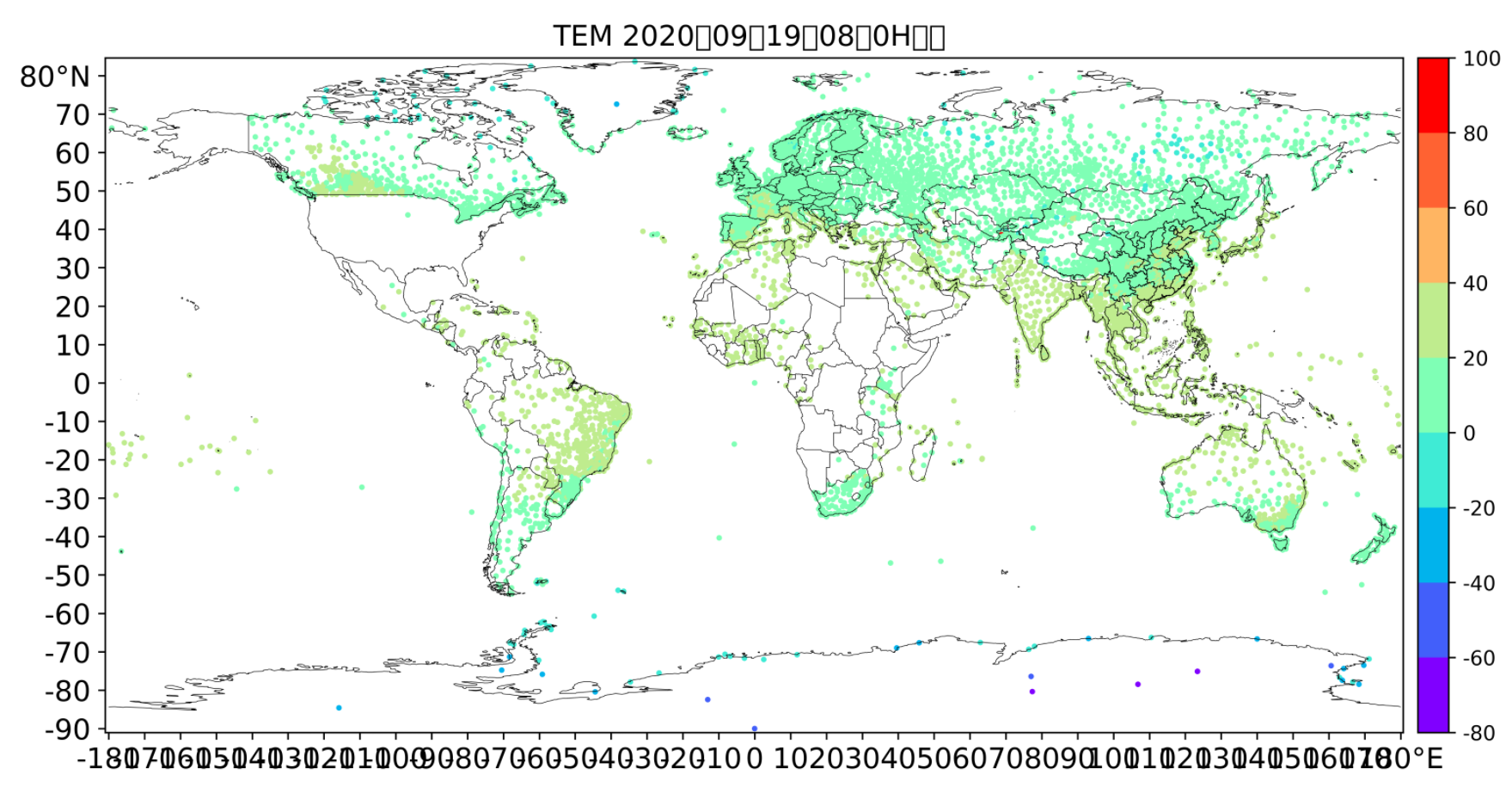
绘制站点图
meb.tool.plot_tools.scatter_sta(
gts_data,
)
验证
对比从 GDS 上检索的数据和本地观测数据
筛选
按照 GDS 数据的站点号过滤 gts_data
使用 pd.merge() 函数合并两个 DataFrame,使用 inner 合并,仅保留两个数据中都有的站点观测。
根据合并规则,相同的列名会默认添加 _x 和 _y 后缀。
merged_station_data = pd.merge(
station_data, gts_data,
how="inner",
on="id",
)
merged_station_data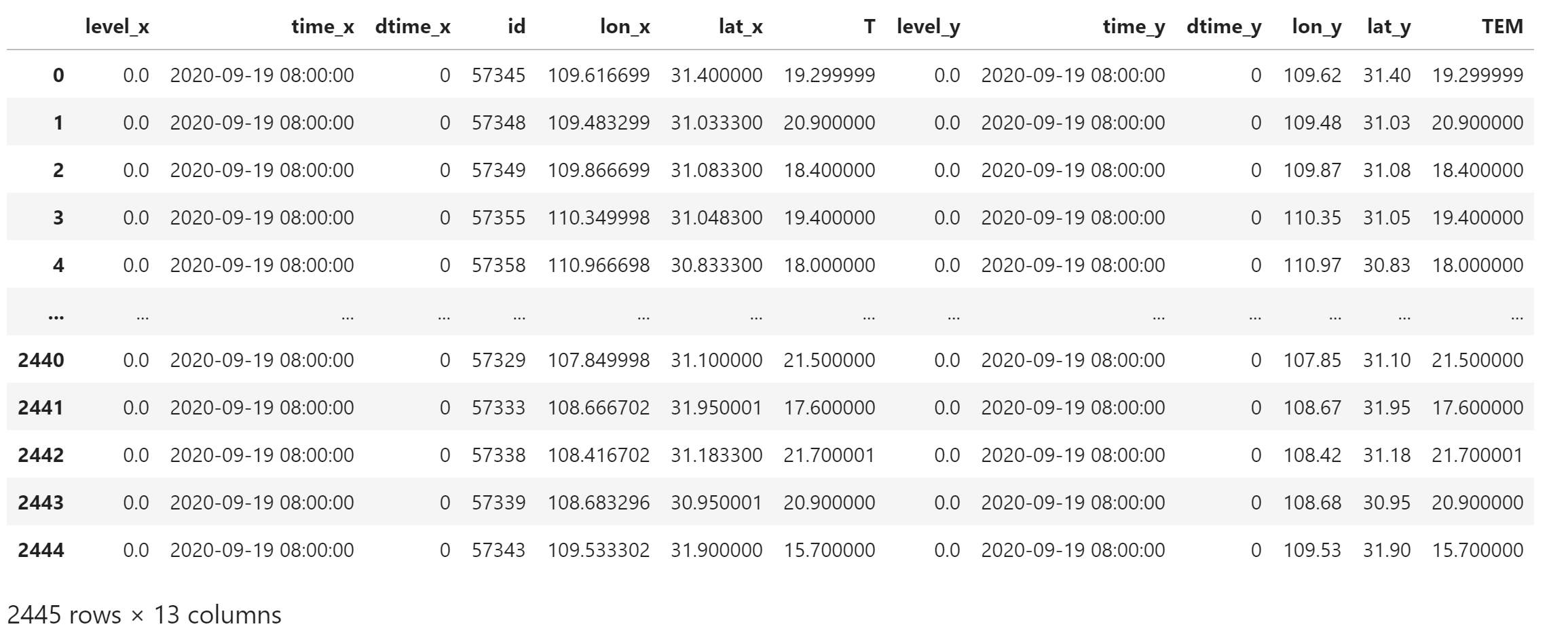
meb.fun.combine_on_id() 函数可以实现按站号合并的功能,同时会删掉重复的列,并修改列名
meb.fun.combine_on_id(station_data, gts_data)
对比
计算两个观测数据的 RMSE
mem.continuous.rmse(
merged_station_data["T"],
merged_station_data["TEM"]
)0.0020223775004260154
两个数据差别很小,说明本地观测数据文件可以在某种程度上代替 GDS 上的观测数据。
指标
以 RMSE 为例说明
计算 NCEP GFS 模式 24 小时 2 米温度相对于观测站点的 RMSE
数据
格点数据路径
forecast_date_utc = obs_date_utc - pd.Timedelta(hours=24)
forecast_date_utcTimestamp('2020-09-18 00:00:00')
grib2_path = find_local_file(
"glob/gfs/grib2/0p50",
start_time=forecast_date_utc,
forecast_time=pd.Timedelta(hours=24),
data_class="cm"
)
grib2_pathPosixPath('/g1/COMMONDATA/glob/gfs/2020/gfs.2020091800/gfs.t00z.pgrb2.0p50.f024')
观测数据使用本地载入的数据,merged_station_data
经纬度坐标使用 _y 后缀的坐标,并去掉后缀
test_station_data = merged_station_data[
["level_y", "time_y", "dtime_y", "id", "lon_y", "lat_y", "TEM"]
]
test_station_data.columns = [
"level", "time", "dtime", "id", "lon", "lat", "obs"
]
test_station_data
载入格点数据
已在前一篇文章《Meteva笔记:加载GRIB 2要素场》中介绍。
def load_grid(
file_path,
parameter,
level_type=None,
level=None,
) -> xr.DataArray:
field = load_field_from_file(
