NWPC笔记:检查输出数据
数值预报模式积分一般会输出多个不同时效的预报结果文件,产品制作模块一般会对每个时效的文件进行处理并制作数据、图片等产品。 为了提高产品时效性,需要在数据文件生成后就立即开始制作产品,也就是在模式积分过程中运行后处理模块。
数值预报中心的业务系统使用两种方法来实现模式积分与后处理同时进行,下面首先介绍这两种后处理系统的模型。
后处理系统模型
触发器
SMS和ecFlow提供触发器机制用于解决不同任务之间的依赖关系,结合前一篇文章《NWPC业务系统笔记:获取模式积分任务的执行进度》中介绍的方法,可以为每个时效的后处理任务建立trigger,随着积分过程制作产品。
基于触发器的后处理系统模型是数值预报中心一直使用的后处理模型。尽管大部分业务系统将模式系统与产品制作系统分离,仍有部分业务系统使用该种模式,包括集合预报、区域台风、环境模式等。
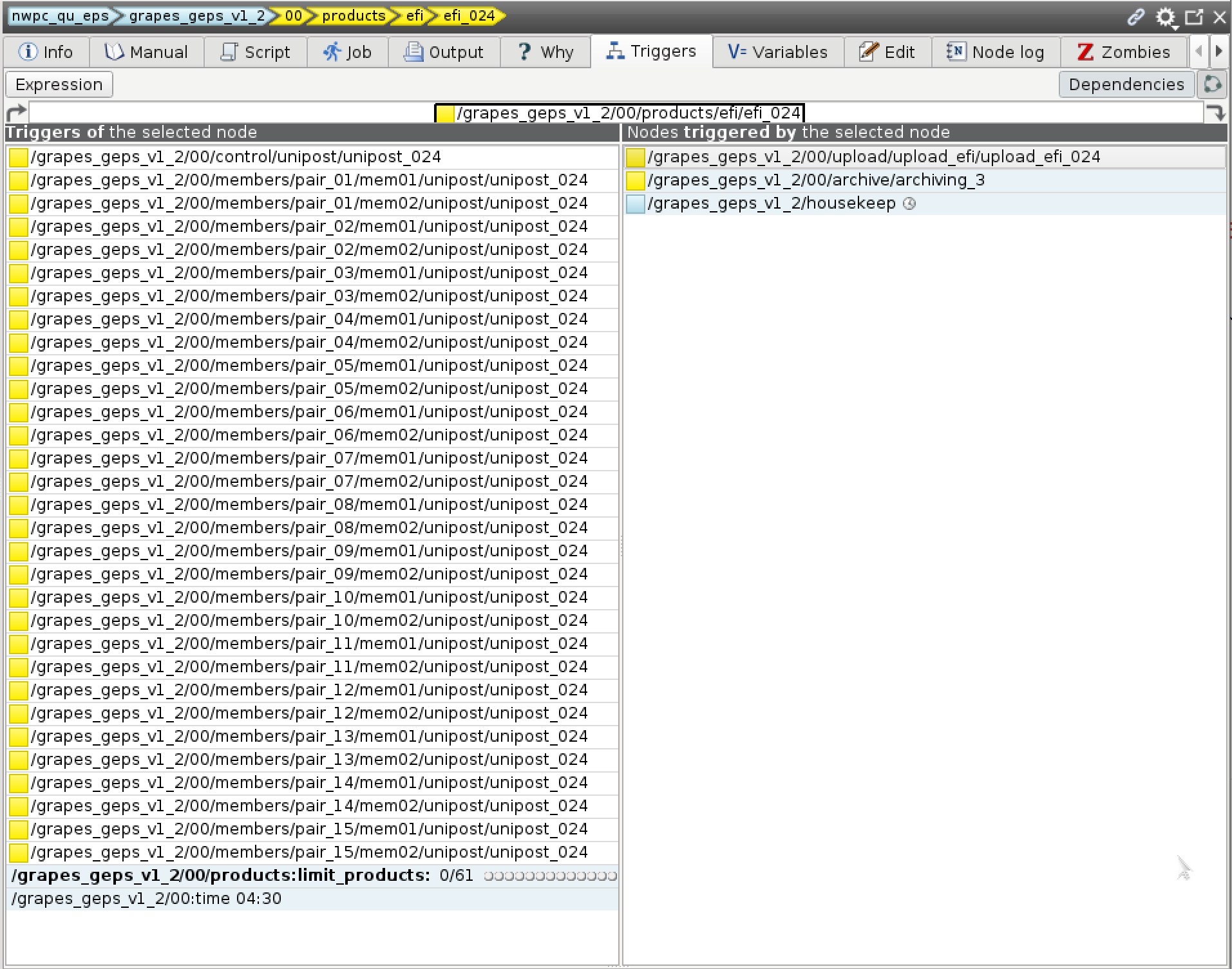
GRAPES GEPS的024时效efi任务触发器,需要所有模式积分024时效的unidata任务完成后才能触发
该模式不需要额外的机制来处理数据依赖关系,可以在数据完成(触发器满足条件)时立即启动后处理任务。
配置得当的trigger可以完全覆盖所有前置任务(数据)需求,触发器模式的复杂性就在于此。 例如上图中efi_024任务需要使用所有模式积分的数据,所以设定了31个触发条件。 不过我们使用python构建ecFlow的定义文件,通过for循环构建触发器比手动编写要容易实现。
下面是两种方式的对比。
使用for循环
tk_efi_hhh.add_part_trigger(f"../../control/unipost/unipost_{hhh} == complete")
for pair_index in range(0, 16):
for mem_index in range(0, 2):
tk_efi_hhh.add_part_trigger(
f"../../members/pair_{pair_index}/mem{mem_index}/unipost/unipost_{hhh} == complete",
True
)
使用硬编码
tk_efi_hhh.add_trigger(
"../../control/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_01/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_01/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_02/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_02/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_03/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