AI4ESS 2020: 建立坚实的基础 - 定义机器学习问题和预处理
本文翻译自 AI4ESS 2020 课程,并有部分修改
Artificial Intelligence for Earth System Science (AI4ESS) Summer School
Building a Strong Foundation: Defining ML Problems and Preprocessing
David John Gagne - NCAR
介绍
动机

过去三年来,人们对大气科学中的人工智能和机器学习的兴趣激增。
大部分的注意力都集中在算法上,如深度学习,随机森林,或者其他更大的方法。
但在实践中只是选择正确的机器学习算法不足以创建成功的人工智能/机器学习系统,不足以有效提供良好的决策以及所有我们正在寻找认为 AI 应该为我们完成的东西。
每个机器学习项目的 80% 时间都花在以下两个问题:
- 定义机器学习问题,比如我们究竟是怎么做机器学习
- 对数据进行预处理
因此,我们如何从不适合进行机器学习的原始形式中获取数据。 一旦你完成这一步,训练部分会进行得相对较快, 但到达这一步可能是相当艰难的旅程
本讲座将讨论训练任何机器学习模型之前必须做出的许多重要选择。
数据科学术语
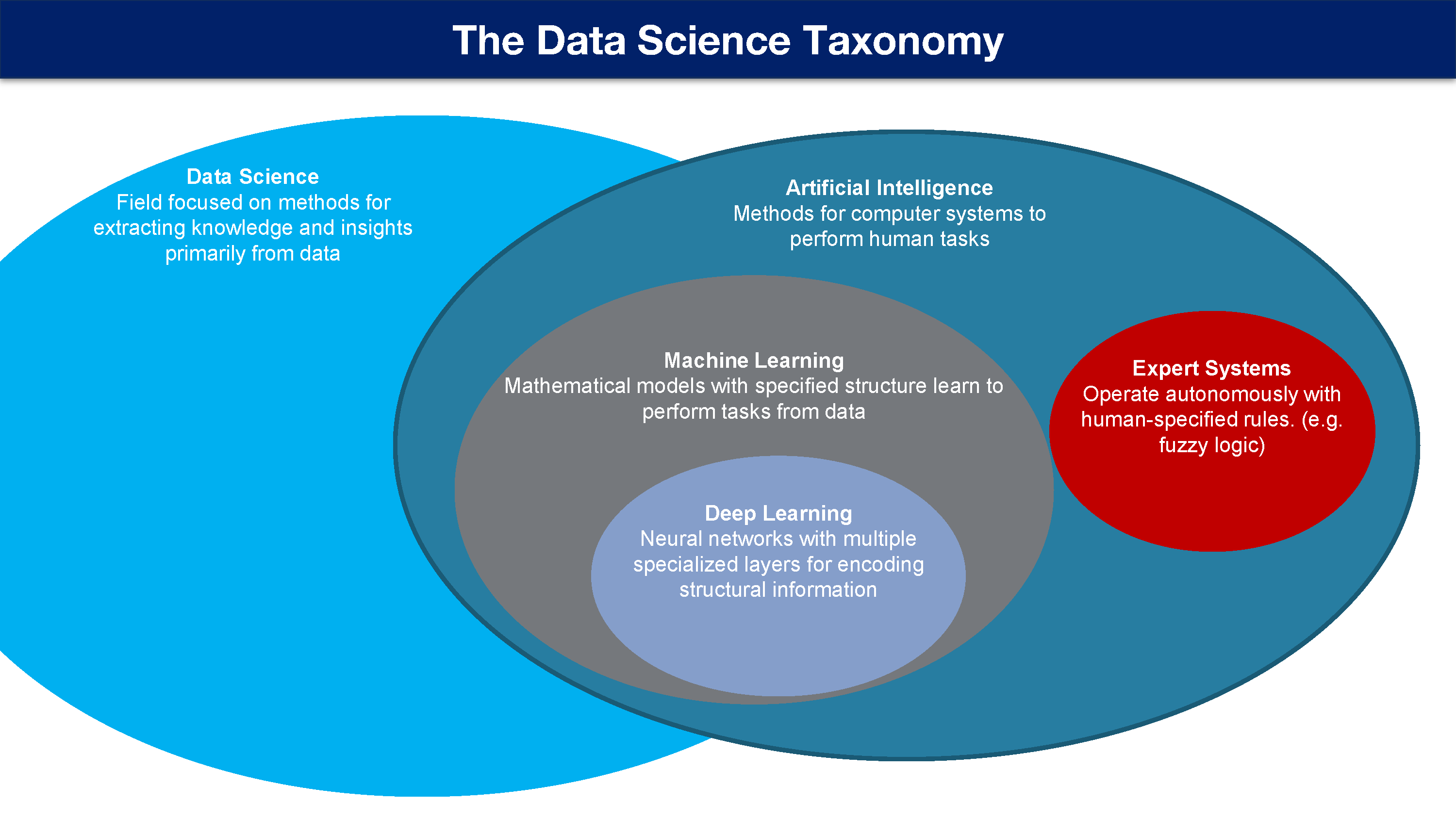
数据科学
专注从数据中提取知识和见解的方法。
包含人工智能方法。但也有一大堆其他数据科学工具和技术,不使用 AI 系统,用于处理非常大的数据,进行分析,并获取关于数据的见解。
*人工智能
让计算机系统从事人类任务的方法。
所以这是一个包罗万象的术语, 有很多不同的方式来定义一个 AI 系统。 通常不只是像机器学习模型的单个组件,而是包含所有计算机需要与之交互的一切,包括任何与外部交互的接口。
专家系统
使用人类指定的规则自主操作。
例如在大气科学中,模糊逻辑(fuzzy logic)是一种专家系统方法,它已经获得了相当的成效,因为现在仍然在一定程度上继续使用。
机器学习
从数据学习具有指定结构的数学模型执行任务。
我们发现,专家被证明是或并不总是能描述他们如何做决定,有很多边缘情况出现。
因此,构建 AI 系统的一个更有效的方法就是给它很多任务示例和结果,然后根据该数据将数学模型或机器学习模型拟合到某种指定的结构(如神经网络或决策树)中。
深度学习
具有多个专用层的神经网络,用于编码结构信息。
结构信息可以是空间数据,如图像或时间序列,数字时间序列或文本块或图像和时间的某种组合,以及各种不同的结构化或非结构化数据集。
深度学习模型特别强大的,因为他们可以做很多预处理本身,但不是所有的预处理任务都能完成,需要额外考虑这一点。
机器学习流程
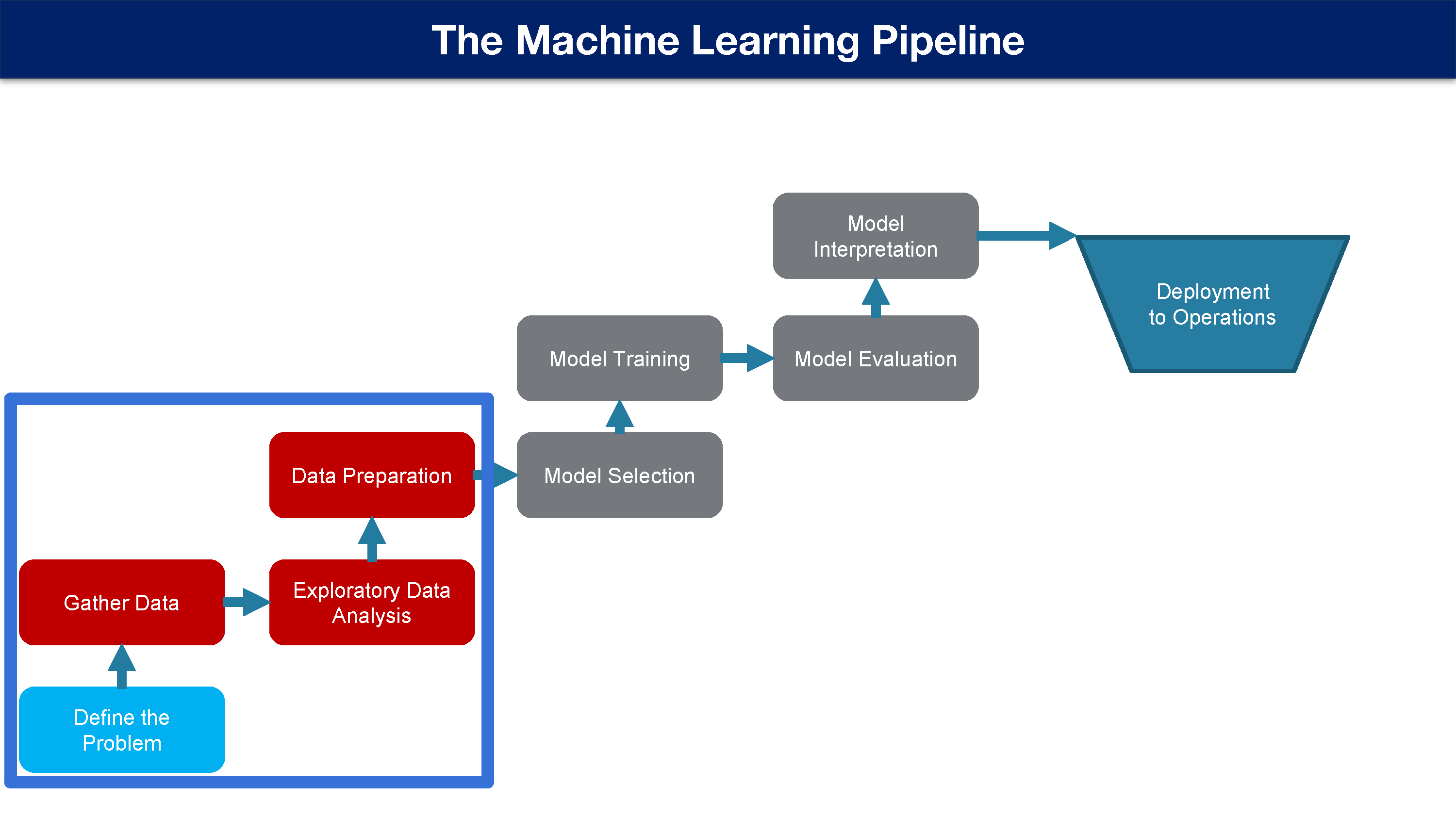
机器学习任务被认为不只是单一步骤,往往是一个每个系统都必须遵循的大管道。 对于本将所,我们将专注于管道的第一部分,即定义问题,收集数据,探索分析数据和准备数据。
定义问题
第一个问题是,对于任何给定的科学挑战,是否都应该尝试从问题中选择机器学习。 通常有很多基于机器学习的方法,可以是基于模拟的,基于启发式的或基于原始方程的,基于物理的系统,或者是所有这些系统的混合体。
