xarray指南:数据结构
本文翻译自 xarray 官方文档 Data Structures。
开始之前,先导入需要的包。
import numpy as np
import pandas as pd
import xarray as xr
import matplotlib.pyplot as plt
xr.set_options(display_style="text")DataArray
xarray.DataArray 是 xarray 实现的带标签的多维度数组,有下面几个关键属性:
value:保存数组值的numpy.ndarraydims:每个轴的名称,例如('x', 'y', 'z')coords:类似字典的数组容器(coordinates),标记每个点。例如数字、日期时间对象或字符串的一维数组attrs:保存任意元数据(attributes)的dict
xarray 使用 dims 和 coords 实现其核心元数据感知操作。
维度(Dimensions)提供 xarray 使用的名称,代替许多 numpy 函数中的 axis 参数。
坐标(Coordinates)类似 Pandas DataFrame 或 Series 上的索引功能,实现基于标签的快速索引和对齐功能。
DataArray 对象也可以有名称,并通过 attrs 属性的形式保存任意元数据。
名称和属性仅适用于用户和用户编写的代码:xarray 不会尝试解释它们,并且仅在明确的情况下传播它们
(请参阅FAQ,What is your approach to metadata?)。
创建 DataArray
DataArray 构造函数需要:
data:数据的多维数组(例如,numpy 的 ndarray,Series,DataFrame或pandas.Panel)coords:坐标列表或字典。如果是列表,则应为元组列表,其中第一个元素是维度名称,第二个元素是对应的坐标 array_like 对象。dims:维度名称列表。如果省略,并且coords是元组列表,则维度名称取自coords。attrs:添加到对象实例的属性字典name:命名对象实例的字符串
data = np.random.rand(4, 3)
locs = ["IA", "IL", "IN"]
times = pd.date_range("2020-01-01", periods=4)
foo = xr.DataArray(
data,
coords=[times, locs],
dims=["time", "space"],
)
foo<xarray.DataArray (time: 4, space: 3)>
array([[0.09558283, 0.54437857, 0.72715542],
[0.68237872, 0.92443852, 0.04011683],
[0.77798767, 0.09533936, 0.53837686],
[0.25279103, 0.46399048, 0.31854009]])
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
只有 data 是必须指定的;所有其它参数都可以使用默认值。
xr.DataArray(data)<xarray.DataArray (dim_0: 4, dim_1: 3)>
array([[0.09558283, 0.54437857, 0.72715542],
[0.68237872, 0.92443852, 0.04011683],
[0.77798767, 0.09533936, 0.53837686],
[0.25279103, 0.46399048, 0.31854009]])
Dimensions without coordinates: dim_0, dim_1
如您所见,维度名称始终存在于 xarray 的数据模型中:如果不显式提供,则使用默认格式 dim_N 自动创建。
但是,坐标始终是可选的,并且 dimensions 没有自动坐标标签。
可以用以下几种方式指定坐标:
- 长度等于维度值的列表,为每个维度提供坐标标签。每个值都必须采用以下形式之一:
DataArray或Variable- 格式为
(dims, data[, attrs])的元组,会被转变为Variable的参数 - pandas 对象或标量数值,被转换为
DataArray - 一维数组或列表,它被解释为沿相同名称维度的一维坐标变量的值
{coord_name:coord}的字典,其中值的形式与列表相同。以字典形式提供坐标可以使用不对应维度的坐标(稍后会详细介绍)。如果您以字典形式提供coords,则必须显式指定dim。
元组列表:
xr.DataArray(
data,
coords=[
("time", times),
("space", locs)
]
)<xarray.DataArray (time: 4, space: 3)>
array([[0.09558283, 0.54437857, 0.72715542],
[0.68237872, 0.92443852, 0.04011683],
[0.77798767, 0.09533936, 0.53837686],
[0.25279103, 0.46399048, 0.31854009]])
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
字典
xr.DataArray(
data,
coords={
"time": times,
"space": locs,
"const": 42,
"ranking": ("space", [1, 2, 3])
},
dims=["time", "space"]
)<xarray.DataArray (time: 4, space: 3)>
array([[0.09558283, 0.54437857, 0.72715542],
[0.68237872, 0.92443852, 0.04011683],
[0.77798767, 0.09533936, 0.53837686],
[0.25279103, 0.46399048, 0.31854009]])
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
const int32 42
ranking (space) int32 1 2 3
附带多个维度坐标的字典
xr.DataArray(
data,
coords={
"time": times,
"space": locs,
"const": 42,
"ranking": (("time", "space"), np.arange(12).reshape(4,3))
