NWPC高性能计算机环境介绍:作业管理
本文是 NWPC高性能计算机环境介绍 系列文章的一部分。
本文内容部分参考 ECMWF 的文档《Batch Systems》。
直接运行与批处理
之前章节介绍过,高性能计算机系统由少量的登陆节点和大量的计算节点组成。
直接在登录节点上运行程序就是下图所示的情形,登陆节点上跑了大量的程序,导致登陆节点响应速度降低,而大量计算节点处于空闲状态。
我们在平时工作中经常会遇到登陆节点执行命令卡住的情况,一个可能的原因就是因为某用户在登录节点上运行大量程序,导致 CPU 占用过高。
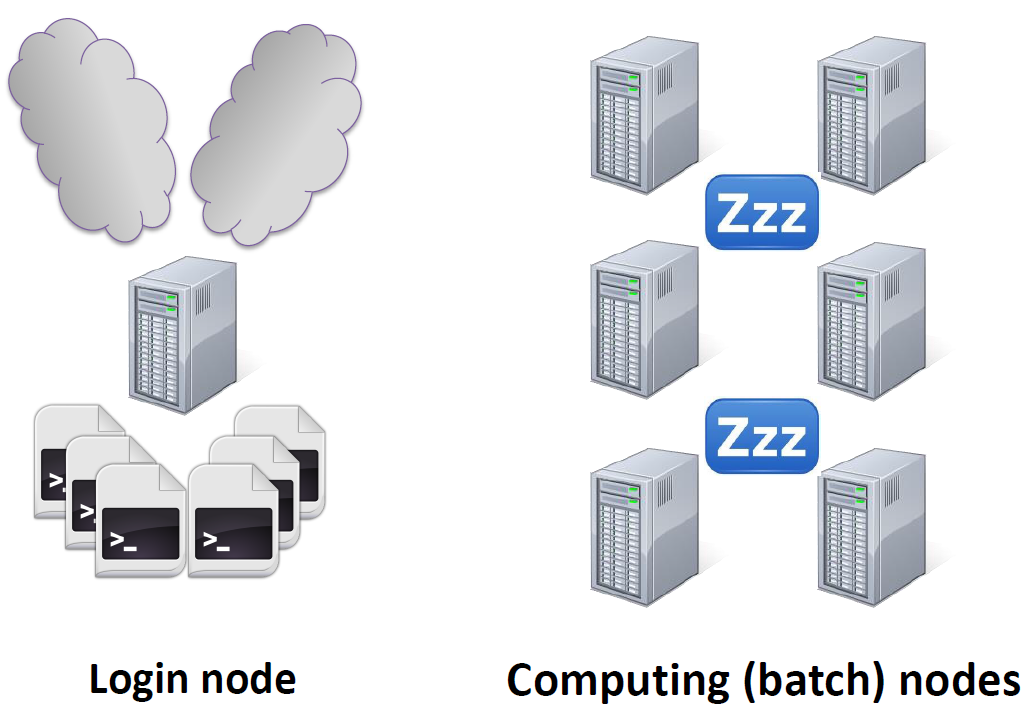
登陆节点上直接运行程序,图片来自 ECMWF 的《Batch Systems》
我们应该将作业提交到计算节点上以批处理的方式运行,如下图所示。这就需要使用作业调度系统。
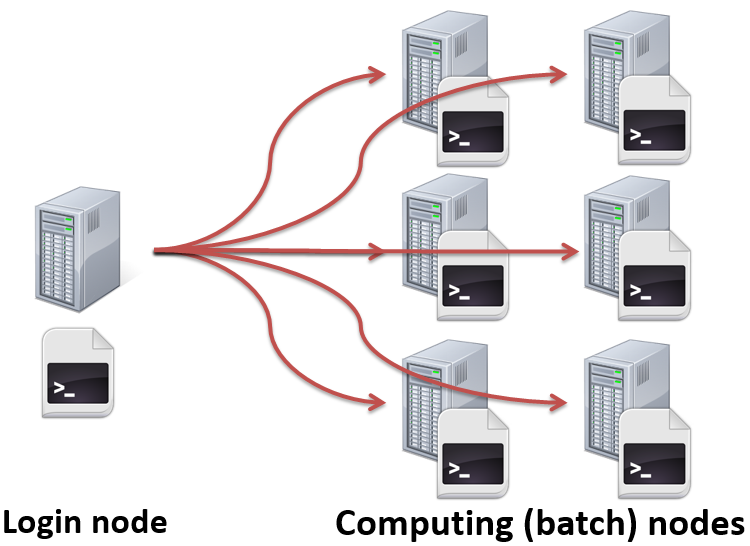
提交到计算节点上运行程序,图片来自 ECMWF 的《Batch Systems》
为了保证系统正常提供服务,请不要在登录节点上运行程序。
直接运行
某些特殊情况下,我们仍然需要在登录节点上运行程序,例如编辑文件、编译程序等。
登录节点上直接运行程序有下面几种方式:
交互方式
命令行输入程序名及参数,程序在登录终端前台运行,程序运行结束才能运行下一条命令。
./your_program arg1 arg2
后台方式
使用 & 在后台运行程序,同时执行其他操作。
此种方式需要保证登录终端一直存在才能运行结束。
./your_program arg1 arg2 &
我们使用 ecFlow UI 监控数值预报业务系统一般使用这种方式。
如果需要在登录终端退出后依然运行程序,则使用 nohup 运行程序。
nohup ./your_program arg1 arg2 &
ecFlow 的后台服务就是使用 nohup 命令使程序与终端解绑。
作业调度系统
CMA-PI 上的批处理由 Gridview 综合管理系统实现,该系统基于开源作业调度系统 Slurm Workload Manager 开发。
Slurm Workload Manager 主要提供一下功能:
- 运行和管理批处理作业
- 资源申请
- 作业调度
在作业调度系统中运行的批处理作业一般都是 shell 脚本,使用某些特殊指令描述作业属性。
作业调度原理
下图说明作业调度系统的原理。
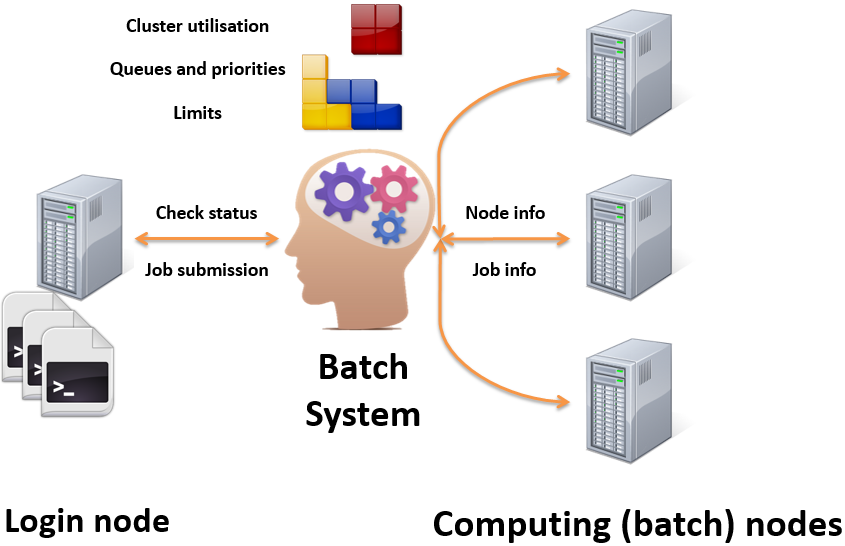
作业调度系统原理,图片来自ECMWF的《Batch Systems》
批处理系统负责对计算节点进行组织,提供队列、优先级和限制等功能。 用户从登陆节点可以提交作业和查询批处理系统的状态。 批处理系统从计算节点获取节点和作业信息。
作业调度系统的基本任务
