预测雷暴旋转的基础机器学习:分类 - 决策树集成学习
本文翻译自 AMS 机器学习 Python 教程,并有部分修改。
Lagerquist, R., and D.J. Gagne II, 2019: “Basic machine learning for predicting thunderstorm rotation: Python tutorial”.
本文接上一篇文章《预测雷暴旋转的基础机器学习:分类 - 决策树超参数试验》。
本文介绍如何使用随机森林 (Random Forest) 和梯度提升决策树 (Gradient Boosted Decision Trees, GBDT) 降低决策树的过拟合现象。
随机森林
随机森林 (Random Forest) 是决策树的集合。
在介绍决策树的第一个示例中,您可能已经注意到很多 过拟合 (overfitting) 的情况。 这通常是决策树的问题,因为它们依赖于精确的阈值,这会在决策函数中引入“跳跃”。
例如,在下面显示的树中,CAPE 的差异为 0.0001 J kg^-1 可能导致龙卷风概率的差异为 55%。
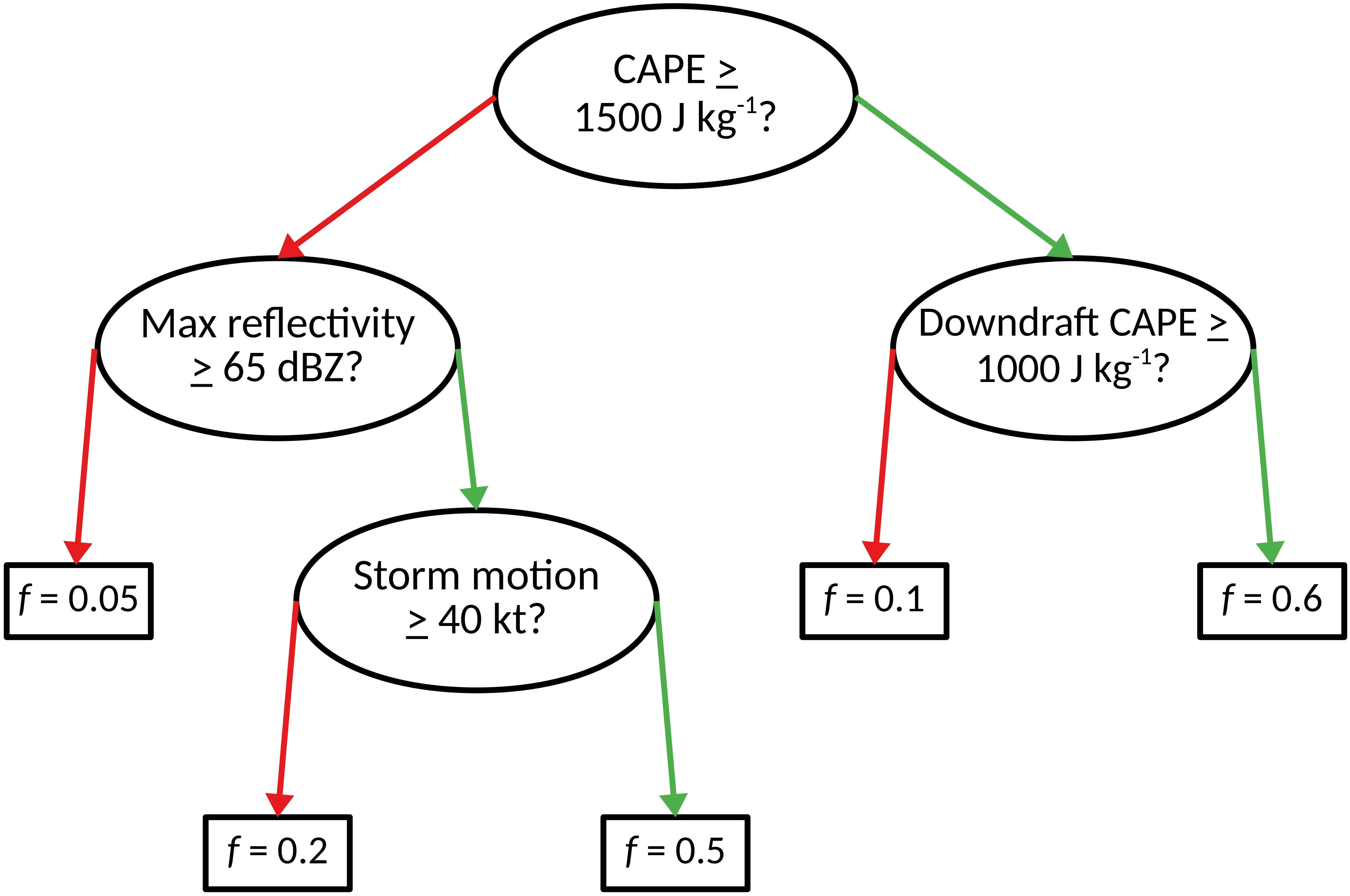
减轻这种过拟合的一种方法是:训练一堆决策树。
如果决策树足够多样化,则它们有望具有抵消的偏差(以不同方式过拟合)。
随机森林以两种方式确保多样性:
- Example-bagging
- Predictor-bagging (or “feature-bagging”)
example-bagging 通过使用训练数据的 自助副本 (bootstrapped replicate) 训练每棵树来完成。
对于带有 N 个示例的训练集,通过随机抽样替换 N 个示例来创建“自助复制”。 替换采样会导致重复。 平均而言,每个自助复制都仅包含 63.2% (1 - e^{-1}) 的唯一示例,其他 37.8% 是重复的。 这样可以确保使用不同的独特示例集对每棵树进行训练。
Predictor-bagging 通过在每个分支节点上循环随机的预测变量子集来完成。
换句话说,不要尝试所有预测变量找到最佳问题,而只尝试几个预测变量。 如果存在 M 个预测变量,则一般规则是在每个分支节点上尝试 \sqrt{M} 个预测变量。 在我们的示例中,有 41 个预测变量,因此每个分支节点将循环遍历 6 个随机选择的预测变量。
示例
下一个单元训练具有以下超参数的随机森林:
- 100棵树
- 每个叶节点尝试6个预测变量
- 分支节点上至少有500个样本
- 叶节点上至少有200个样本
计算预测变量个数
num_predictors = len(list(training_predictor_table))
max_predictors_per_split = int(np.round(
np.sqrt(num_predictors)
))
max_predictors_per_split
6
注:执行下面的代码忽略警告
import warnings
warnings.filterwarnings('ignore')
创建模型
setup_classification_forest 创建随机森林
def setup_classification_forest(
max_predictors_per_split: int,
num_trees: int=100,
min_examples_at_split: int=30,
min_examples_at_leaf: int=30
) -> sklearn.ensemble.RandomForestClassifier:
return sklearn.ensemble.RandomForestClassifier(
n_estimators=num_trees,
min_samples_split=min_examples_at_split,
min_samples_leaf=min_examples_at_leaf,
max_features=max_predictors_per_split,
bootstrap=True,
random_state=RANDOM_SEED,
verbose=2
)
根据示例条件创建随机森林模型对象
random_forest_model = setup_classification_forest(
max_predictors_per_split=max_predictors_per_split,
num_trees=100,
min_examples_at_split=500,
min_examples_at_leaf=200,
)
random_forest_model
RandomForestClassifier(max_features=6, min_samples_leaf=200,
min_samples_split=500, random_state=6695, verbose=2)
训练模型
train_classification_forest 用于训练随机森林模型
def train_classification_forest(
model: sklearn.ensemble.RandomForestClassifier,
training_predictor_table: pd.DataFrame,
training_target_table: pd.DataFrame,
) -> sklearn.ensemble.RandomForestClassifier:
model.fit(
X=training_predictor_table.values,
y=training_target_table[BINARIZED_TARGET_NAME].values
)
return model
训练
_ = train_classification_forest(
model=random_forest_model,
training_predictor_table=training_predictor_table,
training_target_table=training_target_table
)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
building tree 1 of 100
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.3s remaining: 0.0s
building tree 2 of 100
building tree 3 of 100
building tree 4 of 100
...