所以您可能想知道我听说过很多关于机器学习在什么地方可能会很好地工作,在哪些地方可能工作得不好。
是否应该选择机器学习

机器学习何时效果好
中度覆盖可能的输入空间
请注意,这并不意味着需要大量数据,因为对于让机器学习模型很好地工作来说,数据量不是必须的。 您可能拥有 TB 级别的数据,描述了某个雷暴的五秒种时段,但这些数据可能无法让您很好地预测龙卷风,因为那五秒钟与龙卷风发生的时间无关。 因此数据大小不如数据的覆盖范围重要。
输入和输出之间至少存在某种合理的联系
输入和输出之间也应该至少存在一些合理的联系。 您可以使机器学习模型适合任何输入和输出集,但是除非一定存在某种理想的物理连接,否则不一定会得到理想的结果。 可以通过某种方式进行合理性测试。
非机器学习方法太昂贵或容易出错
当非机器学习方法过于昂贵或容易出错时,如果您需要进行仿真,并且您找到合适的人来加快速度,或者当前无法通过正在执行的任何系统来建模,或者需要大量的人工才能完成相同的任务,如果您手动执行,则将花费大量时间,那么最后机器学习通常会很好地工作。
也许机器学习是我们可以通过计算来加快获得过程或获得更准确结果的一种方式。 还有一个庞大的搜索基础,您正在着手进行机器学习,也可以帮助您进行导航并减少操作。
机器学习何时表现不好
可能的输入数据覆盖范围有限
如果机器学习效果不佳,可能是输入的数据覆盖范围有限。 因此,如果数据样本很小或仅覆盖一小部分空间,则机器学习是一个很好的内插器,它将在该部分空间中表现出色。 但必然会推断其他情况,因此无法获取更多的数据可能是一个问题
输入和输出之间的联系很少
在输入和输出之间还存在一点联系,您可能仍然可以拟合模型,但是运行效果很差,
当前解决问题的方法已经有效
如果当前的方法已经可以有效地解决问题,那么需要进行权衡使用机器学习方法值不值得。 您将付出巨大的努力,但如果运作良好,它可能会提供有限的优势,但是对基础设施要求可能让有限的优势显得不值得。
因此,如果您选择沿着这条路走,那么在机器学习项目开始时就应该考虑一下。
定义问题

下一步是,如果您认为机器学习是解决问题的好选择,那么您实际上应该首先定义问题.
绝大部分机器学习项目中最重要的部分就是正确定义问题。
这样,如果您可以很好地定义您的目标,那么您就可以摆脱一切。
需要问的问题:
项目的最终目标是什么?
以某种方式作为指导原则,确保机器学习实际上在实现那些最终的科学目标,并且确保不会来回移动目标杆以使机器学习模型的功能适应更多的需求。
实现目标所需的具体输入和输出是什么?
这并不是说您实际上需要哪些数据来解决什么问题,通常不一定有什么可用的
哪些数据可用于输入和输出?数据限制是什么?
第三个问题是,哪些数据实际可用于输入和输出,有哪些数据限制或某些输入或输出测量不良,或者其中存在偏差,或者可能出现其他需要担心的问题
问题的约束是什么(时间,空间,延迟,物理)?
第四个问题是,在时空延迟方面的问题约束是什么?
您是否要预测未来 100 年的龙卷风,还是您要预测太平洋上的飓风,您是否需要五分钟或一周内的预测。
所有这些事情对于弄清计算时间和预算的多少以及对于给定问题可能适用或不可行的方法而言非常重要。
当前如何解决问题,这些方法的局限性是什么?