不同作业调度系统提供不同的命令和方法,但提供的功能大多相似:
- 向调度系统提交作业
- 检查队列的状态
- 检查作业是否运行
- 从调度系统中取消或删除某个作业
在创建脚本时,通常会在脚本开头添加 特殊注释,定义作业的属性。例如:
- 作业名
- 队列名
- 使用资源(处理器个数、内存等)
- 标准输出、标准错误输出文件
- 工作路径
- 时间限制
- …
任务队列
不同队列有不同的优先级和限制。
所有用户可以使用的队列(子系统2)
| 队列名 | 描述 | 优先级 | 节点个数 | 节点名 |
|---|---|---|---|---|
| serial | 串行队列 | 1000 | 24 | cmbc[0011-0034] |
| normal | 并行队列 | 1000 | 1479 | cmbc[0035-1538] |
| largemem | 大内存并行队列 | 1000 | 230 | cmbc[0035-0260] |
仅限业务账户使用的队列(子系统2)
| 队列名 | 描述 | 优先级 | 节点个数 | 节点名 |
|---|---|---|---|---|
| serial_op | 串行队列 | 1000 | 24 | cmbc[0011-0034] |
| operation | 并行队列 | 2000 | 1479 | cmbc[0035-1538] |
可以看到 serial/serial_op、normal/operation 是共享节点的,largemem 和 normal/operation 共享部分节点。
业务账户具有最高的优先级,在资源不够的时候会抢占对应队列的资源。 建议大家在非业务运行高峰时间段提交作业,避免被抢占。
查询队列状态
使用 sinfo 命令查看队列状态。
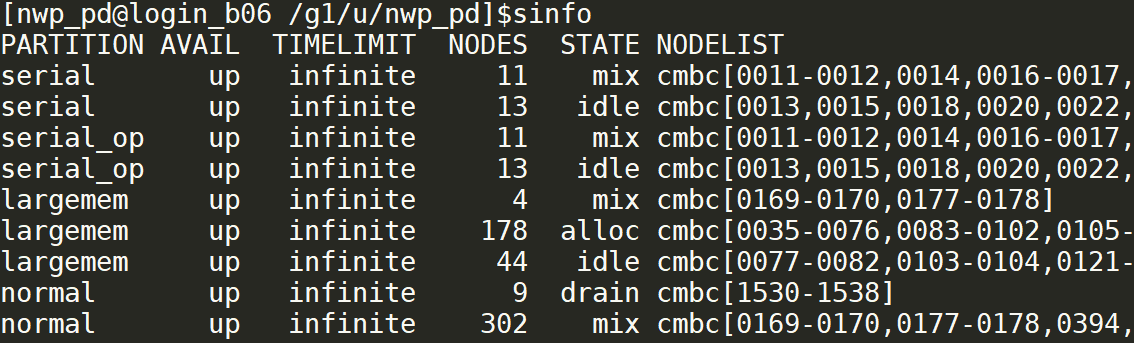
sinfo命令查看队列状态
STATE 代表节点状态,含义如下图所示:
| 节点状态 | 含义 |
|---|---|
| idle | 空闲 |
| alloc | 被占用 |
| mix | 部分占用 |
| down | 不可用 |
| drain | 管理员下线 |
使用 sinfo -s 可以查看队列的汇总状态。
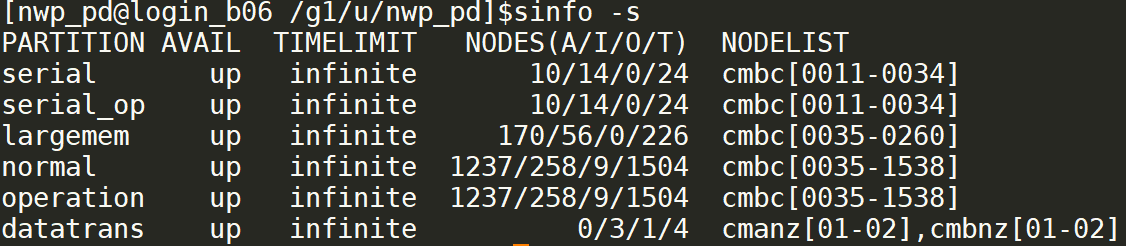
sinfo -s 命令查看队列状态
NODES 列是各种状态的节点个数,节点状态如下表所示
| 节点状态 | 含义 |
|---|---|
| A | 占用 |
| I | 空闲 |
| O | 其它 |
| T | 总数 |
编写作业脚本
提交作业前需要首先便也作业脚本。
作业是一个 shell 脚本。 第一行必须指定 shell 解释器,如 bash、ksh、csh 等。
指令是 shell 注释。
