等压面要素场检验指标绘图
目录
上一篇文章《计算等压面要素场检验指标 - 并发》及之前的几篇文章介绍如何计算等压面要素场的检验指标。
本文介绍如何用计算得到的检验指标绘图。
数据
检验指标数据保存在 CSV 文件中,如下图所示
forecast_hour,variable,level,region,rmse,me,mae,sd,rmsem,rmsep,acc
0,gh,1000,NHEM,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,1.000000
0,gh,1000,SHEM,0.000000,0.000000,0.000000,0.000000,0.000000,0.000000,1.000000
...
24,t,10,GLOB,1.020141,-0.155320,0.794115,1.008247,0.155320,0.864821,0.963317
...
准备
载入使用的库
import pandas as pd
import numpy as np
import xarray as xr
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
import pathlib读取单个文件
检验指标文件按照不同的预报时间保存到 CSV 文件中
file_path="./stats.2018072512.csv"使用 pd.read_csv 函数载入 CSV 文件
table = pd.read_csv(file_path)
table.head()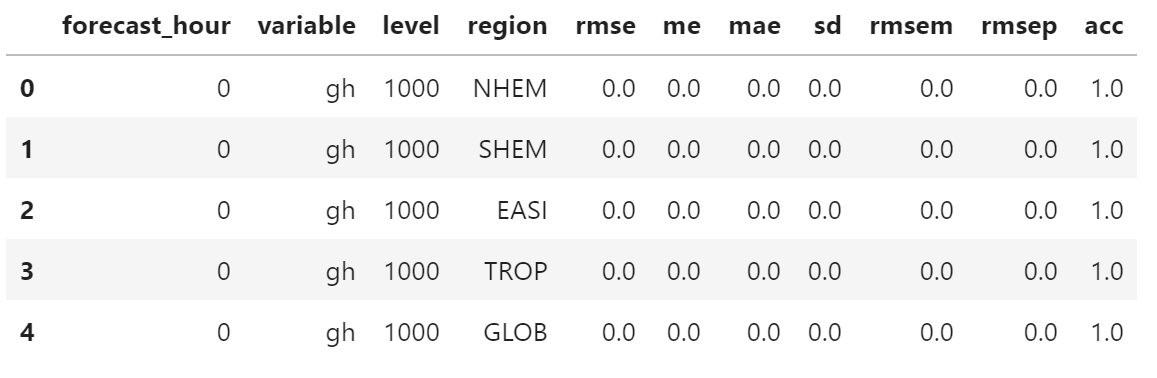
处理缺失值,数据中的 -999.0 代表缺失值
table[table == -999.0] = np.nan添加日期作为新列 (date)
table["date"] = pd.to_datetime("2018-07-25 12:00:00")设置多级索引
table.set_index(
["date", "forecast_hour", "variable", "level", "region"]
).head()
将读取单个文件的代码封装成函数 read_stats
def read_stats(file_path: str) -> pd.DataFrame:
p = pathlib.Path(file_path)
if not p.exists():
return None
current_time = pd.to_datetime(
p.name,
format="stats.%Y%m%d%H.csv"
)
table = pd.read_csv(file_path)
table[table == -999.0] = np.nan
table["date"] = pd.to_datetime(current_time)
table = table.set_index(
["date", "forecast_hour", "variable", "level", "region"]
)
return table读取多个文件
构造时间序列
date_list = pd.date_range(
"2018-07-25 12:00",
"2018-08-24 12:00",
freq='D'
)
date_list[:5]DatetimeIndex(['2018-07-25 12:00:00', '2018-07-26 12:00:00',
'2018-07-27 12:00:00', '2018-07-28 12:00:00',
'2018-07-29 12:00:00'],
dtype='datetime64[ns]', freq='D')
expr2
读取 expr2 试验的检验指标
构造检验指标文件路径列表
file_list = [
f"./dask-stat/expr2/stats.{d.strftime('%Y%m%d%H')}.csv"
for d in date_list
]
file_list[:5]['./dask-stat/expr2/stats.2018072512.csv',
'./dask-stat/expr2/stats.2018072612.csv',
'./dask-stat/expr2/stats.2018072712.csv',
'./dask-stat/expr2/stats.2018072812.csv',
'./dask-stat/expr2/stats.2018072912.csv']
读取每个文件
dfs = [read_stats(f) for f in file_list]将多个 DataFrame 对象合并为 1 个 DataFrame 对象。