_03/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_04/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_04/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_05/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_05/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_06/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_06/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_07/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_07/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_08/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_08/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_09/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_09/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_10/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_10/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_11/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_11/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_12/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_12/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_13/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_13/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_14/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_14/mem02/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_15/mem01/unipost/unipost_"+hhh+" == complete"
" and ../../members/pair_15/mem02/unipost/unipost_"+hhh+" == complete"
)
数据检查
最近几年,数值预报中心的大部分业务系统已将产品制作模块从模式系统中分离,构建单独的产品制作系统。 最初拆分系统的目的应该是分解系统构建任务。 但后来发现分离后处理系统能有效保障主模式系统流程的简洁,避免任务众多的后处理模块影响整个模式积分的进程,因为任务越多就越容易出错。 同时,产品制作与分发经常需要更新升级,单独建立后处理系统能避免对主模式系统的影响,也有利于系统调试。
数值预报中心使用单独的产品账户运行所有单独的后处理系统,不影响其他模式积分系统的正常运行。
因为ecFlow不支持跨服务的触发器,所以需要额外的机制检测模式积分输出数据的进度,并启动相应的产品制作任务。
我们采用检测数据文件的方式解决不同系统间的数据依赖关系。
系统会实时监测模式系统的输出文件,当监测的数据文件完整后,会启动后续的产品制作任务。
下面介绍监测数据文件相关的关键技术。
数据检查方式
数值预报中心业务系统有两种检查数据的方式:多个作业并发检测和单个作业顺序检测。
多个作业并发检测
最直接的方式就是为每个数据创建一个数据检查任务,同时检查数据。 这种方式适合任务运行时所有数据已经存在的情况,并且后续任务需要在所有数据都处理完后才能继续进行。
例如区域模式需要多个时效的全球模式背景场资料,一般在区域模式启动时,全球模式的数据都已经生成。 所以同时启动多个数据检测任务可以加快数据检测过程。
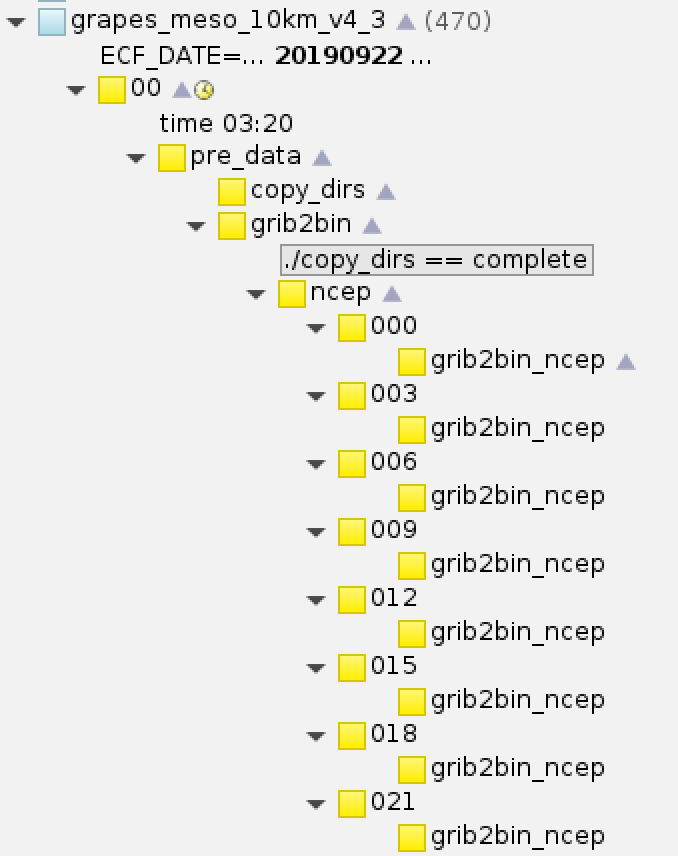
GRAPES MESO同时检测多个时效的背景场资料
数据并发检测往往和数据预处理结合到一块,加快数据预处理过程。

并发检测的缺点在于如果数据没有按时生成,等待时间过长会占用大量串行队列。并且如果需要检测的数据过多,也会占用大量资源。 我们采用限制同时运行的作业数并在登录节点运行数据检查作业等方法优化检查任务,降低对资源占用。
对于产品制作系统,我们通常采用下面的方法检查数据。
单个作业顺序检测
模式输出的每个时效数据都会对应一部分产品任务,因为模式积分是逐时效输出数据的, 所以我们只需提交一个串行作业,依次检测各个时效的数据是否生成。 这种方式能显著减少作业的提交数量。
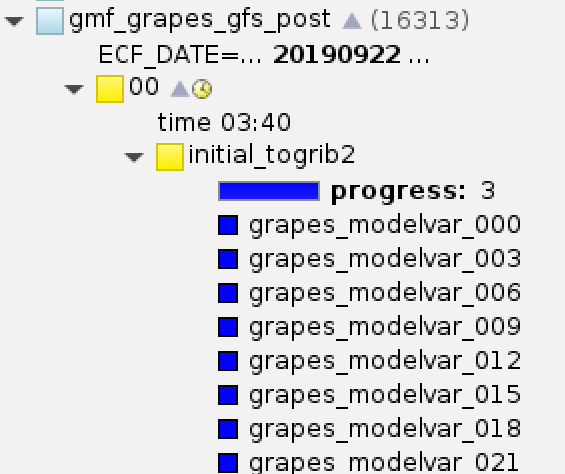
GRPAES GFS后处理系统顺序检测各个时效的MODELVAR文件,每检测到一个时效会设置对应的event
后续任务可以使用各个event作为trigger。
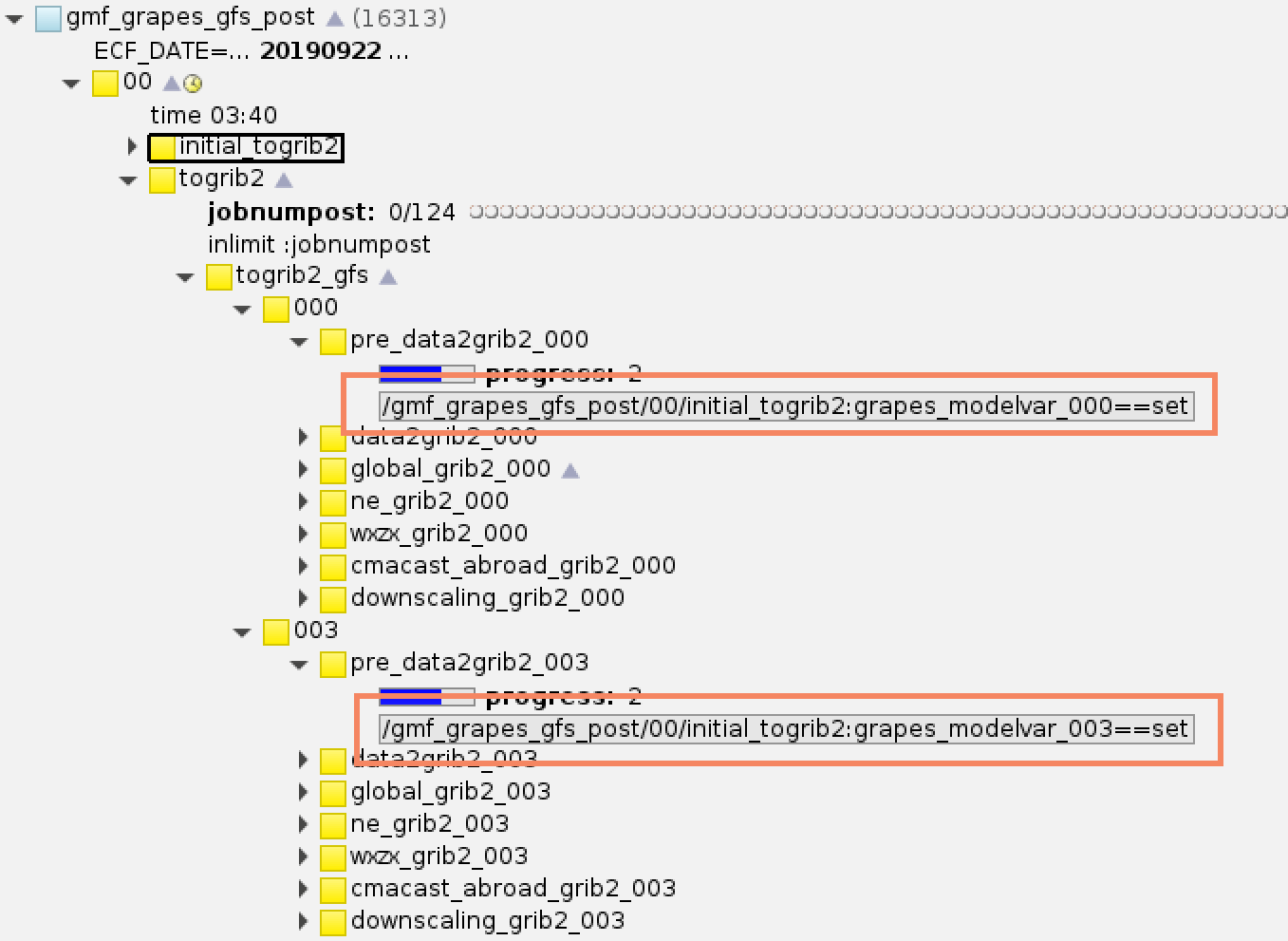
GRAPES GFS后处理系统数据转码任务使用initail_togrib2的各个event作为触发器
这种方式的缺点在于如果某个时效的文件无效,那么后续所有时效的文件将不会被检测到。 不过对于模式输出来讲,输出文件出错的情况及其罕见。如果出现就可能意味着后续所有的文件都不再可信,或者HPC本身有重大故障。 所以,后处理系统中可以采用这种方式检测文件。