最后一个问题是当前如何解决该问题以及这些方法的局限性。
因此您应该有一个良好的基准与之进行比较,并确保您的机器学习在最新技术基础上正在不断进步。
知道最新技术的局限性将有助于指导您选择使用哪种机器学习模型。
示例
伴随这些问题,还有以下不同类型的问题类别相关的其他问题,这些都是大气科学或地球系统科学中常见的一些示例。
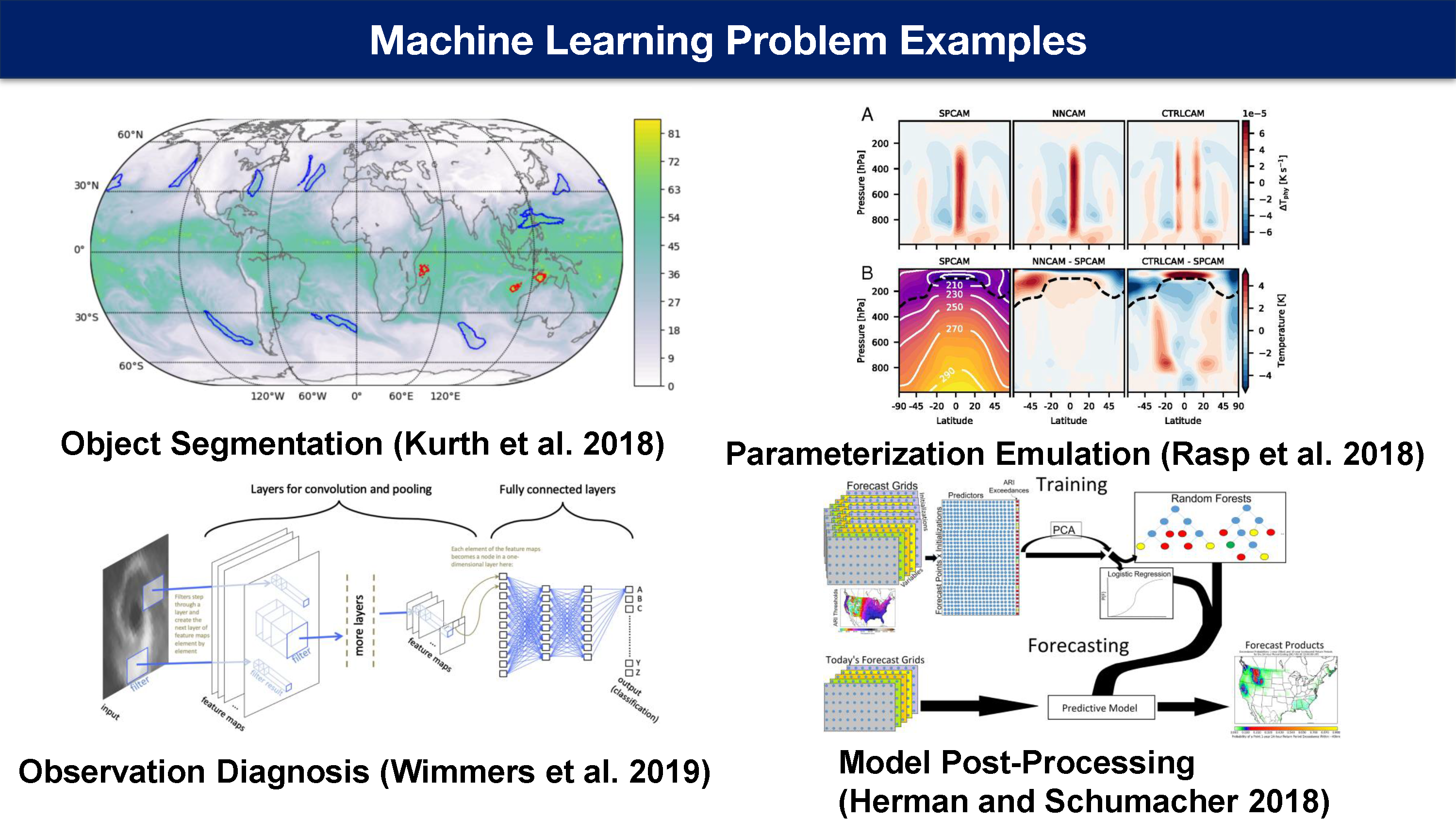
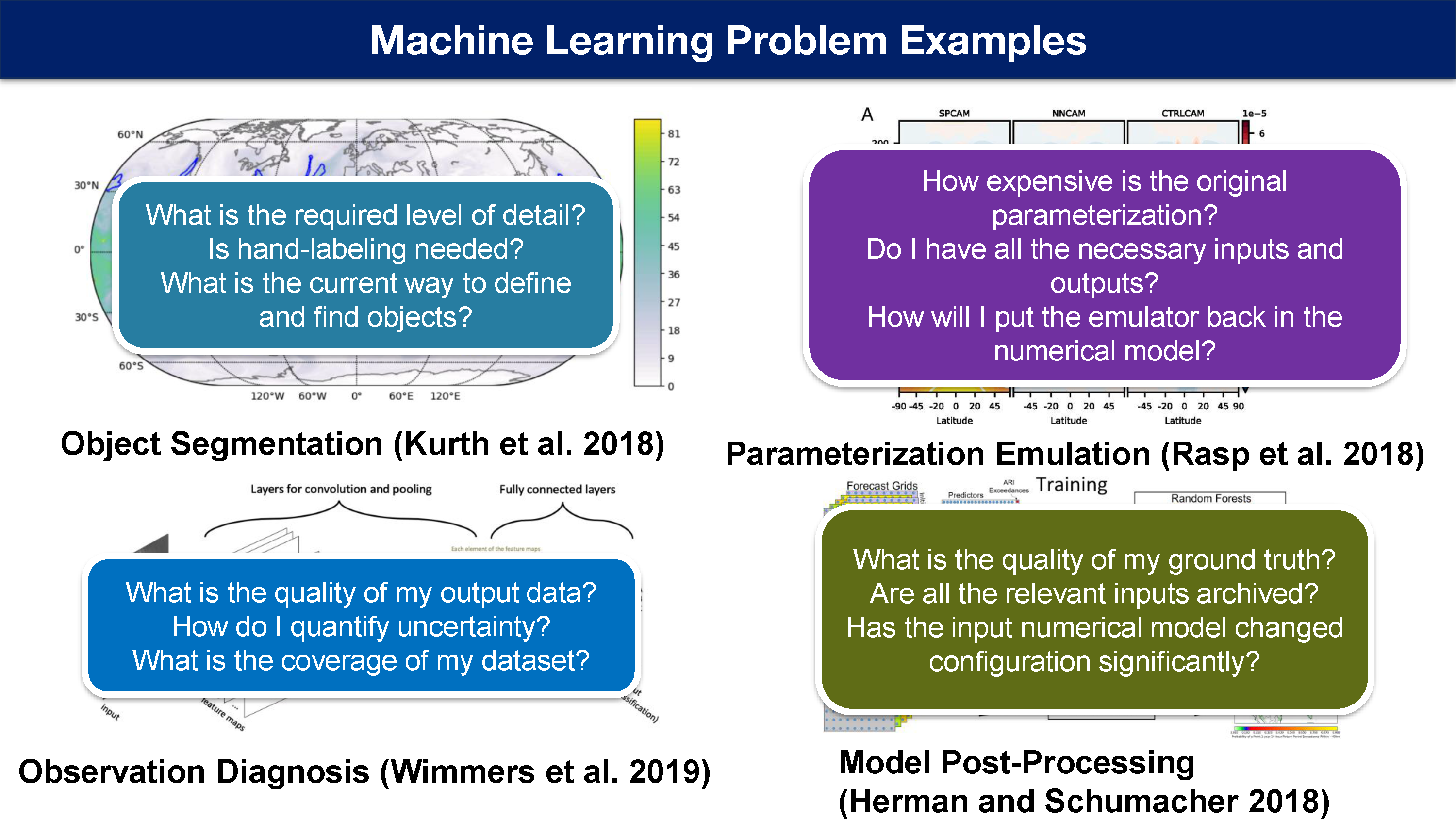
对象分割
第一个是对象分割问题。
当您想在天气或气候模型输出的大型数据集中识别锋面,大气河流或飓风时, 您可能首先感兴趣询问需要什么级别的详细信息:
需要风暴的确切轮廓?还是知道边界框就足够? 还是我只需要知道这次地球上某处有飓风。
需要手动贴标签吗?您实际上是否需要有人在每个飓风周围绘制轮廓? 还是有另一种方法可以获取此类标签来训练模型? 还是可以使用某种启发式方法,而根本不需要做任何标记?
