使用Bulk API向ElasticSearch发送数据
本文是介绍 NWPC 消息平台 系列文章的第一篇文章。
nwpc-oper/nwpc-message-client 和 nwpc-oper/nmc-message-client 两个项目用于向消息队列发送产品生成消息,已应用在数值预报中心的 GRAPES 确定性模式系统中。 项目中包括用于消息持久化的命令行工具,从消息队列接收消息并保存到 ElasticSearch 中。
逐条向 ElasticSearch 发送数据效率太低,本文介绍如何使用 Bulk API 批量发送数据。
策略
发送数据既要考虑采用批量发送减少请求次数,也要考虑到消息的时效性。 所以采用如下策略:
- 接收消息,保存到 暂存数组 中。
- 如果消息数目超过 发送阈值,发送消息。
- 等待超过一定 时间阈值,将暂存数组中的消息全部发送。
- 如果发送失败,保留暂存数组数据。
- 如果暂存数组大小超过 发送阈值 的一定倍数,程序直接退出。
下面介绍 nwpc-oper/nmc-message-client 如何应用上述策略。
应用
nmc-message-client 使用 GOLONG 实现命令行程序,从 Kafka 服务器接收消息,并保存到 ElasticSearch 中。
下图是该工具核心流程的示意图。
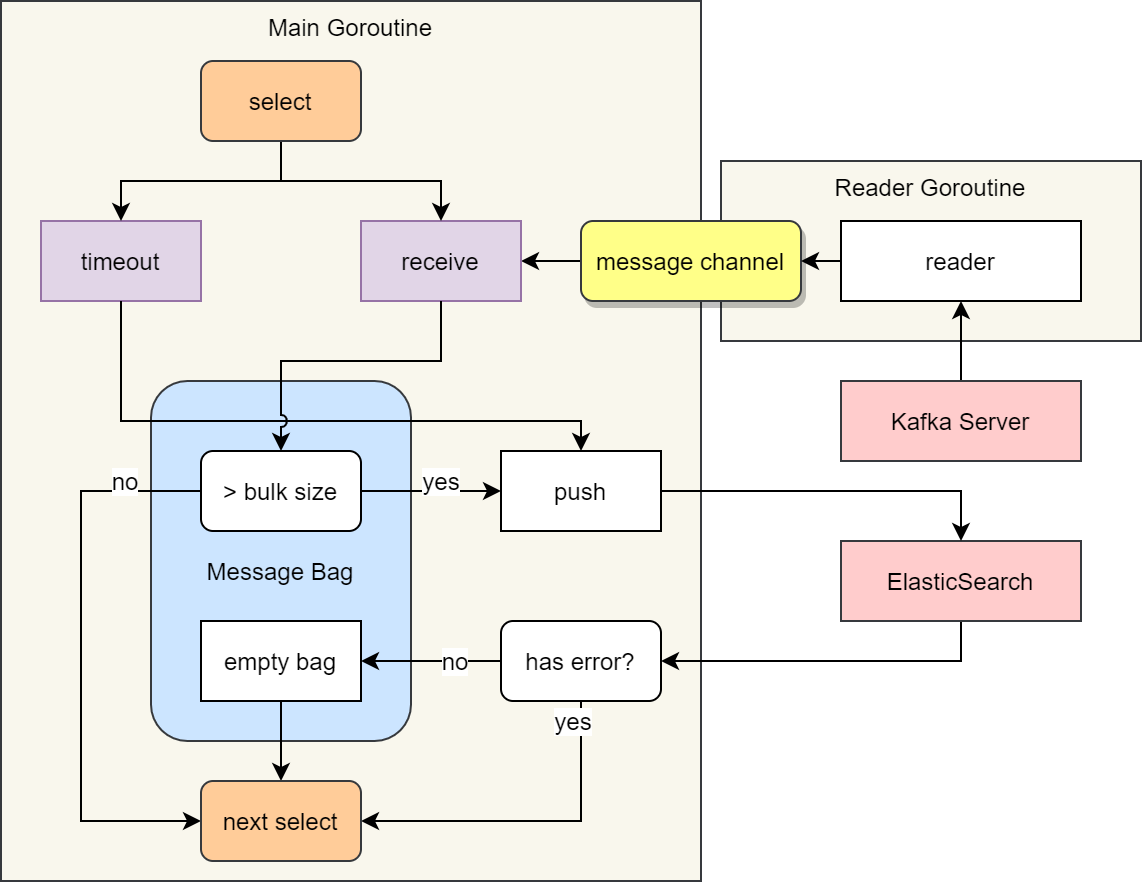
利用 Golang 的通道实现定时批量发送数据
工具在一个 Goroutine (Reader Goroutine) 中从 Kafka 队列读取消息,并将消息发送到消息通道 (message channel) 中。
主 Goroutine (Main Goroutine) 的核心是一个无限循环,循环中使用 select 语句等待两个事件:
- receive:从 message channel 中接收一个消息
- timeout:等待超过一定的时间阈值
接收消息后,会将消息保存到暂存数组 (Message Bag)。 如果缓存数量超过发送阈值 (bulk size),会将全部缓存数据发送到 ElasticSearch 中。 发送成功后,会清空暂存数组。发送失败,则直接进入下一次循环。
超时事件发生后,会将暂存数组中所有的数据都发送给 ElasticSearch 中。
图中省略了对暂存数组超过阈值一定倍数则程序出错的步骤。
下面介绍如何使用 Golang 实现上述步骤。
实现
主程序创建消息通道 messageChannel 和结束通道 done,并启动两个 Goroutine:接收 Kafka 消息readFromKafka,向ElasticSearch发送消息consumeProdGribMessageToElastic。
主程序在最后执行 select {} 进入死循环。
messageChannel := make(chan nmc_message_client.GribProduction, 10)
done := make(chan bool)
go s.readFromKafka(messageChannel, done)
go s.consumeProdGribMessageToElastic(client, ctx, messageChannel, done)
select {}其中消息通道 messageChannel 是缓存通道,结束通道 done 是阻塞通道。
接收 Kakfa 消息
readFromKafka 循环从 Kafka 队列中读取消息,使用 isProductionGribMessage 函数过滤掉不需要的消息,将解析后的消息发送到消息通道 messageChannel 中。
无法继续获取消息时,会将 true 写入到结束通道 done 中。
func readFromKafka(messageChannel chan nmc_message_client.GribProduction, done chan bool) {
for {
m, err := s.Source.Reader.ReadMessage(context.Background())
if err != nil {
break
}
var message nmc_message_client.MonitorMessage
err = json.Unmarshal(m.Value, &message)
if err != nil {
continue
}
if !isProductionGribMessage(message) {
continue
}
gribProduction, err := generateGribProduction(message, m)
if err != nil {
continue
}
messageChannel <- gribProduction
}
done <- true
}向 ElasticSearch 发送消息
consumeProdGribMessageToElastic 的主循环中使用 select 语句等待三个事件:
- 从消息通道
messageChannel中接收一个消息 - 等待超过 1 秒
- 从结束通道
done中接收到值
第一个事件将消息保存到slice对象 received 中,检测 received 大小,如果超过发送阈值 s.BulkSize,就向 ElasticSearch 发送数据。
后两个事件则直接发送 received 中的所有消息。
发送消息成功后,会清空 received。
单次循环的最后,会检测 received 大小是否超过 s.BulkSize 的 10 倍,如果超过,程序直接出错退出。
func consumeProdGribMessageToElastic(
client *elastic.Client,
ctx context.Context,
messageChannel chan nmc_message_client.GribProduction,
done chan bool,
) {
var received []messageWithIndex
isDone := false
for {
select {
case message := <-messageChannel:
index := getIndexForProductionMessage(message)
received = append(received, messageWithIndex{
Index: index,
Id: message.Offset,
Message: message,
})
if len(received) > s.BulkSize {
err := pushMessages(client, received, ctx)
if err == nil {
received = nil
}
}
case <-time.After(time.Second * 1):
if len(received) > 0 {
err := pushMessages(client, received, ctx)
if err == nil {
received = nil
}
}
case <-done:
if len(received) > 0 {
err := pushMessages(client, received, ctx)
if err == nil {}
received = nil
}
}
isDone = true
}
if isDone {
break
}
if len(received) >= s.BulkSize*10 {
log.WithFields(log.Fields{
"component": "elastic",
"event": "push",
}).Fatalf("Count of received messages is larger than 10 times of bulk size: %s", len(received))
}
}
}数据重复问题
因为 Kafka 会缓存一定时间的数据,如果程序出错重启,可能会遇到消息重复的问题。
本项目使用 Kafka 消息的 offset 作为消息的 _id,代替 ElasticSearch 自动生成的 _id。
如果重复发送,只会更新 _id 对应的文档,不会出现重复消息。
如下面的代码所示,在消息发送时,使用 Id 方法手动设置文档的_id。
func pushMessages(client *elastic.Client, messages []messageWithIndex, ctx context.Context) error {
bulkRequest := client.Bulk()
for _, indexMessage := range messages {
request := elastic.NewBulkIndexRequest().
Index(indexMessage.Index).
Id(indexMessage.Id).
Doc(indexMessage.Message)
bulkRequest.Add(request)
}
_, err := bulkRequest.Do(ctx)
if err != nil {
return fmt.Errorf("push has error: %v", err)
}
return nil
}参考
本文示例代码来自 用于NMC监控的NWPC消息工具:nwpc-oper/nmc-message-client
可以参考另一个项目 NWPC消息工具:nwpc-oper/nwpc-message-client