xarray基本用法
本文介绍xarray的基本用法,来自官方文档。
下面是一些简单的示例,介绍如何使用xarray.DataArray对象。
示例中介绍的所有用法都会在官方文档中有更详细的解释。
开始之前,请使用惯用缩写加载 numpy,pandas 和 xarray 库。
import numpy as np
import pandas as pd
import xarray as xr创建DataArray
从numpy数组或list中创建DataArray,附加可选的dimensions和coordinates。
data = xr.DataArray(
np.random.randn(2, 3),
dims=("x", "y"),
coords={"x": [10, 20]}
)
data<xarray.DataArray (x: 2, y: 3)>
array([[ 0.72416562, -0.91294078, -0.76305295],
[ 0.26180493, -0.5472152 , -1.12753176]])
Coordinates:
* x (x) int32 10 20
Dimensions without coordinates: y
上面代码创建一个二维数组,将两个维度命名为x和y,并将两个坐标标签10和20赋值给x维度对应的两个位置。
如果向DataArray提供pandas的Series和DataFrame,会自动拷贝元数据。
data_covid = xr.DataArray(
pd.DataFrame(
{
"confirmed": [437, 350, 136, 576],
"recovered": [349, 324, 132, 566],
"active": [80, 24, 1, 4]
},
index=["beijing", "shanghai", "tianjin", "chongqing"],
),
dims=("city", "cases"),
)
data_covid<xarray.DataArray (city: 4, cases: 3)>
array([[437, 349, 80],
[350, 324, 24],
[136, 132, 1],
[576, 566, 4]], dtype=int64)
Coordinates:
* city (city) object 'beijing' 'shanghai' 'tianjin' 'chongqing'
* cases (cases) object 'confirmed' 'recovered' 'active'
下面代码展示DataArray的关键属性。
与pandas一样,values是一个numpy数组,可以直接修改值。
data.valuesarray([[ 0.72416562, -0.91294078, -0.76305295],
[ 0.26180493, -0.5472152 , -1.12753176]])
维度
data.dims('x', 'y')
坐标
data.coordsCoordinates:
* x (x) int32 10 20
属性,data中尚未设置属性
data.attrs{}
索引
xarray提供四种类型的索引。 上面我们已经为x维度设置坐标值,我们可以使用在该维度上使用类似pandas的基于标签的索引。
下面2组示例每组都返回相同的结果,但有不同程度的便利性和直观性。
位置和整数标签
类似numpy。
data[0, :]<xarray.DataArray (y: 3)>
array([ 0.72416562, -0.91294078, -0.76305295])
Coordinates:
x int32 10
Dimensions without coordinates: y
data_covid[1, :]<xarray.DataArray (cases: 3)>
array([350, 324, 24], dtype=int64)
Coordinates:
city <U8 'shanghai'
* cases (cases) object 'confirmed' 'recovered' 'active'
loc 或 location
位置和坐标标签,类似numpy。
data.loc[10]<xarray.DataArray (y: 3)>
array([ 0.72416562, -0.91294078, -0.76305295])
Coordinates:
x int32 10
Dimensions without coordinates: y
data_covid.loc["shanghai"]<xarray.DataArray (cases: 3)>
array([350, 324, 24], dtype=int64)
Coordinates:
city <U8 'shanghai'
* cases (cases) object 'confirmed' 'recovered' 'active'
isel 或 interger select
使用维度名称和整数标签。
data.isel(x=0)<xarray.DataArray (y: 3)>
array([ 0.72416562, -0.91294078, -0.76305295])
Coordinates:
x int32 10
Dimensions without coordinates: y
data_covid.isel(city=1)<xarray.DataArray (cases: 3)>
array([350, 324, 24], dtype=int64)
Coordinates:
city <U8 'shanghai'
* cases (cases) object 'confirmed' 'recovered' 'active'
sel 或 select
使用维度名称和坐标标签。
data.sel(x=10)<xarray.DataArray (y: 3)>
array([ 0.72416562, -0.91294078, -0.76305295])
Coordinates:
x int32 10
Dimensions without coordinates: y
data_covid.sel(city="shanghai")<xarray.DataArray (cases: 3)>
array([350, 324, 24], dtype=int64)
Coordinates:
city <U8 'shanghai'
* cases (cases) object 'confirmed' 'recovered' 'active'
属性
使用DataArray时,为元数据设置属性通常是一个好主意。
一个有用的选择是设置data.attrs["long_name"]和data.attrs["units"],因为xarray会利用这些值自动为绘图设置标签。
这些特殊的名字来自NetCDF Climate and Forecast (CF) Metadata Conventions。
attrs是一个Python字典对象,可以为属性设置任意值。
data.attrs["long_name"] = "random velocity"
data.attrs["units"] = "metres/sec"
data.attrs["description"] = "A random variable crated as an example."