以 #SBATCH 开头,# 与 SBATCH 中间没有空格。
不能展开 shell 变量,仅是 shell 注释。
必须设置comment参数,指定运行的模式名称,例如 GRAPES。
#!/bin/ksh
# 作业名称
#SBATCH -J GRAPES
# 队列名称
#SBATCH -p operation
# 标准输出文件
#SBATCH -o /g2/nwp/ECFOUT/gmf_grapes_gfs_v2.4/06/model/fcst_long.1
# 标准错误输出文件
#SBATCH -e /g2/nwp/ECFOUT/gmf_grapes_gfs_v2.4/06/model/fcst_long.1.err
# 注释,必须设置
#SBATCH --comment=GRAPES
# 特殊指令,出错后不自动重新提交
#SBATCH --no-requeue
# 节点个数
#SBATCH -N 128
# 每个节点使用的CPU数
#SBATCH --ntasks-per-node=30
作业指令
作业指令可以在shell注释中以 #SBATCH 开头的指令设置,也可以在使用 sbatch 命令提交作业时使用命令行参数设置。
常用的作业指令如下:
| 指令 | 描述 | 示例 |
|---|---|---|
| –job-name / -J | 作业名称 | #SBATCH –J GRAPES |
| –comment | 指定运行的模式名称 | #SBATCH –comment=GRAPES |
| –partition / -p | 指定队列 | #SBATCH -p normal |
| –nodes / -N | 节点个数 | #SBATCH -N 2 |
| –ntasks / -n | 任务个数(一般为处理器总数) | #SBATCH -n 64 |
| –ntasks-per-node | 每个节点使用的处理器数量 | #SBATCH –ntasks-per-node=32 |
| –cpus-per-task | 每个任务使用的处理器数量(OpenMP线程) | #SBATCH –cpus-per-task=4 |
| -t 天-时:分:秒 | 作业运行时间 | #SBATCH –t 00:20:00 |
| –output / -o | stdout输出文件 | #SBATCH -o %j.out |
| –error / -e | stderr输出文件 | #SBATCH -e %j.err |
说明:
nodes、ntasks、ntasks-per-node:一般只需要指定 2 项,第 3 项可以由另外两项推导出。partition:串行作业必须使用串行节点。t: 某些情况下,作业运行出错后不会自动退出,最好设置墙钟时间。业务系统必须设置,避免作业运行时间过长。