合并会根据我们之前添加的多级索引自动完成。
df = pd.concat(dfs)
df
转换为 xarray.DataArray 对象,方便使用带标签名的索引
x = df.to_xarray()
x.attrs["name"] = "expr2"
x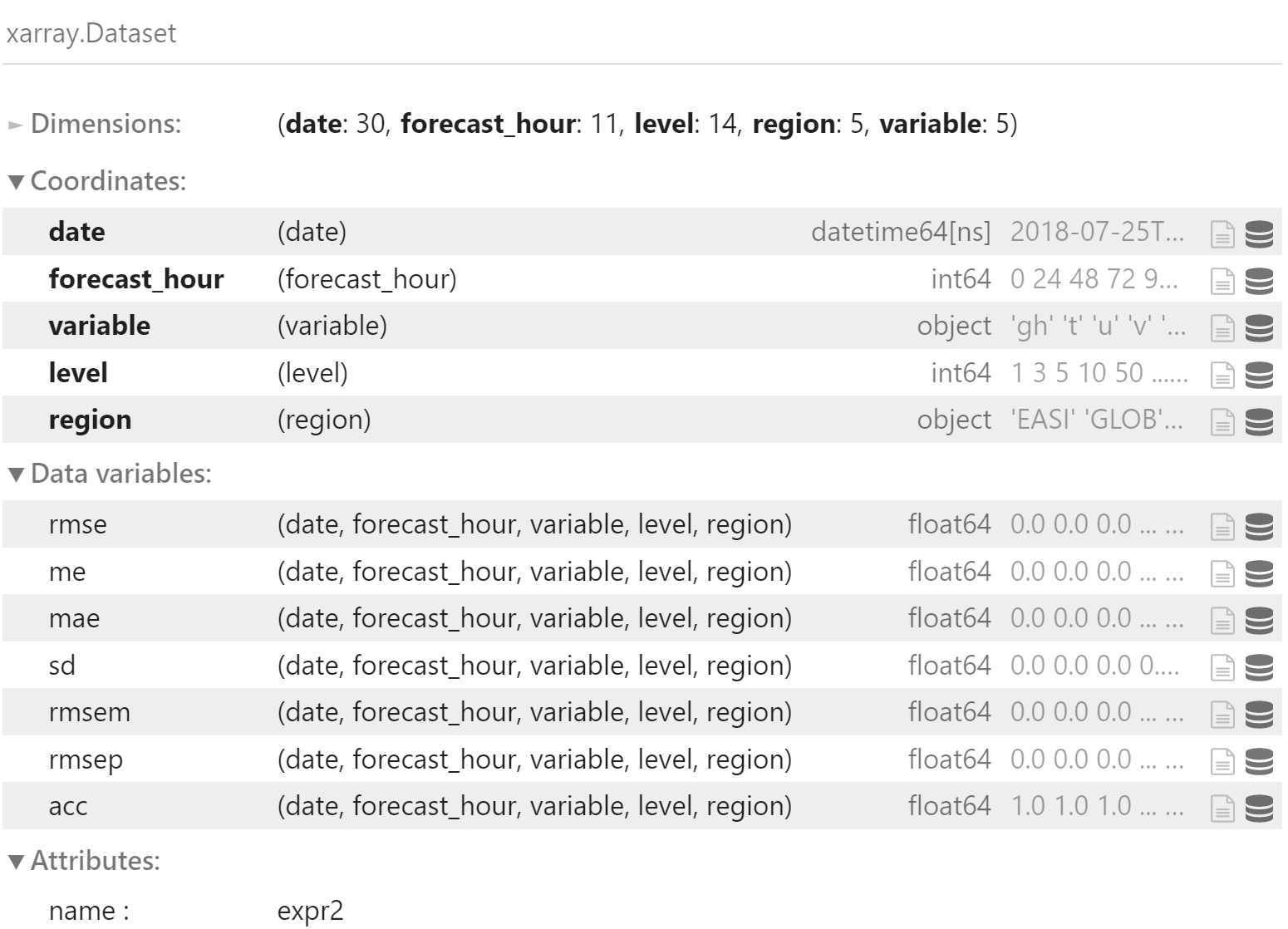
探索数据
选取全球区域 24 时效 850 hPa 的高度场的 ACC 指标
使用 sel 方法,返回一维数组,坐标为预报时间 (date)
acc_h850_024 = x.acc.sel(
forecast_hour=24,
variable="gh",
region="GLOB",
level=850,
)
acc_h850_024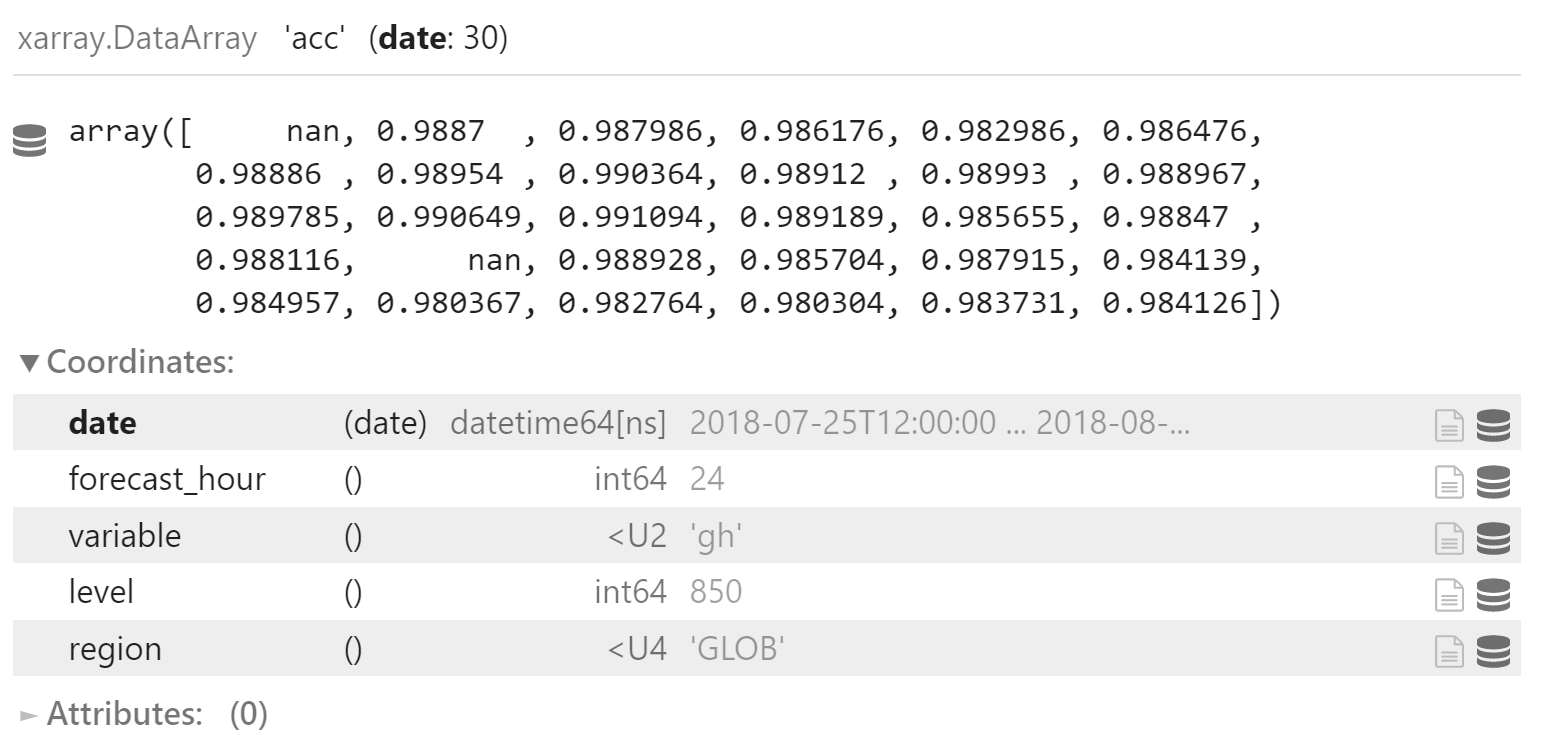
使用 plot 方法快速绘图
plt.figure(figsize=(10, 5))
acc_h850_024.plot()
plt.show()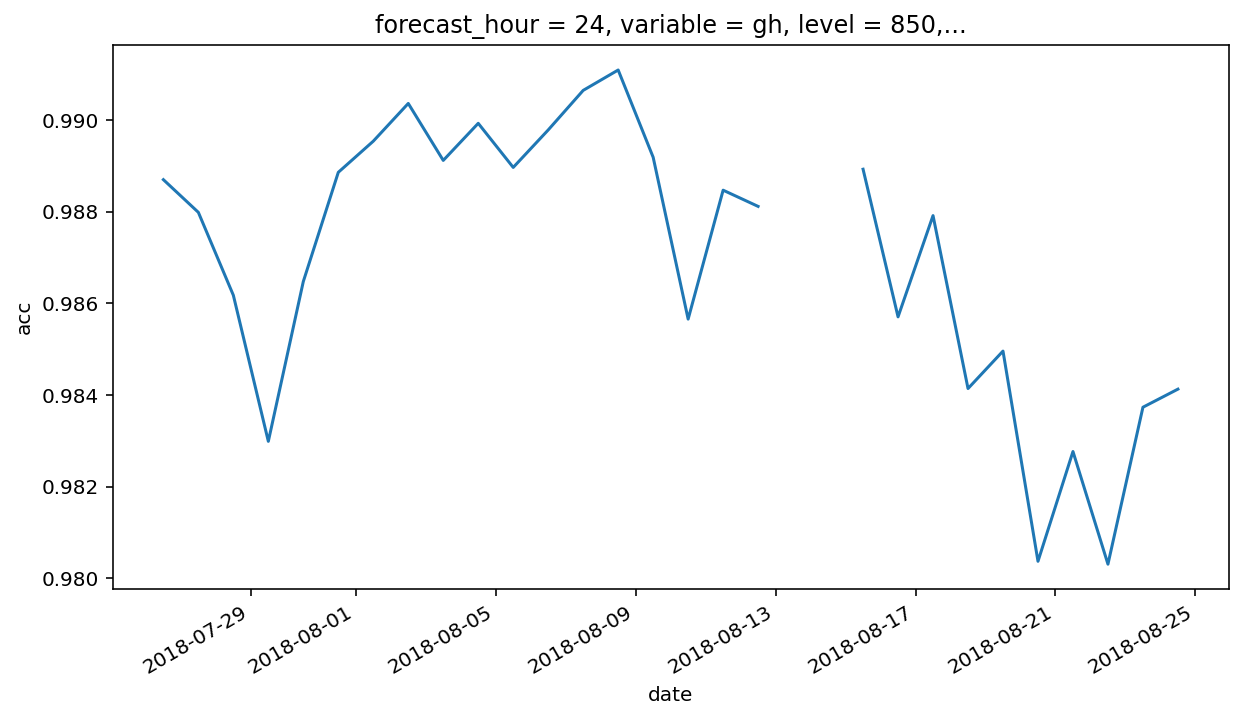
ctrl1
载入 ctrl1 控制预报的检验数据
file_list2 = [
f"./dask-stat/ctrl1/stats.{d.strftime('%Y%m%d%H')}.csv"
for d in date_list
]
df_ncep = pd.concat(
[read_stats(f) for f in file_list2]
)
y = df_ncep.to_xarray()
y.attrs["name"] = "ctrl1"
y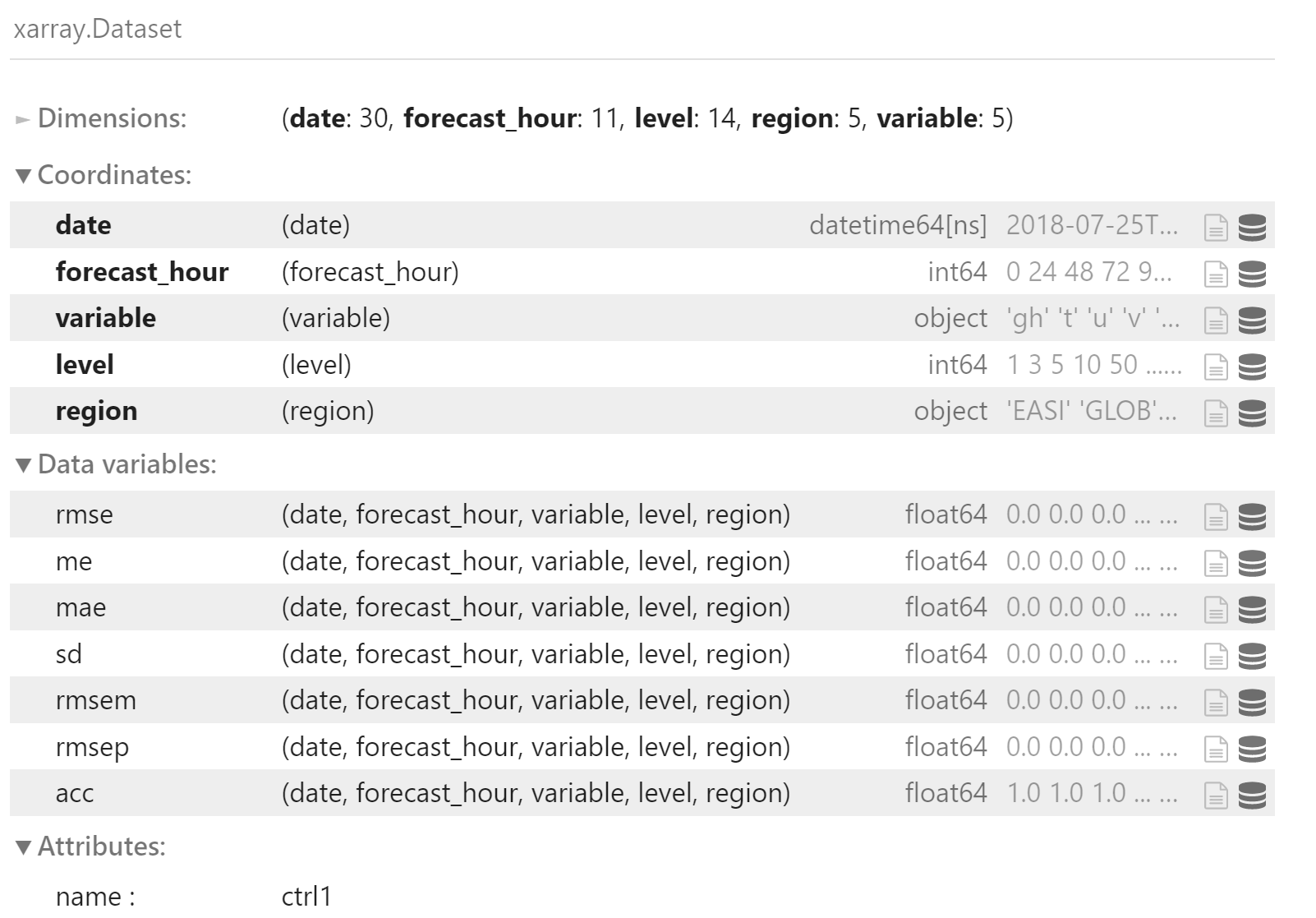
绘制时间序列图
时间序列图直接使用检验指标绘制,没有额外计算
添加一个新的坐标 name 代表试验名称,用于后续合并
acc_x = x.acc.sel(
forecast_hour=120,
variable="t",
region="GLOB",
level=850
)
acc_x.coords["name"] = "expr2"
acc_x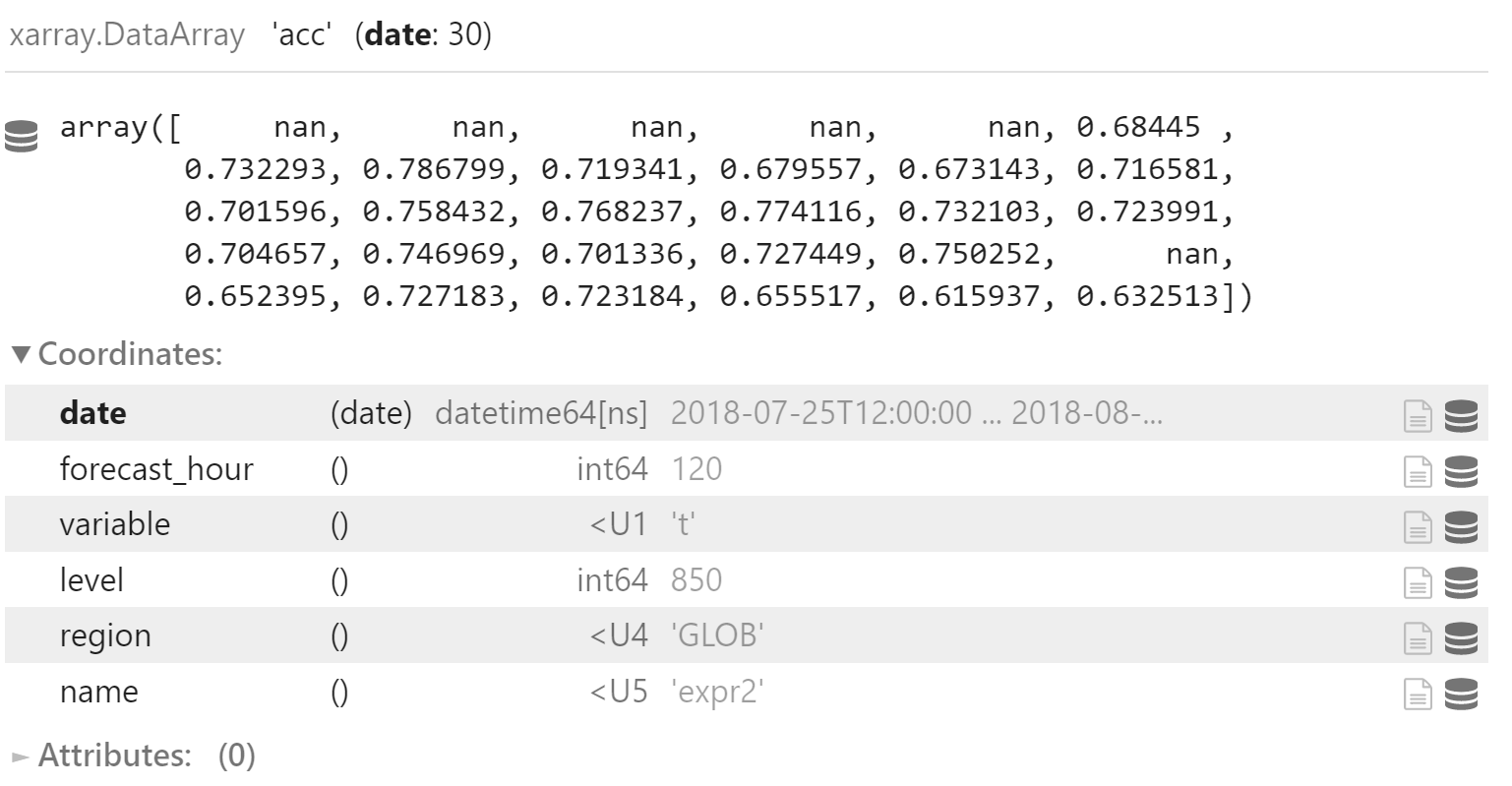
acc_y = y.acc.sel(
forecast_hour=120,
variable="t",