},
dims=["time", "space"],
)<xarray.DataArray (time: 4, space: 3)>
array([[0.09558283, 0.54437857, 0.72715542],
[0.68237872, 0.92443852, 0.04011683],
[0.77798767, 0.09533936, 0.53837686],
[0.25279103, 0.46399048, 0.31854009]])
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
const int32 42
ranking (time, space) int32 0 1 2 3 4 5 6 7 8 9 10 11
如果通过提供 pandas Series,DataFrame 或 pandas.Panel 创建 DataArray,则将用 pandas 对象填充 DataArray 构造函数中所有未指定的参数:
df = pd.DataFrame(
{
"x": [0, 1],
"y": [2, 3],
},
index=["a", "b"]
)
df.index.name = "abc"
df.columns.name = "xyz"
xr.DataArray(df)<xarray.DataArray (abc: 2, xyz: 2)>
array([[0, 2],
[1, 3]], dtype=int64)
Coordinates:
* abc (abc) object 'a' 'b'
* xyz (xyz) object 'x' 'y'
DataArray 属性
让我们看一下 DataArray 上的重要属性:
foo.valuesarray([[0.09558283, 0.54437857, 0.72715542],
[0.68237872, 0.92443852, 0.04011683],
[0.77798767, 0.09533936, 0.53837686],
[0.25279103, 0.46399048, 0.31854009]])
foo.dims('time', 'space')
foo.coordsCoordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
foo.attrs{}
print(foo.name)None
可以就地修改 values:
foo.values = 1.0 * foo.values注意
DataArray 中的数组值只有单一的数据类型。
要在 xarray 中使用异构或结构化数据类型,请使用坐标,或将单独的 DataArray 对象放在单个 Dataset 中(请参见下文)。
现在,填写一些缺少的元数据:
foo.name = "foo"
foo.attrs["units"] = "meters"
foo<xarray.DataArray 'foo' (time: 4, space: 3)>
array([[0.09558283, 0.54437857, 0.72715542],
[0.68237872, 0.92443852, 0.04011683],
[0.77798767, 0.09533936, 0.53837686],
[0.25279103, 0.46399048, 0.31854009]])
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
Attributes:
units: meters
rename() 方法返回一个新的数据数组:
foo.rename("bart")<xarray.DataArray 'bart' (time: 4, space: 3)>
array([[0.09558283, 0.54437857, 0.72715542],
[0.68237872, 0.92443852, 0.04011683],
[0.77798767, 0.09533936, 0.53837686],
[0.25279103, 0.46399048, 0.31854009]])
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
Attributes:
units: meters
DataArray 坐标
coords 属性类似 dict。
可以按名称访问单个坐标,甚至可以通过索引数据数组本身来访问:
foo.coords["time"]<xarray.DataArray 'time' (time: 4)>
array(['2020-01-01T00:00:00.000000000', '2020-01-02T00:00:00.000000000',
'2020-01-03T00:00:00.000000000', '2020-01-04T00:00:00.000000000'],
dtype='datetime64[ns]')
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
foo["time"]<xarray.DataArray 'time' (time: 4)>
array(['2020-01-01T00:00:00.000000000', '2020-01-02T00:00:00.000000000',
'2020-01-03T00:00:00.000000000', '2020-01-04T00:00:00.000000000'],
dtype='datetime64[ns]')
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
也有包含每个维度的刻度标签的 DataArray 对象。
可以使用类似字典的语法来设置或删除坐标:
foo["ranking"] = ("space", [1, 2, 3])
foo.coordsCoordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
ranking (space) int32 1 2 3
del foo["ranking"]
foo.coordsCoordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
更详细的信息,请查看下面的坐标章节。
Dataset
xarray.Dataset 是 xarray 的 DataFrame 多维等效项。
它是类似 dict 的具有对齐纬度的标记数组(DataArray对象)的容器。
它被设计成 netCDF 文件格式的数据模型的内存表示形式。