building tree 99 of 100
building tree 100 of 100
[Parallel(n_jobs=1)]: Done 100 out of 100 | elapsed: 35.8s finished
预测
输入样本的预测类别是森林中树木的投票,并由其概率估计值加权。 也就是说,预测类别是整个树上具有最高平均概率估计的类别。
training_probabilites = random_forest_model.predict_proba(
training_predictor_table.values
)[:, 1]
training_probabilites
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 100 out of 100 | elapsed: 0.9s finished
array([0.00736077, 0.06411623, 0.06525689, ..., 0.01160056, 0.00074797,
0.00106433])
training_event_frequency = np.mean(
training_target_table[BINARIZED_TARGET_NAME].values
)
training_event_frequency
0.10034434450161697
评估
评估训练集
eval_binary_classifn(
observed_labels=training_target_table[BINARIZED_TARGET_NAME].values,
forecast_probabilities=training_probabilities,
training_event_frequency=training_event_frequency,
dataset_name="training",
)
Training Max Peirce score (POD - POFD) = 0.781
Training AUC (area under ROC curve) = 0.955
Training Max CSI (critical success index) = 0.471
Training Brier score = 0.049
Training Brier skill score (improvement over climatology) = 0.459
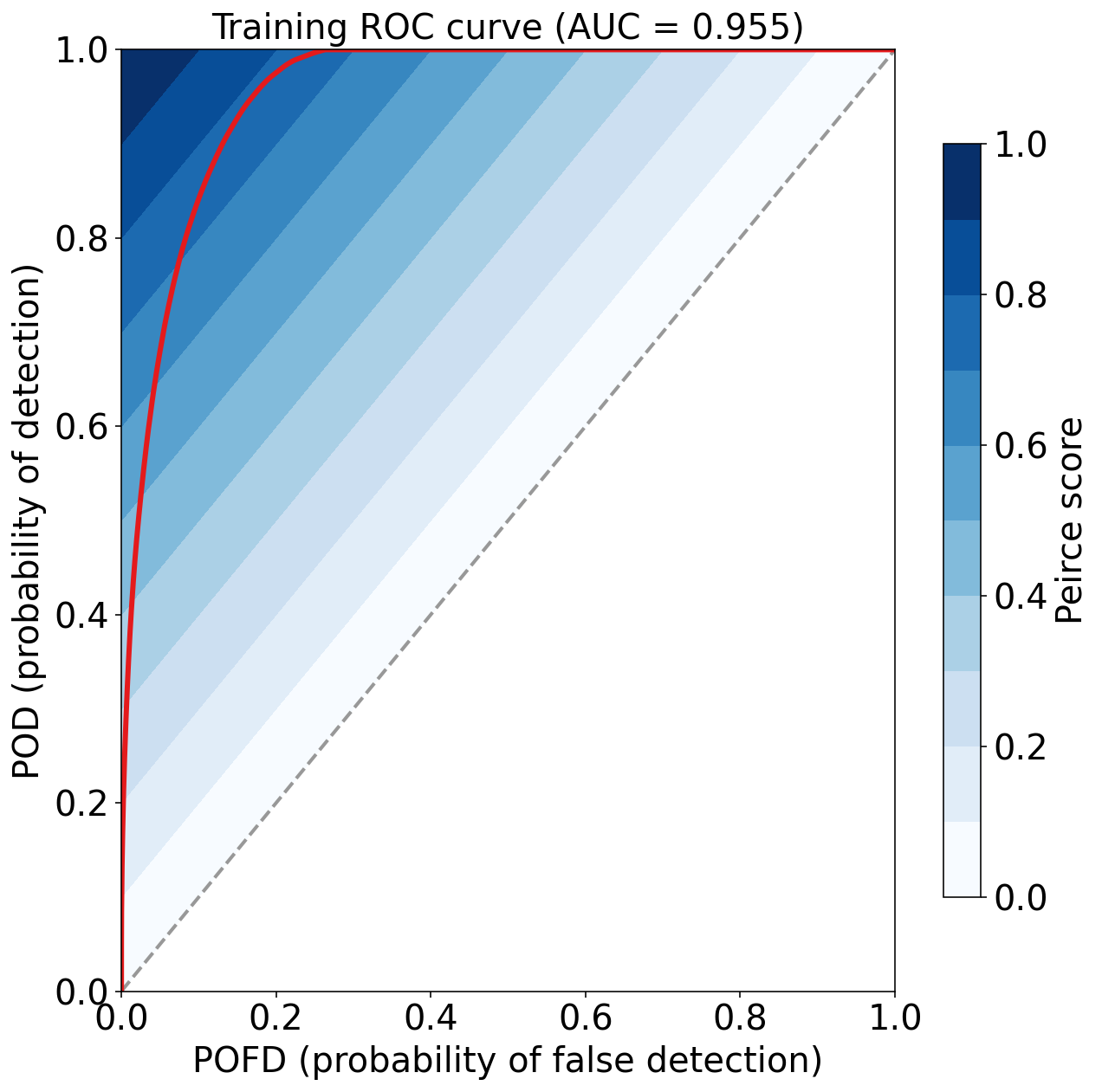