region="GLOB",
level=850
)
acc_y.coords["name"] = "ctrl1"
acc_y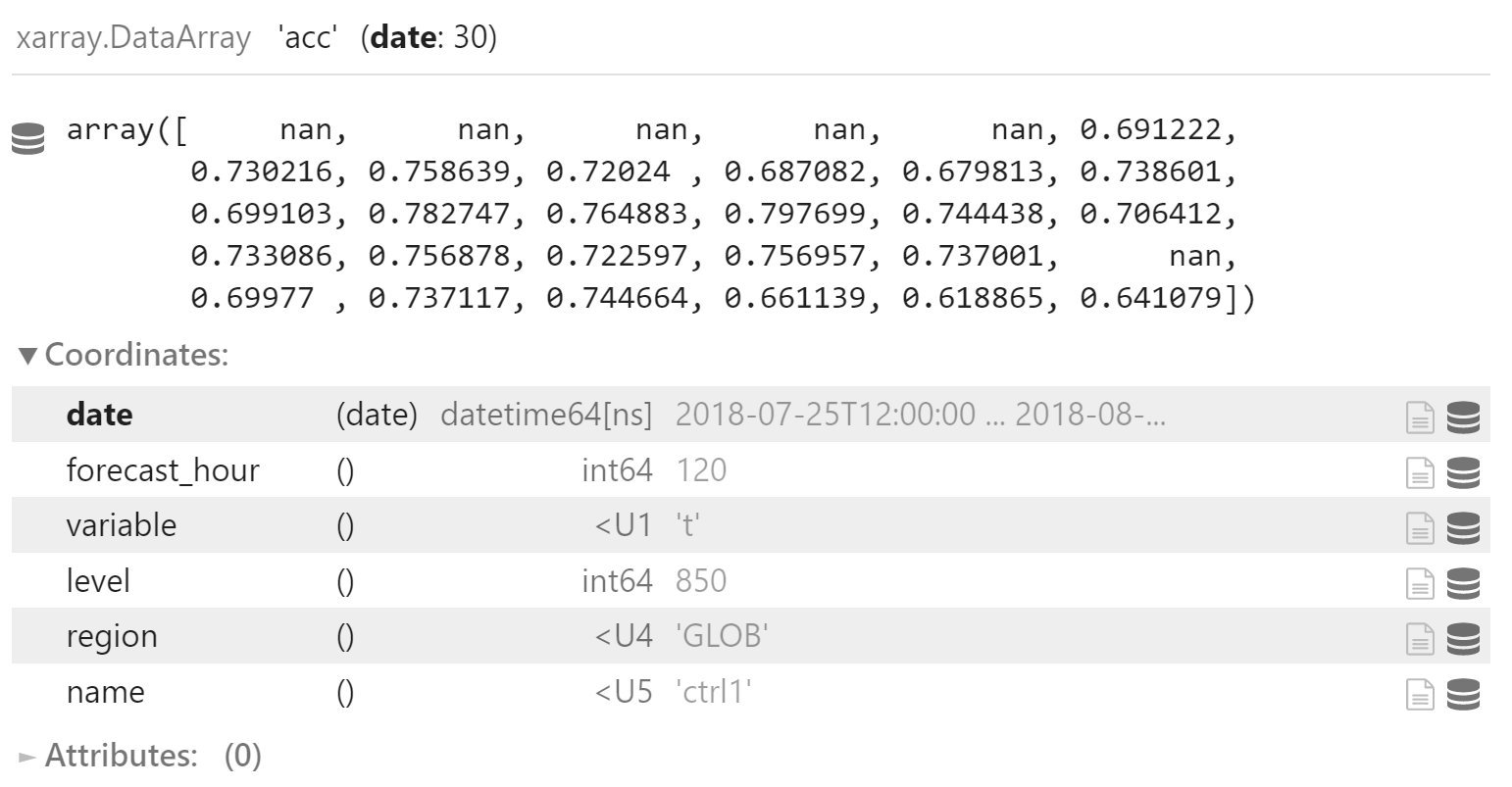
沿 name 维度合并两个不同试验的 ACC 指标,返回二维数组
plot_data = xr.concat([acc_x, acc_y], dim="name")
plot_data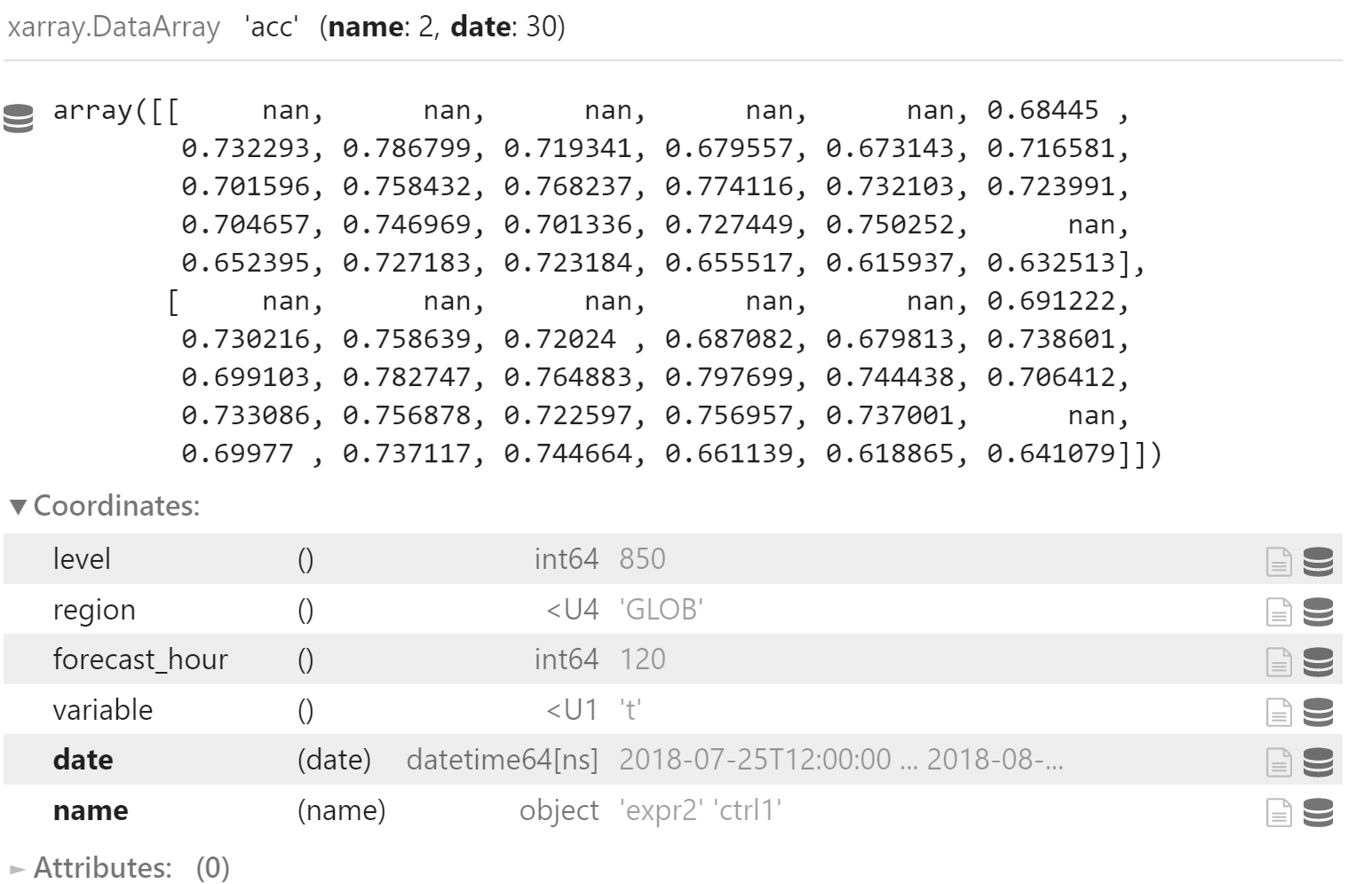
绘制时间序列图,横坐标为 date
plt.figure(figsize=(10, 5))
plot_data.plot.line(
x="date",
hue="name"
)
plt.show()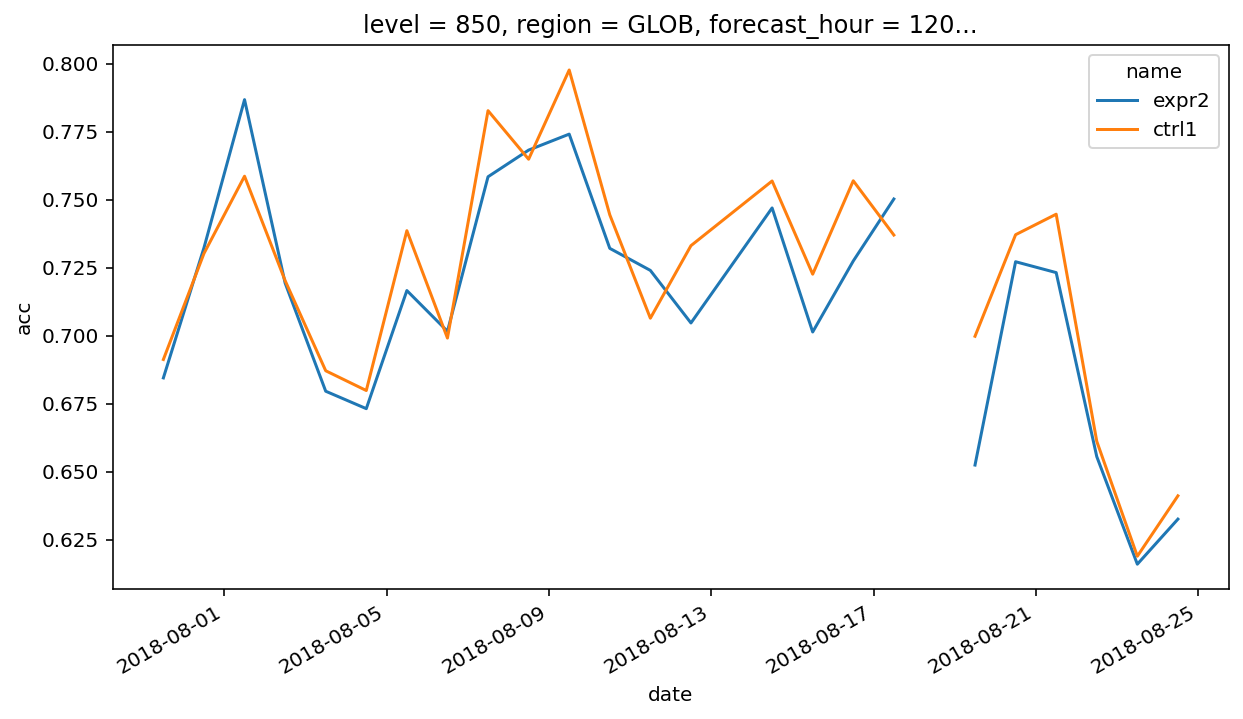
绘制垂直廓线图
需要为每个时效、每个变量、每个层次、每个区域的指标计算均值
ME
求均值
y_me = y["me"].sel(
forecast_hour=24,
region="GLOB",
variable="t"
)
y_me_mean = y_me.mean(dim="date")
y_me_mean.coords["name"] = "ctrl1"
y_me_mean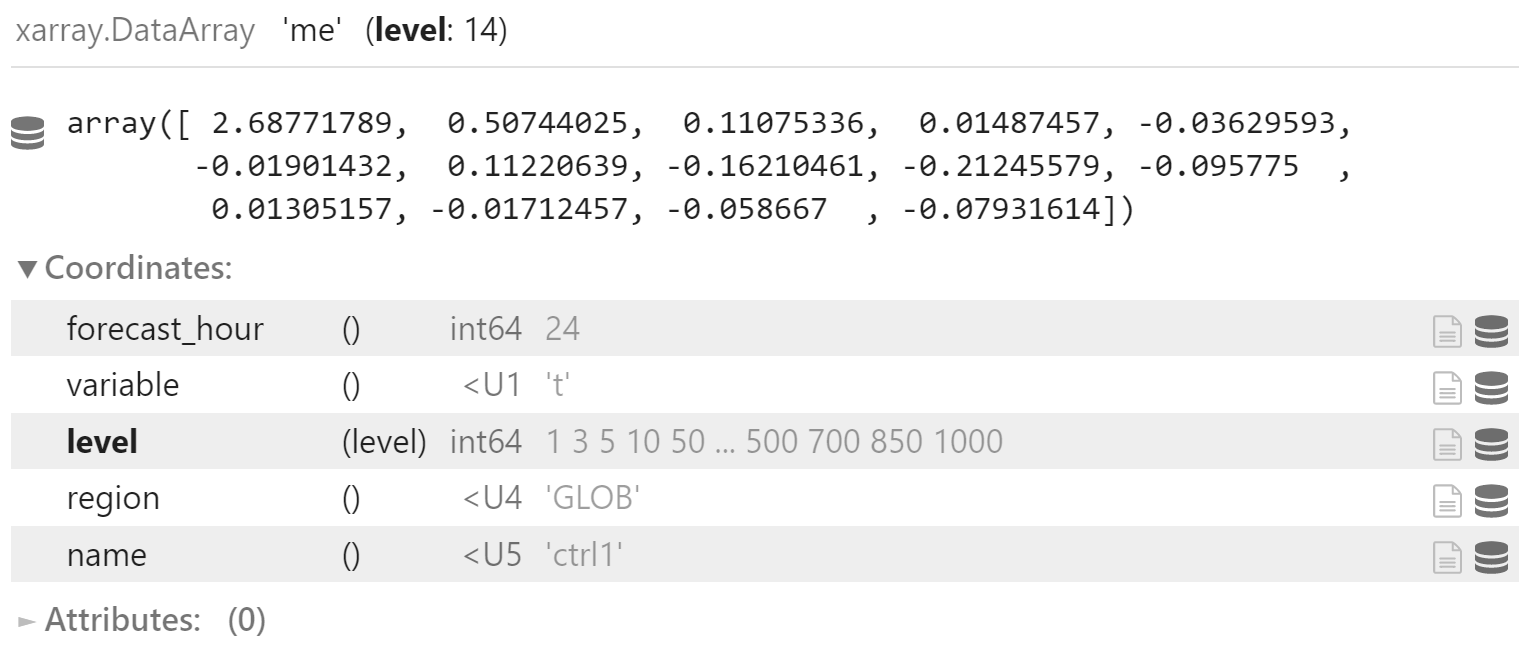
plt.figure(figsize=(8, 8))
y_me_mean.plot.line(
y="level",
yincrease=False,
yscale="log"
)
plt.show()
x_me = x["me"].sel(
forecast_hour=24,
region="GLOB",
variable="t"
)
x_me_mean = x_me.mean(dim="date")
x_me_mean.coords["name"] = "expr2"
x_me_mean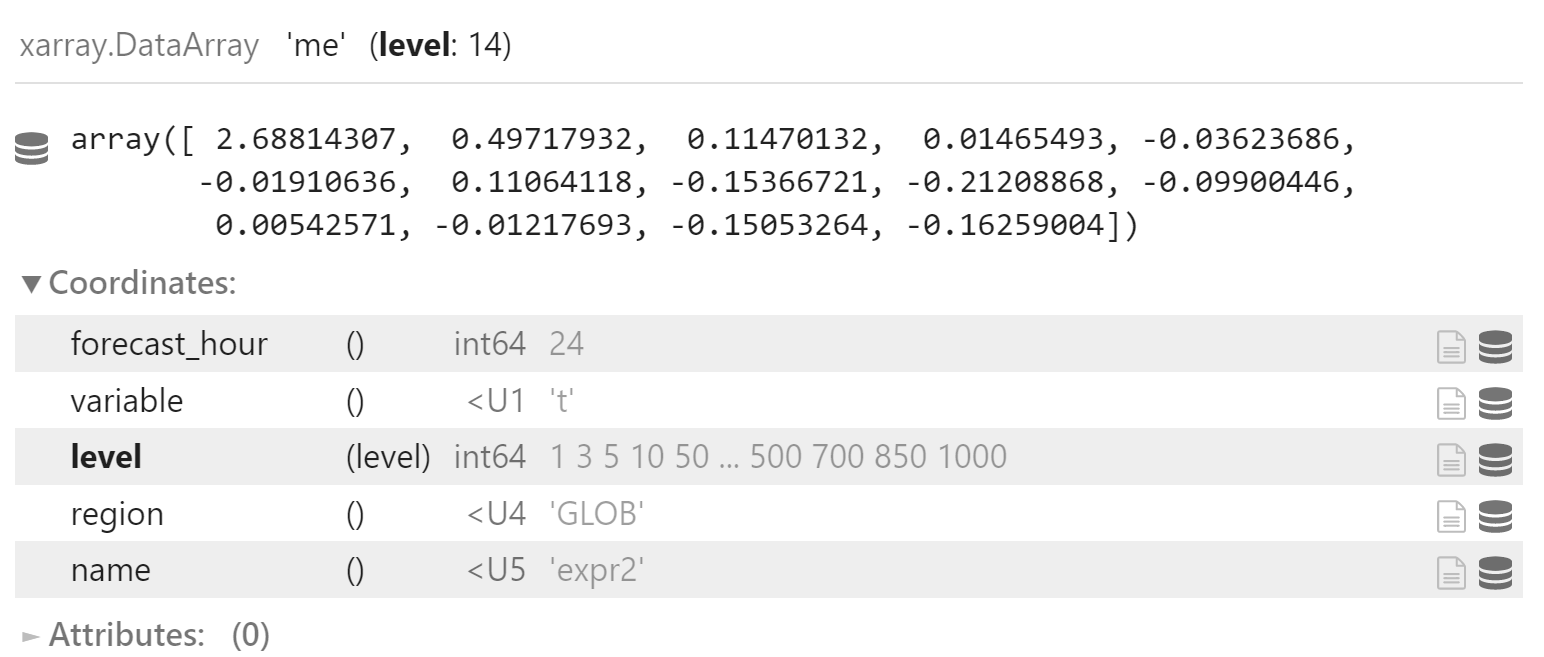
plt.figure(figsize=(8, 8))
x_me_mean.plot.line(
y="level",
yincrease=False,
yscale="log"
)
plt.show()
合并两个数据集
me_mean = xr.concat(