data.attrs["random_attribute"] = 123
data.attrs{'long_name': 'random velocity',
'units': 'metres/sec',
'description': 'A random variable crated as an example.',
'random_attribute': 123}
同样也可以为坐标添加元数据。
data.x.attrs["units"] = "x units"
data.x.attrs{'units': 'x units'}
data_covid.attrs["long_name"] = "count"
data_covid.attrs["units"] = "case"
data_covid.attrs{'long_name': 'count', 'units': 'case'}
计算
DataArray与numpy的ndarray数组类似。
data + 10<xarray.DataArray (x: 2, y: 3)>
array([[10.72416562, 9.08705922, 9.23694705],
[10.26180493, 9.4527848 , 8.87246824]])
Coordinates:
* x (x) int32 10 20
Dimensions without coordinates: y
np.sin(data)<xarray.DataArray (x: 2, y: 3)>
array([[ 0.66251068, -0.79130521, -0.69113112],
[ 0.2588244 , -0.5203111 , -0.90335634]])
Coordinates:
* x (x) int32 10 20
Dimensions without coordinates: y
data.T<xarray.DataArray (y: 3, x: 2)>
array([[ 0.72416562, 0.26180493],
[-0.91294078, -0.5472152 ],
[-0.76305295, -1.12753176]])
Coordinates:
* x (x) int32 10 20
Dimensions without coordinates: y
Attributes:
long_name: random velocity
units: metres/sec
description: A random variable crated as an example.
random_attribute: 123
data.sum()<xarray.DataArray ()>
array(-2.36477014)
聚合操作可以使用维度名代替轴序号。
data.mean(dim="x")<xarray.DataArray (y: 3)>
array([ 0.49298527, -0.73007799, -0.94529235])
Dimensions without coordinates: y
data_covid.sum(dim="city")<xarray.DataArray (cases: 3)>
array([1499, 1371, 109], dtype=int64)
Coordinates:
* cases (cases) object 'confirmed' 'recovered' 'active'
算术操作根据维度名称进行广播。这意味着无需为了对齐数据而插入虚拟维度。
a = xr.DataArray(
[1, 2, 3], [data.coords["y"]]
)
a<xarray.DataArray (y: 3)>
array([1, 2, 3])
Coordinates:
* y (y) int64 0 1 2
b = xr.DataArray(
[100, 200, 300], dims="z"
)
b<xarray.DataArray (z: 3)>
array([100, 200, 300])
Dimensions without coordinates: z
a + b<xarray.DataArray (y: 3, z: 3)>
array([[101, 201, 301],
[102, 202, 302],
[103, 203, 303]])
Coordinates:
* y (y) int64 0 1 2
Dimensions without coordinates: z
这样还意味着绝大部分情况下无需考虑维度的顺序。
data - data.T<xarray.DataArray (x: 2, y: 3)>
array([[0., 0., 0.],
[0., 0., 0.]])
Coordinates:
* x (x) int32 10 20
Dimensions without coordinates: y
计算还会根据索引标签对齐。
data[:-1] - data[:1]<xarray.DataArray (x: 1, y: 3)>
array([[0., 0., 0.]])