当前定义和查找对象的方法效果如何?有什么方法可以评估该结果并将其与您的方法进行比较,或者如果在计算上它是一种昂贵的方法,甚至可以将其用作模拟该方法。
Thorsten Kurth, Sean Treichler, Joshua Romero, Mayur Mudigonda, Nathan Luehr, Everett Phillips, Ankur Mahesh, Michael Matheson, Jack Deslippe, Massimiliano Fatica, Prabhat, and Michael Houston. 2018.
Exascale deep learning for climate analytics.
In Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC ’18). IEEE Press, Article 51, 1–12.
参数模拟
参数化仿真在数值天气或气候模型中是具有非常昂贵的子网格过程的近似计算
我们希望训练一台机器学习模型对其进行仿真,以期使机器学习模型的运行速度比昂贵的过程快得多,然后将该模拟器放入我们基于物理的模型中。
因此,我们首先需要担心的是原始参数化的昂贵程度,例如参数化计算会导致计算呈数量级变慢,还是只需要两行已经优化和运行超快的 Fortran 代码,而在机器学习模型中逼近它的速度可能会比原始模型慢。
所以弄清楚,如果您只关心计算速度,那么您的收益是多少?
是否有所有必要的输入和输出,所以如果您依赖于如何获取数据,这可能是一个问题。 如果您不是自己运行模型,而其他人正在为您运行模型,则可能会出现问题。 您需要确保它们提供所有正确的输入和输出以正确模拟它。
最后如何将仿真器放回数值模型中,这是一项极具挑战性的任务。 但我们应该在后续的讲座中介绍更多有关这些任务的信息。
Deep learning to represent subgrid processes in climate models
Stephan Rasp, Michael S. Pritchard, Pierre Gentine
Proceedings of the National Academy of Sciences Sep 2018, 115 (39) 9684-9689
观测诊断
另一项任务是我们称之为观测诊断。比如观察热带气旋,然后试图从数据中估算当前热带气旋的强度。
但是还有很多其他问题,例如有一堆卫星图像,雷达或地面数据,您想要提取其中的一些属性进行分析。 例如飓风是否加强或减弱,五分钟之内是否就会有闪电等。
机器学习往往擅长于这类挑战。
但是在构建这些系统时,首先应该考虑的是因为收集过程中存在一些问题,输出数据或标签的质量仅在特定区域或有限的时间记录中收集。
如何量化不确定性,例如预测的不确定性,或者模型权重参数的不确定性,例如对不同输入的敏感程度。 在时间和空间方面对数据集的覆盖范围是多少? 是否有足够的记录可以覆盖不同风暴类型的范围以及可能影响关注区域的事物。
Wimmers, A., C. Velden, and J. H. Cossuth, 2019:
Using Deep Learning to Estimate Tropical Cyclone Intensity from Satellite Passive Microwave Imagery.
Mon. Wea. Rev., 147, 2261–2282
模式后处理
最后,我们进行了多种处理,这基本上是使用机器学习模型或统计模型来校正数值天气预报模型的过程,该模型基于历史时段内数值天气预报模型中的系统偏差。
自 1960 年代后期以来,我们一直在使用线性回归类型的模型进行此操作。
但是机器学习已经成为一种更高级的方式,通过查看不同的方案并添加了更高级别的数据描述,从而以更高的性能实现了这一目标。
但是当我们这样做时,我们应该再考虑一下真实值的质量怎么样。 是否已获取所有相关的输入?输出的数值模式是否显著更改配置?
Herman, G. R., and R. S. Schumacher, 2018:
Money Doesn’t Grow on Trees, but Forecasts Do: Forecasting Extreme Precipitation with Random Forests. Mon. Wea. Rev., 146, 1571–1600
数据获取
因此,一旦您回答了所有这些问题并确定了潜在的陷阱所在。 下一步就是去收集一些数据。
三种方式
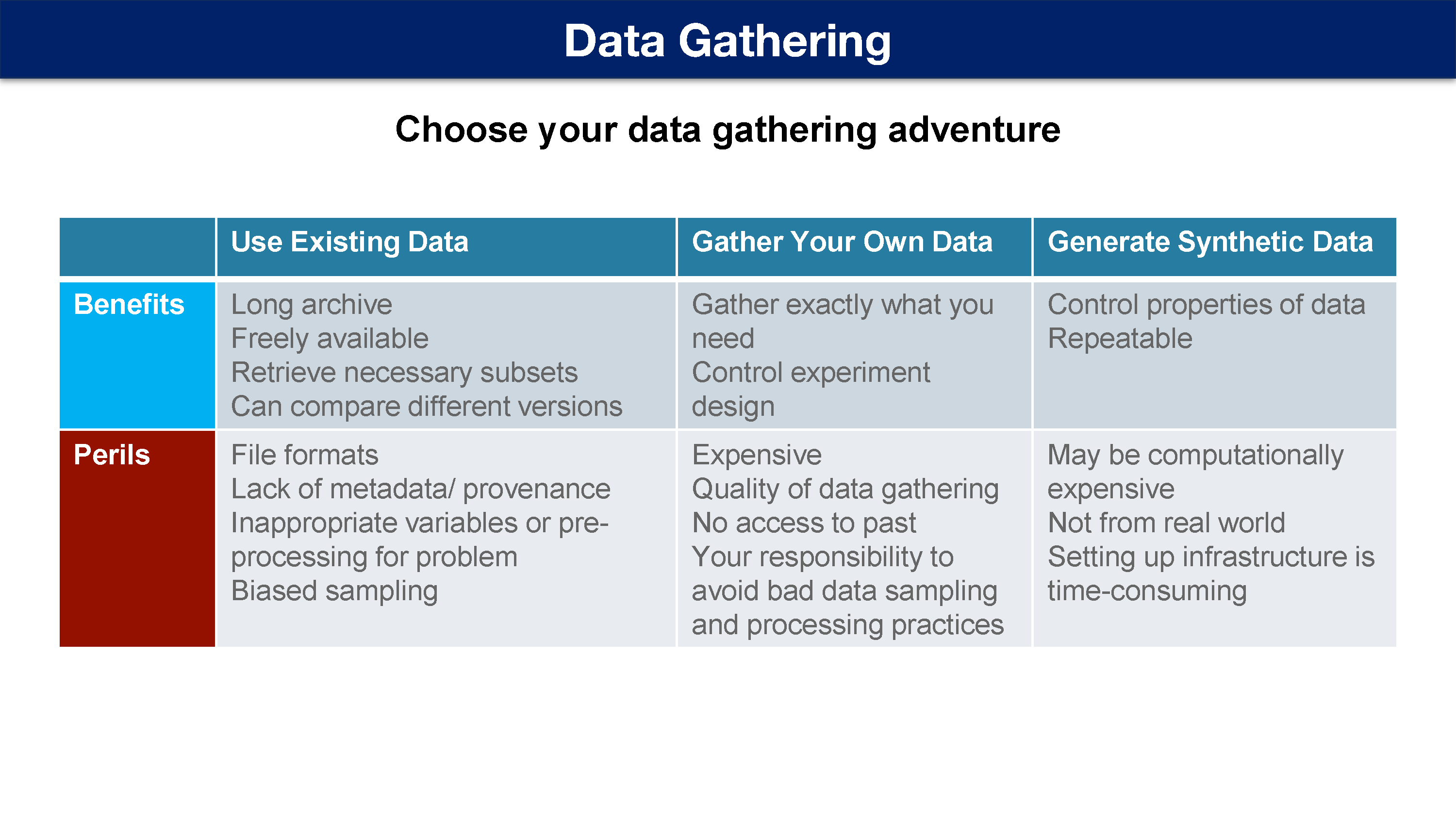
有多种方法可以收集数据,但每种都有自己的优势和劣势。
使用现有数据
常用的选择通常是使用现有数据。
优势
长序列归档
现有数据通常有为其他任务生成的长序列归档,您可以将其用于机器学习。
这些数据可能是再分析数据集或实际预报结果,或者只是有人一直在他们的服务器上进行大量 GFS 试验。
无论有什么数据,都可以用于机器学习中。
免费获取
通常现有这是免费提供的,但可能并非总是免费提供的,显然要为存档数据集支付很多费用。
检索需要的子集
通常您可以仅检索必要的子集,这样就不必保留完整的数据存档。 您可以提取所需的内容并将其用于机器学习。
可以对比不同的版本
如果多人已经完成相同类型的应用,那么现在可能存在不同的再分析数据集。 您可以对不同的数据集应用相同的机器学习过程,并进行比较,看看结果是否相同,以便进行测试。
劣势
文件格式
稍后将详细讨论文件格式的问题,这关系到是否可以轻松读取数据。
缺少元数据和数据源
有时对于现有数据而言,可能缺少元数据或数据源。 比如所有数据来自何处以及如何处理。 如果只是将它们放在随机的组文件中,则可能无法跟踪对它所做的所有更改。
缺少合适的变量或预处理
可能还有不适当的变量,需要针对特定问题进行预处理。 因为数据的平均计算方法可能与您的平均计算方法不同。
抽样偏差
而且现有数据是在特定时间段内以某种方式进行抽样收集的。 也许在收集过程中错过了某些信息。 可能会出现各种潜在问题,这些问题都会影响机器学习模型。
自己收集数据
你可能不想遇到所有这些问题,所以决定我要收集自己的数据,并以正确的方式来执行。
优势
精确收集需要的数据
您真的可以建立一个强大的实验和强大的程序以及所有此类内容,并准确收集所需的信息,
控制实验设计