[x_me_mean, y_me_mean],
dim="name"
)
me_mean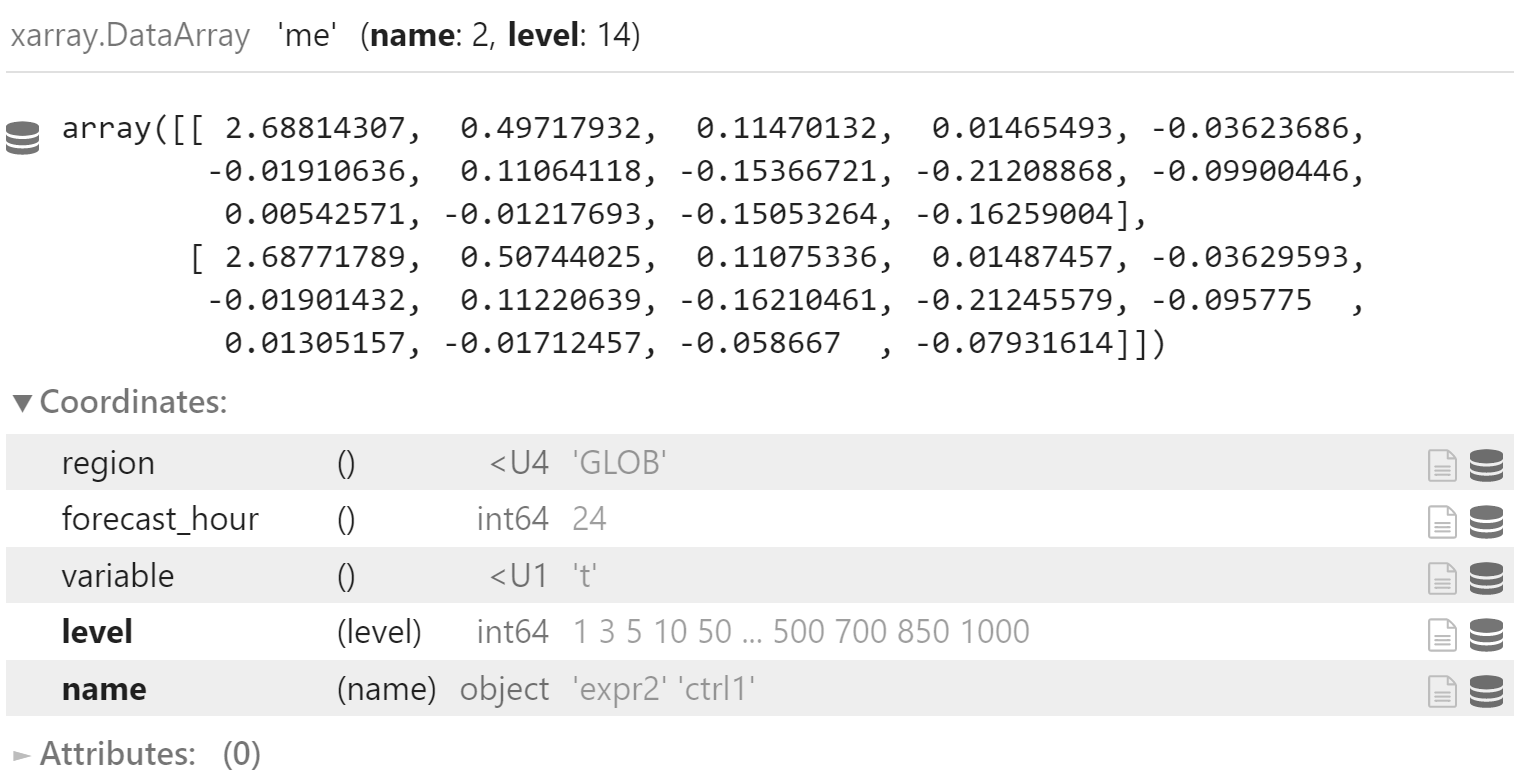
plt.figure(figsize=(8, 8))
me_mean.plot.line(
y="level",
yincrease=False,
yscale="log"
)
plt.show()
RMSE
计算均方根
x_rmse = x["rmse"].sel(
forecast_hour=24,
variable="t",
region="GLOB"
)
x_rmse_mean = np.sqrt((x_rmse*x_rmse).mean(dim="date", skipna=True))
x_rmse_mean.coords["name"] = "expr2"
x_rmse_mean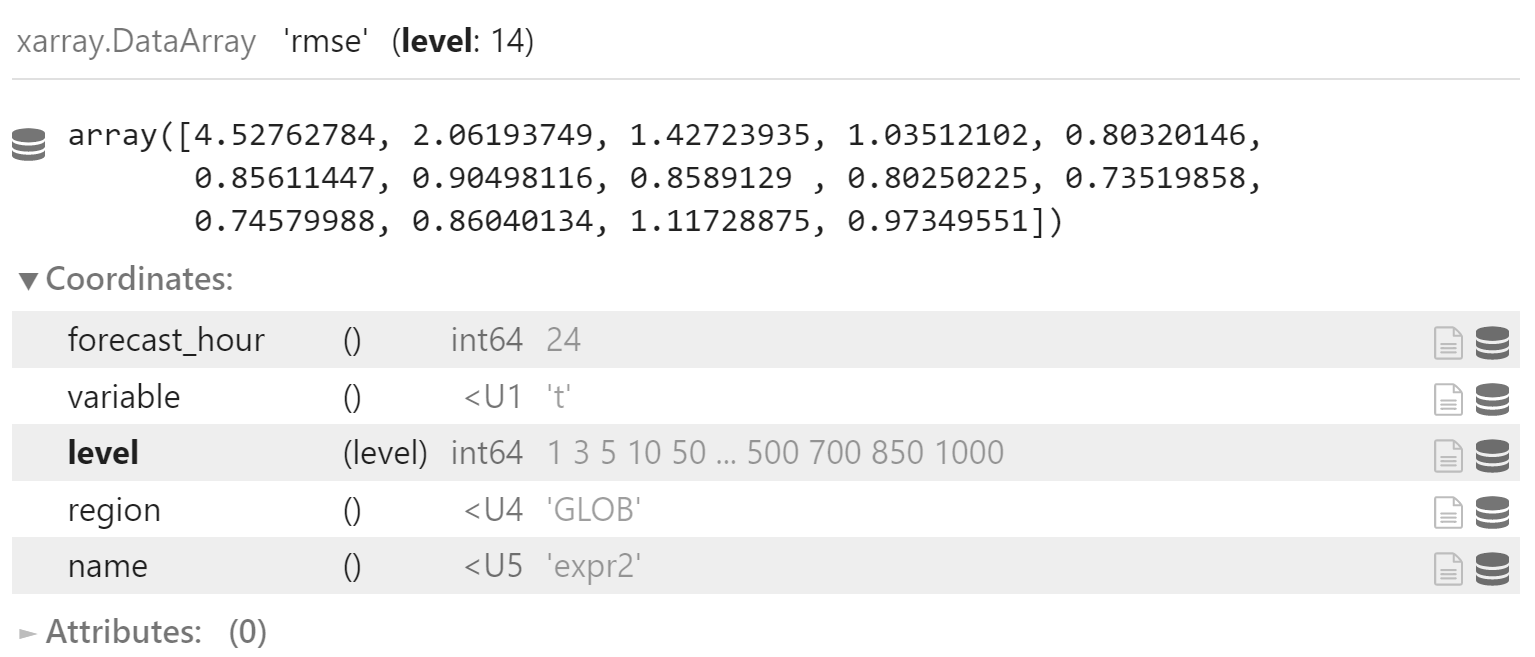
y_rmse = y["rmse"].sel(
forecast_hour=24,
variable="t",
region="GLOB"
)
y_rmse_mean = np.sqrt((y_rmse*y_rmse).mean(dim="date", skipna=True))
y_rmse_mean.coords["name"] = "ctrl1"
y_rmse_mean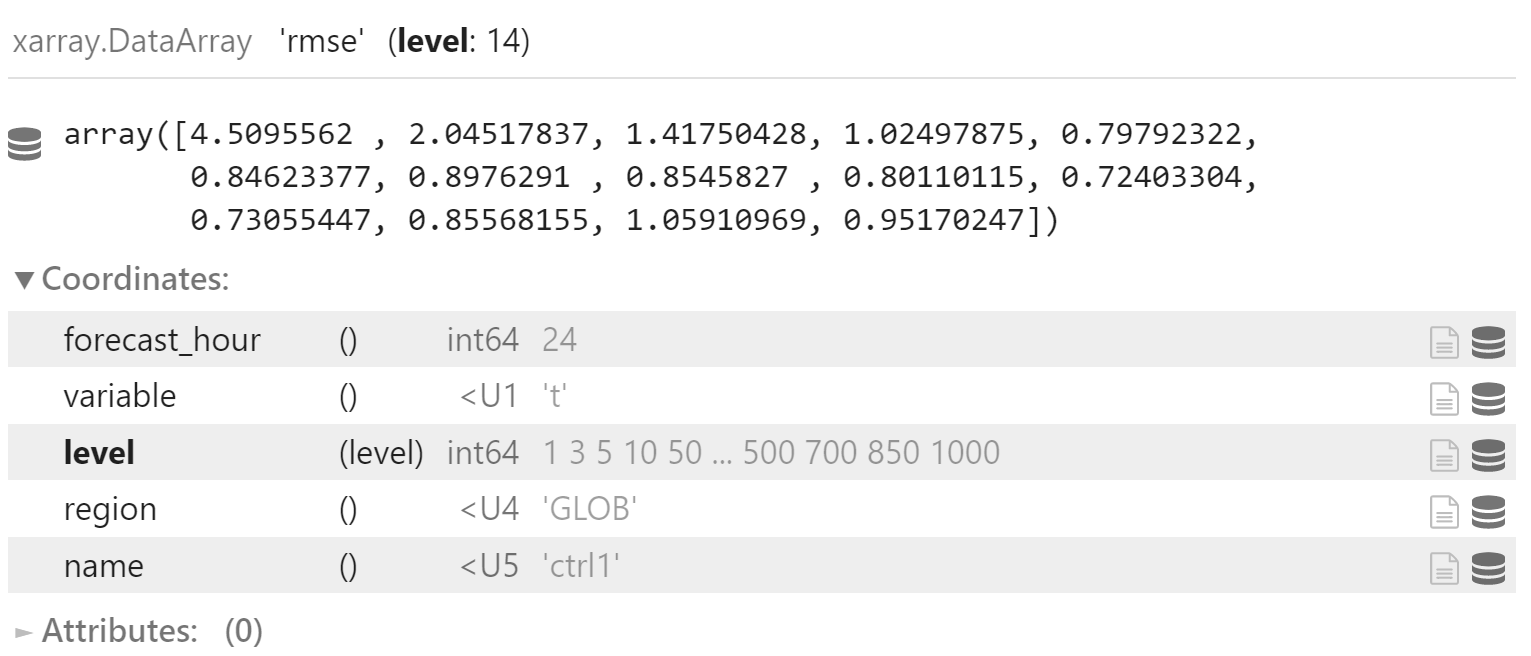
合并数据并画图
rmse_mean = xr.concat(
[x_rmse_mean, y_rmse_mean],
dim="name"
)
plt.figure(figsize=(8, 8))
rmse_mean.plot.line(
y="level",
yincrease=False,
yscale="log"
)
plt.show()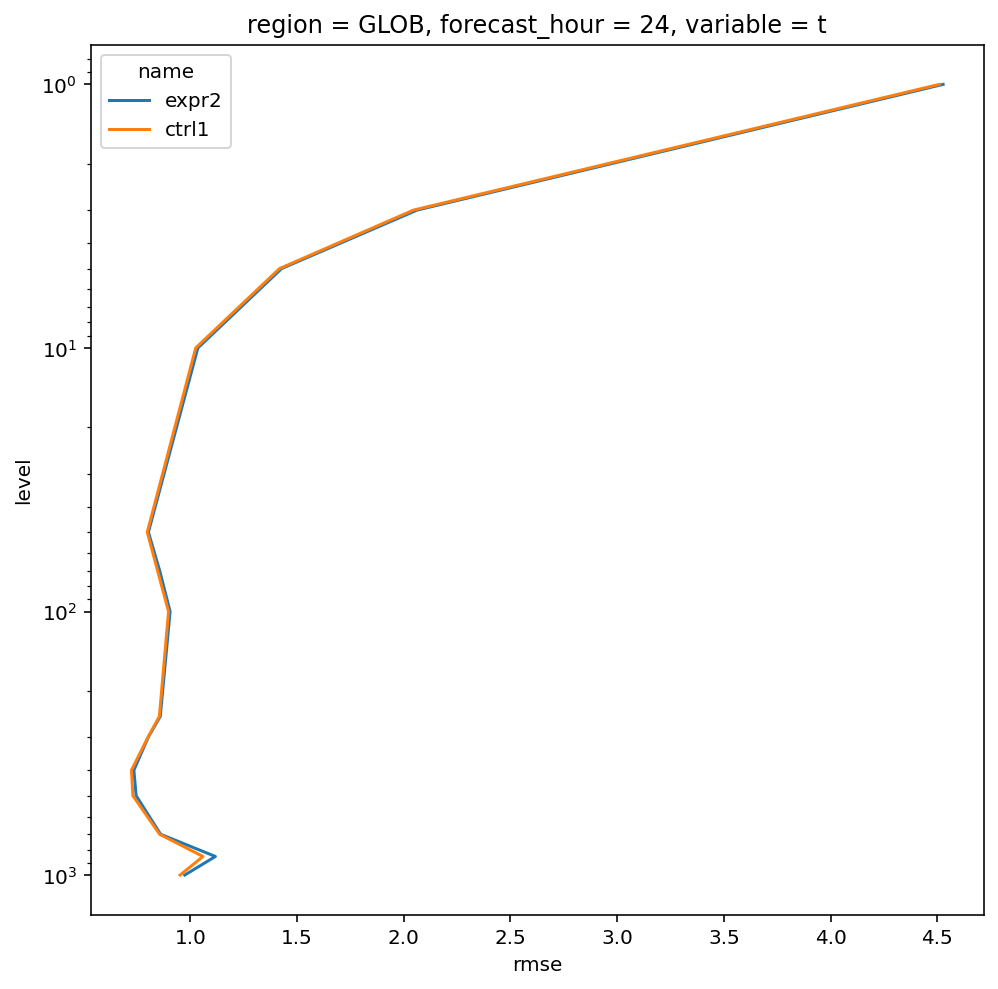
ACC
x_acc = x["acc"].sel(
forecast_hour=24,
variable="t",
region="GLOB"
)
x_acc_mean = np.log(
(x_acc + 1) / (1 - x_acc)
).mean(dim="date")