模式名称
使用 modelname 命令查看支持的模式名称。
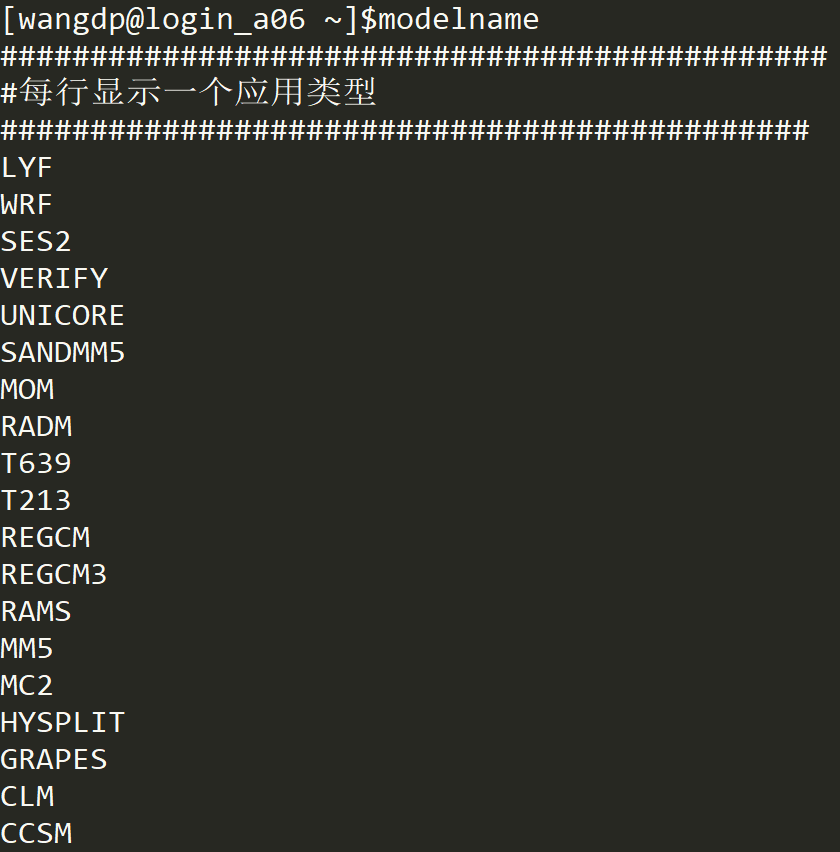
modelname命令查看支持的模式名称
NWPC 一般使用 GRAPES 即可。
该项参数主要是用于统计高性能计算机资源都用于何种用途,所以强烈建议 NWPC 使用 GRAPES 作为 comment 参数。
作业脚本示例
示例1:串行作业
下面代码是全球 GRAPES 预报后处理系统使用 ncl 画图的脚本,是一个串行作业。
#!/bin/ksh
#SBATCH -J GRAPES
#SBATCH -p serial_op
#SBATCH -o /g2/nwp_pd/.../RAIN24_SFC_FC_AEA_sep_024.1
#SBATCH -e /g2/nwp_pd/.../RAIN24_SFC_FC_AEA_sep_024.1.err
#SBATCH --comment=GRAPES
#SBATCH -t 00:10:00
#SBATCH --no-requeue
# ...skip some codes...
ncl ${file_name}
示例2:并行 MPI 作业
下面代码是全球 GRAPES 集合预报模式积分任务,是一个并行作业。
#!/bin/ksh
#SBATCH -J GRAPES
#SBATCH -p operation
#SBATCH -o /g2/nwp_qu/ECFLOWOUT/.../forecast.1
#SBATCH -e /g2/nwp_qu/ECFLOWOUT/.../forecast.1.err
#SBATCH --comment=GRAPES
#SBATCH -N 32
#SBATCH --ntasks-per-node=32
#SBATCH --no-requeue
#SBATCH -t 01:45:00
#SBATCH --exclusive
srun --mpi=pmi2 ./grapes_global.exe
运行并行程序的具体方式由并行计算课程单独介绍,不属于本教程的一部分。
提交作业
使用 sbatch 向 slurm 提交作业。上一节提到作业参数的设置方法:
- 脚本中使用指令(以
#SBATCH开头的 shell 注释) - 使用与指令相同的命令行参数
作业提交成功会返回作业号

sbatch提交成功会返回作业号,本例中作业号是 3217587
作业提交失败会返回错误消息

sbatch提交失败会返回错误信息,本例中作业脚本没有指定comment参数
判断作业是否提交成功
我们可以使用上面的输出判断作业是否提交成功。
下面的代码源自业务系统在 ecflow 中提交作业使用的命令,可以访问 /g1/u/nwp/bin/slsubmit6 查看源代码。
第2行使用 sbatch 提交作业,并将标准输出保存到 submit_output 变量。
第4行从输出中提取作业号,第 6 行会判断作业号是否提取成功。 如果提取成功,说明作业提交成功;如果作业号为空,说明作业提交失败。
1#!/bin/bash
2submit_output=$(sbatch ${job_name} 2>>${submit_log_path})
3
4rid=$(echo ${submit_output} | cut -d ' ' -f 4)
5
6if [ -n "$rid" ]; then
7 echo "Job submit success: ${task_name}"
8 # do something: set a flag...
9else
10 echo "Job submit failed: ${task_name}"
11 # do something: show an error...
12fi
检查作业
判断脚本是否在 Slurm 中运行
对于串行作业来说,同一个脚本可以在串行队列中运行,也可以在登录节点上运行。
尽管之前提到过不应该在登录节点上运行程序,但业务系统中某些任务不适合在登录节点上运行。
循环检测模式输出文件的作业一般会运行 1 到 2 个小时,如果在串行队列中运行,会长时间占用一个任务槽。
该任务大部分时间调用 sleep 命令,占用 CPU 较小,所以可以将其放到登录节点上运行,不会影响登录节点正常使用,同时能节省串行队列。
对于不同的运行方式,我们需要获取不同的作业标识用于控制任务:
- 队列中运行:作业号
- 登录节点运行:进程号
所以我们需要判断脚本是否在Slurm中运行。
Slurm运行作业时会自动设置一些环境变量,例如:
SLURM_JOB_ID: 作业号SLURM_NODELIST: 节点列表
业务系统使用如下的脚本判断作业是否在Slurm中运行
#!/bin/ksh
JOB_ID=$( echo ${SLURM_JOB_ID:-0.0} )
if [ $JOB_ID -eq 0 ] ; then
JOB_ID=$$
echo "JOB is running on login node"
else
echo "JOB is running on Slurm"
fi
squeue
squeue 显示正在运行或等待的作业信息。
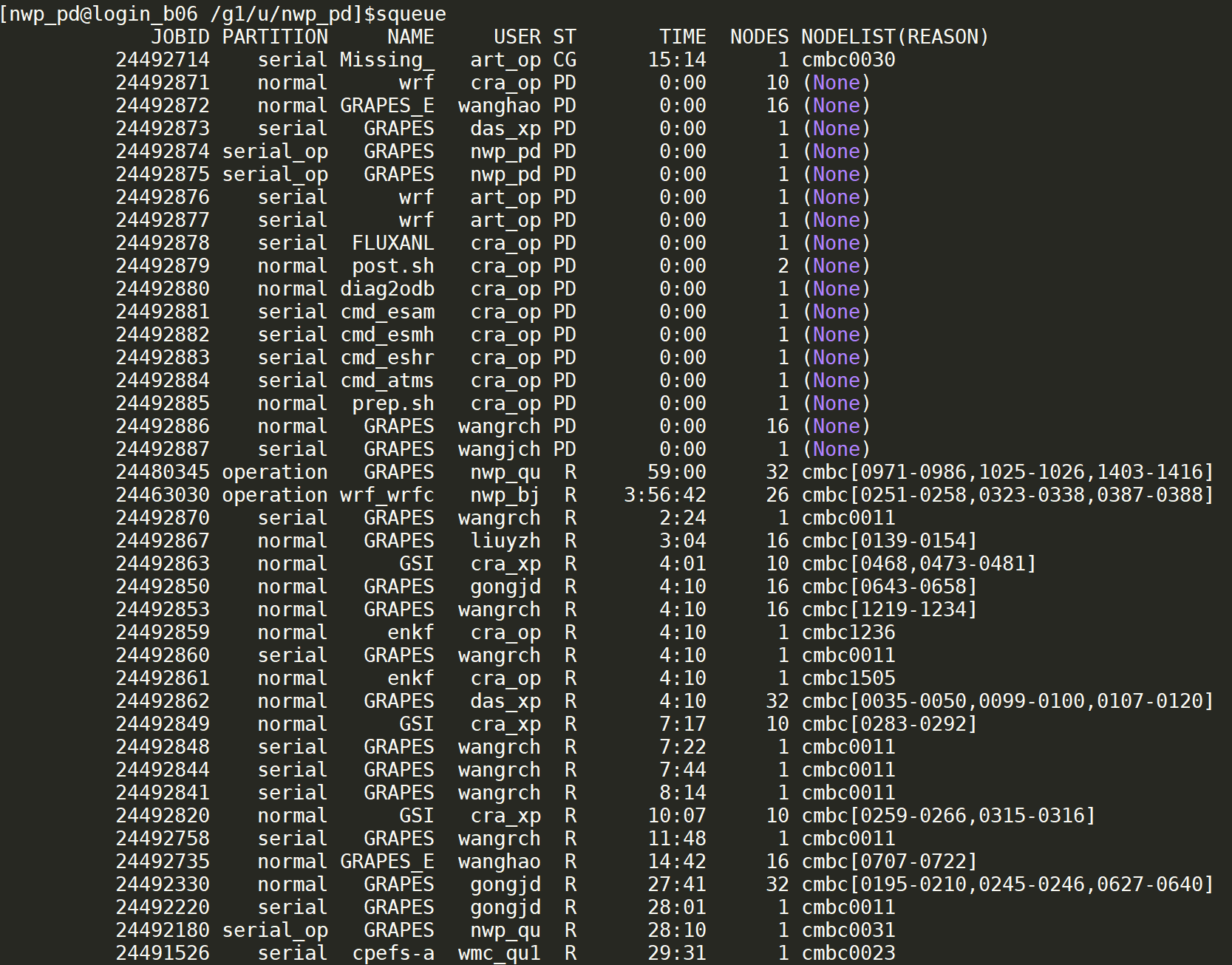
squeue 显示 slurm 中当前所有作业的状态
ST 代表作业状态,具体含义见下表。
| 作业状态 | 含义 |
|---|---|
| PD | 等待资源 |
| R | 正在运行 |
| S | 挂起 |
| CD | 作业正常退出 |
| F | 作业异常退出 |
| PR | 作业被抢占 |
| TO | 作业超时被杀 |
其中PD和R是最常见的状态。
slclient
slclinet query 是封装的 slurm 查询程序,程序放在 /g1/u/nwp/bin/slclient。
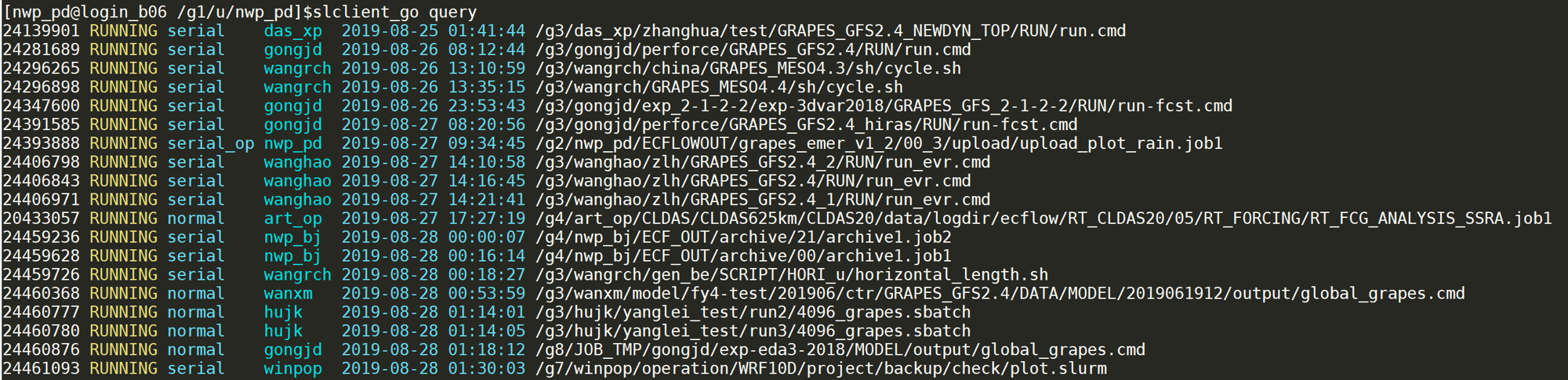
slclient query 输出
该工具是 NWPC 开发的开源项目,如果对该项目感兴趣请访问 https://github.com/nwpc-oper/slurm-client-go
取消作业
scancel 取消指定的作业,主要参数如下:
-i: 交互模式-v: 显示-u: 用户名
scancel jobid: 取消作业号为 jobid 的作业

scancel取消特定作业号的任务
scancel -u user: 取消用户 user 提交的所有作业
scancel 取消用户 wangdp 提交的所有作业
为什么作业没有运行