下面介绍数据检测任务中如何实现对数据文件的检测。
数据存在检测
首先要检测数据是否存在。最简单的情况就是如果数据不存在就直接出错。 但对于业务系统来讲,往往不能保证系统启动时需要的数据一定会存在,如果直接出错,会给运维人员带来繁重的维护压力。 所以我们一般采用多种方式避免数据检测立即出错,增加数据检测的容错性。
循环等待数据
对于使用模式积分数据的后处理系统,我们通常采用循环等待数据的方式,每隔一段时间循环检测数据文件是否生成。
下面的代码展示如何循环等待数据,并设置超时限制:两次检测间隔60秒,最多检测240次,如果超过次数,直接出错。
max_check_count=240
sleep_seconds_for_check=60
check_file()
{
data_type=$1
start_time=$2
f_time=$3
file_path=$4
count=0
get_data=0
while [[ ${count} -lt ${max_check_count} ]] && [ ${get_data} -ne 1 ]
do
echo "check...${data_type} ${start_time} ${f_time}...${count}/${max_check_count}"
file_path=$(some program to get file path)
if [[ "x${file_path}" != "xNOTFOUND" ]]; then
get_data=1
echo "check...${file_path}...${count}/${max_check_count}: check data success"
else
sleep ${sleep_seconds_for_check}
fi
count=$(($count+1))
done
if [[ $get_data -eq 0 ]];then
echo "check...${data_type} ${start_time} ${f_time}...failed (too many times)"
return 1;
fi
echo "check...${file_path}...found"
return 0;
}
if ! check_file \
"grapes_meso_3km/bin/postvar" \
${START_TIME} \
${ftime} \
${file_path}; then
we_got_an_error
fi
使用多种渠道
区域模式需要NCEP GFS做背景场资料,为了保证预报时效,无法像后处理系统那样设置很长的循环等待时间。 我们一般使用多种渠道获取数据,并添加GRAPES GFS作为备份数据源。
GRAPES MESO模式会按照下面的顺序查找数据:
- PI上共享目录下是否存在当前时次的GFS数据
- IBM上共享目录下是否存在当前时次的GFS数据
- FTP上共享目录下是否存在当前时次的GFS数据