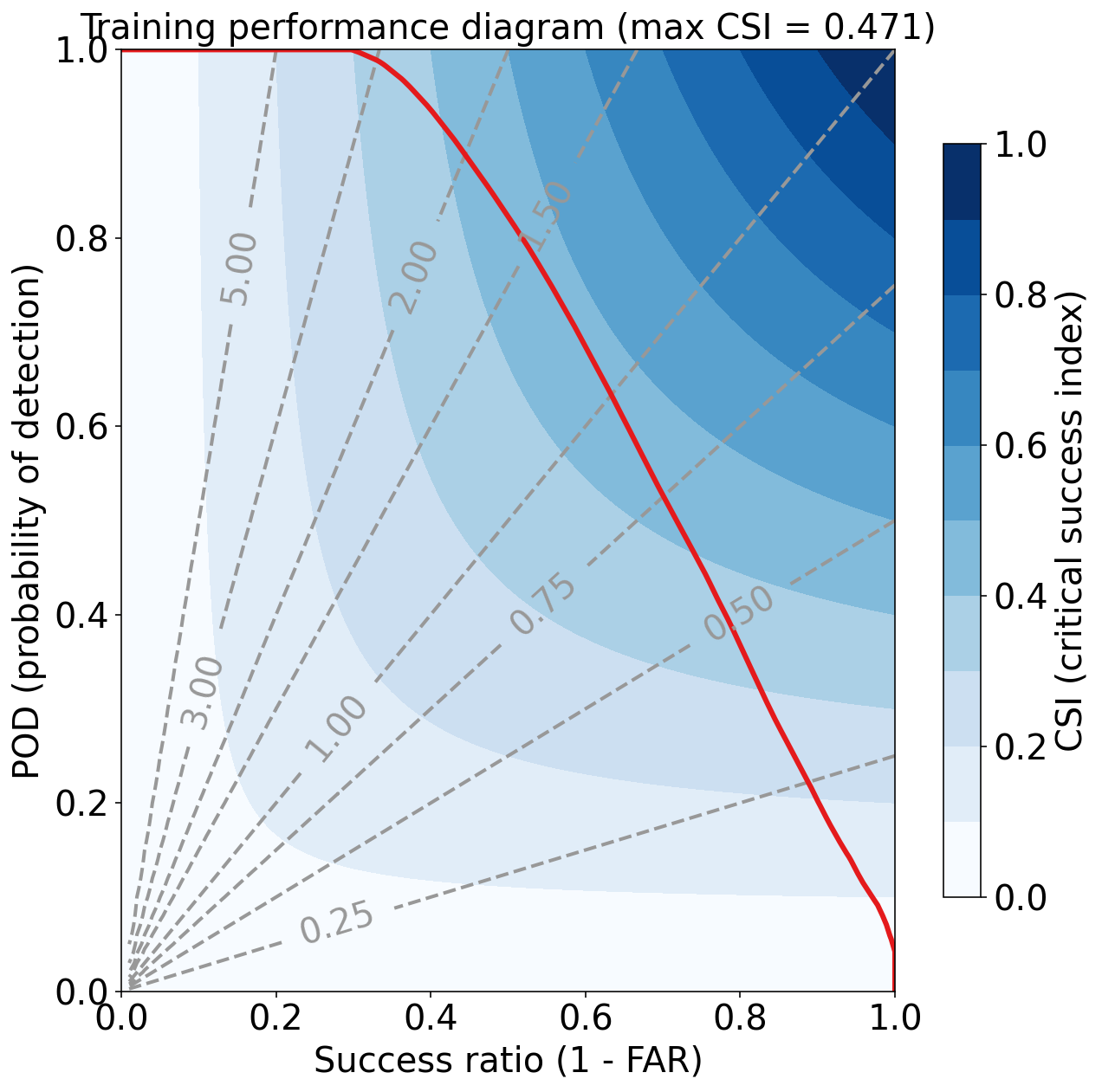
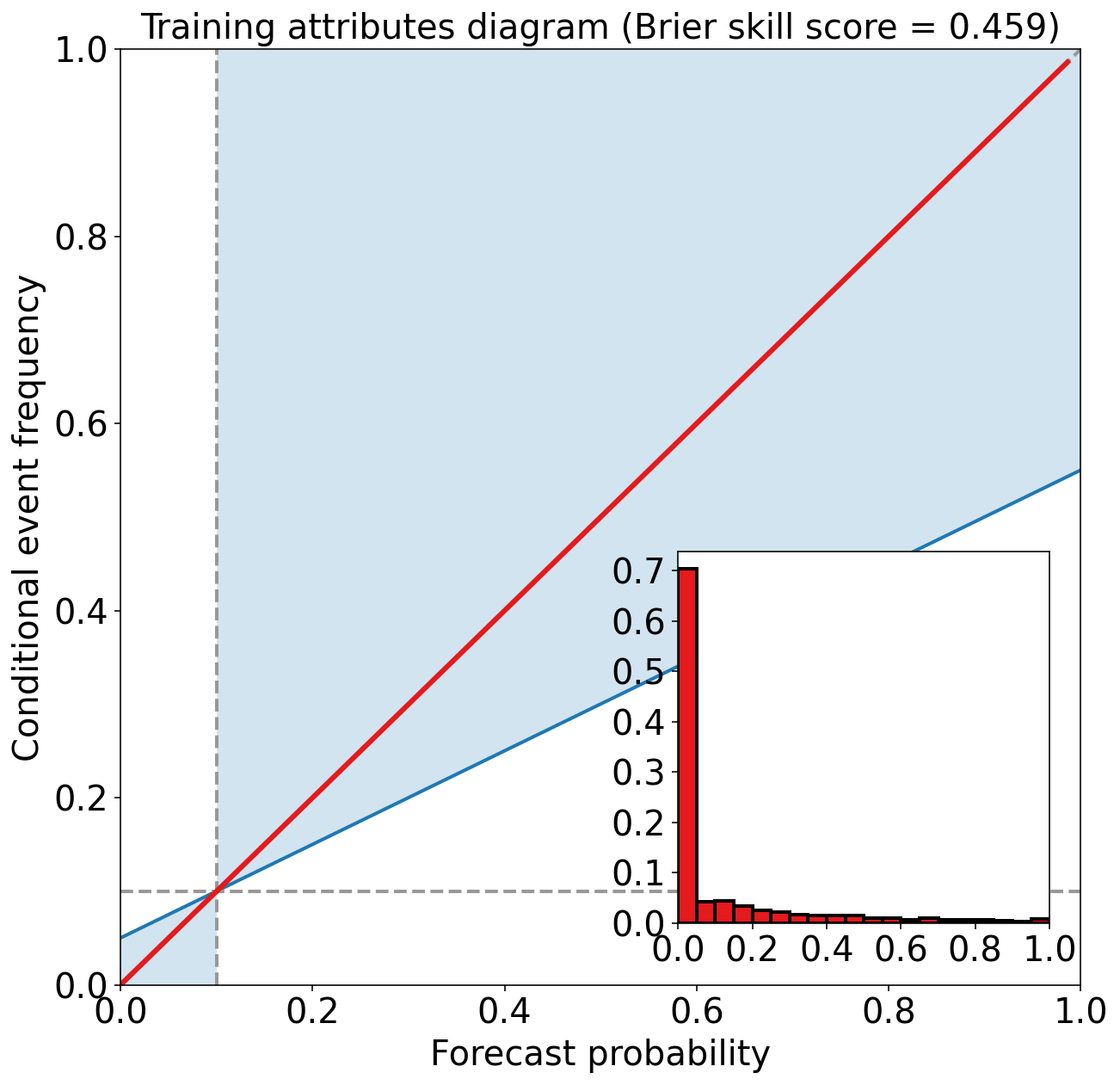
评估验证集
validation_probabilities = random_forest_model.predict_proba(
validation_predictor_table.values
)[:, 1]
validation_probabilities
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 100 out of 100 | elapsed: 0.2s finished
array([0.00122932, 0.01751874, 0.12011435, ..., 0.00554694, 0.00496335,
0.00237349])
eval_binary_classifn(
observed_labels=validation_target_table[BINARIZED_TARGET_NAME].values,
forecast_probabilities=validation_probabilities,
training_event_frequency=training_event_frequency,
dataset_name="validation",
)
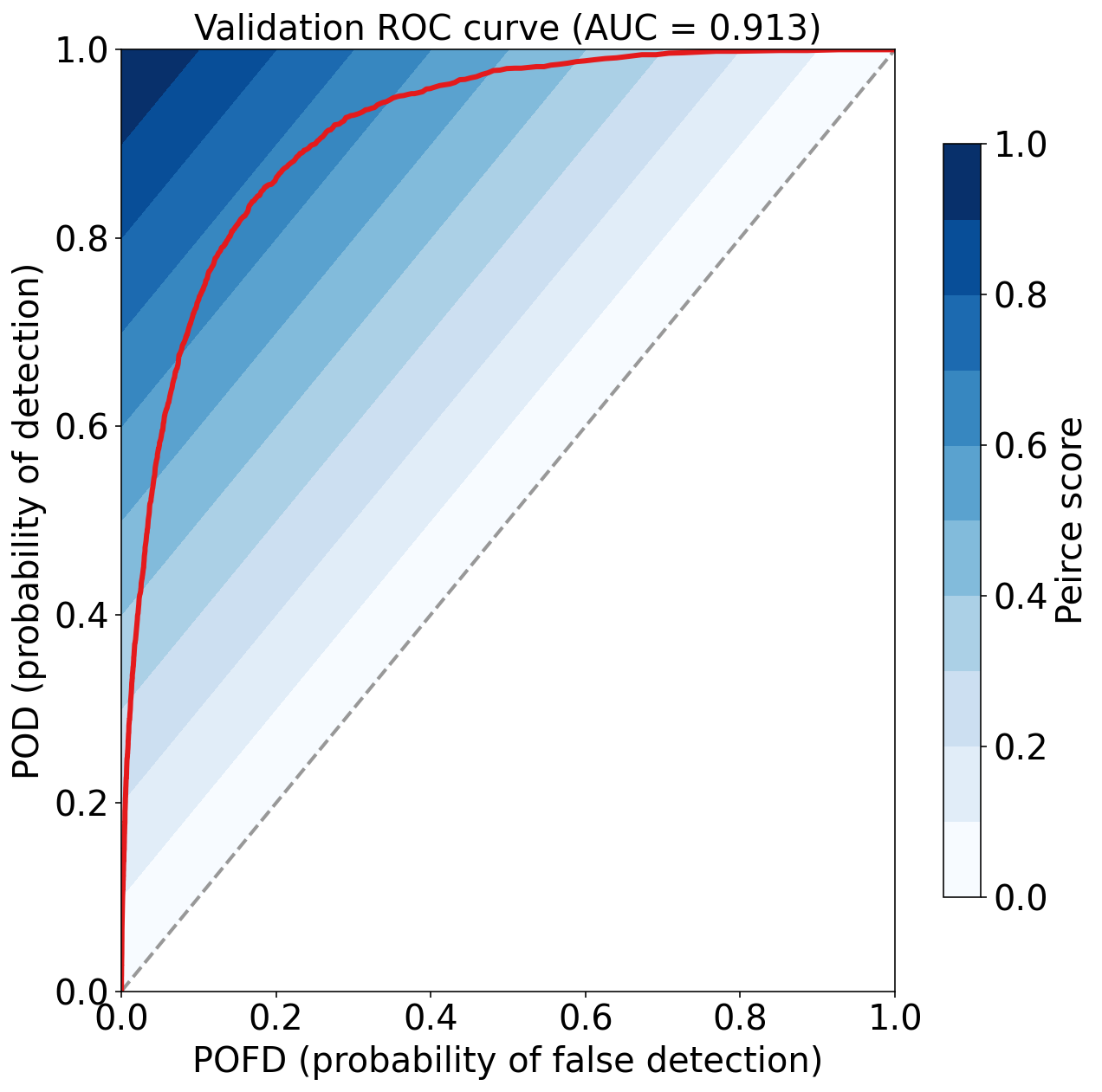
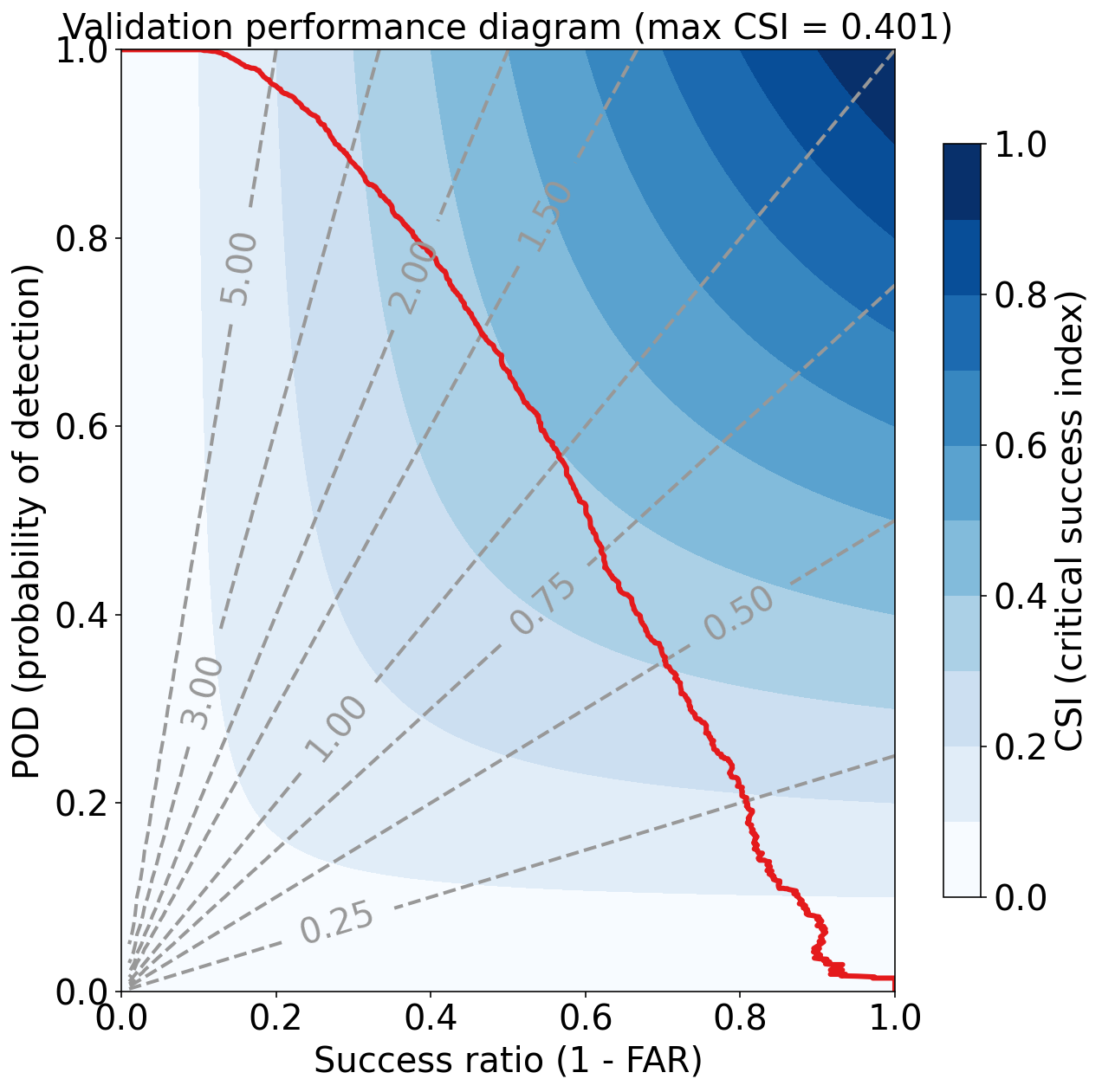
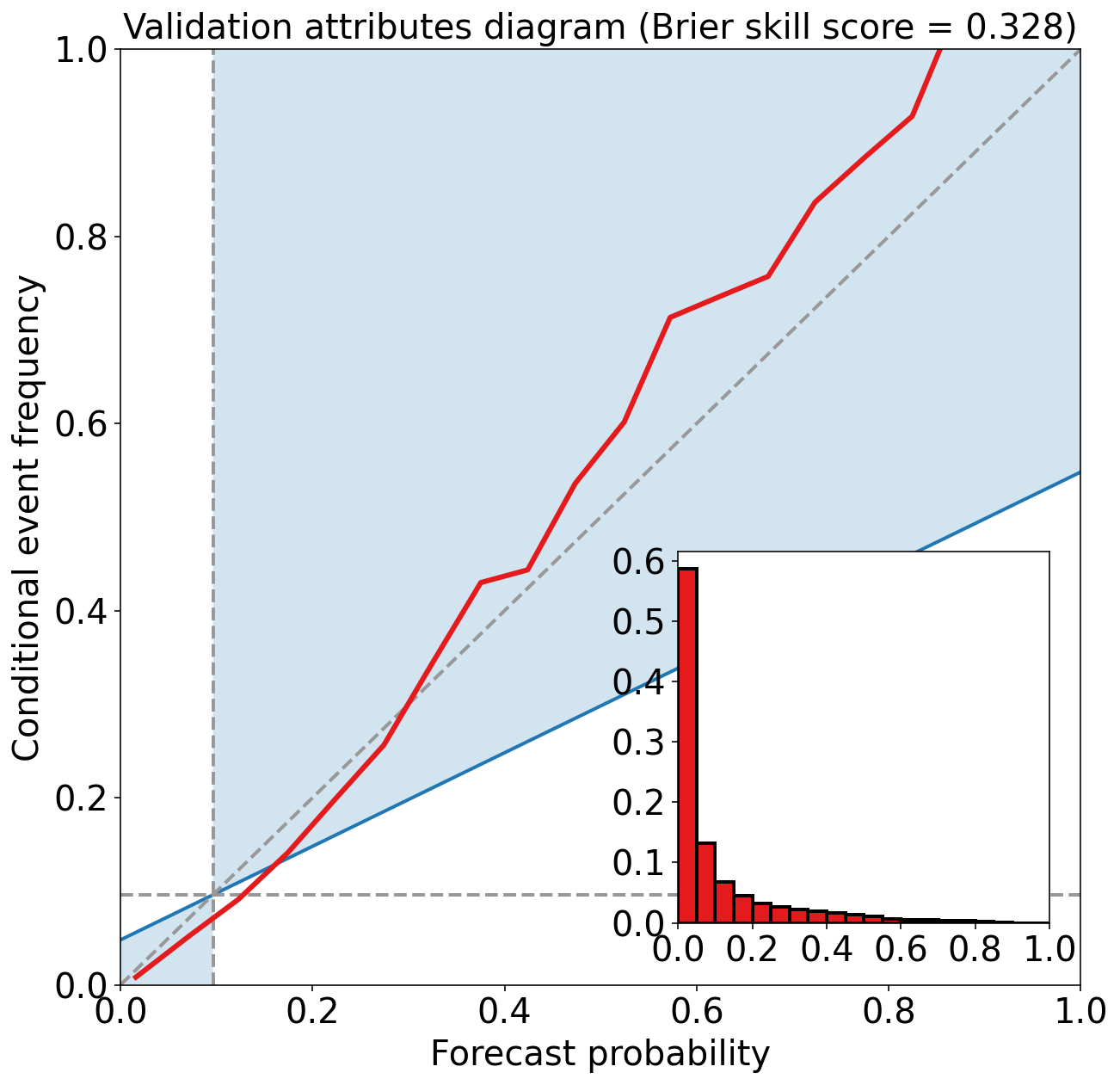
Validation Max Peirce score (POD - POFD) = 0.670
Validation AUC (area under ROC curve) = 0.913
Validation Max CSI (critical success index) = 0.401
Validation Brier score = 0.061
Validation Brier skill score (improvement over climatology) = 0.328
练习
训练具有不同超参数的随机森林。 探究在训练和验证数据集上的性能。
梯度提升决策树
Gradient-boosted Trees
Gradient boosting 是集成决策树的另一种方法。