x_acc_mean = (np.exp(x_acc_mean) - 1) / (np.exp(x_acc_mean) + 1)
x_acc_mean.coords["name"] = "expr2"
x_acc_mean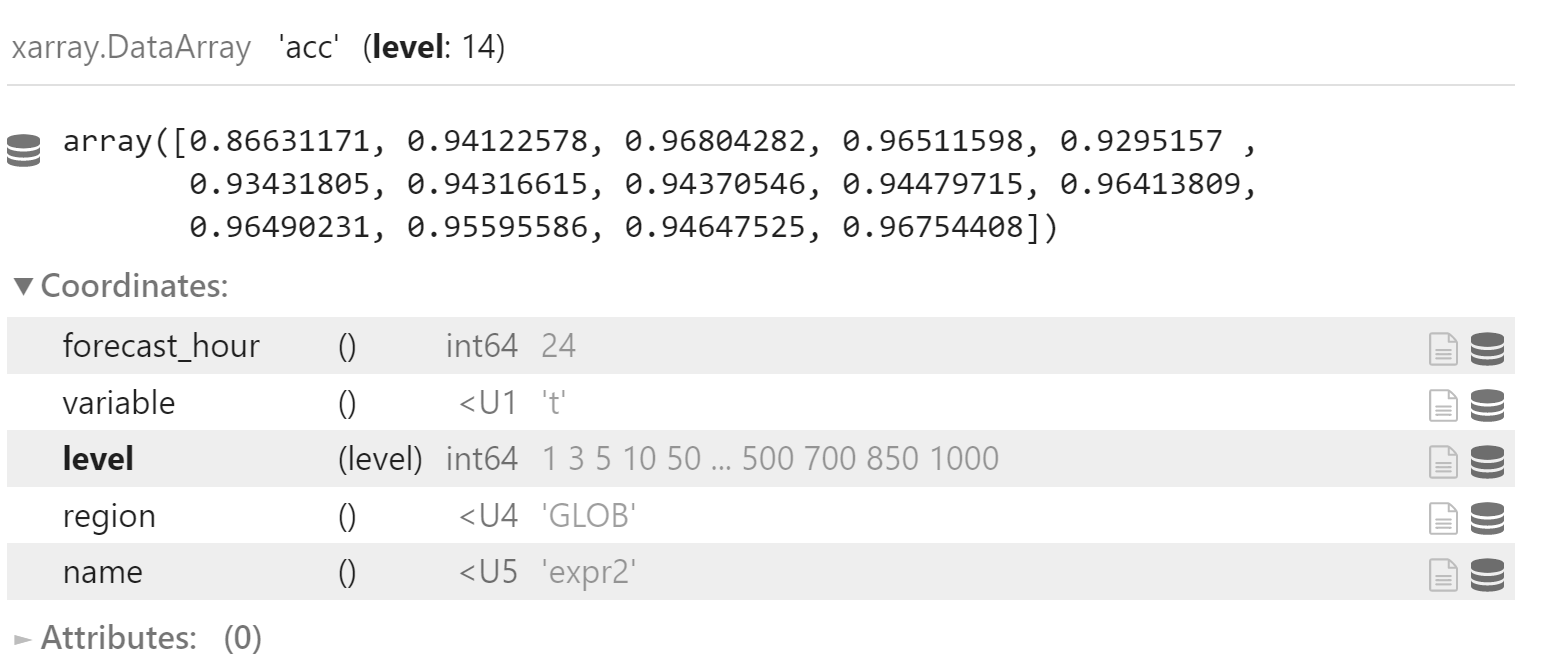
y_acc = y["acc"].sel(
forecast_hour=24,
variable="t",
region="GLOB"
)
y_acc_mean = np.log(
(y_acc + 1) / (1 - y_acc)
).mean(dim="date")
y_acc_mean = (np.exp(y_acc_mean) - 1) / (np.exp(y_acc_mean) + 1)
y_acc_mean.coords["name"] = "ctrl1"
y_acc_mean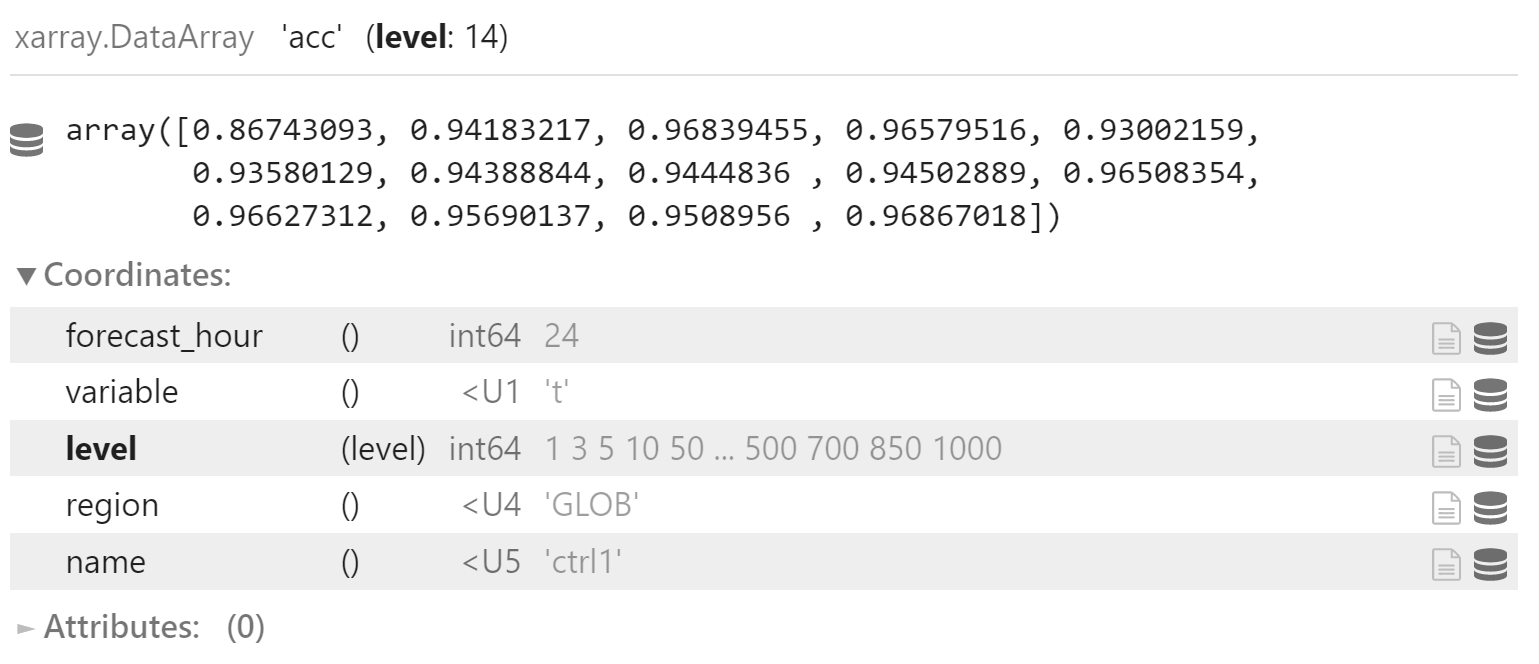
合并数据并画图
acc_mean = xr.concat(
[x_acc_mean, y_acc_mean],
dim="name"
)
plt.figure(figsize=(8, 8))
acc_mean.plot.line(
y="level",
yincrease=False,
yscale="log"
)
plt.show()
绘制平均图
RMSE
准备数据
x_rmse = x["rmse"].sel(
variable="t",
level=850,
region="GLOB"
)为每个预报时效求均值
x_rmse_mean = np.sqrt(
(x_rmse * x_rmse).mean(
dim="date",
skipna=True
)
)
x_rmse_mean.coords["name"] = "expr2"
x_rmse_mean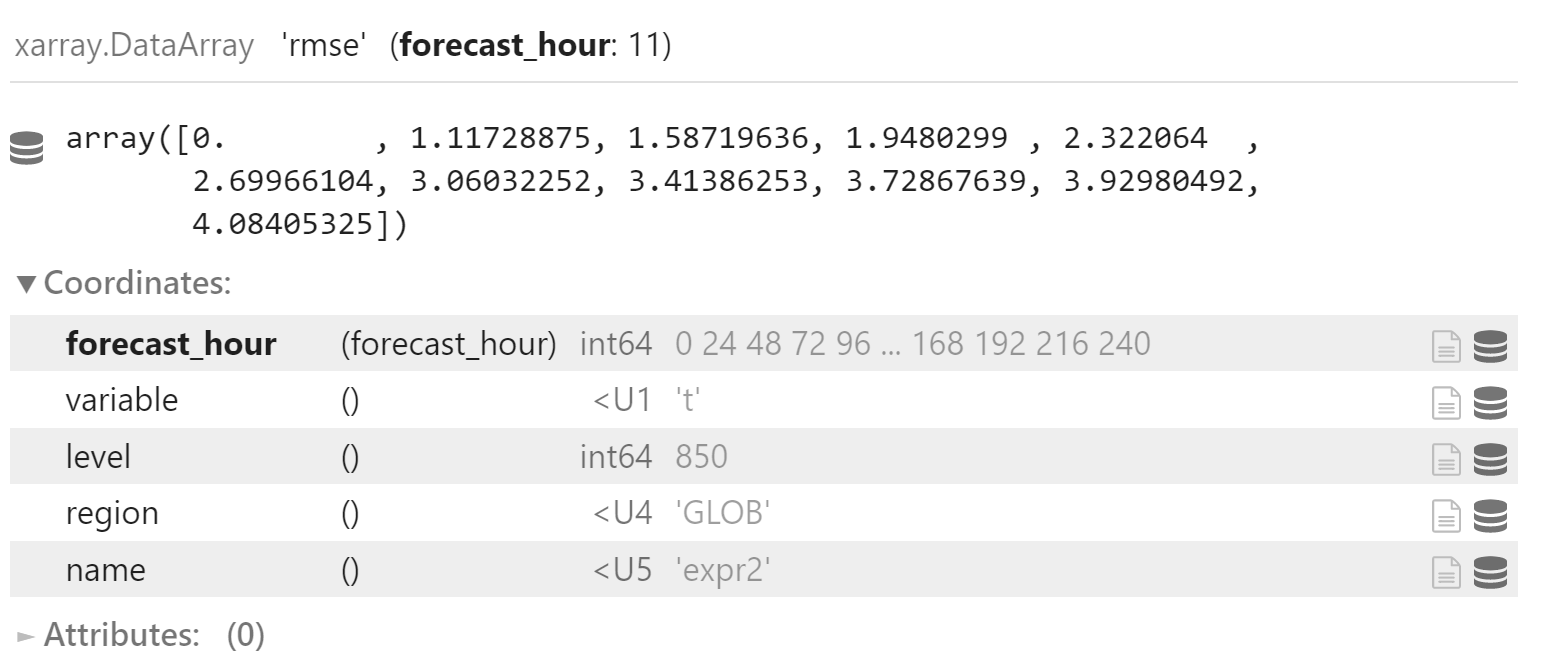
y_rmse = y["rmse"].sel(
variable="t",
level=850,
region="GLOB"
)
y_rmse_mean = np.sqrt(
(y_rmse*y_rmse).mean(
dim="date",
skipna=True
)
)
y_rmse_mean.coords["name"] = "ctrl1"