- PI上共享目录下是否存在前一时次(6小时前)的GFS数据
- 如果数据都不存在,直接出错
下面的代码展示了如何实现上面的查找步骤。
if [ ! -e ${NCEP_GFS_LOCAL_DIR}/gfs.t${BDYHH}z.pgrb2.${res}.f${TTT} ];then
if [ -e ${NCEP_GFS_SRC_DIR}/gfs.t${BDYHH}z.pgrb2.${res}.f${TTT} ];then
cp ${NCEP_GFS_SRC_DIR}/gfs.t${BDYHH}z.pgrb2.${res}.f${TTT} ${NCEP_GFS_LOCAL_DIR}/
else
set +e
scp pi@ibm:${IBM_NCEP_GFS_LOCAL_DIR}/gfs.$BDYTIME/gfs.t${BDYHH}z.pgrb2.${res}.f${TTT} \
${NCEP_GFS_LOCAL_DIR}/
set -e
if [ ! -e ${NCEP_GFS_LOCAL_DIR}/gfs.t${BDYHH}z.pgrb2.${res}.f${TTT} ];then
ftp -nv ${NCEPGFS_IP} << EOF
${NCEPGFS_AUTH}
cd ${NCEPGFS_DIR}/gfs.$BDYTIME
lcd ${NCEP_GFS_LOCAL_DIR}
bin
get gfs.t${BDYHH}z.pgrb2.${res}.f${TTT}
bye
EOF
if [ -e ${NCEP_GFS_LOCAL_DIR}/gfs.t${BDYHH}z.pgrb2.${res}.f${TTT} ];then
echo "get gfs.t${BDYHH}z.pgrb2.${res}.f${TTT} by ftp."
elif [ "$bckghr" = "-6" ] & \
[-e ${NCEP_GFS_SRC_DIR_BAK1}/gfs.t${BDYHH_BAK1}z.pgrb2.${res}.f${TTT_BAK1}] & \
[ ${TTT_BAK1} -ge 0 ];then
cp ${NCEP_GFS_SRC_DIR_BAK1}/gfs.t${BDYHH_BAK1}z.pgrb2.${res}.f${TTT_BAK1} \
${NCEP_GFS_LOCAL_DIR}/gfs.t${BDYHH}z.pgrb2.${res}.f${TTT}
elif [ -e ${NCEP_GFS_SRC_DIR_BAK2}/gfs.t${BDYHH_BAK2}z.pgrb2.${res}.f${TTT_BAK2} ];then
cp ${NCEP_GFS_SRC_DIR_BAK2}/gfs.t${BDYHH_BAK2}z.pgrb2.${res}.f${TTT_BAK2} \
${NCEP_GFS_LOCAL_DIR}/gfs.t${BDYHH}z.pgrb2.${res}.f${TTT}
else
echo "can't found NCEP GFS data, use GRAPES_GFS instead."