控制实验设计,运行自己的模拟程序
劣势
成本高
您需要人的时间和设备,也许还需要大量的超级计算才能完成此任务。
数据收集的质量
如果您不是此特定数据格式或问题的专家,那么收集的数据质量可能就不太两项。 因此您可能需要在此过程中招募其他专家或与某人合作来完成这一步骤,尽管这会增加费用。
缺乏历史数据
如果需要收集观测数据,那么将无法回溯过去并使用观测仪器。 因此,您仅能获取从现在开始收集的内容。 如果您想查看历史趋势,这将成为一个问题。
您有责任避免不良的数据采样和预处理
您有有责任避免抱怨现有数据集的所有不良数据采样和处理方法。 责任全在你身上了,如果失败了,没有人要责怪,只有你自己。
人工合成数据
最后,您可以人工合成数据。这些数据来自运行模拟程序或数据生成程序,生成符合您要求的数据。
优势
控制数据的属性
可重复
劣势
可能在计算上很昂贵
不是来自真实世界的数据
合成数据需要将您知道的所有内容编码为数据,但这些数据不是来自现实世界。
如果您是真实世界的数据,那么通常会包含合成数据中没有的其他未知信息。
因此在合成数据中获得的良好性能可能无法转化到真实数据上。
建立基础架构非常耗时
因此,无论您选择哪种方式,总是会遇到一些挑战。 但是根据您对问题的定义方式,这些方法中的一种可能是最有效,或者是所有这些方法的某种组合。
数据的偏差

在收集数据的同时,还需要考虑数据可能存在偏差。 这里的偏差指的是有一些主观的选择,价值观和道德操守被应用到收集不同数据集的过程中,这些过程最终会影响从中得出的结果。
偏差存在于几乎每个数据集中,并且某些偏差可能特别糟糕,并且会产生极大的负面影响。
因此需要意识到偏差的存在,并进行检查,在可能的情况下找出减少偏差的方法。
观测数据并不是随机收集的
就像地球系统科学一样,经常出现的一件事是,观测数据不是随机收集的。 我们在某些位置放出了仪器,而出于任何原因选择仪器。 但是基本上,我们并不是在地球上的每个点上收集数据。 因此,我们的数据将反映出我们放置观测系统的位置选择。
数据可能会因收集过程而有偏差,尤其是报表数据集
在此示例中,我们从 Allen 的论文中可以看到,冰雹报告优先在公路和大城市中被收集,并且还可以看到龙卷风报告也是如此。 但这并不意味着在没有道路的地区不会发生冰雹,仅意味着有人在观察。
因此,当您正在训练机器学习的冰雹预测系统时,或者在考虑诸如平滑数据或执行其他一些步骤来汇总数据有助于纠正其中一些问题时,应该考虑到这一点。
在有偏差的数据和有偏差的假设下训练的机器学习模型会将偏差传播到其预测中
我之所以再次提到这一点,是因为在有偏差数据和有偏假设的基础上训练的机器学习模型会将偏差传播到预测中。
对于那些可能在周末关注机器学习 Twitter 的人们来说,有一个称为 Pulse 的模型发布了。 该模型主要用于从拍摄人的模糊图像制作高分辨率的图像,人们尝试放入不同的图像,以查看结果如何。
其中一个不幸或幸运的是,有人发现了一个有问题的偏差模型,放入奥巴马总统的画像后,却输出了一个看起来不是很像奥巴马总统的成年白人。