y_rmse_mean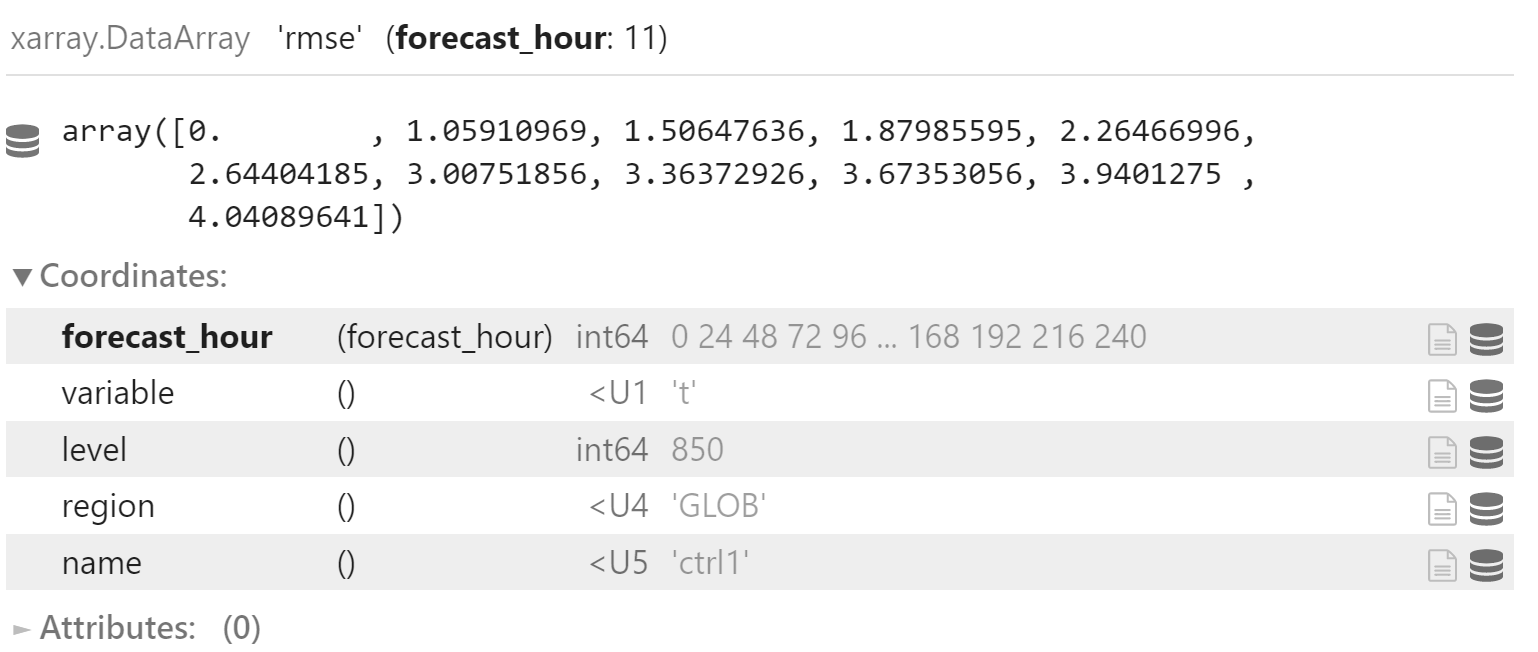
计算
计算单个时效的 Bootstrap 置信区间
bootstrap_rmses = []
forecst_hour_df = x_rmse.sel(forecast_hour=24).to_dataframe()
for i in tqdm(range(10000)):
m = forecst_hour_df.sample(30, replace=True)["rmse"].mean()
bootstrap_rmses.append(m)
df = pd.DataFrame({"rmse": bootstrap_rmses})
df.describe()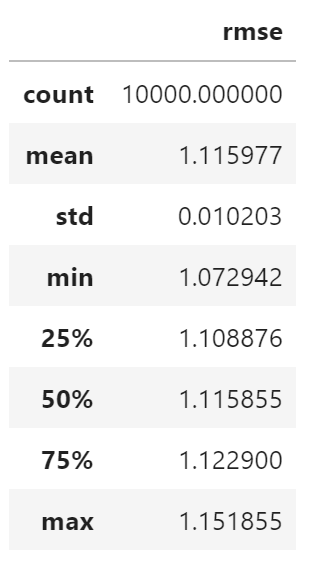
df.quantile(0.975)rmse 1.13626
Name: 0.975, dtype: float64
df.quantile(0.025)rmse 1.096304
Name: 0.025, dtype: float64
所有时效的 95% 置信区间
uppers = []
lowers = []
rmse_diff = x_rmse - y_rmse
for forecast_hour in tqdm(x_rmse.coords["forecast_hour"]):
bootstrap_rmses = []
forecst_hour_df = rmse_diff.sel(forecast_hour=forecast_hour).to_dataframe()
for i in tqdm(range(10000), leave=False):
m = forecst_hour_df.sample(30, replace=True)["rmse"].mean(skipna=True)
bootstrap_rmses.append(m)
df = pd.DataFrame({"rmse": bootstrap_rmses})
upper = df["rmse"].quantile(0.975)
lower = df["rmse"].quantile(0.025)
uppers.append(upper)
lowers.append(lower)
ds = xr.Dataset({
"upper": (x_rmse_mean.dims, uppers),
"lower": (x_rmse_mean.dims, lowers),
},
coords=x_rmse_mean.coords,
)
ds["y_mean"] = y_rmse_mean
ds["x_mean"] = x_rmse_mean
ds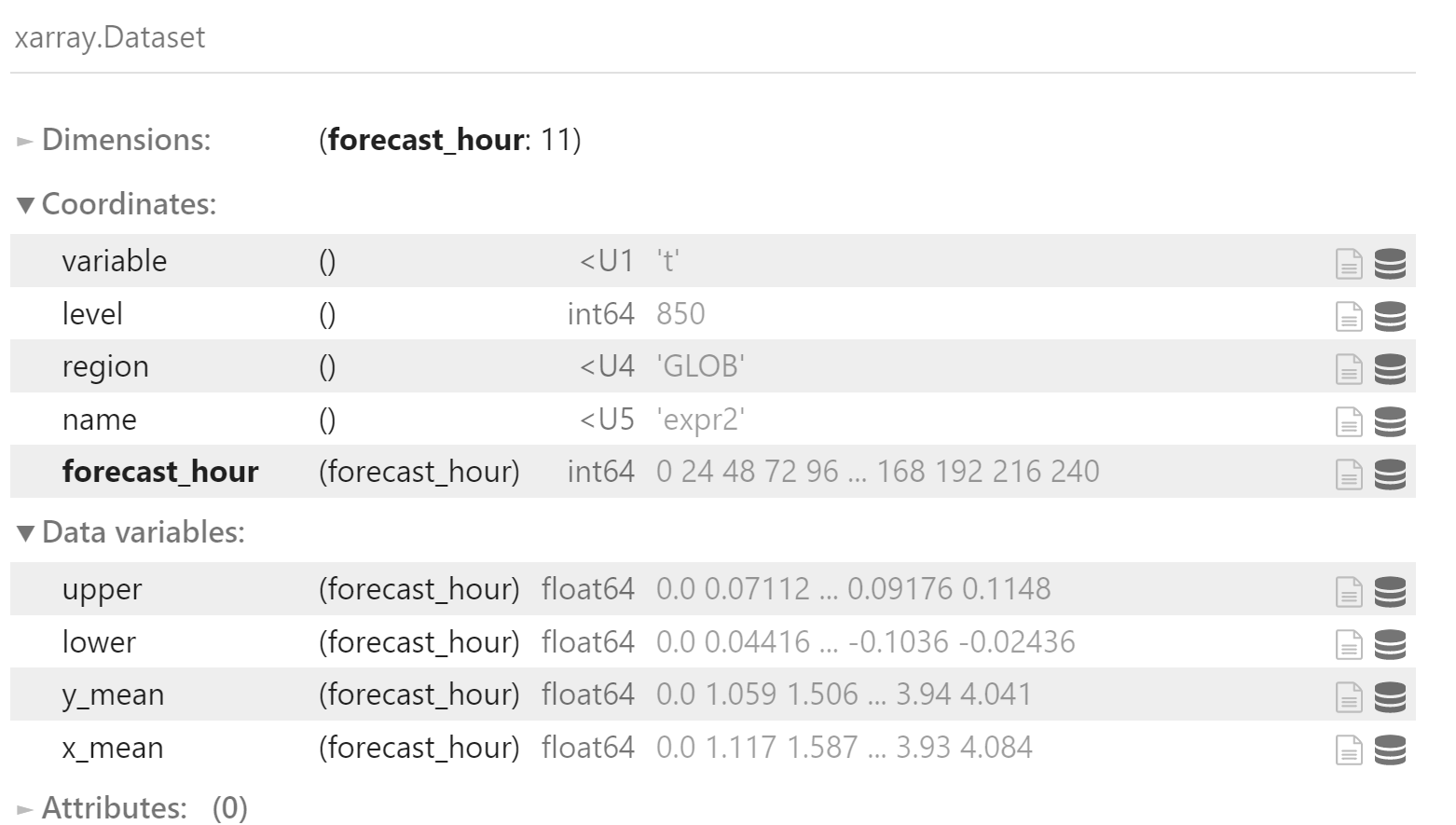
画图
绘制逐时效 RMSE 变化
fig, axes = plt.subplots(
figsize=(10, 6)
)
axes.xaxis.set_major_locator(plt.MultipleLocator(24))
ds["x_mean"].plot.line(
x="forecast_hour",
ax=axes,
)
ds["y_mean"].plot.line(
x="forecast_hour",
ax=axes
)
axes.legend(["grapes", "ncep"])
plt.show()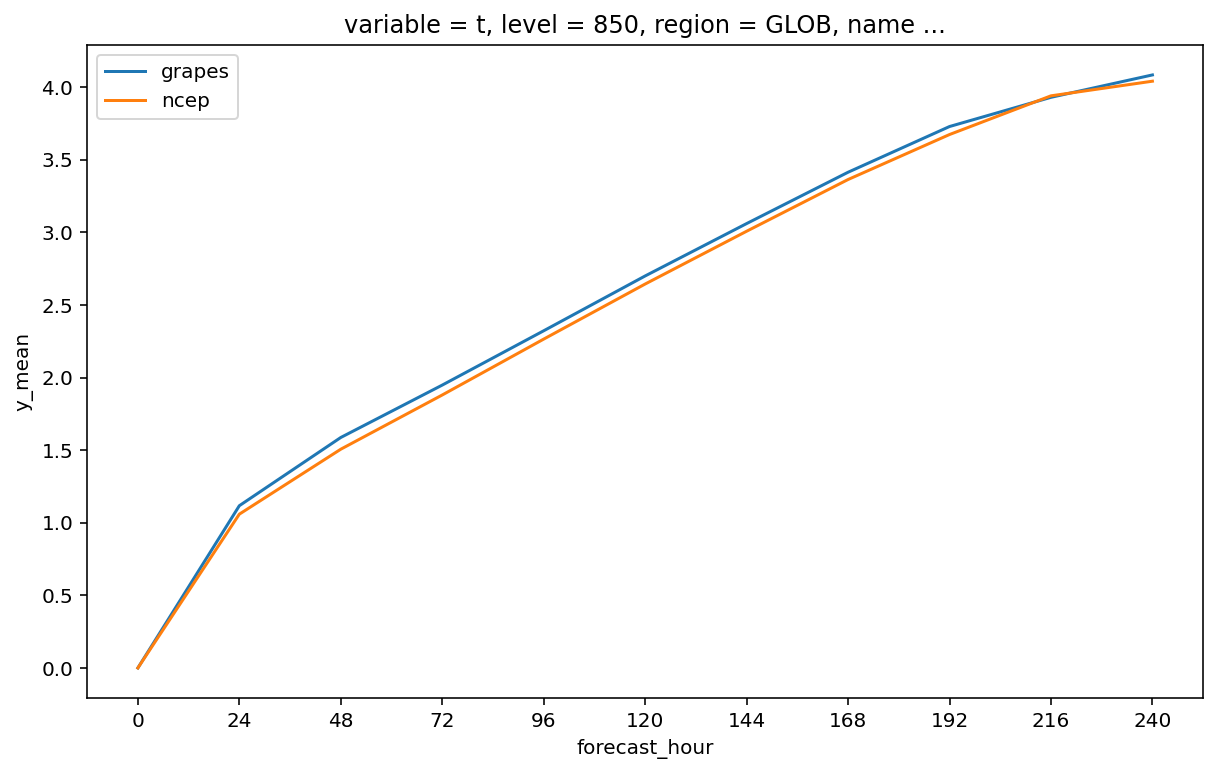
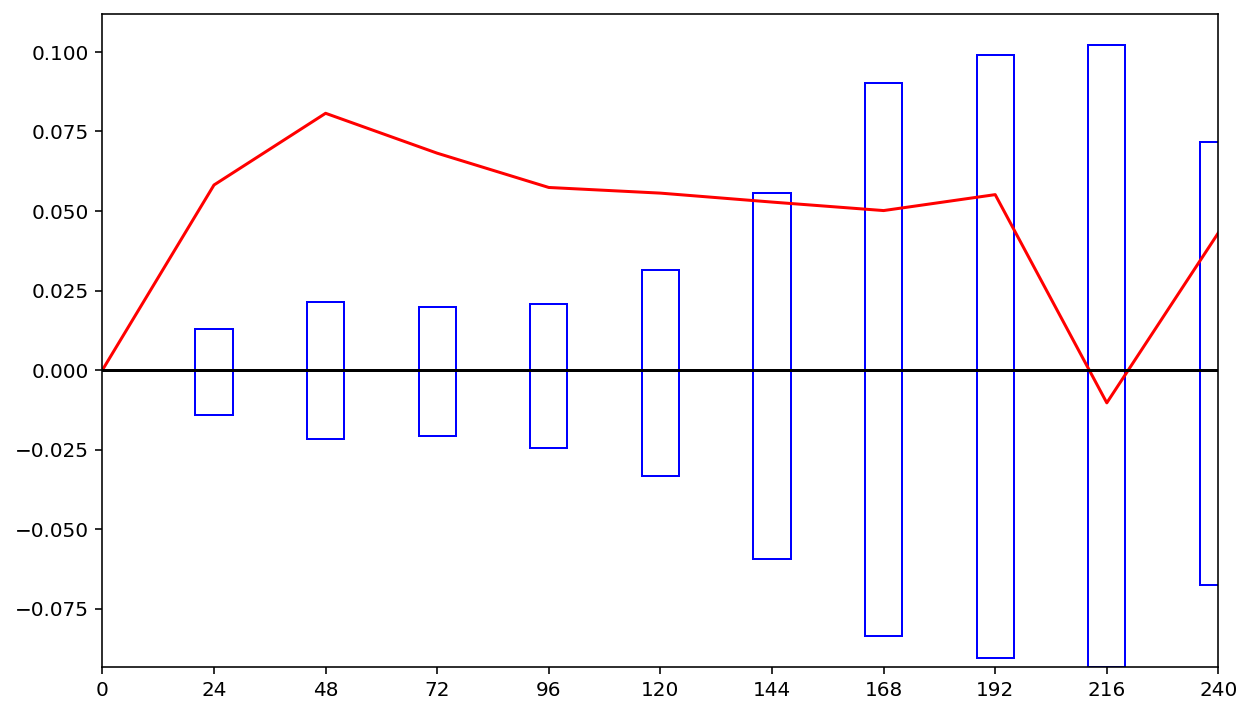
绘制模式试验 expr2 相对于控制预报 ctrl1 的 RMSE 平均差值和 95% 置信区间
fig, axes = plt.subplots(
figsize=(10, 6)
)
axes.xaxis.set_major_locator(plt.MultipleLocator(24))
plt.bar(
ds.forecast_hour.values,
(ds.upper - ds.lower).values,
width=8,
bottom=(ds.lower - (ds.x_mean - ds.y_mean)).values,
edgecolor="blue",
color="white"
)
plt.plot(
ds.forecast_hour.values,
(ds.x_mean - ds.y_mean).values,
color="red"
)
plt.plot(
ds.forecast_hour,
np.zeros(len(ds.forecast_hour)),
color="black",
)
plt.xlim([0, 240])
plt.show()