在随机森林中,决策树彼此独立训练。
在 gradient-boosted 集合(或 “gradient-boosted forest”)中,训练第 k 棵树以适合前 k - 1 棵树的残差。 第 i 个样本的残差 (“residual”) 是
\begin{equation*} y_i - p_i \end{equation*}
Gradient-boosted 森林仍然可以使用 example-bagging 和 preidictor-bagging。 但是,在大多数库中,默认设置都不使用 “example-bagging” 或 “predictor-bagging”,即使用所有样本训练每棵树,并在每个分支节点尝试所有预测变量。
在随机森林中,可以并行训练树木(每棵树木彼此独立),这使随机森林更快。 在 gradient-boosted 集合中,必须顺序训练树木,这会使训练决策树变慢。 但是,在实践中,gradient-boosting 的性能通常会胜过随机森林。 在最近的太阳能预测竞赛中,排名前三的团队都使用了 gradient-boosted 森林 (McGovern et al. 2015)。
示例
下一个单元格使用以下超参数训练 gradient-boosted 集合:
- 不使用 example-bagging
- 不使用 predictor-bagging
- 100 棵树
- 分支节点上至少有 500 个示例
- 叶节点上至少有 200 个示例
创建模型
setup_classification_gbt 用于创建 gradient-boosted trees 模型
def setup_classification_gbt(
max_predictors_per_split: int,
num_trees: int=100,
learning_rate: float=0.1,
min_examples_at_split: int=30,
min_examples_at_leaf: int=30,
) -> sklearn.ensemble.GradientBoostingClassifier:
return sklearn.ensemble.GradientBoostingClassifier(
loss='exponential',
learning_rate=learning_rate,
n_estimators=num_trees,
min_samples_split=min_examples_at_split,