Coordinates:
* x (x) int32 10
Dimensions without coordinates: y
分组
xarray支持分组操作,使用类似pandas的API。
labels = xr.DataArray(
["E", "F", "E"],
[data.coords["y"]],
name="labels",
)
labels<xarray.DataArray 'labels' (y: 3)>
array(['E', 'F', 'E'], dtype='<U1')
Coordinates:
* y (y) int64 0 1 2
data.groupby(labels).mean("y")
<xarray.DataArray (x: 2, labels: 2)>
array([[-0.01944366, -0.91294078],
[-0.43286342, -0.5472152 ]])
Coordinates:
* x (x) int32 10 20
* labels (labels) object 'E' 'F'
data.groupby(labels).map(lambda x: x - x.min())<xarray.DataArray (x: 2, y: 3)>
array([[1.85169738, 0. , 0.36447881],
[1.38933669, 0.36572557, 0. ]])
Coordinates:
* x (x) int32 10 20
* y (y) int64 0 1 2
labels (y) <U1 'E' 'F' 'E'
绘图
可以非常快速和方便地对数据集进行可视化。
data.plot()<matplotlib.collections.QuadMesh at 0x1e4e34b6d90>
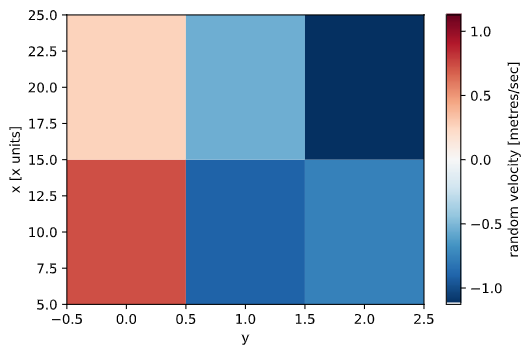
使用xarray直接绘图
注意观察自动生成的带有名称和单位的标签。增加元数据属性的努力有了回报。
xarray仅能自动绘制少数几种图形,如果需要自动绘制更多种类的图形,可以将DataArray对象转换为pandas.DataFrame,再使用DataFrame的自动绘图功能。
data_covid.sel(cases="confirmed").to_dataframe(name="count").plot.bar()<matplotlib.axes._subplots.AxesSubplot at 0x1e4e35b47c0>
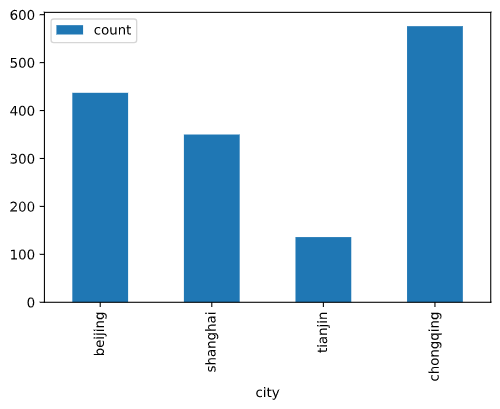
使用pandas直接绘图
pandas
使用to_series(),to_dataframe()和to_xarray()等方法,xarray对象可以很容易与pandas对象之间相互转换。
series = data.to_series()
seriesx y
10 0 0.724166
1 -0.912941
2 -0.763053
20 0 0.261805
1 -0.547215
2 -1.127532
dtype: float64
series.to_xarray()
<xarray.DataArray (x: 2, y: 3)>
array([[ 0.72416562, -0.91294078, -0.76305295],
[ 0.26180493, -0.5472152 , -1.12753176]])
Coordinates:
* x (x) int64 10 20
* y (y) int64 0 1 2
series_covid = data_covid.to_dataframe(name="count")
series_covid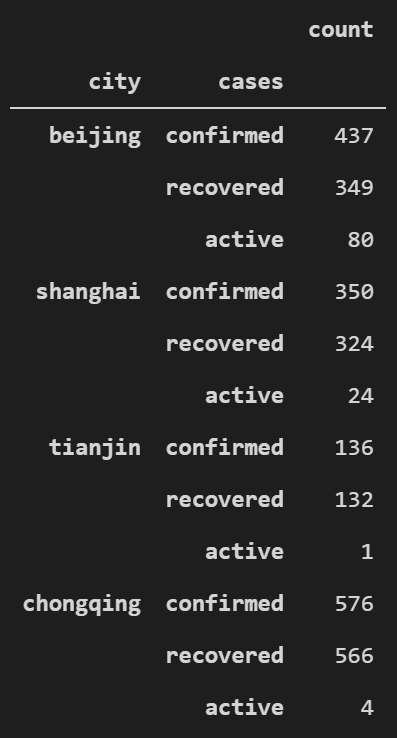
返回表格结果
table = series_covid.unstack(level=-1)
table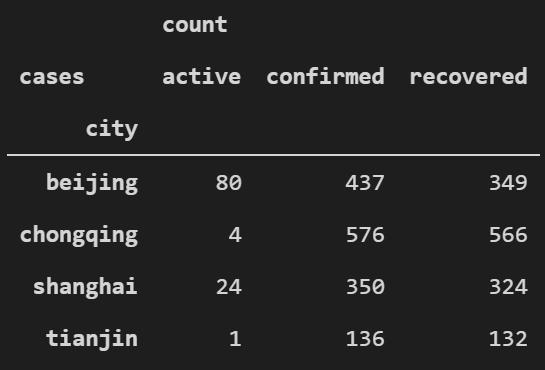
返回表格结果
series_covid.to_xarray()<xarray.Dataset>
Dimensions: (cases: 3, city: 4)
Coordinates:
* city (city) object 'beijing' 'chongqing' 'shanghai' 'tianjin'
* cases (cases) object 'active' 'confirmed' 'recovered'
Data variables:
count (city, cases) int64 80 437 349 4 576 566 24 350 324 1 136 132