提交作业后往往会遇到作业没有立即运行的情况,squeue 输出的最后一列会给出提示。

squeue 最后一列说明未运行的原因
常见的未运行原因如下表所示:
| 原因 | 描述 |
|---|---|
| Priority | 其他作业优先级更高 |
| Resources | 没有足够的资源 |
| JobHeld | 作业被挂起 |
| PartitionNodeLimit | 作业请求的节点数超过分区的作业节点数限制 |
| PartitionTimeLimit | 作业请求的运行时间超过分区的作业运行时间限制 |
| PartitionDown | 作业所在的分区处于 DOWN 状态 |
| QOSMaxJobsPerUserLimit | 超过最大运行作业数限制 |
| QOSMaxCpuPerUserLimit | 超过最多使用CPU核数限制 |
| Dependency | 其他依赖作业没有完成 |
最常见的原因就是没有足够的资源或者被业务系统作业抢占资源。
队列使用规则
每个账户都有队列使用限制,这里列出 2018 版培训 PPT 中给出的限制数,2019 年应该由修改,具体情况请咨询高性能计算机管理员。
CPU核数
每个用户最多使用 4100 核(8200?)
作业数
每个用户最多运行 50 个作业;最多提交 200 个作业(所有队列作业和)
每个用户最多在 normal 和 largemem 队列运行 10 个并行作业(100?)
队列
串行作业必须提交到串行作业队列
参考
ECMWF 关于批处理系统和 Slurm 的文档
https://software.ecmwf.int/wiki/display/UDOC/Batch+Systems
https://software.ecmwf.int/wiki/display/UDOC/SLURM
https://software.ecmwf.int/wiki/display/UDOC/Slurm+job+script+examples
Slurm网站和文档
https://slurm.schedmd.com/tutorials.html
NWPC高性能计算机环境介绍 系列文章
