NWPC笔记:优化模式输出文件检查模块
去年的一篇文章《NWPC笔记:获取模式积分任务的执行进度》介绍 NWPC 数值预报业务系统中使用的积分进度跟踪方法。
其中“检测数据文件输出”方法已应用于 GRAPES MESO 和 GRAPES TYM 等区域模式系统。 业务系统在检测到模式输出文件的同时,会将这些文件拷贝到临时归档目录(runtime archive)和 HPC 归档目录(archive)中。
最近更新的 GRAPES TYM 系统将输出间隔由 3 小时缩短为 1 小时,并在 postvar 基础上增加模式面数据 modelvar 的输出,显著增加文件拷贝的数据量。 拷贝单个时效文件到两个归档目录耗时将近40秒,已超过模式输出文件的生成间隔(大概30秒),导致标尺 meter 失去指示意义,同时也严重滞后产品后处理任务。
本文介绍如何对模式输出文件检查模块进行优化,使标尺指示的进度与模式积分进度相当。
归档目录
下面首先介绍数值预报业务系统的归档目录。
临时归档目录
直接使用模式输出目录中的数据就不需要拷贝数据,为什么需要将数据放到临时归档目录?
NWPC 数值预报业务系统的数据存储目录如下图所示。
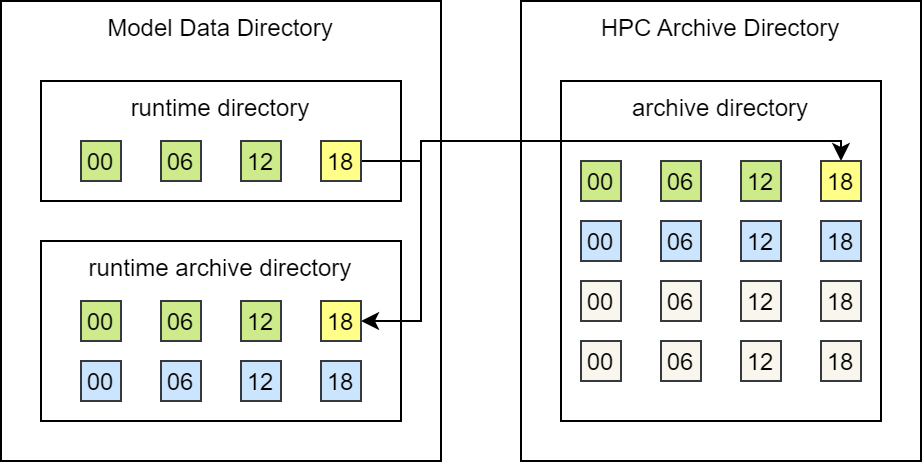
NWPC 数值预报业务系统数据存储目录
其中 Model Data Directory 是业务系统运行目录,实时生成的文件都保存在该目录下。
runtime directory 是模式系统程序实际的运行目录。 一般不同时次在不同的目录中运行,例如 GRAPES MESO 系统由 4 个时次目录。 或者所有时次都在同一个目录中运行,例如 GRAPES TYM 系统只有一个运行目录。
runtime archive directory 是模式数据的临时归档目录,一般只保留10天以内的数据。 archive directory 是在 HPC 归档目录下的在线目录,保存数据时间较长,模式积分输出的二进制数据可能会保存一个月。
业务系统在每次使用运行目录进行积分前,一般会清空该目录下所有的文件。 在业务系统正常运行时,其实无论上面提到的哪种运行目录划分方式,都可以直接使用运行目录下的数据。 但业务系统要具备故障恢复的能力,在系统异常时,留有补救的手段。 比如发现前两天的某个产品没有正常生成,或者 FTP 传输异常,目标用户没有接收到,需要临时补做。 这就需要保留最近几天的模式原始输出数据,也是 runtime archive directory 存在的意义。
另外,因为我们并非将所有的输出数据都归档到 HPC 的在线归档目录,比如 GRAPES TYM 系统不用归档 modelvar 数据,所以业务系统需要在运行目录中保留近期的数据。
复制 vs 移动
既然将文件拷贝到临时归档目录耗时过长,那么为什么不直接移动文件到指定目录?