min_samples_leaf=min_examples_at_leaf,
max_features=max_predictors_per_split,
random_state=RANDOM_SEED,
verbose=2
)
根据示例条件创建 gradient-boosted trees 模型对象
num_predictors = len(list(training_predictor_table))
num_predictors
41
gbt_model = setup_classification_gbt(
max_predictors_per_split=num_predictors,
num_trees=100,
min_examples_at_split=500,
min_examples_at_leaf=200,
)
gbt_model
GradientBoostingClassifier(loss='exponential', max_features=41,
min_samples_leaf=200, min_samples_split=500,
random_state=6695, verbose=2)
训练模型
train_classification_gbt 用于训练 gradient-boosted trees 模型
def train_classification_gbt(
model: sklearn.ensemble.GradientBoostingClassifier,
training_predictor_table: pd.DataFrame,
training_target_table: pd.DataFrame
):
model.fit(
X=training_predictor_table.values,
y=training_target_table[BINARIZED_TARGET_NAME].values
)
return model
使用训练集训练模型
_ = train_classification_gbt(
model=gbt_model,
training_predictor_table=training_predictor_table,
training_target_table=training_target_table,
)
Iter Train Loss Remaining Time
1 0.5767 1.93m
2 0.5554 1.92m
3 0.5369 1.91m
4 0.5211 1.90m
...