file_path,
parameter=parameter,
level_type=level_type,
level=level,
)
field = field.expand_dims(["time", "step", "pl"])
grid = meb.xarray_to_griddata(
field,
level_dim="pl",
time_dim="time",
dtime_dim="step",
lat_dim="latitude",
lon_dim="longitude",
)
return grid
t2m_grid = load_grid(
grib2_path,
"2t",
) - 273.15预报与观测匹配
按站点经纬度寻找预报场中的最近邻点
def get_forecast(row):
value = t2m_grid.squeeze().sel(
lon=row["lon"],
lat=row["lat"],
method="nearest"
).item()
return value
test_station_data["fcst"] = test_station_data.apply(
get_forecast,
axis="columns"
)
test_station_data
计算
mem.continuous.rmse(
test_station_data["obs"],
test_station_data["fcst"],
)2.6649602959720116
集成方法
使用 Meteva 内置的函数完成数据匹配和指标计算
重新生成 test_station_data 数据
test_station_data = merged_station_data[
["level_y", "time_y", "dtime_y", "id", "lon_y", "lat_y", "TEM"]
]
test_station_data.columns = [
"level", "time", "dtime", "id", "lon", "lat", "obs"
]使用 meb.interp_gs_nearest() 函数预报数据对站点的最近邻插值数据。
使用 meb.set_stadata_names() 为数据命名
gfs_station_data = meb.interp_gs_nearest(t2m_grid, test_station_data)
meb.set_stadata_names(gfs_station_data, ["gfs"])
gfs_station_data
使用 meb.combine_on_obTime_id() 将预报与观测数据合并
合并策略:预报 time + 预报 dtime = 观测 time
data = meb.combine_on_obTime_id(
test_station_data,
[gfs_station_data]
)
data
使用 mpd.score 函数为表格数据计算 RMSE。
该函数认为第一个数据列是观测,其余数据列都是预报
mpd.score(data, method=mem.rmse)(array(999982.25, dtype=float32), None)
参考
Meteva 项目:
https://github.com/nmcdev/meteva
nwpc-data 项目: