计算等压面要素场检验指标 - 并发
上一篇文章《计算等压面要素场检验指标 - 多时效》中介绍如何批量计算等压面要素多个时次多时效的检验指标。
本文进一步讨论批量计算的耗时,关注计算效率问题。
计算分析
在《多时效》的“计算”章节中,笔者使用 5 层 for 循环,逐个为每个要素场计算检验指标。
下图展示了计算的层次,并将部分耗时较长的代码封装成函数。
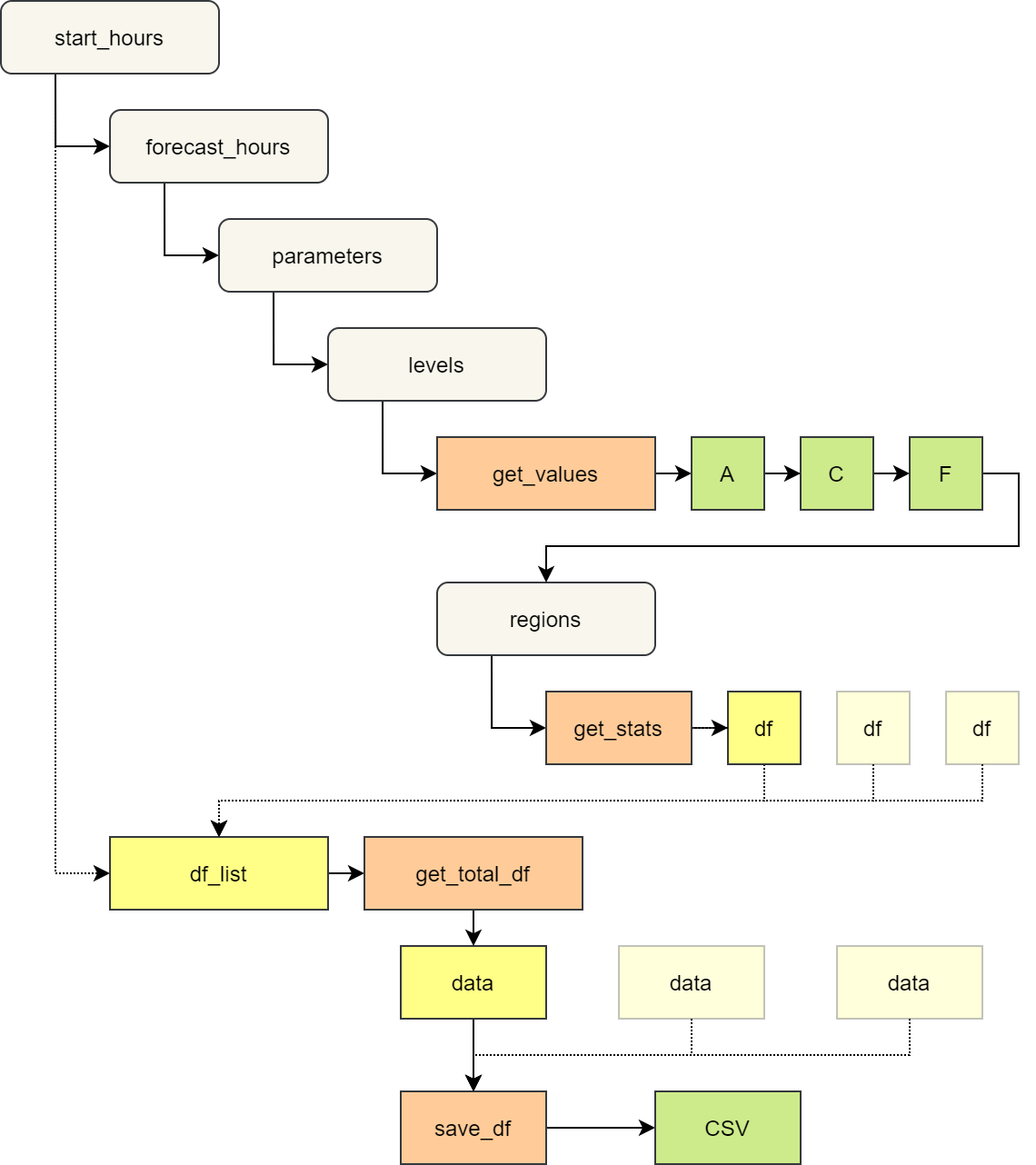
等压面要素场检验指标批量计算层次
get_values 函数用于从 GRIB 2 文件中载入需要的要素场。
对于每个要素场,需要从三个不同的文件中分别加载预报场 (F),分析场 (A) 和气候场 (C)。
get_stats 函数计算并返回一组检验指标。
每个要素场 (由 start_hours,forecast_hours,parameters 和 levels 决定) 计算多个区域 (regions)。
get_total_df 函数将多组的检验指标合并。
每个时间点 (start_hours) 执行一次。
save_df 将某天对应的所有检验指标写入到 CSV 文件中。
每个时间点 (start_hours) 执行一次。
串行耗时
使用《多时效》文中的示例数据,串行执行上述过程,不包含 save_df,在 Jupyter Notebook 中使用 %%time 统计耗时如下:
CPU times: user 20min 28s, sys: 1min 29s, total: 21min 57s
Wall time: 22min 22s
即计算一个月数据的指标用时超过 20 分钟,显然耗时太长。 可以使用并发方式加快计算过程。
并发设计
并发的关键在于尽可能将 for 循环中的操作同时运行。
从上图中可以看到,整个循环过程中有很多计算是相互独立的,可以并发运行。
例如:
- 每个要素场都调用 3 次
get_values函数,可以同时运行。 - 每个要素场为多个区域调用
get_stats函数,可以同时运行。 - 不同要素场的计算可以同时运行。
- 每个时间点调用一次
get_total_df函数和save_df函数,多个时间点可以同时运行。
根据上述特点,设计如下的并发运行方案。
每个时间点独立运行;时间点中的每个要素场独立运行;每个要素场首先并发读取三个数据,再并发计算 5 个区域的指标。
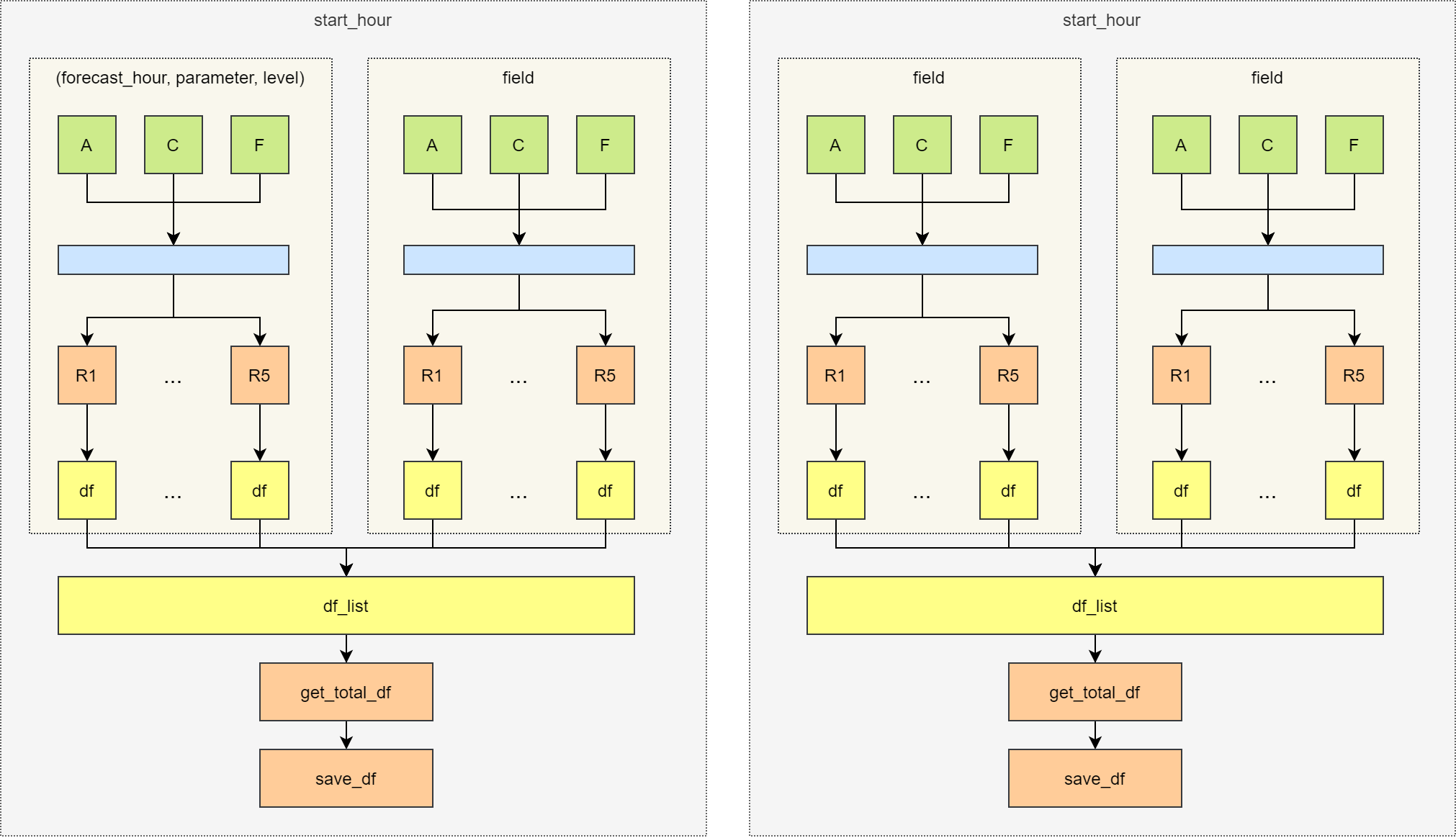
等压面要素场检验指标并发计算方案
使用 dask 库的 dask.delayed 方法实现并发计算功能。
并发耗时
在 CMA 的 HPC PI 登陆节点上运行,启动 8 个进程,每个进程有 4 个线程,共 32 个工作单元。
并发耗时如下所示:

运行时间减为 3 分钟以内,并发计算效果比较明显。
实现
仅列出与前一篇文章不同的代码。
封装函数
将多重 for 循环中的部分操作封装成函数。
get_values 函数用于从 GRIB 2 文件中载入需要的要素场。
def get_values(
file_path,
parameter,
level,
):
message = get_message(
file_path,
parameter=parameter,
level=level,
)
array = eccodes.codes_get_double_array(message, "values").reshape([121, 240])
eccodes.codes_release(message)
return arrayget_stats 函数计算并返回一组检验指标。
def get_stats(
forecast_array,
analysis_array,
climate_array,
domain,
current_forecast_hour,
level,
region,
):
df = calculate_plev_stats(
forecast_array=forecast_array,
analysis_array=analysis_array,
climate_array=climate_array,
domain=domain,
)
# 增加元信息
df["forecast_hour"] = current_forecast_hour
df["variable"] = parameter
df["level"] = level
df["region"] = region
return dfget_total_df 函数将多组的检验指标合并。
def get_total_df(df_list):
df = pd.concat(df_list, ignore_index=True)
df = df.set_index(["forecast_hour", "variable", "level", "region"])
return dfsave_df 将某天对应的所有检验指标写入到 CSV 文件中。
def save_df(df, start_hour):
merged_df = pd.merge(
df_index, df,
left_index=True,
right_index=True,
how="left"
).fillna(-999.0)
plain_merged_df = merged_df.reset_index()
plain_merged_df.to_csv(
f"dask-stat/stat.{start_hour.strftime('%Y%m%d')}.csv",
index=False,
float_format="%.6f",
)并发执行
在本地主机上启动 dask 分布式调度客户端
import dask
from dask.distributed import Client, progress
dask_client = Client()
dask_client
使用 dask 库的 dask.delayed 方法封装上面的函数调用。
为每天分别生成检验指标表格数据。
dfs = []
for current_date in start_hours:
analysis_data_path = pathlib.Path(
analysis_root_dir,
f"pgbf000.grapes.{current_date.strftime('%Y%m%d%H')}",
)
climate_data_path = pathlib.Path(