98 0.3674 2.38s
99 0.3672 1.19s
100 0.3669 0.00s
预测
training_probabilities = gbt_model.predict_proba(
training_predictor_table.values
)[:, 1]
training_probabilities
array([0.00523596, 0.02731729, 0.03677319, ..., 0.01886626, 0.00074368,
0.00099775])
评估
评估训练集
eval_binary_classifn(
observed_labels=training_target_table[BINARIZED_TARGET_NAME].values,
forecast_probabilities=training_probabilities,
training_event_frequency=training_event_frequency,
dataset_name="training",
)
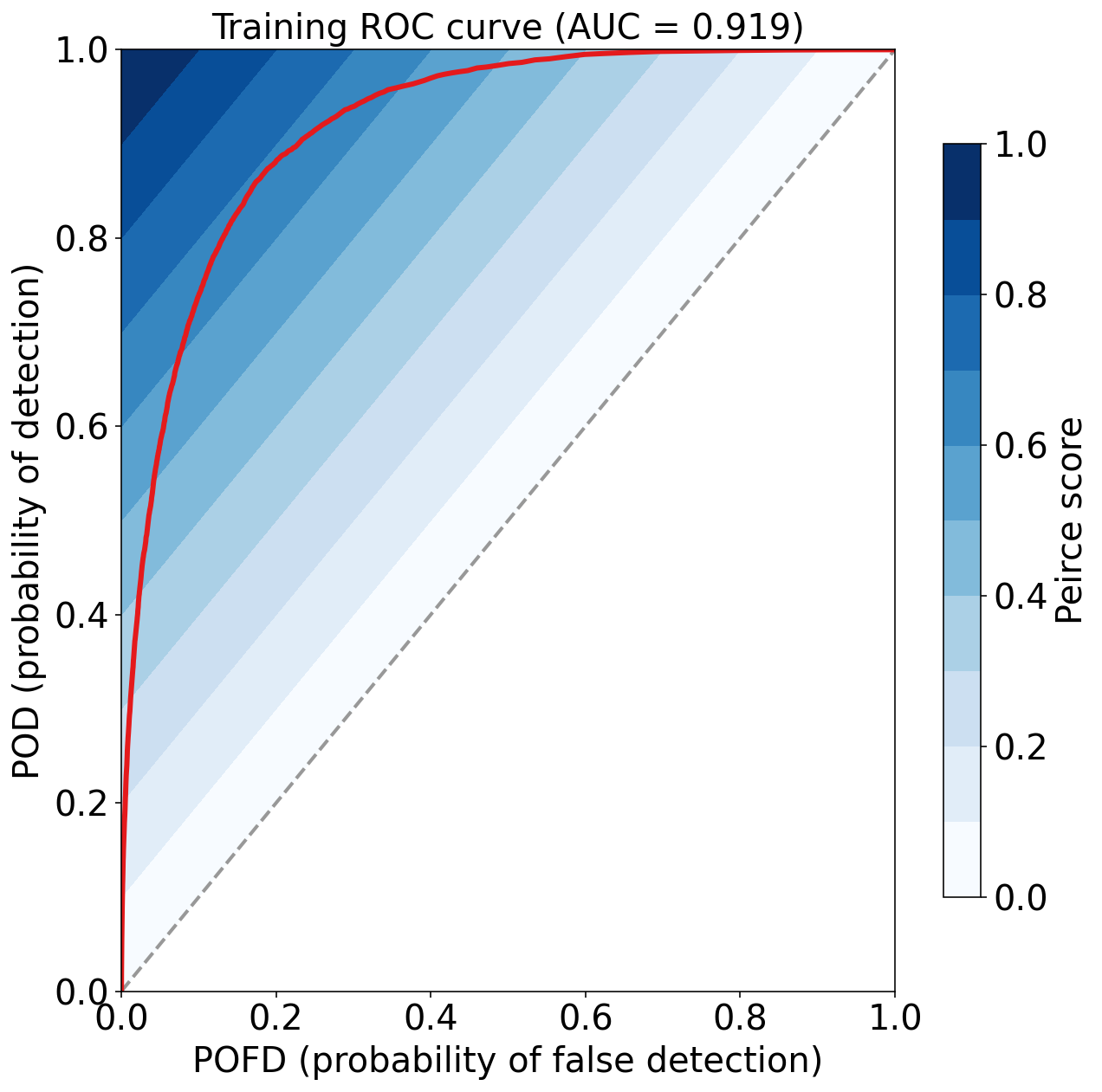
Training Max Peirce score (POD - POFD) = 0.686
Training AUC (area under ROC curve) = 0.919