除了数据集本身的类似 dict 的接口(可用于访问数据集中的任何变量)之外,数据集还具有四个关键属性:
dims:从维度名称映射到每个维度的固定长度的字典(例如{'x':6,'y':6,'time':8})data_vars:对应变量的类似字典的 DataArrays 容器coords:另一个类似 dict 的 DataArray 容器,用于标记data_vars中使用的点(例如,数字数组,日期时间对象或字符串)attrs:保存任意元数据的dict
变量是归入数据还是坐标(从 CF conventions 中借用)之间的区别主要是语义上的,如果您愿意,您可以忽略它:在数据集中类似字典的访问方式将在任一类别中找到变量。 但是,xarray 确实在索引和计算上利用两者的区别。 坐标表示恒定/固定/独立的量,与数据中变化/测量/独立的量不同。
这是一个示例,说明如何构建天气预报的数据集:
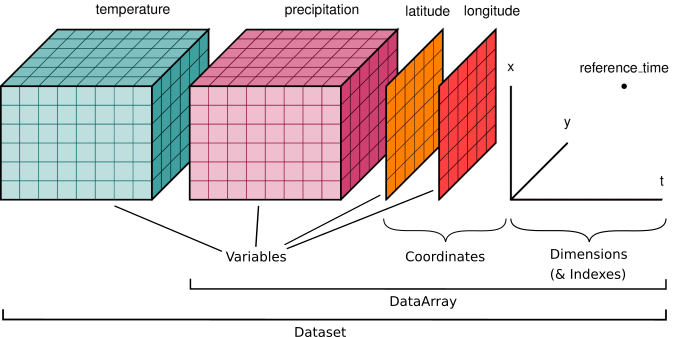
在此示例中,将 温度 和 降水 称为“数据变量”,将所有其他数组称为“坐标变量”是很自然的,因为它们沿维度标注了点。
纬度和经度是二维数组,因为数据集使用投影坐标。
reference_time 是指进行预测的起报时间,而不是预报时间。
让我们为下面的示例创建假象数据:
temp = 15 + 8 * np.random.randn(2, 2, 3)
precip = 10 * np.random.rand(2, 2, 3)
lon = [
[-99.83, -99.32],
[-99.79, -99.23],
]
lat = [
[42.25, 42.21],
[42.63, 42.59],
]
# 实际应用时,最好设置类似单位等数组属性,这里为了简洁而忽略掉这一步骤
ds = xr.Dataset(
{
"temperature": (["x", "y", "time"], temp),
"precipitation": (["x", "y", "time"], precip),
},
coords={
"lon": (["x", "y"], lon),
"lat": (["x", "y"], lat),
"time": pd.date_range("2020-04-08", periods=3),
"reference_time": pd.Timestamp("2020-04-07"),
}
)
ds<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 17.8 16.38 21.29 ... 24.48 15.9 9.936
precipitation (x, y, time) float64 8.035 9.461 2.014 ... 3.524 0.5864
在这里,我们将 xarray.DataArray 对象或 pandas 对象作为字典中的值传递:
xr.Dataset({"bar": foo})<xarray.Dataset>
Dimensions: (space: 3, time: 4)
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) <U2 'IA' 'IL' 'IN'
Data variables:
bar (time, space) float64 0.09558 0.5444 0.7272 ... 0.2528 0.464 0.3185
xr.Dataset({"bar": foo.to_pandas()})<xarray.Dataset>
Dimensions: (space: 3, time: 4)
Coordinates:
* time (time) datetime64[ns] 2020-01-01 2020-01-02 2020-01-03 2020-01-04
* space (space) object 'IA' 'IL' 'IN'
Data variables:
bar (time, space) float64 0.09558 0.5444 0.7272 ... 0.2528 0.464 0.3185
如果将 pandas 对象作为值提供,则将其索引的名称用作维度名称,并将其数据与任何现有维度对齐。
还可以采用如下的方式创建 dataset:
- 将
pandas.DataFrame或pandas.Panel分别沿其列和项目放置,将其直接传递到数据集中 - 使用
Dataset.from_dataframe从pandas.DataFrame对象创建,会额外处理 MultiIndexes - 使用
open_dataset()加载磁盘上的netCDF文件。
Dataset 内容
Dataset 实现了 Python 的映射接口,其值由 xarray.DataArray 对象给出。
"temperature" in dsTrue
ds["temperature"]<xarray.DataArray 'temperature' (x: 2, y: 2, time: 3)>
array([[[17.79880885, 16.37993705, 21.29427808],
[19.89055978, 18.43880845, 22.36864945]],
[[12.48489511, -3.06205514, 16.55347232],
[24.48384908, 15.89758382, 9.93633802]]])
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
有效的键值包括列出的每个坐标和数据变量。
数据和坐标标量同样被分开保存到类似字典的属性 data_vars 和 coords:
ds.data_varsData variables:
temperature (x, y, time) float64 17.8 16.38 21.29 ... 24.48 15.9 9.936
precipitation (x, y, time) float64 8.035 9.461 2.014 ... 3.241 3.524 0.5864
ds.coordsCoordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
最后,类似 DataArray,dataset同样也在 attributes 中保存任意元数据。
ds.attrs{}
ds.attrs["title"] = "example attribute"
ds<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 17.8 16.38 21.29 ... 24.48 15.9 9.936