这就与业务系统运行维护有关。下图是数值预报业务系统模式积分模块的示例。
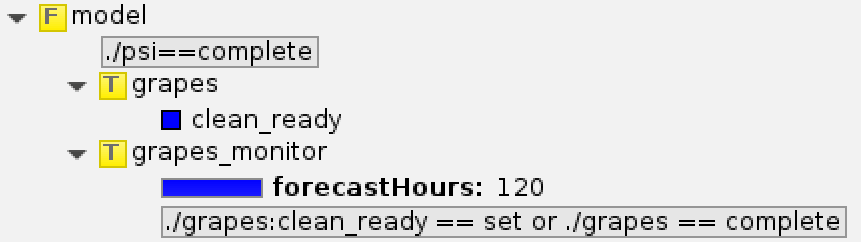
GRAPES TYM 模式积分任务
grapes 模块执行模式积分,而 grapes_monitor 模块监控模式输出文件,并将文件拷贝到归档目录。
ecFlow 中各个模块最佳的设计逻辑是单个任务可以重复执行多次而得到相同的结果。
因为每个任务都可能会因为各种原因而出错,如果某个任务重新执行会出错,就会给运维人员带来额外的负担,毕竟运维人员无法熟悉所有系统的每个模块。
如果在 grapes_monitor 中直接移动文件,那么当 grapes_monitor 意外出错再重新运行时,就会因为无法找到被移动走的文件,而一直卡住,或者直接超时出错。
所以,NWPC 数值预报业务系统中,我们使用 copy 而不是 mv。
当前方案
当前系统在监视输出的任务中将文件复制到 runtime archive 和 archive 两个目录中。
下面的代码来自 GRAPES MESO 3KM 系统中 fcst_monitor 模块。
逐时效检测输出文件是否全部存在,并在等待 3s 后,拷贝文件到归档目录,继续检测下一个时效。
typeset -Z3 FFF
for fhour in `seq 0 ${mfcast_len} `
do
FFF=$fhour
fileExist=".false."
while [ $fileExist = ".false." ]
do
if [ -s postvar${begintime}${FFF}00 -a -s post.ctl_${begintime}${FFF}00 -a modelvar${begintime}${FFF}00 -a -s model.ctl_${begintime}${FFF}00 ]; then
sleep 3
cp postvar${begintime}${FFF}00 \
post.ctl_${begintime}${FFF}00 \
modelvar${begintime}${FFF}00 \
model.ctl_${begintime}${FFF}00 \
${GRAPES_RESULTS}/
cp postvar${begintime}${FFF}00 \
post.ctl_${begintime}${FFF}00 \
modelvar${begintime}${FFF}00 \
model.ctl_${begintime}${FFF}00 \
${OBJDIR_ROOT}/Fcst-main/${begintime}/
ecflow_client --meter=fcstHours $fhour
fileExist=".true."
else
sleep 60
fi
done
done但 GRAPES TYM 更新到逐小时输出后,拷贝文件的时间已超过文件输出的间隔。 所以笔者改进了上面的方案。
优化方案
优化方向有以下几条:
- 减少文件复制量
- 延后文件复制
- 将串行复制改为并发复制
针对第 1 点,GRAPES TYM 不再向 HPC 归档目录中拷贝 modelvar 数据,大大降低复制数据量(单个时效modelvar有 7 GB,postvar 仅有 2 GB)。
针对第 2 点和第 3 点,笔者设计了如下图所示的方案。
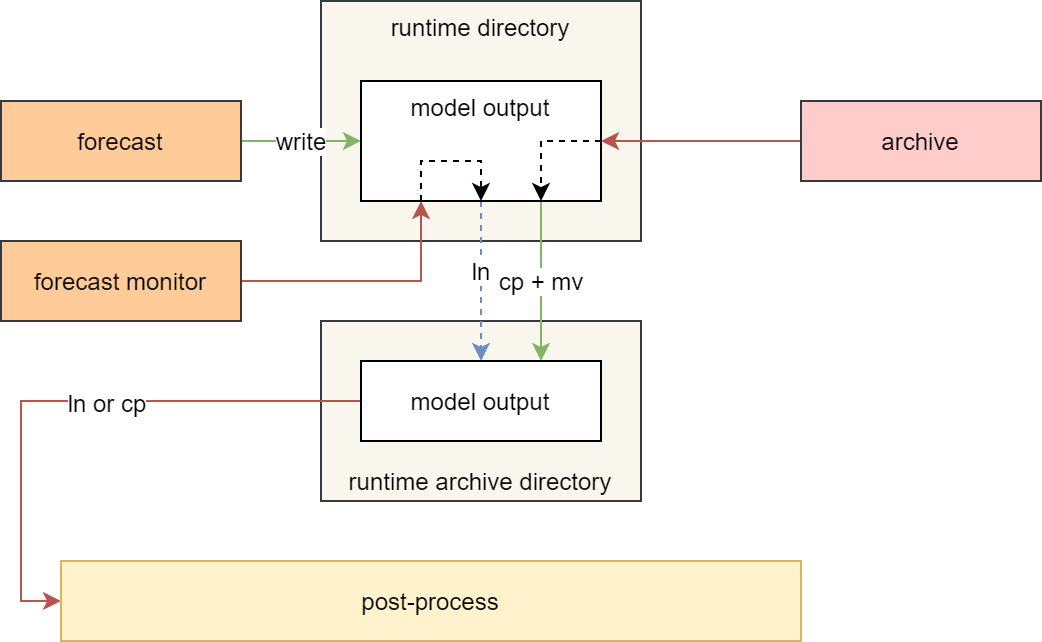
GRAPES TYM 模式输出检查模块优化方案