we_got_an_error
fi
fi
fi
fi
如果NCEP数据没有按时获取到,我们还准备了GRAPES GFS作为备份的背景场。
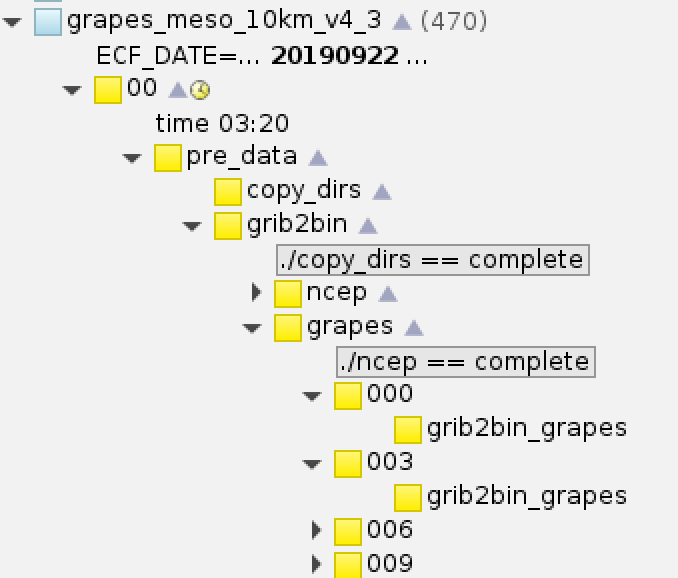
GRAPES MESO在NCEP数据缺失的情况下,会使用GRAPES GFS作为背景场
grib2bin_grapes任务会检测NCEP背景场是否完整,如果有一个时效缺失,就会将所有背景场切换为GRAPES GFS数据。
use_grapes=.true.
if [ "${use_grapes}" = ".true." ];then
use_grapes=".false."
for fhour in `seq 0 ${bckg_interval} ${mfcast_len}`
do
bckgtime=`smsdate ${ECF_DATE}$HH +$fhour `
if [ ! -s ${dataproc_dir}/bckg_${bckgtime} ];then
use_grapes=".true."
break
fi
done
fi
if [ "${use_grapes}" = ".true." ];then
# make grapes gfs bdy.
fi
因为不同背景场资料对模式预报效果影响很大,所以我们需要尽量使用NCEP资料。 NCEP资料正常时,系统会自动跳过grib2bin_grapes任务。 NCEP资料缺失时,在尝试几次获取数据失败后,需要运维人员手动将出错的grib2bin_ncep任务set complete来启动后续的grapes系列任务。
两种方式结合
当然,可以将两者结合。循环检测部分数据,如果超过时限,再切换到新的数据源。
GRAPES TYM系统背景场与GRAPES MESO一样都使用NCEP GFS,但需要120小时的预报结果,数据到达的时间可能比较延后。 为了在数据到达后立即启动预报,系统设置一个偏早的启动时间,并循环等待数据。 如果超过时限数据没到,则使用前一时次的数据。
for fetch_index in $(seq 1 10); do
# ...
# get data like GRAPES MESO
# ...
sleep 60
done
if [ -e ${NCEP_GFS_LOCAL_DIR}/gfs.t${BDYHH}z.pgrb2.${res}.f${TTT} ];then
echo "get gfs.t${BDYHH}z.pgrb2.${res}.f${TTT}"
elif [ -e ${NCEP_GFS_SRC_DIR_BAK2}/gfs.t${BDYHH_BAK2}z.pgrb2.${res}.f${TTT_BAK2} ];then
cp ${NCEP_GFS_SRC_DIR_BAK2}/gfs.t${BDYHH_BAK2}z.pgrb2.${res}.f${TTT_BAK2} ${NCEP_GFS_LOCAL_DIR}/
else
echo "can't found NCEP GFS data, please use GRAPES_GFS instead by yourself: to force ncep complete."