因此,这是模型中种族偏见发生率的一种示例。 有很多关于数据方面的业务,模型的训练方式或固有因素的争论。 模型中不同权重的设置以及卷积及其结构,可能导致这种情况或损失函数。 但基本上,这种偏见可以贯穿整个过程,包括为什么我们选择向上缩放,模糊脸的最终目标是什么。 特别是如果它被用来像犯罪问题或其他类似的东西。
所以思考如何定义问题,以及一些其他问题。 即使我们不一定在大气科学中进行面部识别,我们也在做很多其他预测问题,以及气候或地球系统科学是否对人们有重大的影响。
所以请检查数据,以确保预测不会对有色人种或穷人带来负面影响。 不要认为,我们只是正在处理天气数据或数值模式,这些决定不会有影响。
应该为训练和验证分别收集数据
Allen and Tippett 2015
数据文件格式

通常按照下面的标准选择数据格式:
- 数据的结构
- 数据集的大小
- 用户的需求
原始数据格式对于机器学习来说可能不是理想的格式。
- 旧文件格式
- 以不太理想的内存访问模式进行分块
- 变量名称,格式等缺失或不一致
关键讨论点:文本格式 vs 二进制格式
- 文本:更易于检查,便于携带,但体积大且容易因人为原因产生格式错误
- 二进制:可以紧凑地以一致的格式存储大型数据集,但需要特殊的库才能读取
表格和结构化数据

CSV
纯文本文件,包含按列分隔的数据。 便携式且可读性强,但面向行,无法很好地扩展到 GB 或 TB 级的数据集
Apache Parquet
二进制开源列式数据格式,可提供压缩并支持不同的数据格式
XML,JSON 和 YAML
基于分层文本的数据格式,提供额外少量的语法。 对于配置文件和存储非表格数据很有用。
地理空间数据

GRIB
世界气象组织网格数据的标准格式。 可以进行高度压缩,但是元数据存储在文件外部,这对于自定义变量是一个问题。
netCDF4/HDF5
支持单个变量压缩的分层,自描述的二进制数据格式。 在超级计算机上运行良好,但在云存储中性能较差。
Zarr
新的二进制分层数据格式,可将数据集分解为大量小的二进制文件。 更适合云数据存储。
数据预处理
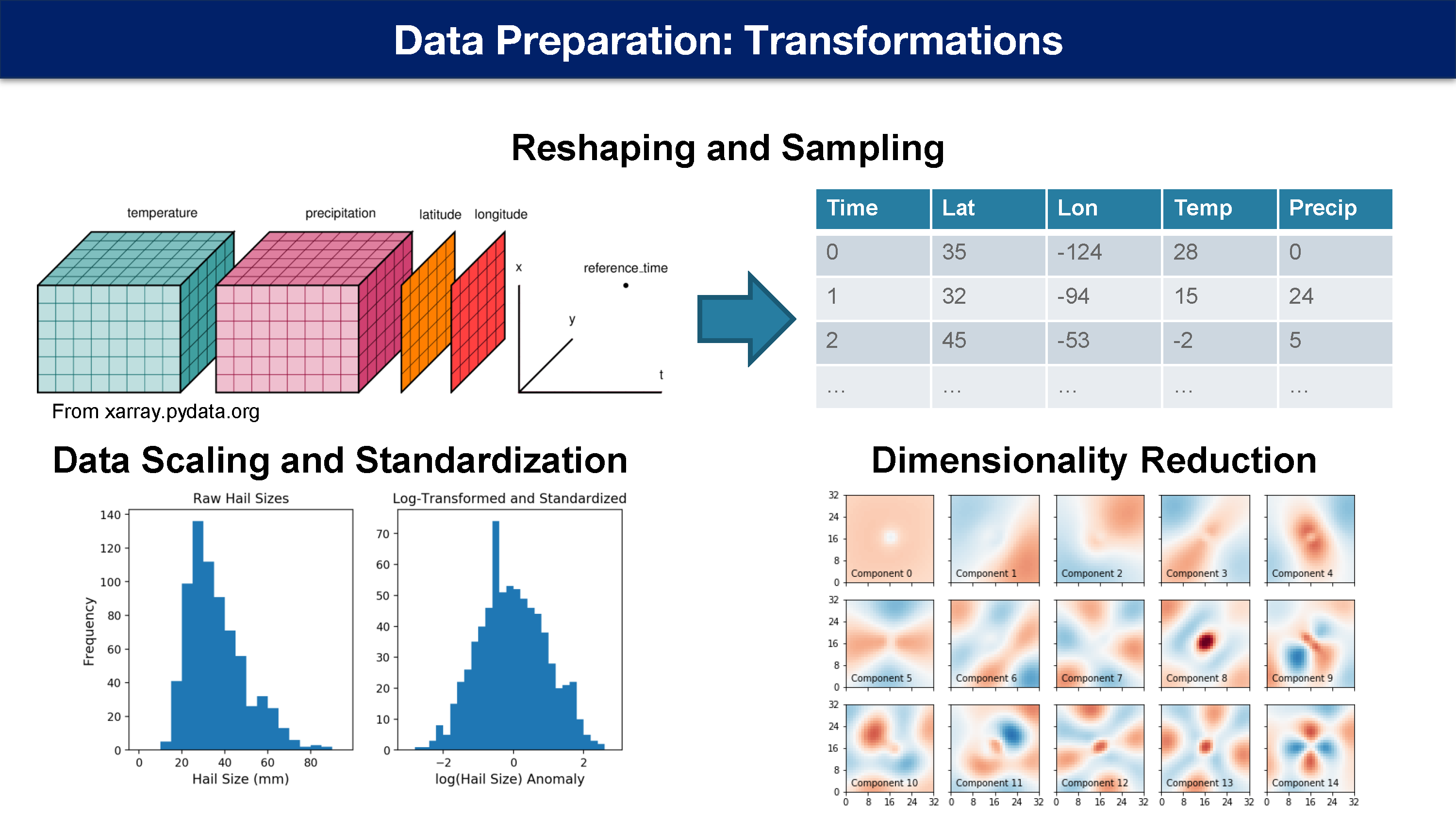
重塑
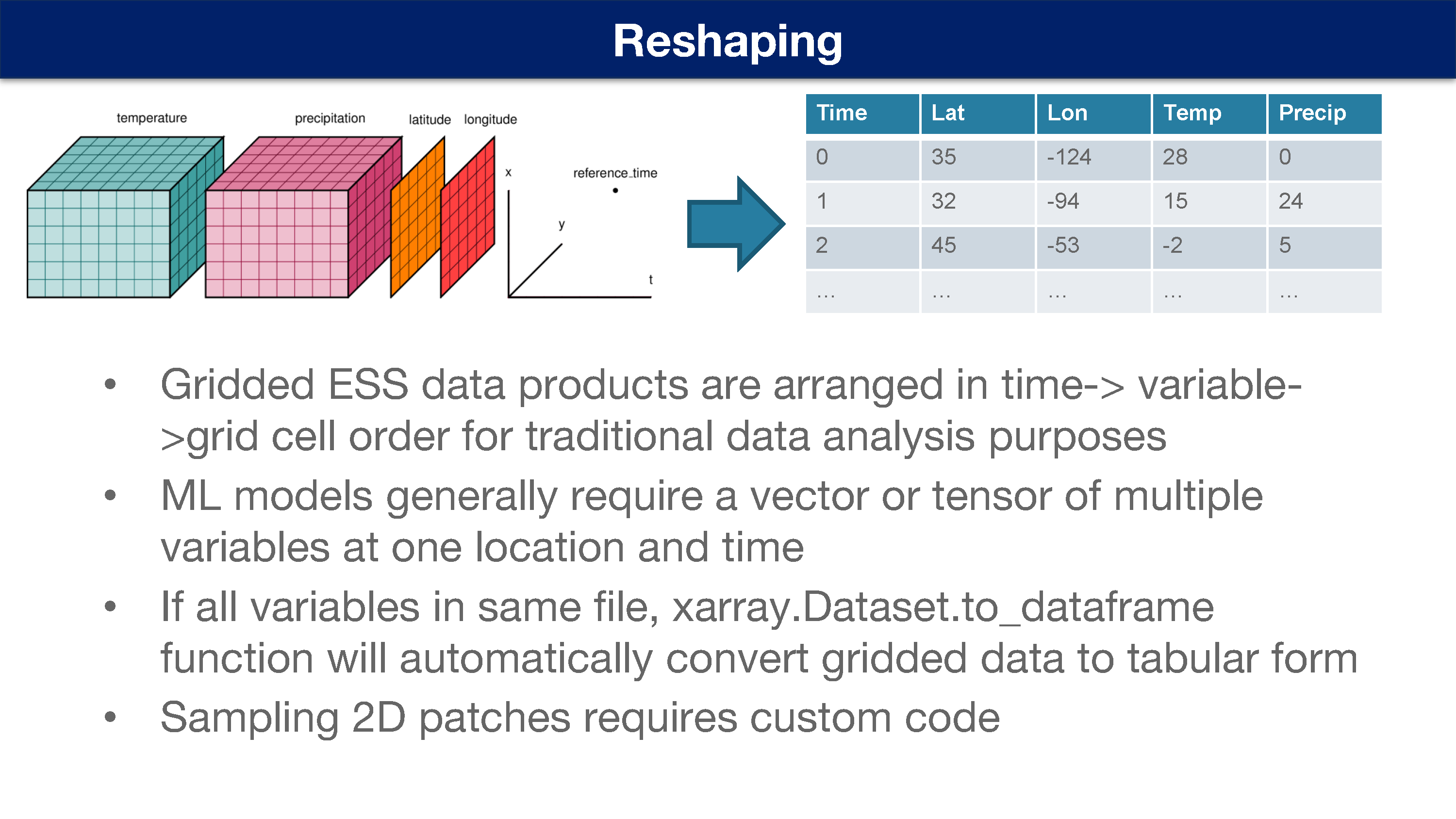
地球系统科学的网格数据产品通常按照 时间 -> 变量 -> 网格 顺序排列,用于传统的数据分析。
机器学习模型通常需要同一地点和时间的多个变量的矢量或张量。
如果所有变量都在同一个文件中,xarray.Dataset.to_dataframe 会自动将网格数据转换为表格形式。
采样二维数据需要额外编写代码。
数据转换和缩放
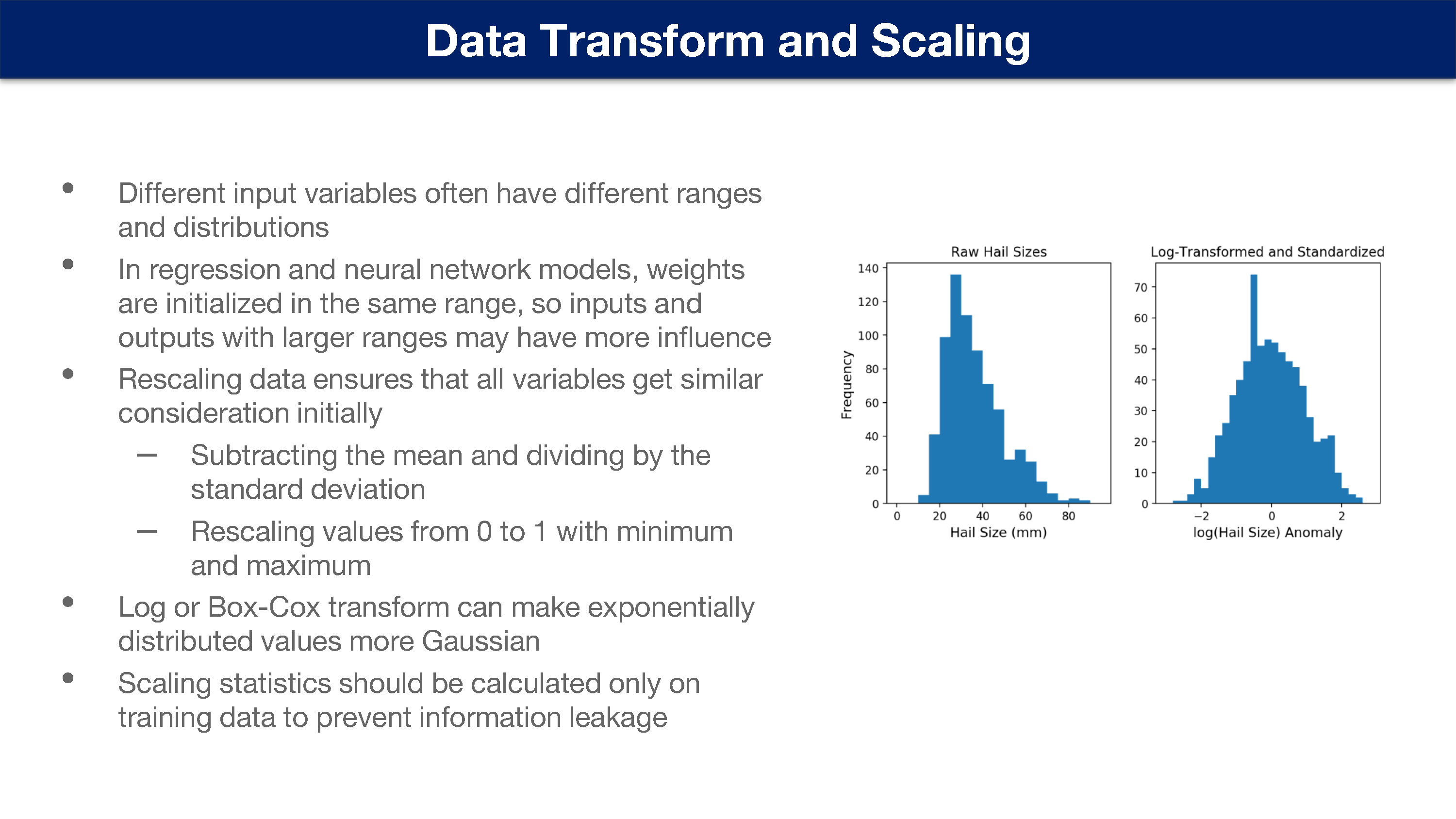
不同的输入变量通常具有不同的范围和分布。
在回归和神经网络模型中,权重在同一范围内初始化,所以范围较大的输入和输出可能有更大的影响。
重新缩放数据可确保所有变量都具有相同的尺度。
- 减去均值,除以标准差
- 根据最小值和最大值,将值重新缩放 0 到 1 之间
Log 或 Box-Cox 变换可以生成比呈指数级分布的数据。
缩放统计信息应仅根据训练数据进行计算,以防止信息泄露。
降低维度
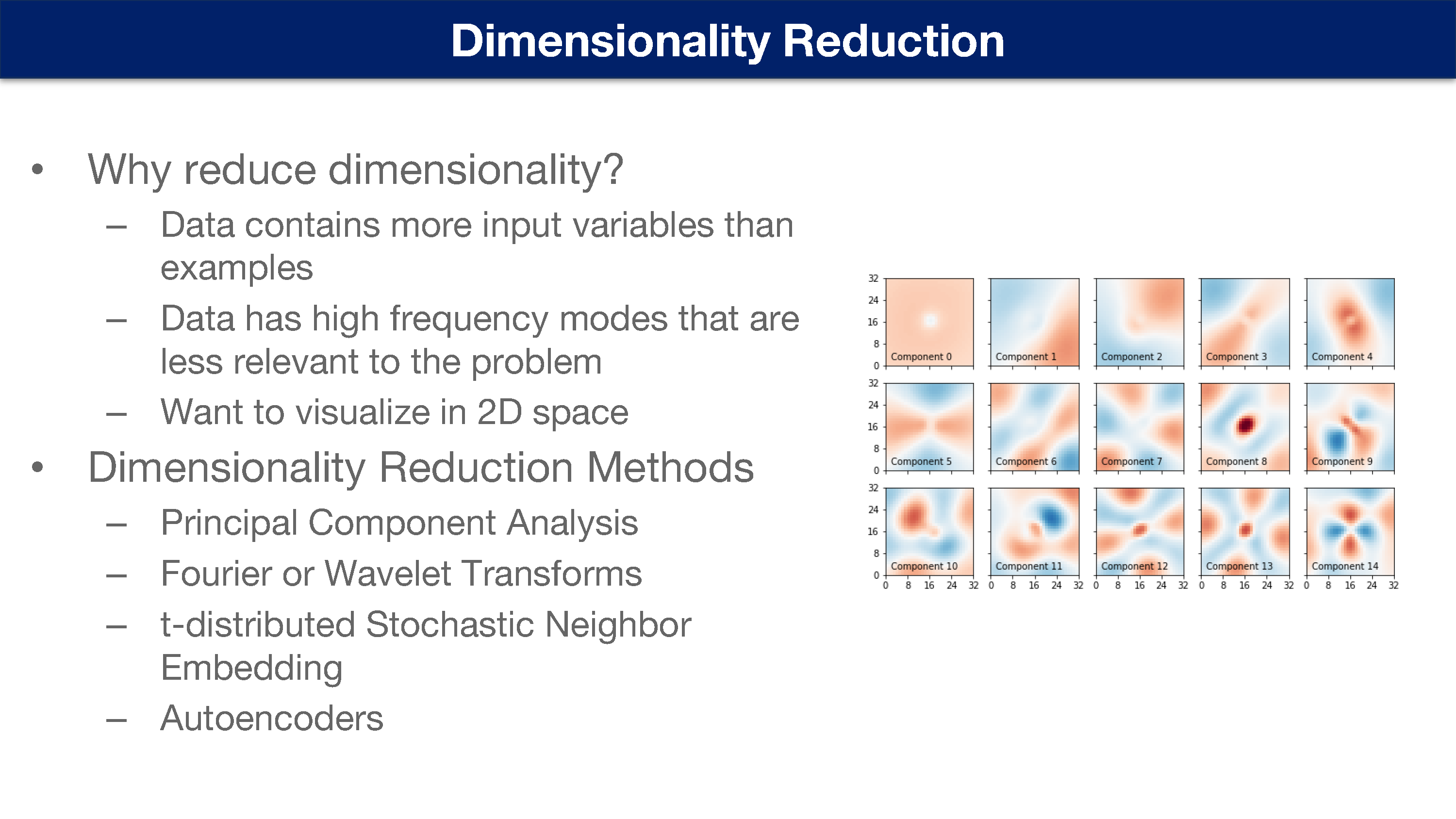
为什么降低维度?