Training Max CSI (critical success index) = 0.407
Training Brier score = 0.058
Training Brier skill score (improvement over climatology) = 0.360
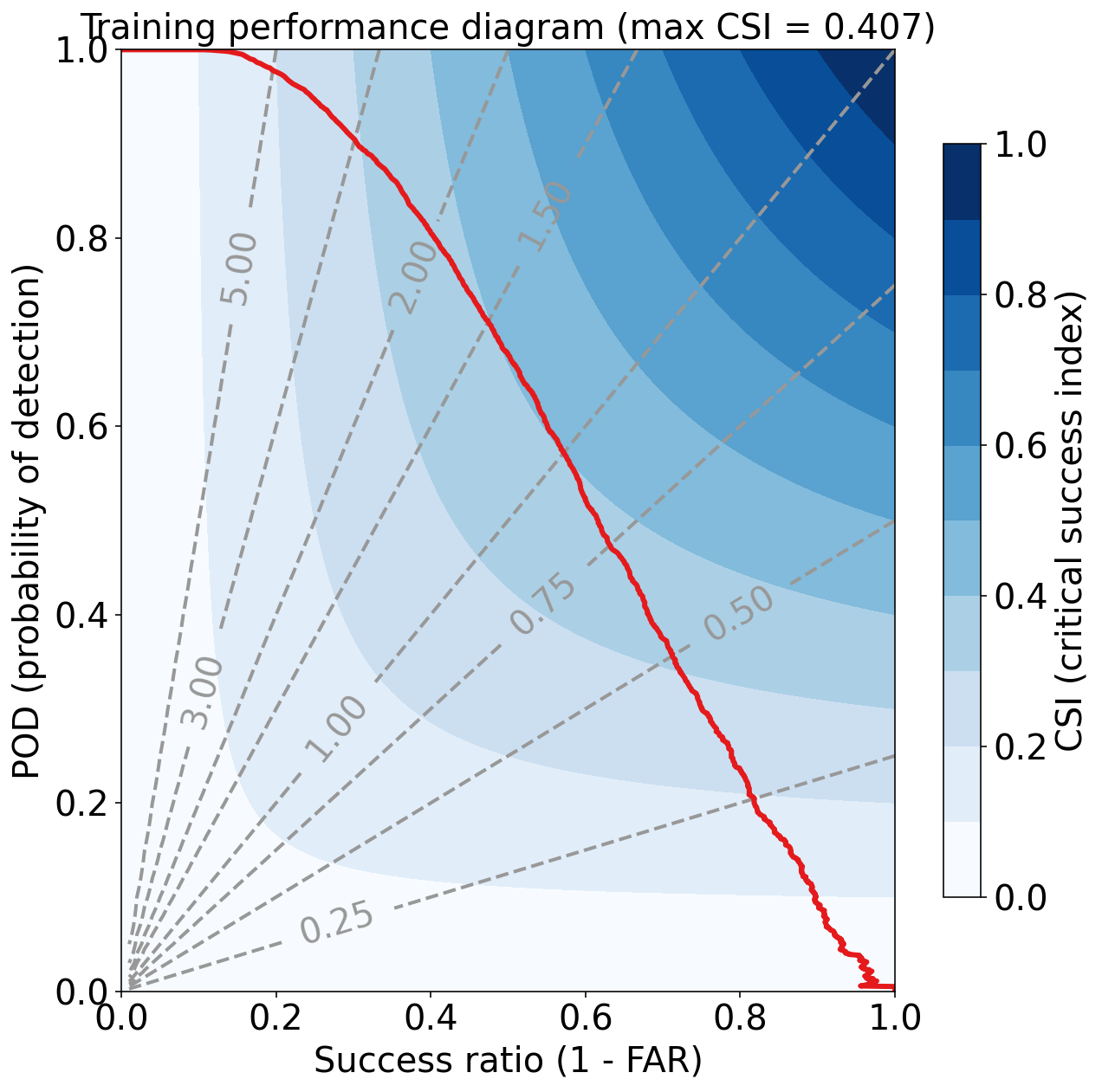
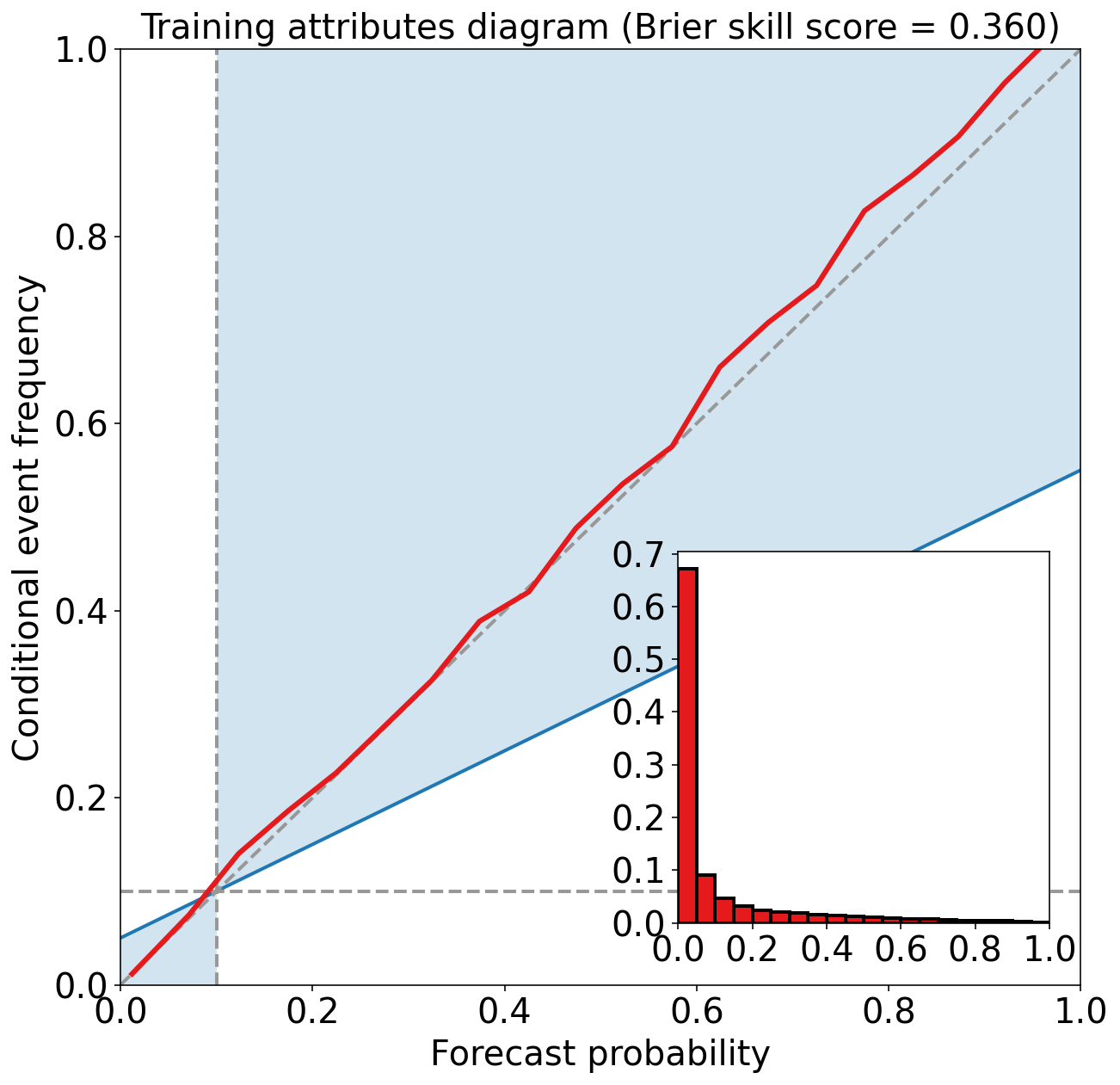
评估验证集
validation_probabilities = gbt_model.predict_proba(
validation_predictor_table.values
)[:, 1]
validation_probabilities
array([0.00085006, 0.00211077, 0.00415696, ..., 0.00075876, 0.0002048 ,
0.00062204])
eval_binary_classifn(
observed_labels=validation_target_table[BINARIZED_TARGET_NAME].values,
forecast_probabilities=validation_probabilities,