climate_root_dir,
f"cmean_1d.1959{current_date.strftime('%m%d')}",
)
df_list = []
for current_forecast_hour in forecast_hours:
forecast_date = current_date - pd.Timedelta(hours=current_forecast_hour)
forecast_data_path = pathlib.Path(
forecast_root_dir,
f"pgbf{current_forecast_hour:03d}.grapes.{forecast_date.strftime('%Y%m%d%H')}"
)
if (not forecast_data_path.exists()) or (not analysis_data_path.exists()):
continue
for parameter in parameters:
for level in levels:
analysis_array = dask.delayed(get_values)(analysis_data_path, parameter, level)
climate_array = dask.delayed(get_values)(climate_data_path, parameter, level)
forecast_array = dask.delayed(get_values)(forecast_data_path, parameter, level)
for area in regions:
domain = area["domain"]
region = area["name"]
df = dask.delayed(get_stats)(
forecast_array,
analysis_array,
climate_array,
domain,
current_forecast_hour,
level,
region,
)
df_list.append(df)
if len(df_list) == 0:
continue
df = dask.delayed(get_total_df)(df_list)
dfs.append({
"start_hour": current_date,
"data": df,
})将指标数据保存到 CSV 文件中
tasks = []
for item in dfs:
start_hour = item["start_hour"]
task = dask.delayed(save_df)(item["data"], start_hour)
tasks.append(task)后台执行操作,并显示“并发耗时”节中任务执行的进度条。
r = dask_client.persist(tasks)
progress(r)关闭调度客户端
dask_client.close()总结
dask.delayed 是一种开箱即用的并发程序设计工具,很容易实现对 for 循环的优化。
但想要对程序进一步优化,还需要继续了解 Dask 库提供的其他工具。