we_got_an_error
fi
数据完整性检测
检测到的数据可能是不完整的,比如写入过程尚未结束,或者文件系统同步问题,或者数据本身有问题等。 所以在检测到数据存在后,需要进一步检测数据是否完整。
数值预报中心业务系统目前主要有下面几种检测数据完整性的方式。
等待时间
最简单的方式就是在检测到数据存在后,等待一小段时间后,进行下一步操作。
下面代码来自GRAPES MESO 3KM系统模式输出检测任务,略有修改。当任务检测到文件存在时,会等待3秒钟,然后执行拷贝命令。 采用这种方式,是假设文件从开始写入到最终完成写入耗时不超过3秒钟。 实际上因为模式采用并行IO输出二进制文件,所以3秒钟之内一定会完成整个文件的输出。
while [ $fileExist = ".false." ]
do
if [ -s postvar${begintime}${FFF}00 ] & \
[ -s post.ctl_${begintime}${FFF}00 ] & \
[ -s modelvar${begintime}${FFF}00 ] & \
[ -s model.ctl_${begintime}${FFF}00 ]; then
sleep 3
cp postvar${begintime}${FFF}00 \
post.ctl_${begintime}${FFF}00 \
modelvar${begintime}${FFF}00 \
model.ctl_${begintime}${FFF}00 \
${GRAPES_RESULTS}/
ecflow_client --meter=fcstHours $fhour
fileExist=".true."
else
sleep 60
fi
done
这种方式实现最简单,但不够鲁棒,无法检测复杂的情况。所以目前仅在模式系统中使用,后处理系统一般使用下面的方法。
文件大小
检测文件大小有两种方式:判断文件大小是否符合规范、文件大小是否有变化
判断文件大小是否符合规范
对于postvar、modelvar等二进制数据,所有数据大小一致,可以通过检测文件大小判断数据是否完整。
下面代码源自GRAPES GFS后处理系统,检测到modelvar文件后,会比较文件的大小是否为预设的数值。 如果小于预设值,会循环等待。
FNMODELVAR=$(some program to find data)
if [ "$FNMODELVAR" != "NOTFOUND" ]; then
# check size
sz=4248478080
user=$(ls -l ${FNMODELVAR})
filesize=$(echo $user|cut -d " " -f$i)
while [ $filesize -lt $sz ]
do
echo $filesize
user=$(ls -l ${FNMODELVAR})
filesize=$(echo $user|cut -d " " -f$i)
sleep 30
done
ecflow_client --event=grapes_modelvar_$ftime
# ...skip...
fi
这种方式需要保证检测的数据文件大小保持不变,在系统升级时需要修改预设的数值。 另外,对于GRIB2等没有固定大小的文件,无法用该方法判断文件完整性。
文件大小是否有变化
我们对上面的方法进行修改,不检测固定的文件大小,而是检测文件大小是否有变化。 如果某个时间段内文件大小没有变化,就说明该文件已经完整。
下面代码实现通用的文件大小变化检测功能,用于多个后处理系统。
sleep_seconds_for_check通常会设置一个比较大的值,比如30秒。
echo "check...${file_path}...${count}/${max_check_count}: check size change"
last_file_size=-1
while [[ ${count} -lt ${max_check_count} ]] && [[ $get_data -eq 0 ]]
do
echo "check...${file_path}...${count}/${max_check_count}: check size chagne"
current_file_size=$(stat -c %%s ${file_path})
if [[ ${last_file_size} -eq ${current_file_size} ]]; then
get_data=1
echo "check...${file_path}...${count}/${max_check_count}: check size chagne success"
else
last_file_size=${current_file_size}
sleep ${sleep_seconds_for_check}
fi
count=$(($count+1))
done
该方法的缺点可能无法检测文件写入超过间隔时间的情况。 不过从业务系统长时间的运行情况来看,尚未出现这样的情况,所以可以采用这种方式。
文件内容
某些特殊情况下,检测文件大小也无法确定文件是否完整。 比如文件写入出错,导致文件大小正确,但内容无法识别。 或者因脚本逻辑不够鲁棒,导致生成的GRIB2文件中出现大量重复消息。
单纯使用文件大小很难检测出上面的故障。所以,在数值预报中心的部分业务系统中,增加了对GRIB2文件内容的检测。
下面的代码使用wgrib2判断消息个数,并指定一个范围,GRIB2消息个数超过范围的文件被认为是异常文件。
message_count=$(wgrib2 -s newgmf.gra.${init_time}${FTIMEH3}.grb2 | wc -l)
if [ ${message_count} -ge 900 -o ${message_count} -le 800 ];then
echo "================================ERROR================================"
echo " grib2 message count is too large or two small. Please check output."
echo "====================================================================="
this_is_an_error
fi