Datasets
xarray.Dataset是类似字典的容器,包含对齐的DataArray对象。
可以将其想象为pandas.DataFrame的多维度扩展。
ds = xr.Dataset({
"foo": data,
"bar": ("x", [1, 2]),
"baz": np.pi
})
ds<xarray.Dataset>
Dimensions: (x: 2, y: 3)
Coordinates:
* x (x) int32 10 20
Dimensions without coordinates: y
Data variables:
foo (x, y) float64 0.7242 -0.9129 -0.7631 0.2618 -0.5472 -1.128
bar (x) int32 1 2
baz float64 3.142
上面代码创建了包含三个名为foo,bar和baz的DataArrays的数据集。
使用字典访问方式或者属性访问方式从Dataset对象中访问DataArray对象。
注意仅能通过字典访问方式进行赋值。
ds["foo"]<xarray.DataArray 'foo' (x: 2, y: 3)>
array([[ 0.72416562, -0.91294078, -0.76305295],
[ 0.26180493, -0.5472152 , -1.12753176]])
Coordinates:
* x (x) int32 10 20
Dimensions without coordinates: y
Attributes:
long_name: random velocity
units: metres/sec
description: A random variable crated as an example.
random_attribute: 123
ds.foo
<xarray.DataArray 'foo' (x: 2, y: 3)>
array([[ 0.72416562, -0.91294078, -0.76305295],
[ 0.26180493, -0.5472152 , -1.12753176]])
Coordinates:
* x (x) int32 10 20
Dimensions without coordinates: y
Attributes:
long_name: random velocity
units: metres/sec
description: A random variable crated as an example.
random_attribute: 123
创建ds时,foo与之前创建的data相同,bar是一维数组,带有单个纬度x并赋值1和2,baz是不与ds中任何一个维度相关的标量。
数据集中的变量有不同的dtype,甚至不同的纬度,但假定所有的维度都引用相同共享坐标系中的点。
例如两个变量有x维度,该维度必须在必须相同。
例如,创建ds时,xarray自动将bar与DataArray foo 对齐。它们共享同样的坐标系统,因此
ds.bar["x"] == ds.foo["x"] == ds["x"]因此,创建ds["bar"]时无需显式指定坐标x。
ds.bar.sel(x=10)<xarray.DataArray 'bar' ()>
array(1)
Coordinates:
x int32 10
如果希望同时操作多个变量,则可以将DataArray对象的几乎所有操作都应用到Dataset对象(包括索引和算术)中。
读写NetCDF文件
netCDF是xarray对象的推荐文件格式。
地球科学家会发现Dataset的数据模型与netCDF文件非常相似(实际上,Dateset正是受其启发)。
使用to_netcdf(),open_dataset()和open_dataarray(),可以直接从硬盘读取或写入xarray对象。
ds.to_netcdf("example.nc")
xr.open_dataset("example.nc")<xarray.Dataset>
Dimensions: (x: 2, y: 3)
Coordinates:
* x (x) int32 10 20
Dimensions without coordinates: y
Data variables:
foo (x, y) float64 ...
bar (x) int32 ...
baz float64 ...
数据集通常分布在多个文件中(通常每个时间步一个文件),xarray通过提供open_mfdataset()和save_mfdataset()方法支持这类用例。