precipitation (x, y, time) float64 8.035 9.461 2.014 ... 3.524 0.5864
Attributes:
title: example attribute
xarray对属性没有任何限制,但是如果您使用的对象不是字符串,数字或 numpy.ndarray 对象,则序列化为某些文件格式可能会失败。
作为有用的快捷方式,您可以使用属性样式访问来读取(但不能设置)变量和属性:
ds.temperature<xarray.DataArray 'temperature' (x: 2, y: 2, time: 3)>
array([[[17.79880885, 16.37993705, 21.29427808],
[19.89055978, 18.43880845, 22.36864945]],
[[12.48489511, -3.06205514, 16.55347232],
[24.48384908, 15.89758382, 9.93633802]]])
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
此项功能在探索式上下文中非常有用,因为你可以使用类似 IPython 类似的工具在这些变量名称上实现自动补全。
类似字典的方法
可以使用 Python 的标准字典方法就地更新数据集。 例如,要从头开始创建此示例数据集,我们可以这样写:
ds = xr.Dataset()
ds["temperature"] = (("x", "y", "time"), temp)
ds["temperature_double"] = (("x", "y", "time"), temp * 2)
ds["precipitation"] = (("x", "y", "time"), precip)
ds.coords["lat"] = (("x", "y"), lat)
ds.coords["lon"] = (("x", "y"), lon)
ds.coords["time"] = pd.date_range("2020-04-08", periods=3)
ds.coords["reference_time"] = pd.Timestamp("2020-04-07")
ds<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 17.8 16.38 21.29 ... 15.9 9.936
temperature_double (x, y, time) float64 35.6 32.76 42.59 ... 31.8 19.87
precipitation (x, y, time) float64 8.035 9.461 2.014 ... 3.524 0.5864
要更改数据集中的变量,可以使用所有标准的字典方法,包括 values,items,__ delitem __,get 和 update()。
请注意,使用 __setitem__ 或 update 将 DataArray 或 pandas 对象分配给 Dataset 变量,会自动将数组与原始数据集的索引对齐。
可以使用 copy() 方法拷贝 Dataset。
默认情况下是浅拷贝,因此将仅复制容器:数据集中的数组仍将存储在相同的基础 numpy.ndarray 对象中。
可以通过调用 ds.copy(deep = True) 复制所有数据。
转换 Datasets
除了上面提到的类似字典的方法,xarray 还有一些类似 pandas 的附加方法用于将数据集转换为一个新的对象。
要删除变量,可以通过使用显示指定名称列表索引或使用 drop_vars() 方法返回新的数据集。
这些操作保持坐标不变:
ds[["temperature"]]<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 17.8 16.38 21.29 ... 24.48 15.9 9.936
ds[["temperature", "temperature_double"]]<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
lat (x, y) float64 42.25 42.21 42.63 42.59
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 17.8 16.38 21.29 ... 15.9 9.936
temperature_double (x, y, time) float64 35.6 32.76 42.59 ... 31.8 19.87
ds.drop_vars("temperature")<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
Data variables:
temperature_double (x, y, time) float64 35.6 32.76 42.59 ... 31.8 19.87
precipitation (x, y, time) float64 8.035 9.461 2.014 ... 3.524 0.5864
要删除一个维度,可以使用 drop_dims() 方法。任何使用该维度的变量将会被删除。
ds.drop_dims("time")<xarray.Dataset>
Dimensions: (x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
Data variables:
*empty*
除了使用字典方式修改外,还可以使用 assign() 和 assign_coords()。
这些方法会返回一个附加或替换数据的新的 dataset。
ds.assign(temperature2 = 2 * ds.temperature)<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 17.8 16.38 21.29 ... 15.9 9.936
temperature_double (x, y, time) float64 35.6 32.76 42.59 ... 31.8 19.87
precipitation (x, y, time) float64 8.035 9.461 2.014 ... 3.524 0.5864
temperature2 (x, y, time) float64 35.6 32.76 42.59 ... 31.8 19.87
还有 pipe() 方法,接收外部函数为参数值并调用(例如 ds.pipe(func)),而不是简单地调用它(例如 func(ds))。
这使您可以编写用于转换数据的管道(使用“方法链”),而不用费力地跟踪嵌套函数调用。
下面两段代码是等效的,但是使用管道我们可以使逻辑完全从左到右流动。
plt.plot((2 * ds.temperature.sel(x=0)).mean("y"))[<matplotlib.lines.Line2D at 0x16a87e46430>]
(ds.temperature
.sel(x=0)
.pipe(lambda x: 2 * x)
.mean("y")
.pipe(plt.plot)
)[<matplotlib.lines.Line2D at 0x16a87ee0520>]
pipe 和 assign 对应 pandas 中的方法(DataFrame.pipe 和 DataFrame.assign)
使用xarray,即使从磁盘上的文件延迟加载变量,创建新数据集也不会降低性能。 创建新对象而不是对现有对象进行转换通常会使代码更易于理解,因此我们鼓励使用这种方法。
重命名变量
另一个有用的方法是使用 rename() 函数重命名数据集中的变量。
ds.rename({
"temperature": "temp",
"precipitation": "precip",
})<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
Dimensions without coordinates: x, y
Data variables:
temp (x, y, time) float64 17.8 16.38 21.29 ... 15.9 9.936
temperature_double (x, y, time) float64 35.6 32.76 42.59 ... 31.8 19.87
precip (x, y, time) float64 8.035 9.461 2.014 ... 3.524 0.5864
相关的 swap_dims() 方法可以交换维度和非维度变量。
ds.coords["day"] = ("time", [6, 7, 8])
ds.swap_dims({"time": "day"})<xarray.Dataset>
Dimensions: (day: 3, x: 2, y: 2)
Coordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
time (day) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
* day (day) int32 6 7 8
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, day) float64 17.8 16.38 21.29 ... 15.9 9.936
temperature_double (x, y, day) float64 35.6 32.76 42.59 ... 31.8 19.87
precipitation (x, y, day) float64 8.035 9.461 2.014 ... 3.524 0.5864
坐标
坐标是存储在 coords 属性中的 DataArray 和 Dataset 对象的辅助变量:
ds.coordsCoordinates:
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
day (time) int32 6 7 8
与属性不同,xarray 会在转换 xarray 对象的操作中解释并保留坐标。 xarray中有两种坐标类型:
- 维度坐标(dimension coordinates) 是一维坐标,其名称等于维度(在打印数据集或数据数组时用
*或黑体标记)。它们用于基于标签的索引和对齐,例如在 pandasDataFrame或Series上的index。实际上,这些“维度”坐标在内部使用pandas.Index来存储其值。 - 无维度坐标(non-dimension coordinates) 是包含坐标数据但不是维度坐标的变量。它们可以是多维的,并且无维度坐标的名称与维度的名称之间没有关系。无维度坐标可用于索引或绘图;否则,xarray不会直接使用与其关联的值。它们不用于对齐或自动索引,也不需要在进行算术运算时进行匹配。
修改坐标
要完全添加或删除坐标数组,可以使用类似字典的语法,如上所示。
要在数据和坐标之间来回转换,可以使用 set_coords() 和 reset_coords() 方法:
ds.reset_coords()<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
Dimensions without coordinates: x, y
Data variables:
temperature (x, y, time) float64 17.8 16.38 21.29 ... 15.9 9.936
temperature_double (x, y, time) float64 35.6 32.76 42.59 ... 31.8 19.87
precipitation (x, y, time) float64 8.035 9.461 2.014 ... 3.524 0.5864
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
reference_time datetime64[ns] 2020-04-07
day (time) int32 6 7 8
ds.set_coords(["temperature", "precipitation"])<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
temperature (x, y, time) float64 17.8 16.38 21.29 ... 15.9 9.936
precipitation (x, y, time) float64 8.035 9.461 2.014 ... 3.524 0.5864
lat (x, y) float64 42.25 42.21 42.63 42.59
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
day (time) int32 6 7 8
Dimensions without coordinates: x, y
Data variables:
temperature_double (x, y, time) float64 35.6 32.76 42.59 ... 31.8 19.87
ds["temperature"].reset_coords(drop=True)<xarray.DataArray 'temperature' (x: 2, y: 2, time: 3)>
array([[[17.79880885, 16.37993705, 21.29427808],
[19.89055978, 18.43880845, 22.36864945]],
[[12.48489511, -3.06205514, 16.55347232],
[24.48384908, 15.89758382, 9.93633802]]])
Coordinates:
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
Dimensions without coordinates: x, y
请注意,这些操作会跳过标注给定名称的坐标(用于索引)。 这主要是因为我们不能完全确定如何设计接口,因为 xarray 无法在同一字典中存储名称相同但值不同的坐标和变量。 但是我们确实认识到支持这样的接口会很有用。
坐标方法
Coordinates 对象还具有一些有用的方法,主要用于将其转换为数据集对象:
ds.coords.to_dataset()<xarray.Dataset>
Dimensions: (time: 3, x: 2, y: 2)
Coordinates:
lon (x, y) float64 -99.83 -99.32 -99.79 -99.23
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
day (time) int32 6 7 8
lat (x, y) float64 42.25 42.21 42.63 42.59
Dimensions without coordinates: x, y
Data variables:
*empty*
合并方法特别有趣,因为它实现了在算术运算中用于合并坐标的相同逻辑:
alt = xr.Dataset(
coords={
"z": [10],
"lat": 0,
"lon": 0,
}
)
ds.coords.merge(alt.coords)<xarray.Dataset>
Dimensions: (time: 3, z: 1)
Coordinates:
* time (time) datetime64[ns] 2020-04-08 2020-04-09 2020-04-10
reference_time datetime64[ns] 2020-04-07
day (time) int32 6 7 8
* z (z) int32 10
Data variables:
*empty*
如果想实现自己的对 xarray 对象起作用的二进制操作,那么 coords.merge 方法可能会很有用。
将来,我们希望编写更多的辅助函数,以便您可以轻松地使函数像 xarray 的内置算法一样工作。
索引
想要将坐标(或任何 DataArray)转换为实际的 pandas.Index 对象,请使用 to_index() 方法:
ds["time"].to_index()DatetimeIndex(['2020-04-08', '2020-04-09', '2020-04-10'], dtype='datetime64[ns]', name='time', freq='D')
一个有用的快捷方式是 indexes 属性(在 DataArray 和 Dataset 上),它延迟构造一个字典,该字典的键由每个维度指定,其值是 Index 对象:
ds.indexestime: DatetimeIndex(['2020-04-08', '2020-04-09', '2020-04-10'], dtype='datetime64[ns]', name='time', freq='D')
多索引坐标
Xarray 支持使用 pandas.MultiIndex 标记坐标值。
midx = pd.MultiIndex.from_arrays(
[
["R", "R", "V", "V"],
[.1, .2, .7, .9]
],
names=("band", "wn"),
)
mda = xr.DataArray(
np.random.rand(4),
coords={
"spec": midx,
},
dims="spec"
)
mda<xarray.DataArray (spec: 4)>
array([0.82815482, 0.80571387, 0.27037516, 0.53940813])
Coordinates:
* spec (spec) MultiIndex
- band (spec) object 'R' 'R' 'V' 'V'
- wn (spec) float64 0.1 0.2 0.7 0.9
为了方便起见,Multi-index 可直接按照“虚拟”或“派生”坐标的访问(在打印数据集或数据数组时以 - 标记):
mda["band"]<xarray.DataArray 'band' (spec: 4)>
array(['R', 'R', 'V', 'V'], dtype=object)
Coordinates:
* spec (spec) MultiIndex
- band (spec) object 'R' 'R' 'V' 'V'
- wn (spec) float64 0.1 0.2 0.7 0.9
mda.wn<xarray.DataArray 'wn' (spec: 4)>
array([0.1, 0.2, 0.7, 0.9])
Coordinates:
* spec (spec) MultiIndex
- band (spec) object 'R' 'R' 'V' 'V'
- wn (spec) float64 0.1 0.2 0.7 0.9
也可以使用 sel 方法对 multi-index 级别进行索引。
与其他坐标不同,“虚拟”级别的坐标不会存储在 DataArray 和 Dataset 对象的 coords 属性中(尽管在打印 coords属性时会显示它们)。
因此,大多数与坐标相关的方法不适用于它们。
它也不能用来代替一个特定的级别。
因为在 DataArray 或 Dataset 对象中,每个多索引级别都可以作为“虚拟”坐标进行访问,所以其名称不得与同一对象的其他级别的名称,坐标和数据变量冲突。
即使 Xarray 为未命名级别的 multi-indexes 设置了默认名称,还是建议您显式设置级别的名称。