数据比示例包含更多的输入变量
数据中有一些高频模式与问题没有太大的关联
想在二维空间中可视化
维度降低方法
主成分分析
傅里叶或小波变换
t 分布随机邻域嵌入
自动编码
对象识别和跟踪

一些地球系统现象可以识别和跟踪为离散事件
启发式物体识别系统使用固定阈值和计算机视觉技术
可以通过实时计算对象与质心或重叠的匹配来完成跟踪
大量的边缘案例和参数权衡
From Ryan Lagerquist
特征选择

如何在最小化输入数量和最大化性能之间找到合适的平衡?
全局特征选择方法,例如顺序前向选择
基于模型的特征选择,例如 LASSO
条件特征选择,例如决策树
From McGovern et al. 2020
训练/验证/测试数据集
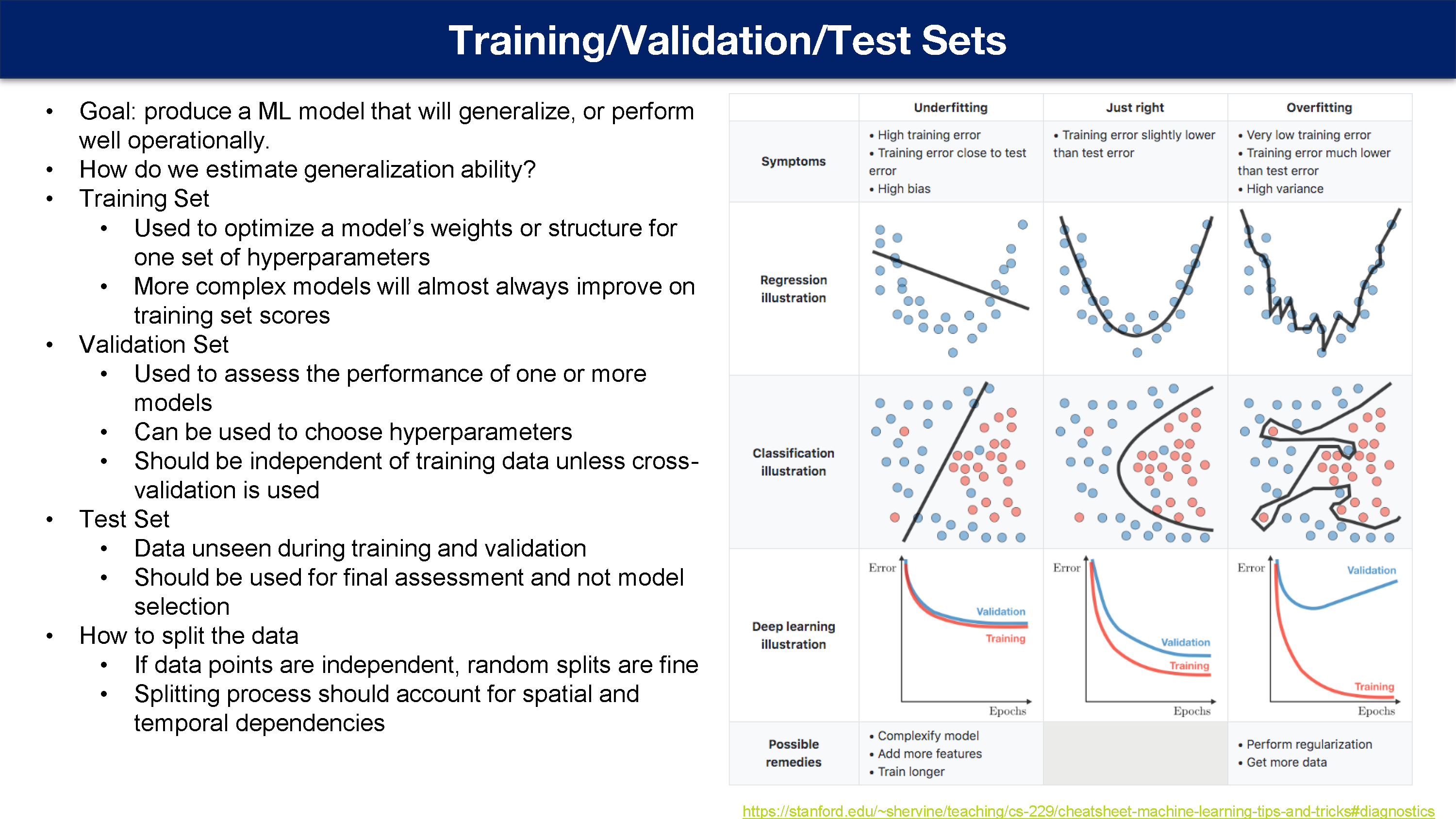
目标:生成一个可以泛化或在业务上表现良好的机器学习模型
我们如何估计泛化能力?
训练集
用于优化一组超参数的模型权重或结构
更复杂的模型几乎总会提高训练集的分数
验证集
用于评估一个或多个性能
可用于选择超参数
应该独立于训练数据,除非使用交叉验证
测试集
训练和验证期间看不到的数据
应该用于最终评估,而不是模型选择
如何分割数据
如果数据点是独立的,则可以随机分割。
分割过程应考虑到空间和时间上的依赖性。
总结

在一开始就很好地定义机器学习问题将为您节省很多时间。
数据收集程序会严重影响最终的机器学习模型的结构和预测。
预处理选择是有效将数据转换为适合机器学习格式的关键。