在检查模式输出文件模块 forecast monitor 中,不再复制文件,而是将文件链接到 runtime archive 目录中。
这样现有系统中的后处理模块无需更改,即可通过链接从 runtime archive 目录中访问到 runtime 目录中的模式输出文件。 在系统的归档阶段,再将数据分时效并行拷贝到 runtime archive 目录。而此时,模式后处理一般情况下已经完成,文件复制操作不会对后处理系统产生影响。
实现
grapes_monitor 中使用 ln -sf 强制生成软连接。
typeset -Z3 FFF
for fhour in `seq 0 ${forecast_length} `
do
FFF=$fhour
fileExist=".false."
while [ $fileExist = ".false." ]
do
cd ${RUNDIR}
# copy postvar and sfcvar
if [ -s postvar${ST_DATE}${FFF}00 ] && [ -s sfcvar${ST_DATE}${FFF}00 ] && [ -s sfc.ctl_${ST_DATE}${FFF}00 ] && [ -s model.ctl_${ST_DATE}${FFF}00 ]; then
sleep 2
chmod 644 postvar${ST_DATE}${FFF}00 sfcvar${ST_DATE}${FFF}00 sfc.ctl_${ST_DATE}${FFF}00 modelvar${ST_DATE}${FFF}00 model.ctl_${ST_DATE}${FFF}00
cd ${D01DAT}
ln -sf ${RUNDIR}/postvar${ST_DATE}${FFF}00 .
ln -sf ${RUNDIR}/sfcvar${ST_DATE}${FFF}00 .
ln -sf ${RUNDIR}/sfc.ctl_${ST_DATE}${FFF}00 .
ln -sf ${RUNDIR}/modelvar${ST_DATE}${FFF}00 .
ln -sf ${RUNDIR}/model.ctl_${ST_DATE}${FFF}00 .
ecflow_client --meter=forecastHours $fhour
fileExist=".true."
else
sleep 2
fi
done
donearchive_binary 任务分时效复制模式输出数据。
拷贝数据到 runtime archive 目录时,先增加 .tmp 后缀,再使用 mv 修改为原来的名称,覆盖之前设置的软连接。
# copy to archive
cp postvar${ST_DATE}${forecast_hour}00 sfcvar${ST_DATE}${forecast_hour}00 sfc.ctl_${ST_DATE}${forecast_hour}00 ${BIN_ARCHIVE_DIR}/
# copy to runtime archive
cp postvar${ST_DATE}${forecast_hour}00 ${D01DAT}/postvar${ST_DATE}${forecast_hour}00.tmp
mv ${D01DAT}/postvar${ST_DATE}${forecast_hour}00.tmp ${D01DAT}/postvar${ST_DATE}${forecast_hour}00
# ...skip...