training_event_frequency=training_event_frequency,
dataset_name="validation",
)
Validation Max Peirce score (POD - POFD) = 0.675
Validation AUC (area under ROC curve) = 0.916
Validation Max CSI (critical success index) = 0.404
Validation Brier score = 0.059
Validation Brier skill score (improvement over climatology) = 0.344
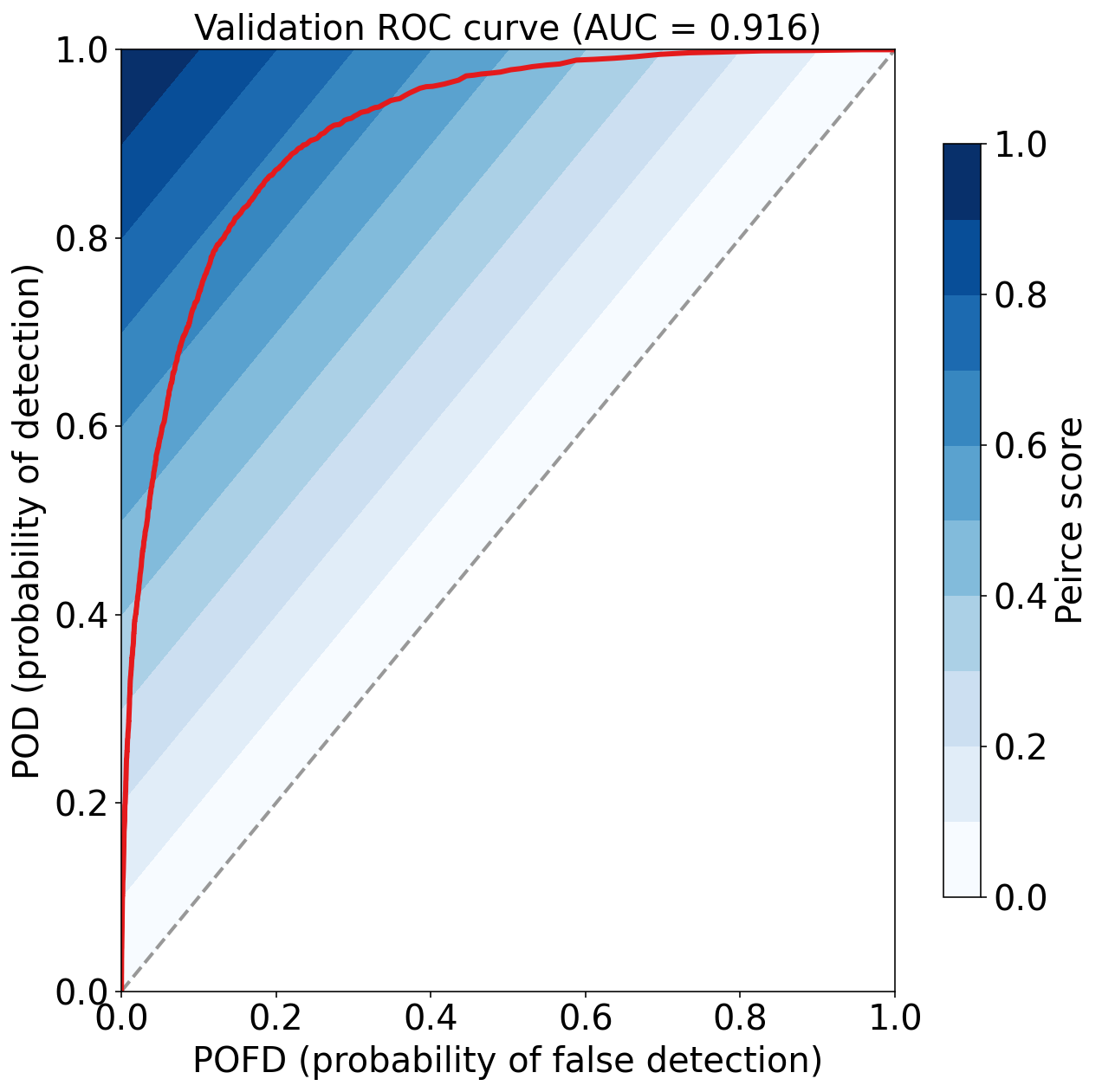

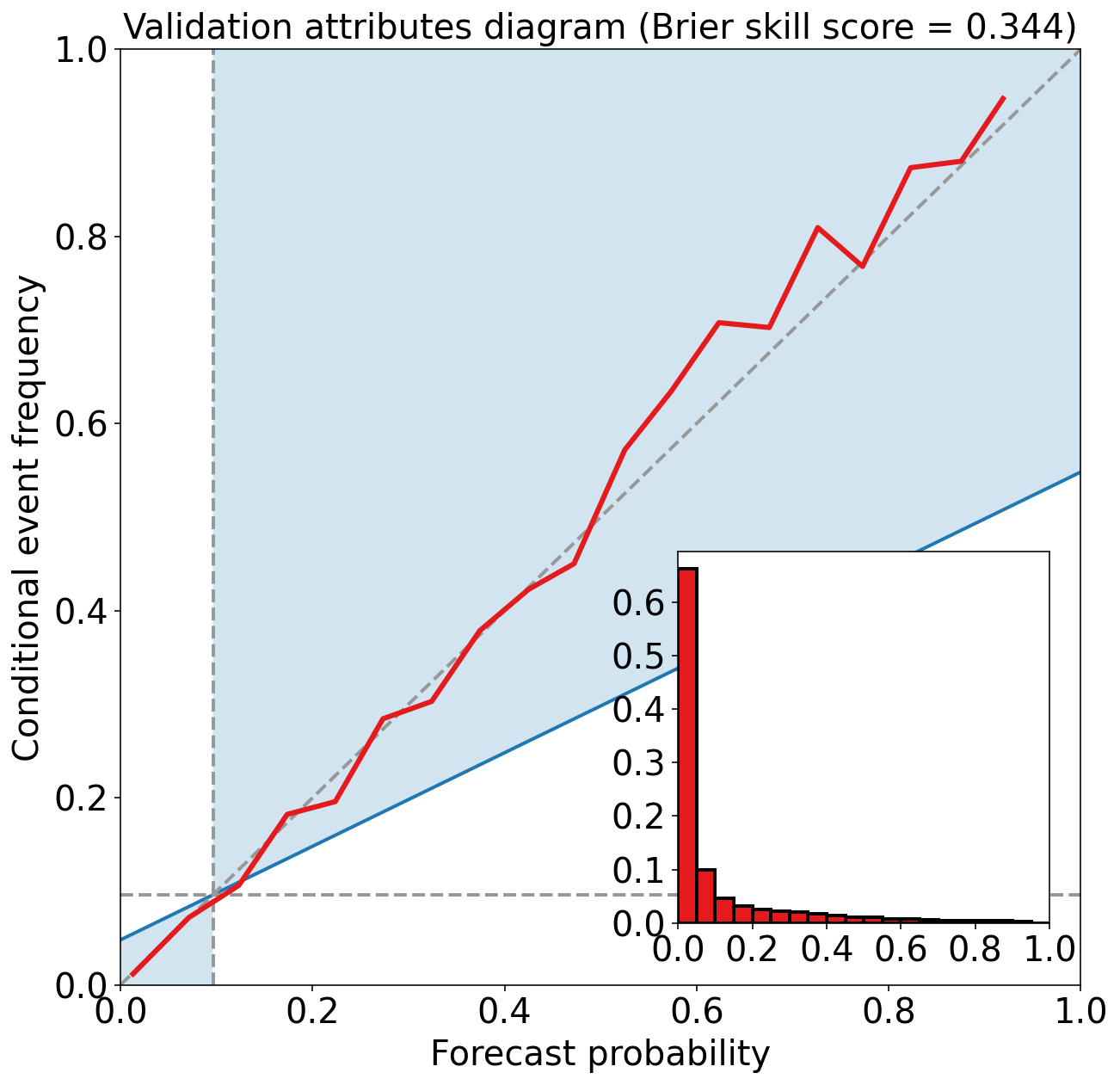
练习
使用不同的超参数训练 gradient-boosted 集合。 探究在训练数据和验证数据上的性能。
译者注
本文是《预测雷暴旋转的基础机器学习》系列的最后一篇文章。
参考
https://github.com/djgagne/ams-ml-python-course
AMS 机器学习课程
数据预处理:
《数据分析与预处理》
实际数据处理:
线性回归:
逻辑回归:
决策树:
